
2025年版 ウェブデータ収集ツール トップ5
Senior Web Scraping Engineer
ウェブデータ収集の目的は、元々は散在し、直接利用しにくい情報を抽出し、それを有用なデータ形式に整理することです。これにより、ビジネス上の課題への回答、アルゴリズムの改善、そして他社との競争に役立ちます。
ウェブサイトから簡単かつ正確にデータを収集する方法とは?
このブログでは、5つの優れたウェブデータ収集ツールを紹介します。読んで、最適なツールを見つけてください!
トップ5ウェブデータ収集ツール
- #1. Scrapeless:包括的なデータコレクター。
- #2. Mention:便利なニュース監視とキーワードリマインダーツール。
- #3. SurveyMonkey:顧客、従業員、市場のインサイトを簡単に収集。
- #4. Lead411:正確な営業インテリジェンスプラットフォーム。
- #5. Magpi:完全機能を備えたモバイルファーストのデータ収集システム。
ウェブデータ収集とは?
ウェブデータ収集は、ウェブスクレイピングやデータクロールとしても知られており、自動化されたツールを通じてインターネットから構造化データまたは非構造化データを抽出するプロセスを指します。
ウェブデータ収集は通常、クローラーを使用してユーザーがウェブサイトを訪問するのをシミュレートし、ウェブページのコンテンツを解析することで必要なデータを抽出します。
例えば、eコマースプラットフォームの商品価格、在庫情報、ユーザーレビューを収集したり、ソーシャルメディアのトレンドトピックやユーザーインタラクションデータを収集することができます。このデータは、市場調査、競合分析、ビジネス上の意思決定、SEO最適化、または人工知能のトレーニングモデルなど、さまざまなシナリオで使用できます。
企業はウェブデータ収集によって何を達成したいと考えていますか?
ウェブデータ収集により、企業はオンラインで利用可能な膨大な情報を活用して、実行可能なインサイトを得て戦略的な意思決定を推進することができます。
このデータを体系的に収集および分析することにより、企業はいくつかの主要な目標を達成することを目指しています。
- 市場分析とトレンド予測
企業はウェブデータを使用して、業界のトレンド、消費者の好み、市場の需要を監視します。これにより、新たなトレンドに適応し、製品やサービスをそれに合わせて調整することで、競合他社に先んじることができます。
- 競合インテリジェンス
競合他社のウェブサイト(価格、製品提供、マーケティング戦略など)からデータを集めることで、市場におけるギャップを特定し、独自の戦略を最適化し、競争優位性を維持することができます。
- 顧客インサイト
ウェブデータ収集により、企業は顧客の行動、レビュー、フィードバックを分析できます。これにより、消費者の不満点、好み、期待を理解し、最終的に顧客満足度とロイヤルティを高めることができます。
- ダイナミックプライシング戦略
eコマースプラットフォームや小売業者は、リアルタイムのウェブスクレイピングを使用して競合他社の価格を追跡し、自社の価格を動的に調整することで、利益率を最大化しながら競争力を維持することができます。
- コンテンツ最適化
企業は、人気のあるキーワード、トレンドトピック、オーディエンスエンゲージメント指標に関するデータを収集して、コンテンツのSEOを最適化し、オンラインでの可視性を高めます。
- リスク管理
企業はネットワークデータ収集を使用して、規制変更、評判の問題、サプライチェーンの混乱など、潜在的なリスクを監視します。これにより、予防措置を講じ、リスクを効果的に軽減することができます。
- AIと機械学習データ
企業は、AIモデルをトレーニングし、機械学習アルゴリズムを強化するために、大規模なデータセットを収集します。たとえば、画像、テキスト、または言語データをスクレイピングすることで、レコメンデーションシステムや予測分析などのAIベースのソリューションを改善することができます。
ウェブデータ収集のための5つの最適なツール
評価基準
ランキング方法の透明性を確保します。いくつかの基準としては以下を含めることができます。
- 効率性: データ収集の速度と精度。
- アンチブロッキング機能: アンチスクレイピング対策を回避する機能。
- ユーザーエクスペリエンス: 使用の容易さ、直感的なUI、設定時間。
- 互換性: サポートされている言語、プラットフォーム、統合。
- 費用対効果: 機能と価格に基づいた費用対効果。
- 法的遵守: GDPRやCCPAなどのデータプライバシー法の遵守。
#1. Scrapeless
Scrapelessは、比類のない信頼性、手頃な価格、使いやすさを提供する、最高のウェブデータ収集ツールとして際立っています。最新のデータスクレイピングのニーズを満たすために設計されたScrapelessは、最先端のテクノロジーと統合された機能のスイートを組み合わせ、あらゆるデータ収集の課題に対するオールインワンのソリューションを提供します。
2000社以上の企業がデータ収集にScrapelessを使用している理由
- 手頃な価格: Scrapelessは、優れた価値を提供するように設計されています。
- 安定性と信頼性: 実績のあるScrapelessは、高負荷時でも安定したAPIレスポンスを提供します。
- 高い成功率: 失敗した抽出に別れを告げ、Scrapelessはウェブデータへの99.99%の成功率の高いアクセスを約束します。
- スケーラビリティ: Scrapelessを支える堅牢なインフラストラクチャのおかげで、数千のクエリを簡単に処理できます。
Scrapelessを際立たせているのは、その優れた安定性と高い成功率で、スムーズで途切れることのない運用を保証します。費用対効果の高い価格設定により、あらゆる規模の企業が利用でき、ユーザーフレンドリーなインターフェースにより、技術に詳しくないユーザーでも簡単に始めることができます。さらに、Scrapelessは迅速な応答時間にも定評があり、さまざまなスクレイピングシナリオでシームレスなパフォーマンスを提供します。
このプラットフォームの真の力は、統合された機能にあります。ウェブアンロック、スクレイピングブラウザ、スクレイピングAPI、CAPTCHAソルバー、組み込みプロキシなど、すべてが連携して複雑なウェブスクレイピングタスクを簡単に処理します。Scrapelessは高度なアンチ検知技術を採用して、99.99%のアンチボット検知とネットワーク制限を回避し、ユーザーに最も厳しい障壁を回避するための信頼性が高く効率的なソリューションを提供します。
#2. Mention
Mentionは、スタートアップがウェブ全体でブランドの言及とセンチメントを追跡できるメディアモニタリングプラットフォームです。ニュース監視、キーワードアラート、インフルエンサー発見などの機能があります。
Mentionを使用すると、小さなスタートアップでも、使いやすく手頃な価格のモニタリングソリューションで、ブランドに関するオンラインでの会話を把握できます。インサイトは、チームが見込み客やインフルエンサーと関わるのに役立ちます。
#3. SurveyMonkey
SurveyMonkeyは、顧客、従業員、市場のインサイトを収集するための使いやすいオンライン調査プラットフォームをスタートアップに提供します。調査作成、配布、分析ツール、統合などの機能があります。
SurveyMonkeyを使用すると、初期段階の企業は、広範な専門知識なしにフィードバック調査を作成および管理できます。手頃な価格のプランは、強力な機能とサポートを提供します。
#4. Lead411
Lead411は、パイプラインを拡大したいと考えているスタートアップ向けに設計された営業インテリジェンスプラットフォームを提供します。主な機能には、リードと企業データ、メール検索ツール、リアルタイムアラートなどがあります。
Lead411は、営業チームがリードを特定し、アウトバウンドマーケティングキャンペーンを強化するための簡単な方法を提供します。競争力のあるエントリーレベルの価格設定により、初期の成長への障壁を取り除きます。
#5. Magpi
Magpiは、スタートアップや小規模な調査チーム向けに特化したモバイルファーストのデータ収集システムです。フォーム、調査、オフラインデータキャプチャ、分析、データセット管理などの機能があります。
Magpiは、組織が社内の広範な専門知識を必要とせずに現場でインサイトを収集する方法を提供します。ベーシックプランは、さまざまなユースケースをサポートする高度な機能を提供します。
スクレイピングAPI:ウェブデータ収集の最適な方法
多くのウェブサイトやプラットフォームは、開発者が特定のデータに構造化された形式でアクセスできるようにするAPIを提供しています。APIは信頼性が高く効率的で、多くの場合、リアルタイムの更新が含まれています。例としては、Twitter API、Google SERP API、eコマースAPIなどがあります。
ただし、レート制限やデータアクセス制限などの制限がある場合があり、ウェブサイトが直接提供するAPIよりも高価なことが多いです。
幸いなことに、一部のサードパーティのスクレイピングAPIは手頃な価格で、高い安定性と成功率を備えています(Scrapelessなど)。
Scrapelessは、競争力のある価格で信頼性が高くスケーラブルなウェブスクレイピングプラットフォームを提供し、ユーザーにとって優れた価値を保証します。
- スクレイピングブラウザ: 1時間あたり0.09ドルから
- スクレイピングAPI: 1,000 URLあたり0.80ドルから
- ウェブアンロック: 1,000 URLあたり0.20ドル
- CAPTCHAソルバー: 1,000 URLあたり0.80ドルから
- プロキシ: 1GBあたり2.80ドル
購読することで、各サービスで最大20%の割引を受けることができます。特定の要件がありますか?今日お問い合わせください。ニーズに合わせたさらに大きな節約を提供します!
ScrapelessスクレイピングAPIがデータ収集に効果的な理由を説明します。Google検索データをスクレイピングする手順に従ってください。
ステップ1. Scrapelessダッシュボードにログインし、「Google検索API」に移動します。
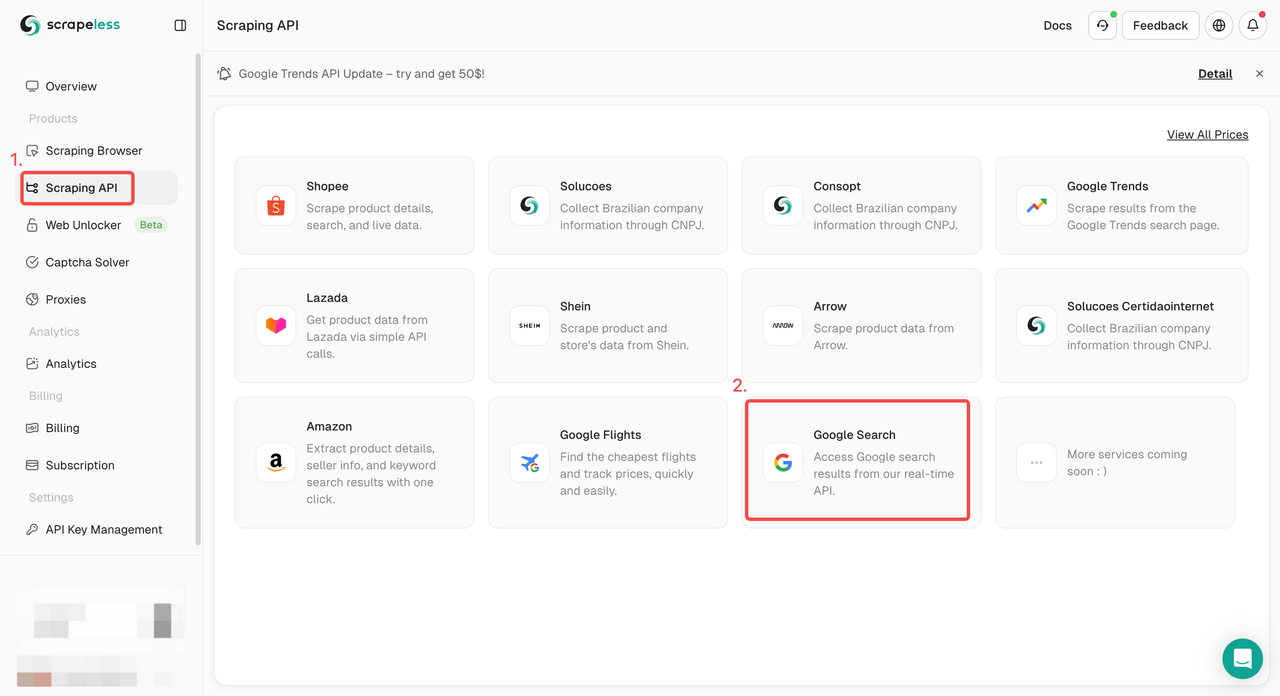
ステップ2. 左側で必要なキーワード、地域、言語、プロキシなどの情報を設定します。すべてがOKであることを確認したら、「スクレイピング開始」をクリックします。
q:検索するクエリを定義するパラメーター。gl:Google検索に使用する国を定義するパラメーター。hl:Google検索に使用する言語を定義するパラメーター。
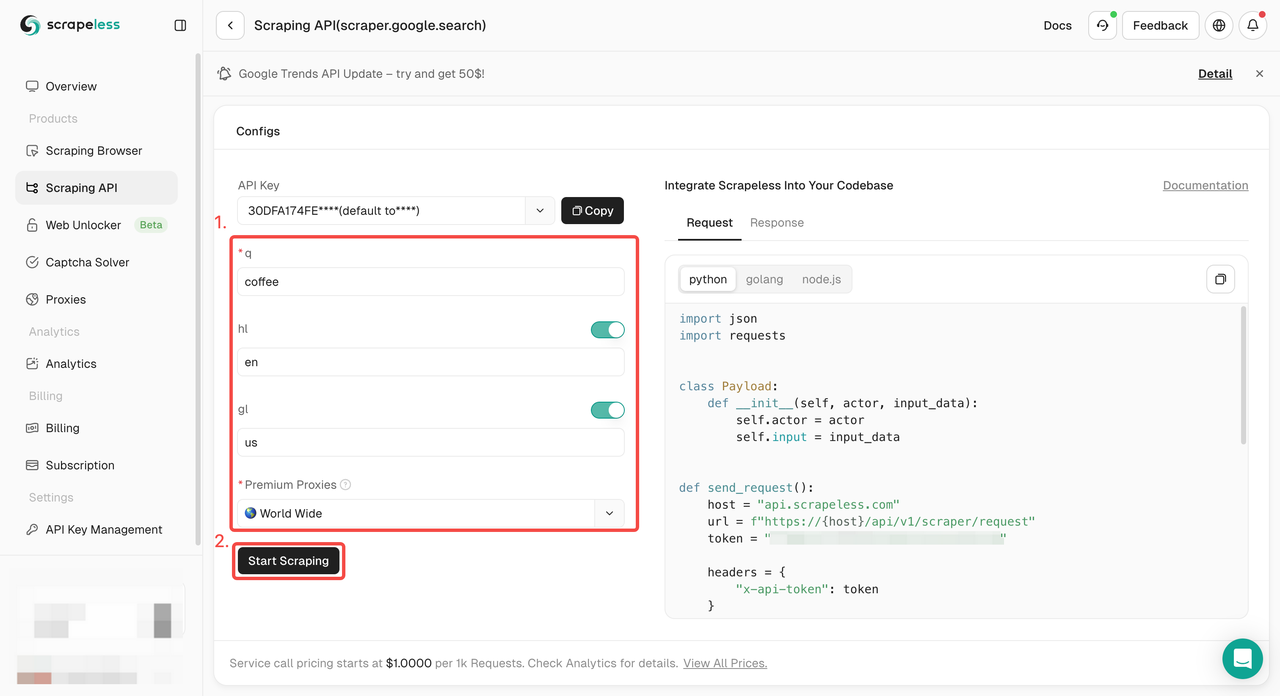
ステップ3. クロール結果を取得してエクスポートします。
プロジェクトに統合するサンプルコードが必要ですか?ご用意しております!または、必要な言語のAPIドキュメントにアクセスすることもできます。
- Python:
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}なぜますます多くの企業がデータ収集ツールを使用しているのか?
- 効率性と生産性の向上: データは組織にとって重要なフィードバックループを生み出します。たとえば、アドテク業界の企業は、ウェブデータを使用して広告コピー、リンク配置、画像を自動的に検証し、正しい広告が正しいオーディエンスに届くようにすることで、手動チェックを排除し、結果を最適化できます。📈
- 迅速かつ効果的な意思決定: リアルタイムのウェブデータ収集により、企業は重要な決定を瞬時に下すことができます。たとえば、投資会社は、株式の取引量やソーシャルセンチメントに関するデータを収集して、より良い売買の意思決定を行うことができます。💡
- 財務パフォーマンスの向上: 企業は、ウェブトラフィック、キーワード、検索トレンドを分析することで収益性を向上させることができ、より良い製品とブランドポジショニング、よりターゲットを絞ったリード獲得につながります。💰
- 新しい製品とサービスによる収益の特定と創出: データ主導の市場調査を通じて、企業は収益性を高めることができます。たとえば、競合他社の状況を分析する企業は、消費者のレビューやフィードバックを通じて、満たされていない消費者のニーズを特定することができます。📊
- 顧客体験の向上: 企業は、ウェブデータを使用してウェブサイトとユーザーエクスペリエンスのテストを行い、地理的なユーザーデータに基づいて、広告、コンテンツ、アプリケーションが期待どおりに機能することを保証できます。🌐
- 競争優位性: ウェブデータにより、企業はリアルタイムの価格とパッケージオファーを比較することで、競争優位性を獲得できます。オンライン旅行代理店(OTA)がデータ収集を使用して動的な価格設定戦略を作成し、競合他社を弱体化させる旅行業界は、その好例です。🏆
最高のデータ収集ツールを見つけましょう!
サイトの調査からコンプライアンスレポートの作成まで、これらのウェブスクレイピングツールは、適切な人々から必要な情報を簡単に収集するのに役立ちます。この記事の5つのツールのそれぞれに、異なる適用シナリオがあります。
ただし、繰り返し選択して呼び出すのを避けるために、Scrapelessを直接使用できます!これは強力なデータ収集ツールキットです。高度なAIツールとJSレンダリングにより、必要なデータを簡単かつ正確に取得できます。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


