
Melhor navegador de scraping de IA: Raspe e monitore dados de qualquer site
Specialist in Anti-Bot Strategies
A raspagem web é essencial para evitar que seu negócio ou produto fique para trás. Os dados da web podem lhe dizer quase tudo sobre potenciais consumidores, desde o preço médio que pagam até os recursos imprescindíveis do momento.
Como você pode reduzir a carga de rastreio e tornar seu trabalho mais eficiente?
Usar as melhores ferramentas de raspagem web é essencial para obter dados de alta qualidade, portanto, você precisa garantir que obtenha as melhores ferramentas para o trabalho.
Comece a ler este artigo agora para aprender tudo sobre raspagem web e obter o melhor navegador de raspagem!
Por que a raspagem de dados é essencial?
Informações desatualizadas podem fazer com que as empresas aloquem recursos de forma ineficiente ou percam as últimas oportunidades de ganhar dinheiro. Você definitivamente precisa confiar nos dados de preços de bens de consumo de movimento rápido da semana anterior aos feriados para formular os preços do próximo mês.
Os dados da web podem ajudar a aumentar as vendas e a produtividade em grande extensão. A internet moderna é extremamente animada - os usuários geram espantosos 2,5 quintilhões de bytes de dados a cada dia. Se você é uma startup ou uma grande empresa com décadas de história, as informações úteis nos dados da internet podem ajudá-lo a atrair potenciais clientes de concorrentes e fazê-los pagar por seus produtos.
No entanto, a enorme quantidade de dados potenciais de clientes significa que você pode passar a vida extraindo dados manualmente e nunca alcançar. E a extração manual de dados também encontra vários desafios!
Desafios ao raspar e monitorar dados
1. Medidas anti-raspagem
Muitos sites implantam várias técnicas para detectar e bloquear atividades de raspagem. Essas medidas são implementadas para proteger seus dados e evitar abusos.
- CAPTCHAs: São quebra-cabeças projetados para diferenciar a atividade humana da atividade de bots. Formas comuns de CAPTCHA incluem texto distorcido, tarefas de reconhecimento de imagem ou ações de clicar para selecionar.
- Limitação de taxa: Os sites podem limitar o número de solicitações de um único endereço IP em um determinado período para evitar sobrecarregar seus servidores. Se muitas solicitações forem enviadas em um curto período, seu IP pode ser bloqueado.
- Bloqueio de IP: Os sites geralmente rastreiam os endereços IP dos quais as solicitações são feitas. Se detectarem comportamento de raspagem, eles podem bloquear ou restringir o acesso desse IP.
- Renderização de JavaScript: Muitos sites modernos usam JavaScript para carregar conteúdo dinamicamente. Os métodos tradicionais de raspagem (por exemplo, com bibliotecas como Requests ou BeautifulSoup) podem ter dificuldades com a raspagem desse conteúdo.
- Impressão digital do navegador: Os sites podem detectar tráfego não humano analisando os comportamentos e impressões digitais do navegador, como resolução de tela, plug-ins instalados e outras características.
Frustrado por ser bloqueado por CAPTCHAs e detecção anti-bot?
Scrapeless desbloqueia 99,9% dos sites
Experimente gratuitamente!
2. Estruturas de sites dinâmicas e complexas
Os sites são frequentemente construídos usando estruturas que carregam dados dinamicamente via JavaScript. Esses sites dinâmicos geralmente usam solicitações AJAX para inserir conteúdo depois que a página foi carregada, tornando difícil a raspagem usando métodos tradicionais.
- Sites com muito JavaScript: A raspagem de conteúdo de sites como agências de notícias ou plataformas de mídia social geralmente requer a capacidade de renderizar JavaScript. Sem isso, o conteúdo pode não estar disponível no código-fonte HTML da página.
- Rolagem infinita: Sites com rolagem infinita (por exemplo, sites de mídia social ou comércio eletrônico) carregam mais conteúdo à medida que o usuário rola para baixo. Isso apresenta desafios para determinar quando todos os dados necessários foram carregados e como extraí-los de forma eficiente.
- Estrutura HTML complexa: Sites com estruturas HTML complexas (por exemplo, elementos aninhados, nomes de tags irregulares ou layouts inconsistentes) podem tornar a análise do conteúdo difícil.
3. Soluções anti-bot
Os sites estão cada vez mais implantando soluções anti-bot sofisticadas para proteger seus dados, o que pode tornar a raspagem uma tarefa mais difícil.
- Impressão digital do dispositivo: Os sites podem usar técnicas avançadas para detectar comportamentos semelhantes a bots, como analisar as impressões digitais do seu navegador, configurações de rede ou até mesmo os movimentos do mouse.
- Análise de comportamento: Alguns sites rastreiam suas interações (por exemplo, movimentos do mouse, cliques e comportamento de rolagem) para detectar comportamento de bot. Se o raspador se comportar de maneira não humana, ele pode acionar medidas anti-bot.
Como funciona um navegador de raspagem?
Etapa 1. Enviando solicitações HTTP
Etapa 2. Renderizando páginas da web
Etapa 3. Navegando na página da web
Etapa 4. Extraindo dados
Etapa 5. Lidando com conteúdo dinâmico
Etapa 6. Gerenciando sessões e cookies
Etapa 7. Lidando com mecanismos anti-raspagem
Etapa 8. Lidando com erros e falhas
Etapa 9. Armazenando e saindo dados
Por que o navegador de raspagem pode contornar os desafios?
Os navegadores de raspagem podem evitar efetivamente o monitoramento e o bloqueio do site, principalmente com base nas seguintes tecnologias principais:
1. Solucionador de CAPTCHA integrado
Um navegador de raspagem integra serviços de solução de CAPTCHA, que podem identificar e resolver automaticamente os desafios de CAPTCHA do site.
2. Rotação de IP
Por meio da rotação de IP, o navegador de raspagem pode alterar frequentemente o endereço IP da fonte da solicitação, o que pode evitar que um único endereço IP faça um grande número de solicitações em um curto período de tempo. Usando proxies rotativos, cada solicitação pode usar um endereço IP diferente e, em seguida, contornar o bloqueio de IP.
3. Randomização do User-Agent
Por meio da randomização do User-Agent, os navegadores de raspagem podem simular solicitações de diferentes navegadores, dispositivos e sistemas operacionais, reduzindo o risco de serem identificados como rastreadores. Ao mudar constantemente a string do User-Agent, os rastreadores podem fazer com que as solicitações pareçam vir de usuários diferentes, em vez de uma única ferramenta automatizada.
4. Impressão digital real
O navegador de raspagem simula a impressão digital do navegador de um usuário real, em vez de alterar ou falsificar a impressão digital para evitar a identificação. As impressões digitais reais podem fazer com que o rastreador se comporte mais como um usuário normal, assim como outros usuários que visitam o site usando o mesmo dispositivo e navegador.
Você também pode gostar: 5 Melhores Navegadores de Raspagem 2025
O melhor navegador de raspagem de IA - Scrapeless
Navegador de Raspagem Scrapeless fornece uma plataforma serverless de alto desempenho. Ele simplifica efetivamente o processo de extração de dados de sites dinâmicos. Os desenvolvedores podem executar, gerenciar e monitorar navegadores sem cabeça sem servidores dedicados, permitindo automação web eficiente e coleta de dados.
Por que o Scrapeless é especial para raspagem web?
Navegador de Raspagem Scrapeless possui uma rede global que abrange 195 países e mais de 70 milhões de IPs residenciais, um poderoso desbloqueador da web e um solucionador de CAPTCHA altamente estável. É ideal para usuários que precisam de uma solução de raspagem web confiável e escalável.
Como usar o navegador de raspagem Scrapeless?
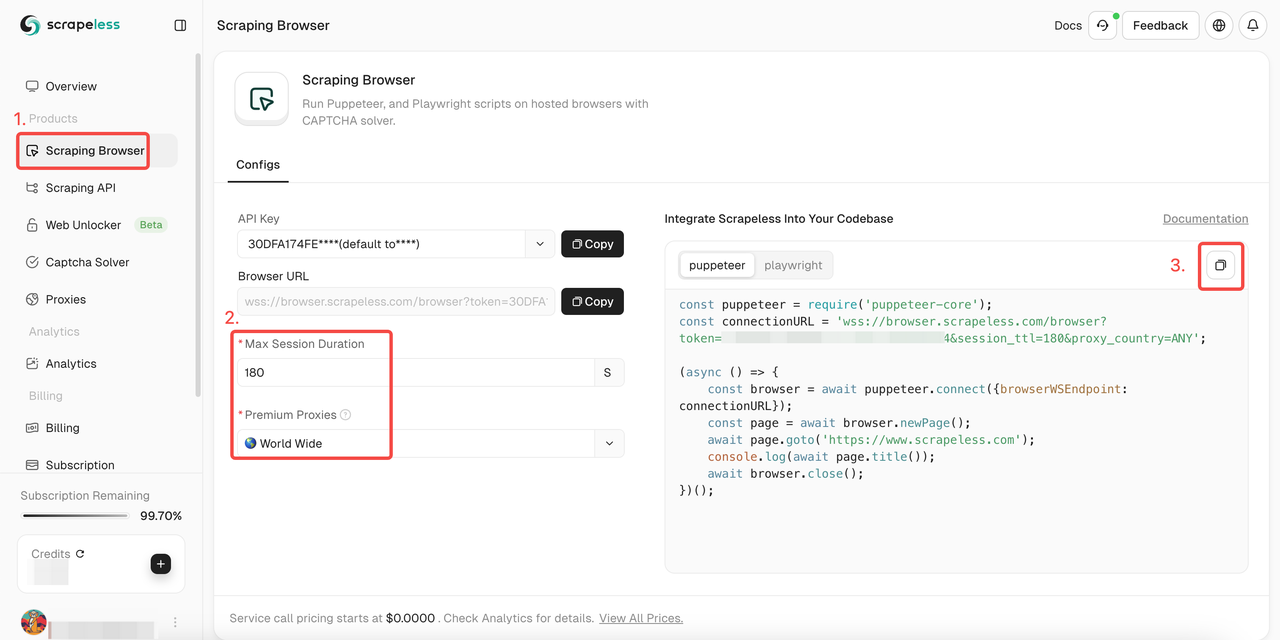
- Etapa 1. Entre em Scrapeless
- Etapa 2. Entre no "Navegador de Raspagem"
- Etapa 3. Defina os parâmetros de acordo com suas necessidades
- Etapa 4. Copie os códigos de amostra para integração em seu projeto:
Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //insira o token da API
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //insira o token da API
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Quer obter mais detalhes? Nosso documento irá ajudá-lo muito!
Puppeteer:
Etapa 1. Instale as bibliotecas necessárias
Primeiro, instale puppeteer-core, uma versão leve do Puppeteer projetada para se conectar a uma instância de navegador existente:
Bash
npm install puppeteer-coreEtapa 2. Escreva código para se conectar ao navegador de raspagem
Em seu código Puppeteer, conecte-se ao Navegador de Raspagem usando o seguinte método:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Dessa forma, você pode aproveitar a infraestrutura do Navegador de Raspagem, incluindo escalabilidade, rotação de IP e acesso global.
Exemplos:
Aqui estão algumas operações Puppeteer comuns após a integração com o Navegador de Raspagem:
- Navegação e extração de conteúdo da página
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- Captura de tela
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Captura de tela salva como example.png');
await browser.close();- Executar scripts personalizados
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Título da página:', result);
await browser.close();Playwright:
Etapa 1. Instale as bibliotecas necessárias
Primeiro, instale playwright-core, uma versão leve do Playwright que se conecta a uma instância de navegador existente:
Bash
npm install playwright-coreEtapa 2. Escreva código para se conectar ao navegador de raspagem
No código Playwright, conecte-se ao Navegador de Raspagem usando o seguinte método:
JavaScript
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Isso permite que você aproveite a infraestrutura do Navegador de Raspagem, incluindo escalabilidade, rotação de IP e acesso global.
Exemplos
Aqui estão algumas operações Playwright comuns após a integração com o Navegador de Raspagem:
- Navegação e extração de conteúdo da página
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- Captura de tela
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Captura de tela salva como example.png');
await browser.close();- Executar scripts personalizados
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Título da página:', result);
await browser.close();8 fatores devem ser considerados ao escolher um raspador web
- Capacidades de extração de dados: Uma boa ferramenta de raspagem web suporta uma variedade de formatos de dados e pode extrair conteúdo de uma variedade de estruturas de páginas da web, incluindo páginas HTML estáticas e sites dinâmicos usando JavaScript.
- Facilidade de uso: Avalie a curva de aprendizado da ferramenta, a interface do usuário e a documentação disponível. As pessoas que usam a ferramenta devem entender a complexidade da ferramenta.
- Escalabilidade: Considere a capacidade da ferramenta de lidar com a extração de dados em larga escala. A escalabilidade em termos de desempenho e a capacidade de acomodar quantidades crescentes de dados ou solicitações são críticas.
- Capacidades de automação: Verifique o grau de automação disponível. Procure por capacidades de agendamento, tratamento automático de CAPTCHAs e a capacidade de gerenciar automaticamente cookies e sessões.
- Rotação de IP e suporte a proxy: A ferramenta deve fornecer suporte robusto de rotação de IP e gerenciamento de proxy para evitar ser bloqueada.
- Tratamento e recuperação de erros: Investigue como a ferramenta gerencia erros, como conexões perdidas ou alterações inesperadas no site.
- Integração com outros sistemas: Determine se a ferramenta se integra perfeitamente a outros sistemas e plataformas, como bancos de dados, serviços em nuvem ou ferramentas de análise de dados. A compatibilidade com APIs também é uma vantagem significativa.
- Limpeza e processamento de dados: Procure capacidades de limpeza e processamento de dados integradas ou facilmente integráveis para simplificar o fluxo de trabalho de dados brutos para informações utilizáveis.
Considerações finais
Os robôs de raspagem web são facilmente identificados pelos sites e levam ao bloqueio! Como obter um processo de extração de dados suave?
O navegador de raspagem Scrapeless integrado ao desbloqueador da web, solucionador de CAPTCHA, IP rotativo e proxy inteligente podem ajudá-lo a evitar facilmente o bloqueio do site e alcançar a raspagem de dados!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


