
2025年のPythonによるWebスクレイピング
Advanced Data Extraction Specialist
データドリブンな意思決定の必要性が高まるにつれ、開発者はBeautiful Soup、Scrapy、SeleniumなどのPythonツールを用いたWebスクレイピングに目を向け、静的および動的Webページから効率的に情報を抽出しています。このステップバイステップのチュートリアルでは、RequestsとBeautiful Soupなどの一般的なライブラリを使用して必要なデータをスクレイピングする方法を学習します。
Webスクレイピングとは
Webスクレイピングは、本質的に、ウェブサイトから大量のデータを自動的に抽出するプロセスです。従来のデータ収集方法とは異なり、Webスクレイピングはコードを利用してWebページと対話し、人間がサイトを閲覧する方法を模倣しますが、はるかに高い効率性と速度を実現します。BeautifulSoup、Scrapy、Seleniumなどの豊富なライブラリエコシステムを持つPythonは、その使いやすさと柔軟性から、Webスクレイピングで最も人気のある言語の1つとなっています。
Webスクレイピングの主な目的は、HTMLやJavaScript形式でよく見られる非構造化Webデータを、CSV、JSON、データベースなどの構造化形式に変換することです。これにより、データを分析したり、さまざまなアプリケーションに統合したりすることができます。このプロセスは、競合他社のデータの抽出と分析、価格動向の追跡、大規模データセットの収集が意思決定に不可欠な、eコマース、金融、市場調査、SEOなどの業界で特に役立ちます。
Python Webスクレイピング入門
Webスクレイピングは、Webから公開されているデータを抽出するための必須スキルであり、Pythonはそのための最も人気のある言語の1つです。PythonによるWebスクレイピングでは、通常、最初にウェブサイトにHTTPリクエストを送信し、HTMLコンテンツを取得してから、それを解析して必要なデータを抽出します。
手順は以下のとおりです。
1. リクエストの送信
スクレイピングを開始するには、まずターゲットウェブサイトにリクエストを送信する必要があります。これは一般的にPythonのRequestsライブラリを使用して行われ、WebサーバーにHTTPリクエストを送信します。
python
import requests
url = 'https://example.com'
response = requests.get(url)
print(response.content)2. データの解析
Webページを取得したら、次のステップはHTMLコンテンツを解析して関連データを抽出することです。
python
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.title.string
print(title)3. 動的コンテンツの処理
多くの最新のウェブサイトは、コンテンツを動的にロードするためにJavaScriptに依存しています。つまり、必要なデータは初期のHTMLソースには表示されない可能性があります。このような場合、Seleniumは優れたツールです。これは実際のブラウザをシミュレートし、動的ページと対話できます。
python
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://example.com')
content = driver.page_sourceこれらの簡単な手順で、基本的なWebスクレイピングを開始できます。次に、詳細な紹介として、「Pythonを使用したウェブサイトのスクレイピング方法(ステップバイステップ)」を説明します。
Pythonを使用したウェブサイトのスクレイピング方法(ステップバイステップ)
Pythonを使用してデータスクレイピングツールを作成するには、次のツールをダウンロードしてインストールする必要があります。
-
Python: https://www.python.org/downloads/ これはPythonを実行するためのコアソフトウェアです。下記の図のように公式ウェブサイトから必要なバージョンをダウンロードできます。ただし、最新バージョンをダウンロードしないことをお勧めします。最新バージョンから1〜2つ前のバージョンをダウンロードできます。
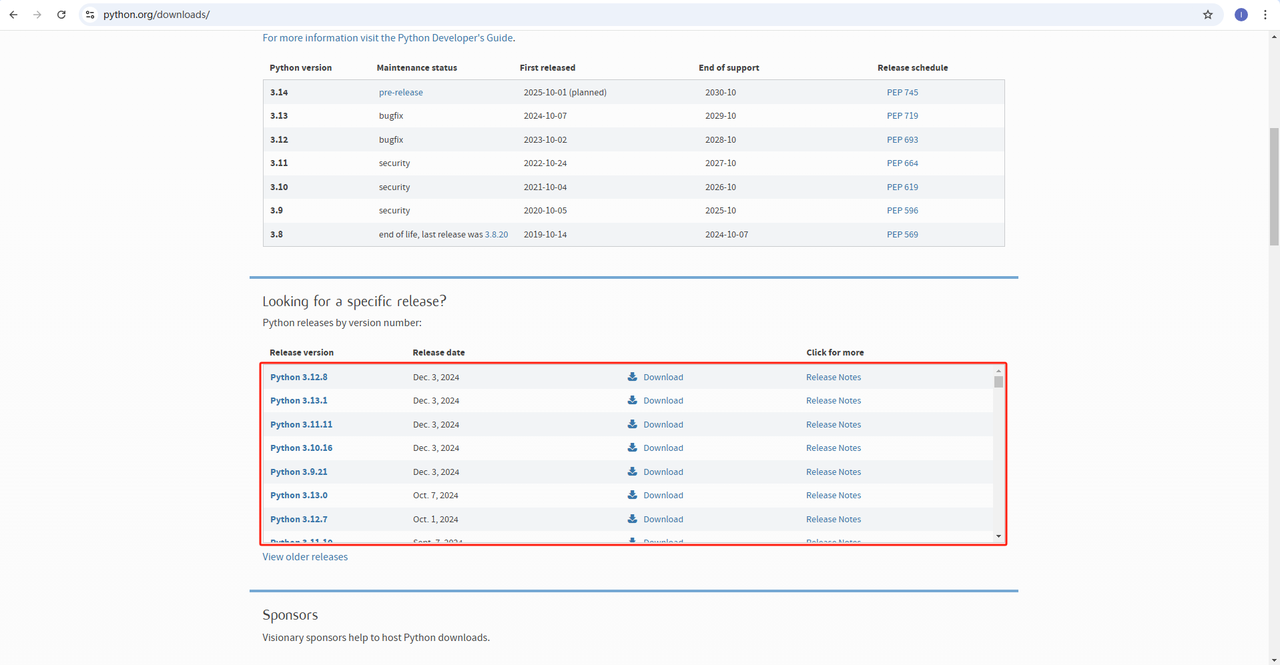
-
Python IDE: PythonをサポートするIDEであればどれでも構いませんが、Python用に設計されたIDE開発ツールであるPyCharmをお勧めします。PyCharmのバージョンについては、無料のPyCharm Community Editionをお勧めします。
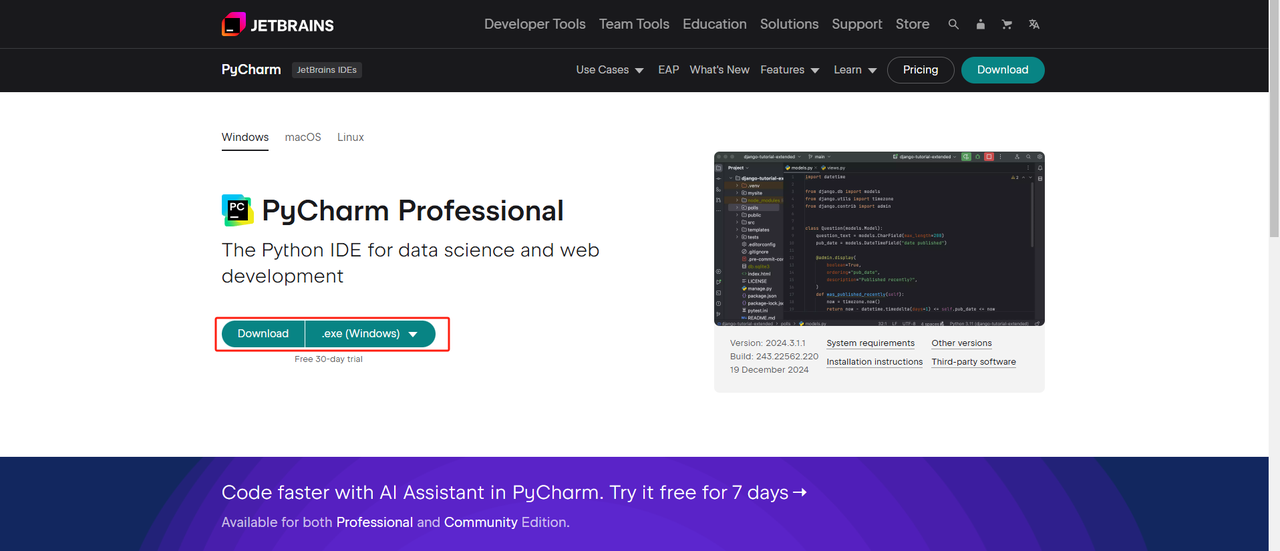
-
Pip: Python Package Indexを使用して、プログラムの実行に必要なライブラリを1つのコマンドでインストールできます。
注: Windowsユーザーの場合は、インストールウィザードで「Add python.exe to PATH」オプションを選択することを忘れないでください。これにより、WindowsはターミナルでPythonとコマンドを使用できるようになります。Python 3.4以降にはデフォルトで含まれているため、手動でインストールする必要はありません。
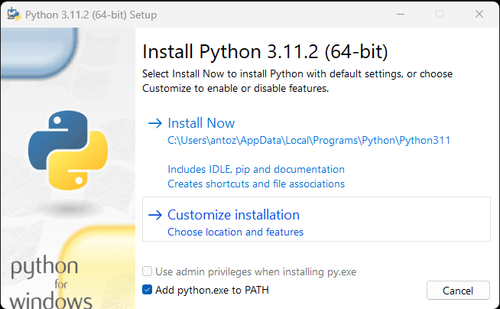
上記の手順により、Pythonを使用したデータクロールのための環境が設定されました。次に、インストールしたPycharmを使用してウェブサイトのデータをクロールできます。
ステップ1: PyCharmを起動し、メニューバーで[ファイル] > [新規プロジェクト...]を選択します。
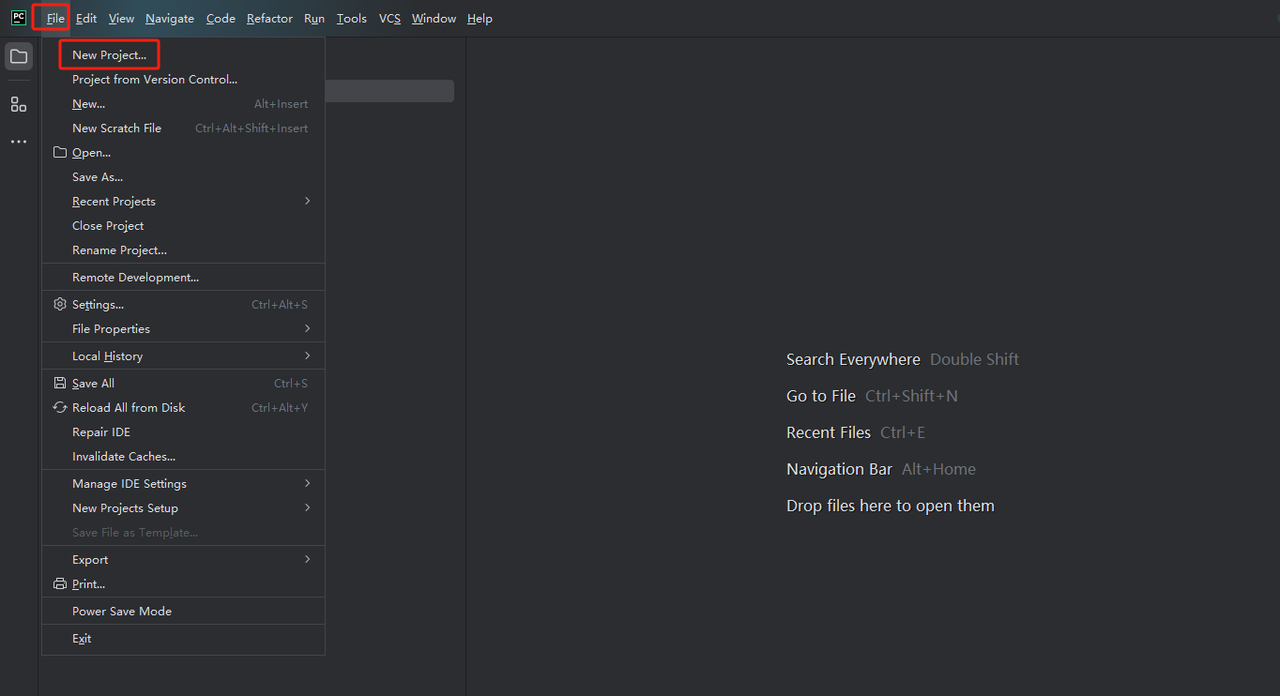
ステップ2: 次に、ポップアップウィンドウで、左側のメニューから[Pure Python]を選択し、下記のようにプロジェクトを設定します。
注: 下記の赤枠で、環境設定の最初のステップでダウンロードしたPythonのインストールパスを選択します。
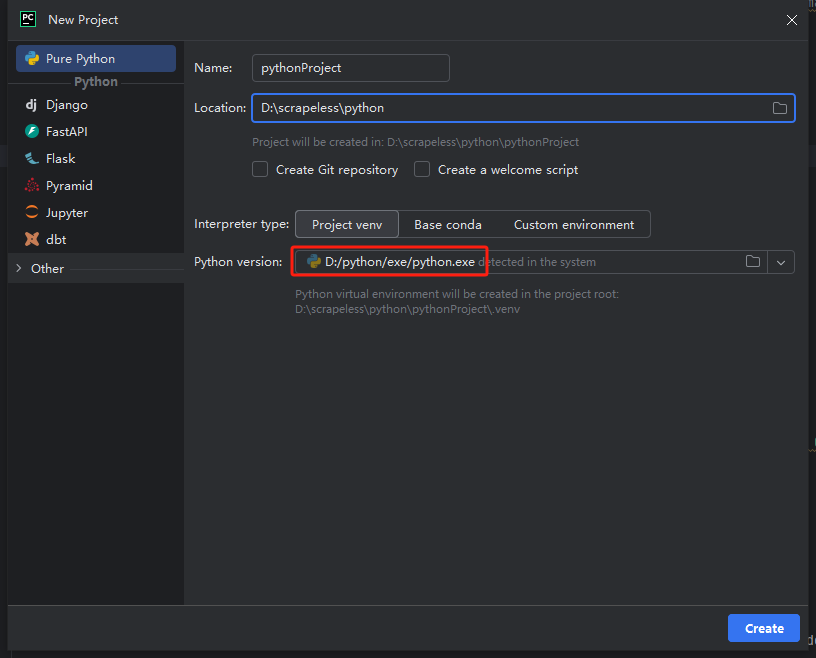
ステップ3: python-scraperというプロジェクトを作成し、フォルダにmain.pyのウェルカムスクリプトを作成するオプションを選択して、[作成]ボタンをクリックします。PyCharmがプロジェクトを設定するのにしばらく時間がかかると、次のような画面が表示されます。
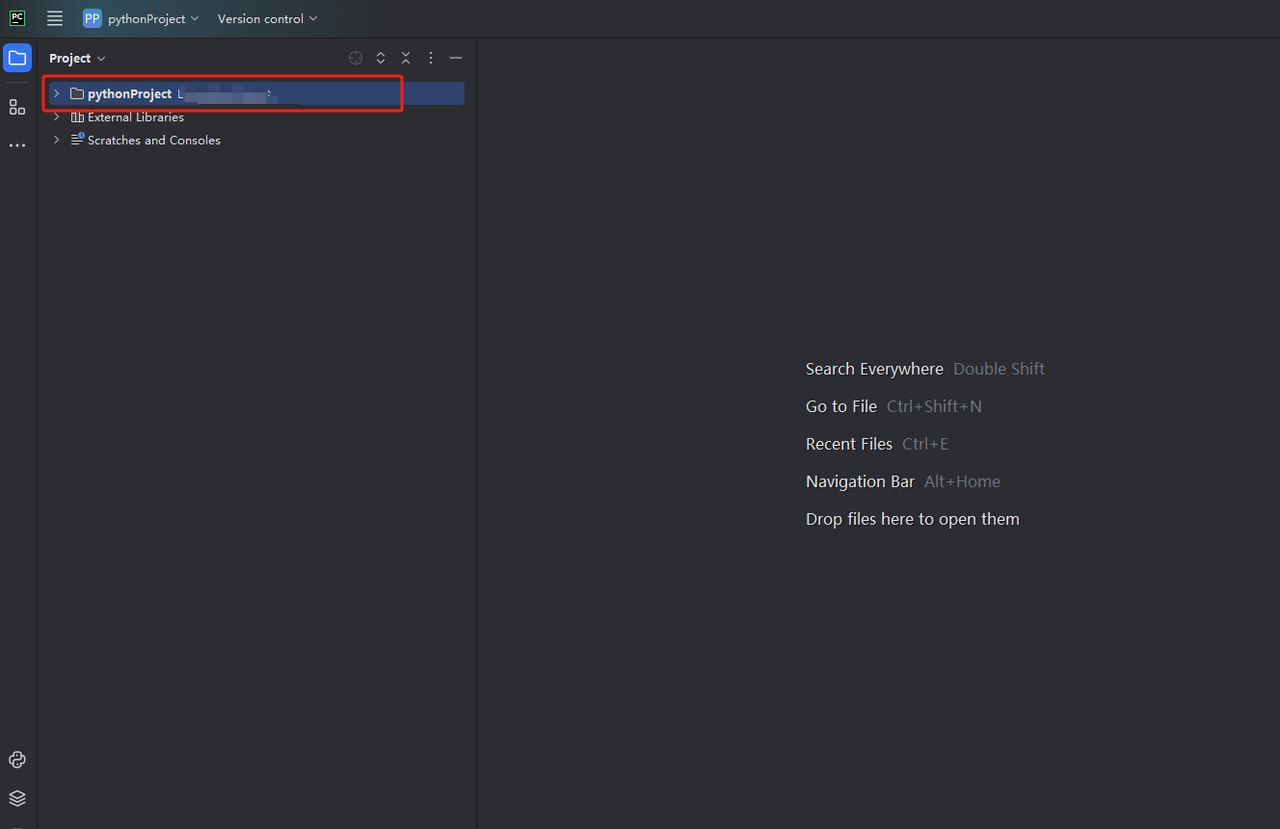
ステップ4: 次に、右クリックして新しいPythonファイルを作成します。
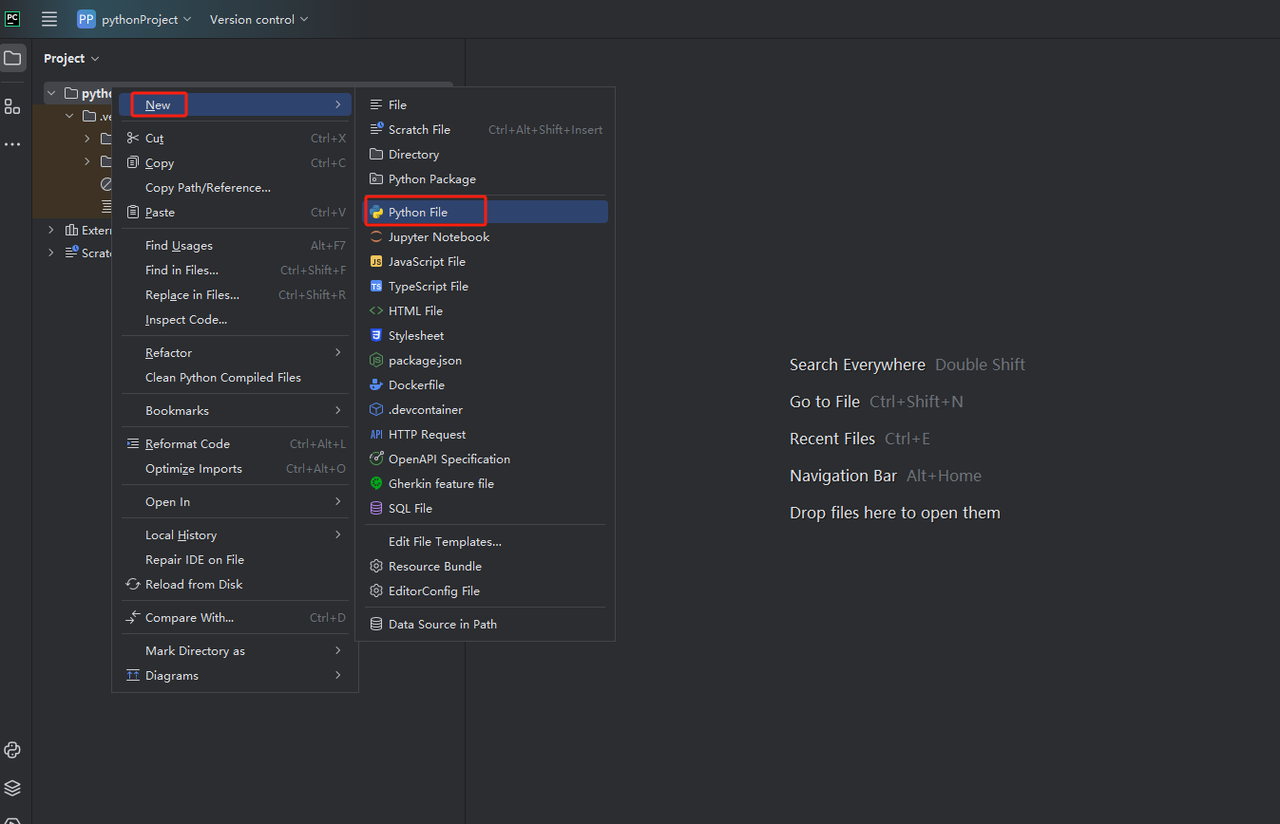
現在、データクロールのための環境が設定されました。次のステップは、Webページで必要なデータをクロールする方法です。
1. データを実際にクロールする前に、URLの理解、パラメータの観察など、いくつかの準備作業を行う必要があります。ブラウザの組み込み開発者ツールを使用して、これらの点を学習および実践できます。Amazonを例に、特定の製品の価格と必要なその他のデータをクロールしてみましょう。
https://www.amazon.com/s?k=computer&page=3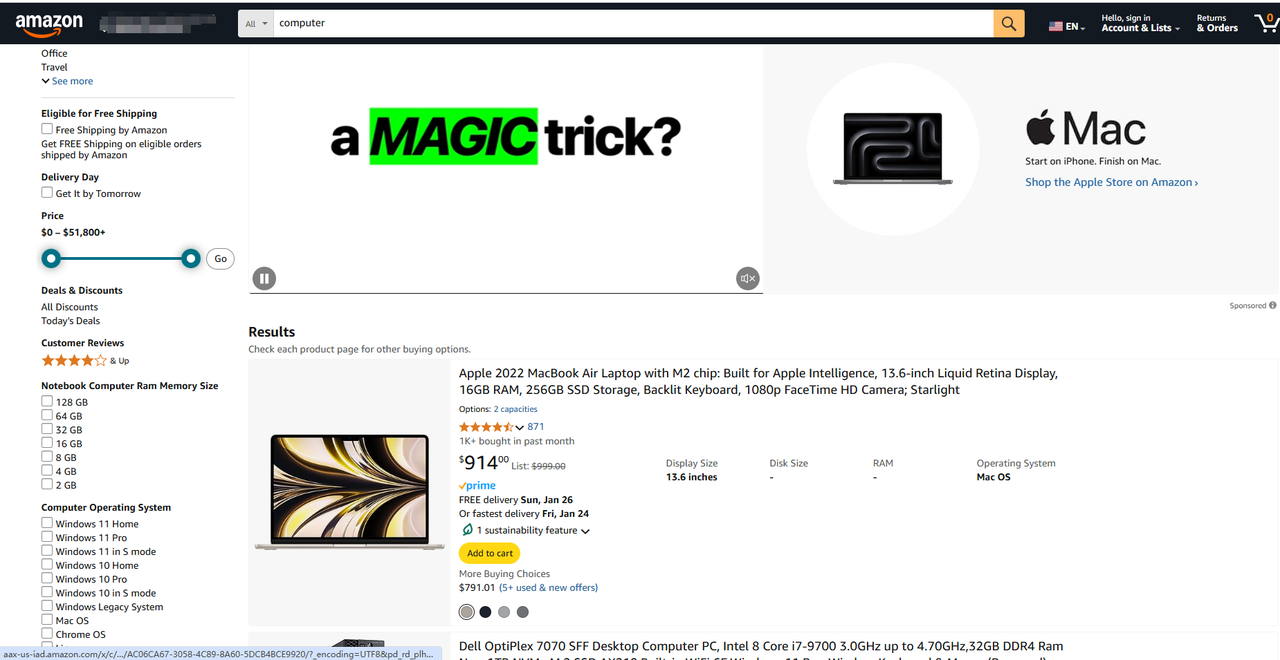
これらのURLは2つの主要な部分に分解できます。
- 基本URL: サイトのストア部分へのパス。ここでは
https://www.amazon.com/s?k=computer&page=3です。 - 特定のページの場所: 特定の製品へのパス。URLは
.html、.phpで終わるか、拡張子がない場合があります。
基本URLはサイト上のすべての製品で同じです。各ページの違いはURLの後半部分であり、サーバーが返す製品ページを指定する文字列が含まれています。通常、同じタイプのページのURLは全体として同様の形式になっています。
さらに、URLには追加情報が含まれる場合があります。
- パスパラメータ: これらはRESTfulメソッドで特定の値を取得するために使用されます(例:
https://www.example.com/users/14では、14はパスパラメータです)。 - クエリパラメータ: これらは疑問符(?)の後にURLの末尾に追加されます。通常、検索を実行するときにサーバーに送信されるフィルター値をエンコードします(例:
https://www.example.com/search?search=blabla&sort=newestでは、search=blablaとsort=newestはクエリパラメータです)。
クエリパラメータ文字列には次のものが含まれています。 - ?: これは始まりを示します。
- key=value:
&で区切られたパラメータのリスト。keyはパラメータの名前、valueはその値を示します。クエリ文字列には、&文字で区切られたキーと値のペアでパラメータが含まれています。
つまり、URLはHTMLドキュメントの単純な位置文字列以上のものです。サーバーがクエリを実行し、特定のデータでページを埋めるために使用できるパラメータ情報も含まれる場合があります。
この例では、3はパスパラメータであり、computerは検索クエリの値です。このURLは、サーバーにページ付き検索クエリを実行させ、computerという文字列を含むすべての結果を取得し、3ページ目の結果のみを返すように指示します。
2. ウェブサイトに慣れたら、次のステップはページのHTMLコードを詳しく調べ、その構造とコンテンツを理解して、そこからデータを抽出する方法を理解することです。
すべての最新のブラウザには高度な開発者ツールのセットが付属しており、ほとんどが同じ機能を提供しています。これらのツールを使用すると、WebページのHTMLコードを調べ、操作できます。このPython Webスクレイピングチュートリアルでは、ChromeのDevToolsが動作します。
HTML要素を右クリックし、[検証]を選択してDevToolsウィンドウを開きます。ウェブサイトで右クリックメニューが無効になっている場合は、次の手順を実行します。
- macOSの場合:メニューバーで[表示] > [開発] > [開発ツールを選択]を選択します。
- WindowsおよびLinuxの場合:右上隅にある⋮メニューボタンをクリックし、[その他のツール] > [開発者ツール]オプションを選択します。
これにより、Webページのドキュメントオブジェクトモデル(DOM)の構造を検査できます。これにより、ソースコードをより深く理解するのに役立ちます。DevToolsセクションで[要素]オプションを入力してDOMにアクセスします。
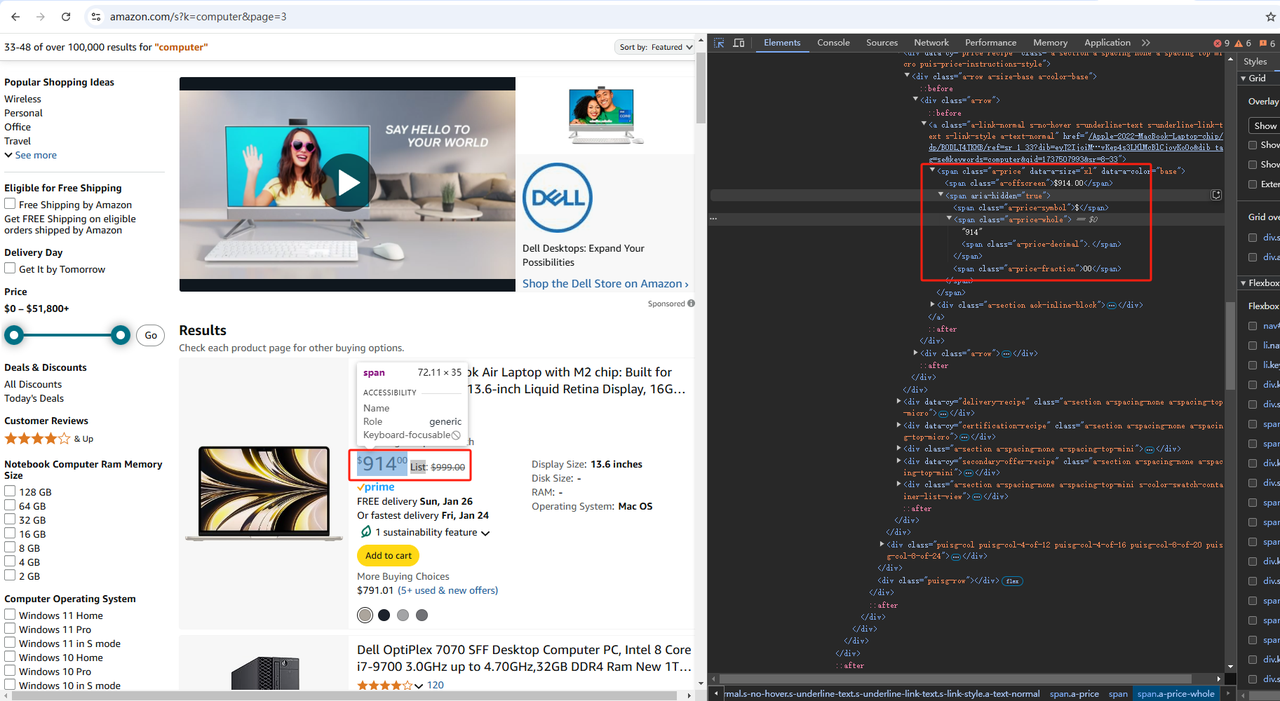
Amazonでは、開発者ツールを開いた後、上記の図のように「要素」をクリックし、「要素」の左側にある矢印を使用して、データを取得したいページ上の任意の場所をクリックします。「要素」内のHTMLソースコードに、必要なデータの場所が表示されます。次に、それが配置されているタグに従ってデータをクロールできます。
DOMとHTMLの違いがわかりにくい場合は、次のとおりです。
- HTMLコードは、開発者が記述したWebドキュメントのコンテンツを表します。
- DOMは、ブラウザによって作成されたHTMLコードの動的なメモリ表現です。JavaScriptでは、ページのDOMを操作して、そのコンテンツ、構造、スタイルを変更できます。
3. 次の場所からデータをクロールするとします。
例
https://www.amazon.com/s?k=computer&page=3まず、ターゲットページのHTMLコードを取得する必要があります。つまり、ページURLに関連付けられたHTMLドキュメントをダウンロードする必要があります。これを行うには、Pythonのrequestsライブラリを使用します。
PyCharmプロジェクトの[ターミナル]タブで、次のコマンドを実行してrequestsをインストールします。
ターミナル
bash
pip install requestsscraper.pyファイルを開き、次のコード行で初期化します。
scrape.py
python
import requests
# HTTP GETリクエストでHTMLドキュメントをダウンロード
response = requests.get("https://www.amazon.com/s?k=computer&page=3")
# HTMLコードを出力
print(response.text)このコードスニペットはrequestsの依存関係をインポートします。次に、get()関数を使用してターゲットページURLにHTTP GETリクエストを実行し、HTMLドキュメントを含むレスポンスのPython表現を返します。
ページのリクエストURLをここに直接貼り付けることで、完全なPythonリクエストコードを取得することもできます。https://curlconverter.com/python/
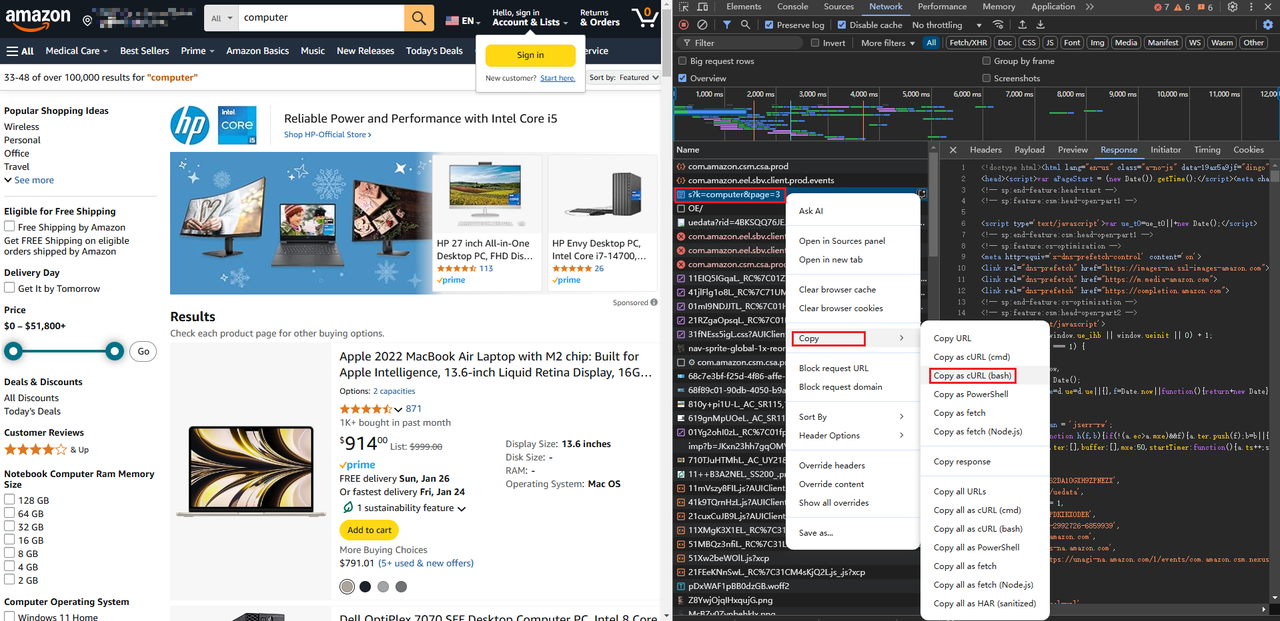
python
import requests
cookies = {
'session-id': '140-2992726-6859939',
'session-id-time': '2082787201l',
'i18n-prefs': 'USD',
'ubid-main': '132-6184525-8448226',
'lc-main': 'en_US',
'skin': 'noskin',
}
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9',
'cache-control': 'no-cache',
'device-memory': '8',
'downlink': '1.5',
'dpr': '1',
'ect': '3g',
'pragma': 'no-cache',
'priority': 'u=0, i',
'rtt': '300',
'sec-ch-device-memory': '8',
'sec-ch-dpr': '1',
'sec-ch-ua': '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-ch-ua-platform-version': '"10.0.0"',
'sec-ch-viewport-width': '1070',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36',
'viewport-width': '1070',
}
params = {
'k': 'computer',
'page': '3',
}
response = requests.get('https://www.amazon.com/s', params=params, cookies=cookies, headers=headers)
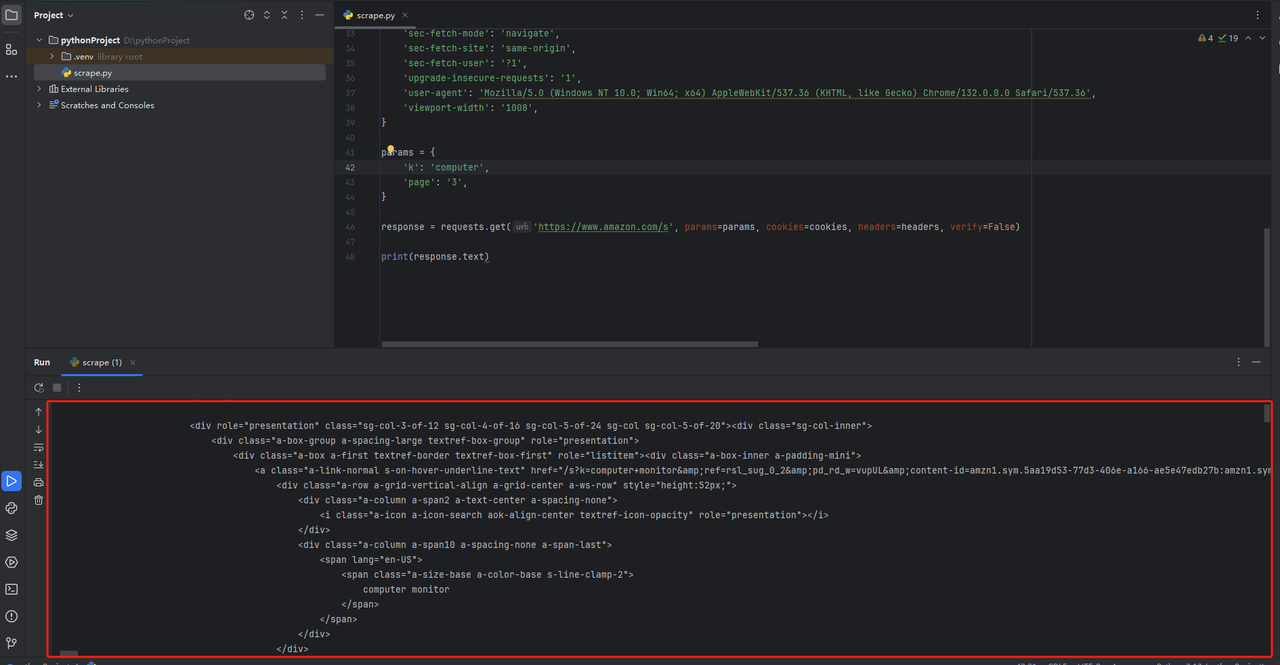
print(response.text)pycharmで、コードの最後にprint(response.text)を追加します。コードを実行すると、以下のようなHTMLページコードが表示されます。
⚠️ よくある間違い: エラー処理ロジックの忘れ!
サーバーへのGETリクエストは、さまざまな理由で失敗する可能性があります。サーバーが一時的に利用できない場合、URLが間違っている場合、またはIPがブロックされている場合があります。そのため、次のようにエラーを処理することをお勧めします。
response = requests.get("https://www.amazon.com/s?k=computer&page=3")
レスポンスが2xxの場合
if response.ok:
スクレイピングロジック…
それ以外の場合
エラーレスポンスのログ出力
4xxまたは5xxの場合
print(response)
これにより、リクエストにエラーが発生した場合でもスクリプトがクラッシュせず、2xxレスポンスでのみ実行が継続されます。
4. Beautiful SoupによるHTMLコンテンツの解析
前のステップでは、サーバーからHTMLドキュメントを取得しました。見てみると、長いコード文字列が表示され、それを理解する唯一の方法は、HTML解析によって必要なデータを抽出することです。
Beautiful SoupはXMLとHTMLコンテンツを解析するためのPythonライブラリであり、HTMLコードを探索するためのAPIを提供します。つまり、HTML要素を選択し、そこからデータを簡単に抽出できます。
ライブラリをインストールするには、ターミナルで次のコマンドを実行します。
bash
pip install beautifulsoup4次に、このようにして取得したコンテンツリクエストを解析します。
python
import requests
from bs4 import BeautifulSoup
# ターゲットページをダウンロード
response = requests.get("https://www.amazon.com/s?k=computer&page=3")
# ページのHTMLコンテンツを解析
soup = BeautifulSoup(response.content, "html.parser")BeautifulSoup()コンストラクタは、いくつかのコンテンツと使用するパーサーを指定する文字列を受け取ります。「html.parser」は、Beautiful SoupにHTMLパーサーを使用するように指示します。
⚠️ よくある間違い:
response.contentではなくresponse.textをBeautifulSoup()に渡すこと。
contentオブジェクトの属性は、レスポンスの生のバイト形式でHTMLデータを保持しており、text属性に格納されているテキスト表現よりもデコードが容易です。文字エンコーディングの問題を回避するには、response.contentを使用するのが最適です。
response.text BeautifulSoup()
ウェブサイトには多くの形式でデータが含まれていることに注意してください。単一の要素、リスト、テーブルはほんの一例です。Pythonスクレイピングツールを効果的にしたい場合は、さまざまな状況でBeautiful Soupを使用する方法を知る必要があります。
下の図のように、検索したデータでは、特定の製品のデータ情報を取得したい場合、親タグから層ごとに解析し、価格、製品名などを取得する必要がある場合があります。
[画像]
Beautiful Soupは、DOMからHTML要素を選択するためのさまざまなメソッドを提供しており、その中でidフィールドは単一の要素を選択する最も効果的なメソッドです。名前が示すように、idフィールドはページ上のHTMLノードを一意に識別します。しかし、これは私たちがクロールしたいウェブサイトのHTMLページのデザインにも依存します。idがない場合は、できるだけ一意なコンテンツを使用して必要なデータを取得する必要があるかもしれません。
上記の図のdata-asin属性は、製品の一意のコードを表しています。role属性と組み合わせることで、この製品に対応するHTML内のコードを取得できます。
python
target_div = soup.find('div', attrs={'data-asin': 'B0DJXW94BL', 'role': 'listitem'})idを持つタグがある場合は、次のようなコードを書くことができます。
python
product_search_element = soup.find(id="woocommerce-product-search-field-0")find()を使用してタグを検索し、必要なデータを取得します。「find()」メソッドの詳細な使用方法は以下のとおりです。
- タグによる検索: パラメータなしで
find()関数を使用します。
python
# ページ上の最初の<h1>要素を取得
h1_element = soup.find("h1")- クラスによる検索:
class_パラメータを使用したfind()
python
# "search_field"クラスを持つページ上の最初の要素を検索
search_input_element = soup.find(class_="search_field")- 属性による検索:
attrsパラメータを使用したfind()
python
# `name="s"` HTML属性を持つページ上の最初の要素を検索
search_input_element = soup.find(attrs={"name": "s"})CSSセレクタとselect()、select_one()を使用してHTMLノードを取得することもできます。
python
# "input.search-field" CSSセレクタで識別される最初の要素を検索
search_input_element = soup.select_one("input.search-field")テキストコンテンツHTML要素では、get_text()メソッドを使用してテキストを抽出します。
python
h1_title = soup.select_one(".beta.site-title").getText()
print(h1_title)⚠️ よくある間違い:
Noneのチェックがないこと。
find()とselect_one()は、必要な要素が見つからない場合にNoneを返します。ページは時間の経過とともに変化するため、常に次のようなNone以外のチェックを行う必要があります。
python
product_search_element = soup.find(id="woocommerce-product-search-field-0")
# ページにproduct_search_elementが存在することを確認してから、そのデータにアクセスする
if product_search_element is not None:
placeholder_string = product_search_element["placeholder"]上記の例では、特定の製品のHTMLコードを見つけることができます。製品名など、より正確なデータを返す場合は、同じ方法を使用して、最初に製品名が配置されているタグを見つけ、次に取得した製品情報のサブタグから取得します。
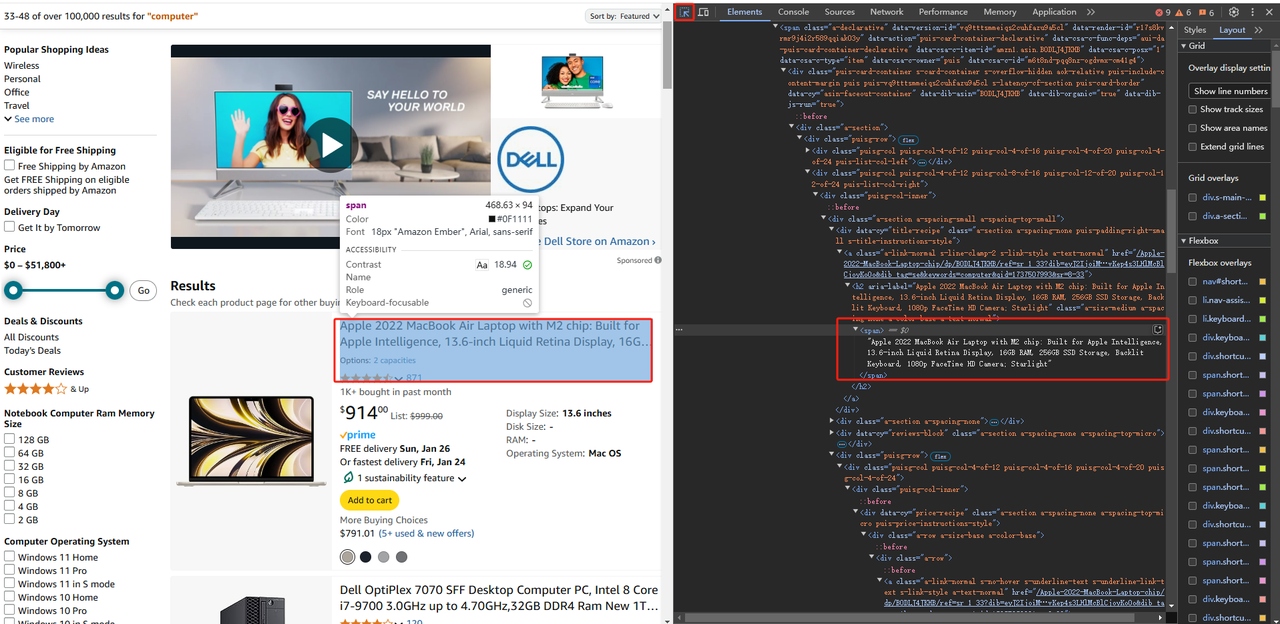
製品名が「span」タグにあることを観察することにより、「a」タグの下の「h2」タグの下の「span」タグを取得することで、タイトルテキストデータを取得できます。
python
if target_div:
a_tags = target_div.find_all('a')
for a_tag in a_tags:
h2_tag = a_tag.find('h2')
if h2_tag:
span_tag = h2_tag.find('span')
if span_tag:
print(span_tag.get_text())
else:
print("No matching div found.")注: 異なるWebページには複数の「a」、「h2」およびその他の同様のタグ要素が存在する可能性があるため、それらを使用する際には、比較的固有のタグ属性を使用してデータを取得するのが最適です。
上記は、Pythonを使用してWebページデータをクロールする方法に関する小さなデモです。より熟練して関連データをより正確に取得するには、多くの練習が必要であり、そうでなければ自分の時間を無駄にするだけです。
より簡単なクロール方法の推奨事項:Scrapeless Scraping API
Pythonを使用したスクレイピングは柔軟性があり強力な方法ですが、通常は多くのコードを記述し、プロキシやIP管理などの複雑な技術的な詳細に対処する必要があります。スクレイピングプロセスを簡素化したい人のために、Scrapeless Scraping APIはより便利なソリューションを提供します。
-
🚀 AI駆動の機能により、Scrapelessを使用すると、複雑なコードを記述したり、プロキシやIP管理などの問題に対処したりすることなく、公開データを簡単に抽出できます。
-
🌍 8,000万を超える実際のIPまたはプライベートデータセンターIPにアクセスする必要がある場合でも、Scrapelessは効率的で信頼性の高いデータスクレイピングサービスを提供できます。
-
⚡ シンプルなAPIインターフェースにより、統合が非常に簡単になり、ユーザーは簡単な構成でスクレイピングタスクを迅速に開始でき、多くの開発時間と労力を節約できます。
従来のスクレイピング方法の複雑さを回避したいユーザーにとって、Scrapelessは間違いなく推奨に値する、より便利なオプションです。
データ抽出のためのScrapeless Scraping APIの使用方法:
ステップ1. Scrapelessダッシュボードにログインし、「Amazon」に移動します。
ステップ2. スクラップする要件に応じて、対応するURLを入力し、対応するアクションを設定して、[スクレイピング開始]をクリックします。
ステップ3. クロールの結果を取得してエクスポートします。
次が必要になる場合もあります。
Pythonを使用したGoogleトレンドデータのスクレイピング方法
PythonでのBeautifulSoupによるWebスクレイピングの方法
Amazon検索結果データのスクレイピング方法:Pythonガイド2025
プロジェクトへのScrapelessのシームレスな統合
プロジェクトにScrapelessを統合する必要がある場合は、完成したドキュメントをクリックして表示することもできます。
Product
python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Seller
python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "",
"action": "seller"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Keywords
python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"action": "keywords",
"keywords": "iPhone 12",
"page": "5",
"domain": "com"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Pythonを使用したWebスクレイピングのベストプラクティス
Pythonを使用したWebスクレイピングは、効率性、倫理、法的遵守のバランスが必要です。PythonプロジェクトのWebスクレイピングに関するベストプラクティスをいくつか紹介します。
1. サイトの利用規約とrobots.txtファイルに敬意を払う
Webスクレイピングの最も重要な側面の1つは、サイトの利用規約とrobots.txtファイルに敬意を払うことです。スクレイピングを開始する前に、これらのファイルを確認して、サイトのルールに違反していないことを必ず確認してください。これにより、法的問題を回避し、スクレイピング活動がウェブサイトのガイドラインに準拠していることを確認できます。
2. サイトのサーバーへの負荷を最小限にする
もう1つのベストプラクティスは、サイトのサーバーへの負荷を最小限にすることです。データを過度に積極的にスクレイピングすると、サーバーが過負荷になり、サイトのパフォーマンスに悪影響を与える可能性があり、ブロックされる可能性があります。PythonのWebスクレイピングツールを使用する際は、レート制限とクロール遅延などのテクニックを実装して、スクレイピング活動が中断を引き起こさないようにしてください。
3. 収集したデータが倫理的かつ安全に処理されていることを確認する
最後に、収集したデータが倫理的かつ安全に処理されていることを確認してください。データプライバシーはこれまで以上に重要であり、収集するデータのユーザーのプライバシーを尊重することが重要です。倫理的なWebスクレイピングのPythonプラクティスを採用することで、運用をコンプライアンスに維持できるだけでなく、業界内の信頼も構築できます。GDPRなどのプライバシー規制に従って、安全な方法でデータの保存と処理を行うようにしてください。
高度なWebスクレイピング技術
ウェブサイトがより動的になり、アンチスクレイピング技術が継続的にアップグレードされるにつれて、2025年のWebスクレイピング技術では、開発者は法的および倫理的な課題に対処しながら効率性を確保するために、一連の高度なスキルを習得する必要があります。現代のWebスクレイピングのための高度なテクニックをいくつか紹介します。
- ブラウザのシミュレーションと自動化技術を使用する
多くのウェブサイトは現在、ブラウザ自動化技術を使用してユーザーエクスペリエンスを向上させていますが、これによりデータスクレイピングにも新たな課題が生じています。例えば、特定の反スクレイピング対策を回避するためにユーザー行動をシミュレートすることなどです。PuppeteerやPlaywrightなどのブラウザ自動化ツールを使用すると、ユーザーインタラクションをシミュレートでき、インタラクションが必要なコンテンツ(検証コードやログインプロセスなど)のクロールに特に役立ちます。従来の静的ウェブスクレイピング方法と比較して、この技術は最新のウェブサイトの複雑さにうまく対処できます。
- プロキシプールとIPローテーションの活用
大規模なスクレイピングプロジェクトでは、ターゲットウェブサイトによってブロックされないようにすることが長年の課題です。IPブロックを回避するために、開発者は通常、複数のIPをローテーションさせることで反スクレイピングメカニズムを回避するプロキシプールを使用します。Scrapelessのような自動化プラットフォームを使用すると、多数のプロキシの管理が容易になり、IPブロックのリスクを軽減し、データスクレイピングの安定性を確保できます。
- AI駆動型インテリジェントデータ抽出
人工知能はデータスクレイピング技術を前進させています。AIは、特定のデータポイントの識別と抽出を支援するだけでなく、複雑なページ内の画像、テキスト、構造化データも識別できます。機械学習アルゴリズムは、画像認識や感情分析に使用され、スクレイピングの精度と正確性を向上させることができます。
- APIを使用してスクレイピング効率を向上させる
多くの企業にとって、専門のクローラーAPIを使用することは、データスクレイピングプロセスを簡素化する効率的な方法です。ScrapelessなどのAPIは、強力なプロキシ管理、CAPTCHAバイパス、IPローテーション機能を提供し、手動管理の負担を効果的に軽減しながら、データスクレイピングの成功率を高めることができます。
要約すると、2025年のウェブスクレイピング技術は、動的なウェブサイト、大規模なデータ抽出、反クロール技術の課題に対処するために、従来のスクレイピングツールとより高度な技術を組み合わせる必要があります。ScrapelessのようなAPIソリューションを使用すると、スクレイピングプロセスをより効率的で信頼性が高く、スケーラブルなものにすることができ、開発者は時間と労力を節約し、技術的な困難を軽減できます。
Scrapelessを使ったウェブスクレイピング--わずか3分
複雑な設定や反スクレイピング対策はもう気にしないでください。Scrapelessを使えば、プロキシ、CAPTCHAのバイパスを簡単に管理し、スクレイピングプロジェクトを容易に拡張できます。これまで以上に信頼性が高く、高速で安全なデータ抽出を体験してください。今すぐScrapelessを試してみましょう!
Pythonを使ったウェブスクレイピングに関するよくある質問
1. ウェブスクレイピングは合法ですか?
ウェブスクレイピングの合法性は、ウェブサイトの利用規約や現地の法律など、さまざまな要因によって異なります。コンプライアンスを確保するために、スクレイピングする前に、サイトのrobots.txtファイルと許容利用ポリシーを確認することが重要です。無許可のスクレイピングは法的責任を負う可能性があるため、倫理的に取り組むのが最善です。
さらに、Scrapelessのようなツールを使用すると、スクレイピング中に倫理的および法的基準への準拠が確保されます。
2. ウェブスクレイピングにおける主な課題は何ですか?
ウェブスクレイピングには、CAPTCHA、IPブロック、動的コンテンツの読み込みなどの反スクレイピング対策への対処、データ抽出を困難にする複雑な構造のウェブサイトなど、いくつかの課題があります。
3. ウェブサイトをスクレイピング中にCAPTCHAをどのように処理しますか?
多くのウェブサイトは、自動スクレイピングを防ぐためにCAPTCHAを使用しています。CAPTCHAをバイパスするには、CAPTCHA解決サービスを統合するか、Seleniumなどのツールを使用して人間のような行動を模倣できます。ただし、より効率的なエクスペリエンスを得るために、Scrapelessのようなプラットフォームは多くの場合、CAPTCHAを自動的に管理する機能を提供し、そのようなサイトのスクレイピングの複雑さを軽減します。
まとめ:Pythonを使ったウェブスクレイピング
ウェブスクレイピングの需要が高まるにつれて、Pythonを使ったウェブスクレイピングは最も重要な手段の1つであり続けています。
しかし、高度な反ボット対策のためにスクレイピングがますます複雑になるにつれて、よりスマートで効率的なソリューションの必要性が明らかになっています。これが、Scrapelessのようなツールが活躍するところです。Scrapelessの最先端のスクレイピングAPIを活用することで、スクレイピングプロセスを合理化し、CAPTCHAをバイパスし、通常は手動コーディングを遅らせる一般的な障害を回避できます。Scrapelessを使用すると、高いデータ精度を維持しながら、最小限の労力でスクレイピングプロジェクトを拡張できます。
スクレイピングの課題に邪魔されないようにしましょう - 今すぐScrapelessを試して、ウェブスクレイピングを次のレベルに引き上げましょう。
ウェブスクレイピングのプロセスを簡素化したいですか?
今すぐScrapelessを始めましょう!無料トライアルを利用して、当社の強力なツールが時間と労力を節約する方法を発見してください。コーディングスキルは必要ありません—効率的で、手間のかからないスクレイピング!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


