
ScrapelessがPipedreamで利用可能になりました!
Senior Web Scraping Engineer
私たちは、Scrapelessが正式にPipedream上でライブになったことを発表できることに thrilled しています! 🎉
これにより、Scrapelessの強力なスクレイピング機能をこの堅牢なサーバーレス統合プラットフォーム内でシームレスに活用し、自動化されたデータ抽出ワークフローを構築できるようになります — もう煩雑なスクレイパーの設定やボット対策の頭痛に悩まされることはありません。
Pipedreamを選ぶ理由
Pipedreamは、イベント駆動型アーキテクチャをサポートする非常に柔軟で効率的な自動化プラットフォームであり、Slack、Notion、GitHub、Google Sheetsなど、数百のサービスを統合することができます。サーバーやインフラを管理することなく、JavaScript、Python、その他の言語でカスタムロジックを書くことができます。
これは、ウェブフックを構築し、データを同期し、リアルタイム通知を作成し、自動化が必要なものを何でも行うための理想的な環境です — 開発を効率化し、時間を節約します。
Pipedreamで最初のScrapelessワークフローを構築しましょう!
前提条件
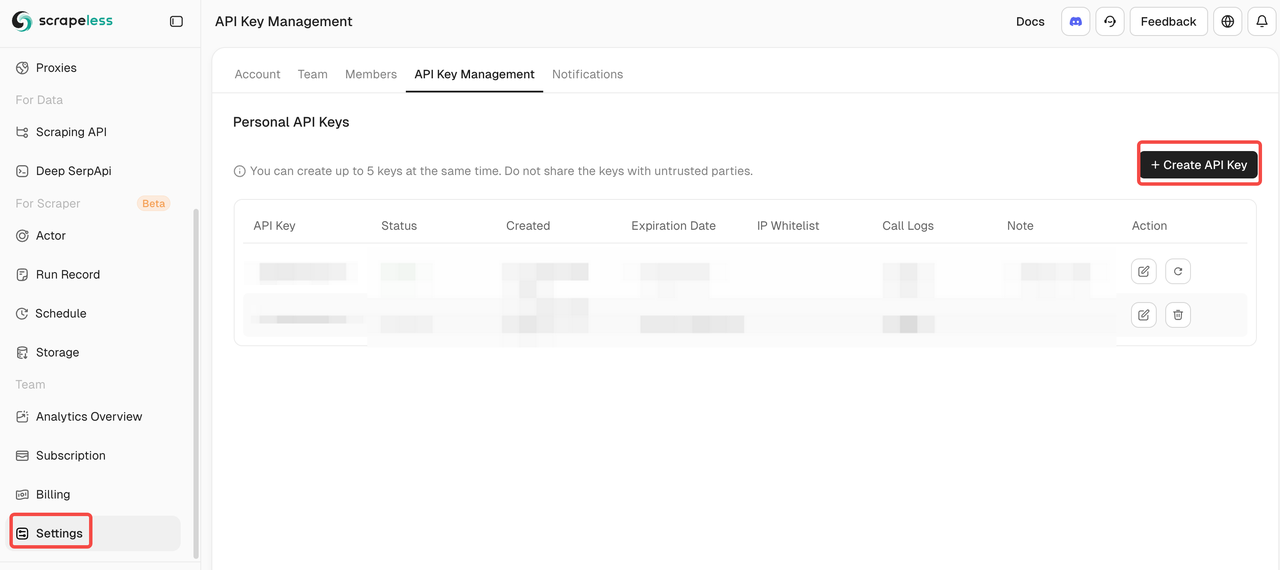
ステップ1. Scrapeless APIキーを取得します。 PipedreamでScrapelessを使用する前に、APIキーを取得していることを確認してください:
- Scrapelessにログインします。
- API管理に移動してキーを生成します。
ステップ2. Pipedreamアカウントを作成します。 まだ作成していない場合は、Pipedreamにサインアップしてください。
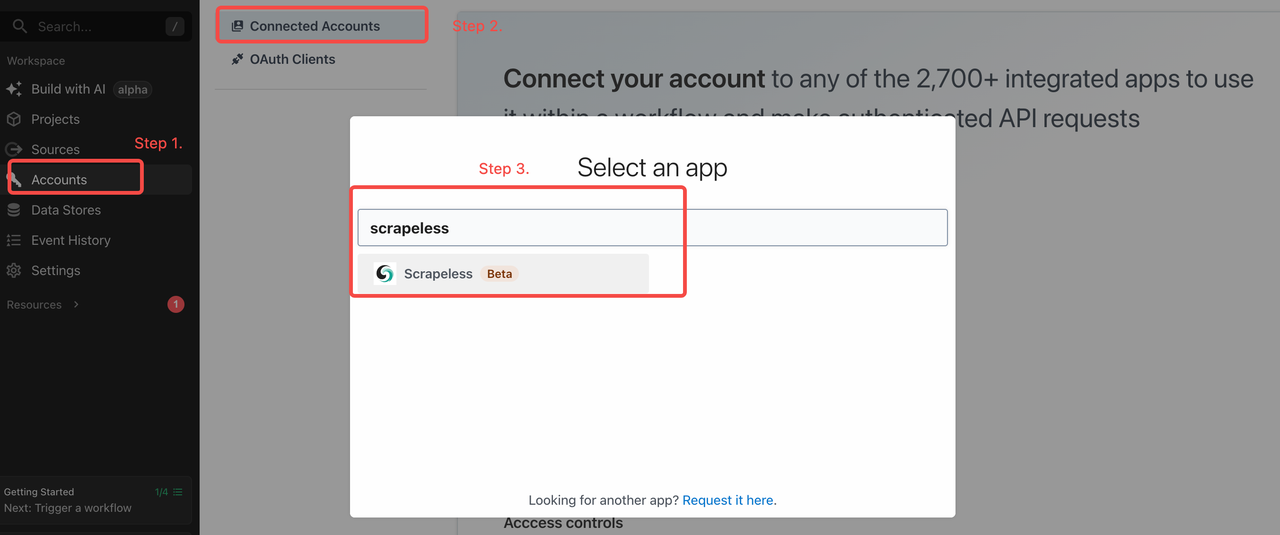
PipedreamでScrapeless APIキーを設定します
準備ができたら、Pipedreamの「アカウント」タブに移動し、Scrapeless APIキーを追加します:
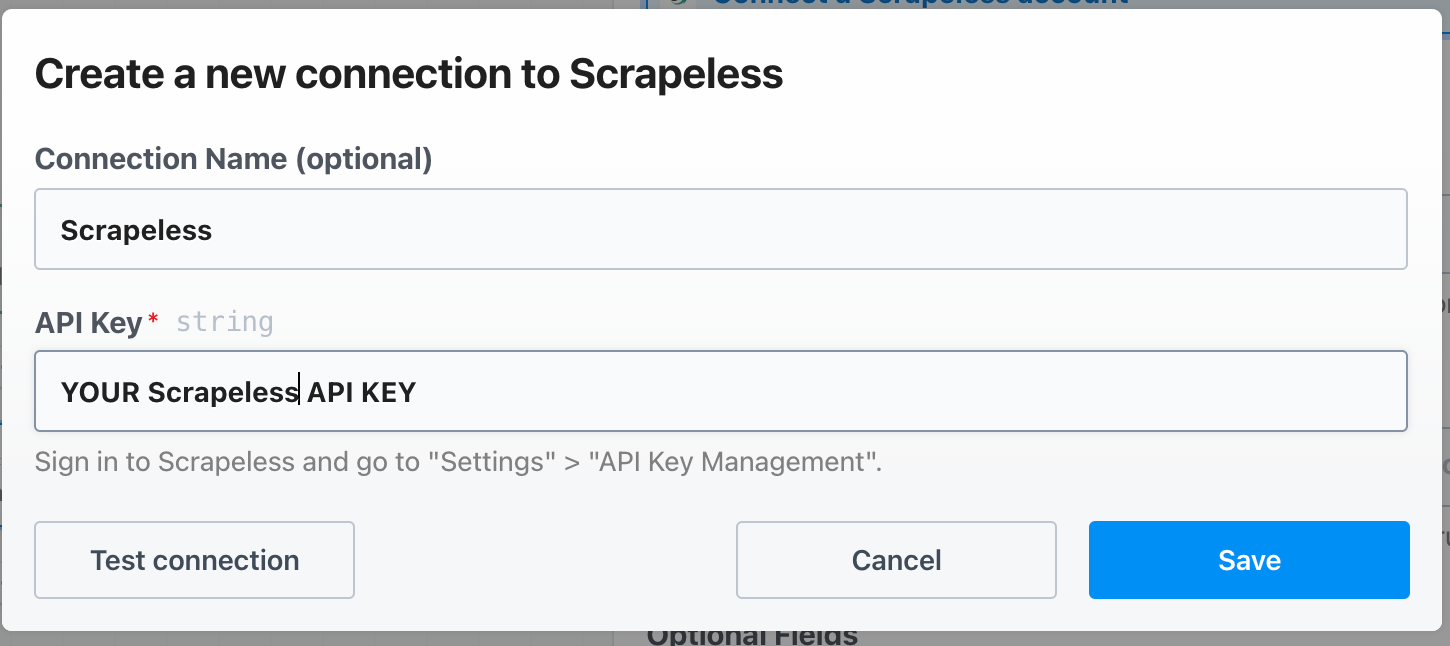
PipedreamでScrapeless APIキーを次のように設定します:
Scrapelessは、データ抽出ワークフローを数分で構築するのに役立つ3つの強力なモジュールを提供します:
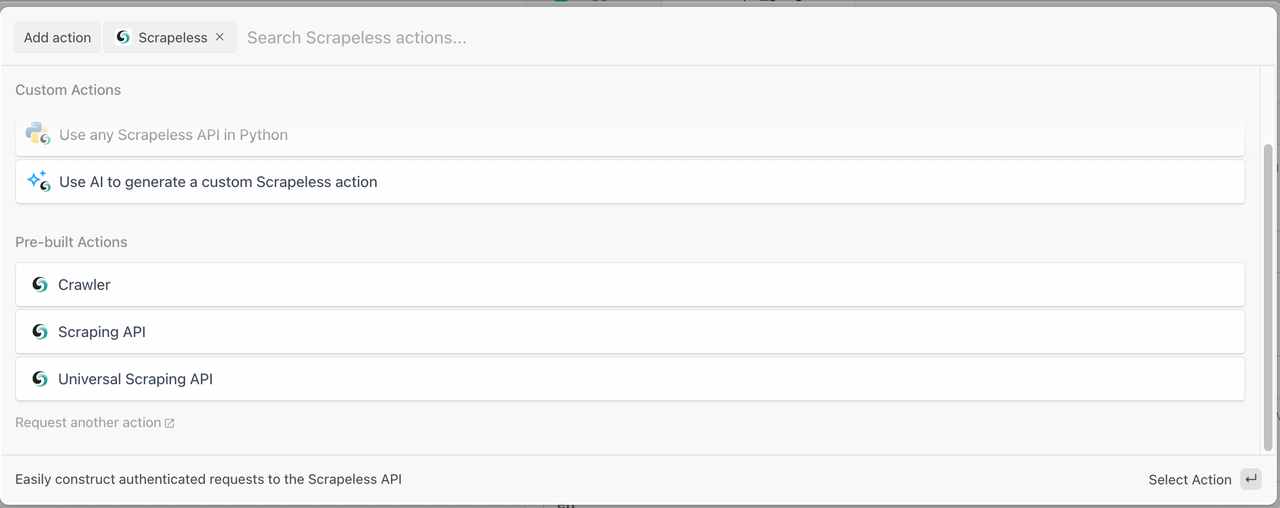
1. クローラーモジュール
- クローラークロール:サイト全体をクロールし、ページ内のリンクに再帰的にアクセスして、完全なデータセットを取得します。
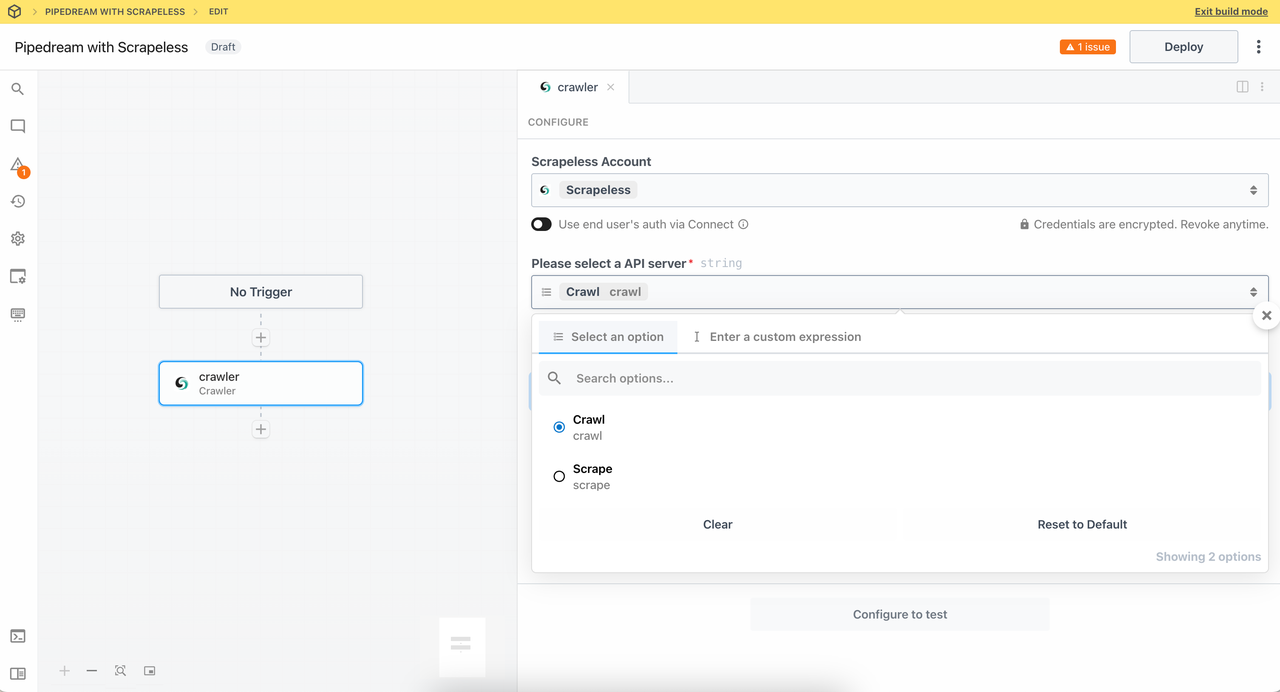
このノードは、Crawlからのクローラー機能を使用します。Scrapelessは、すべてのリンクされたページを完全にキャプチャするためのスマートな再帰クロールを提供します。
ページデータの量を収集するためのサブページ数を設定します。さあ、https://www.scrapeless.com/enをクロールしてみましょう:
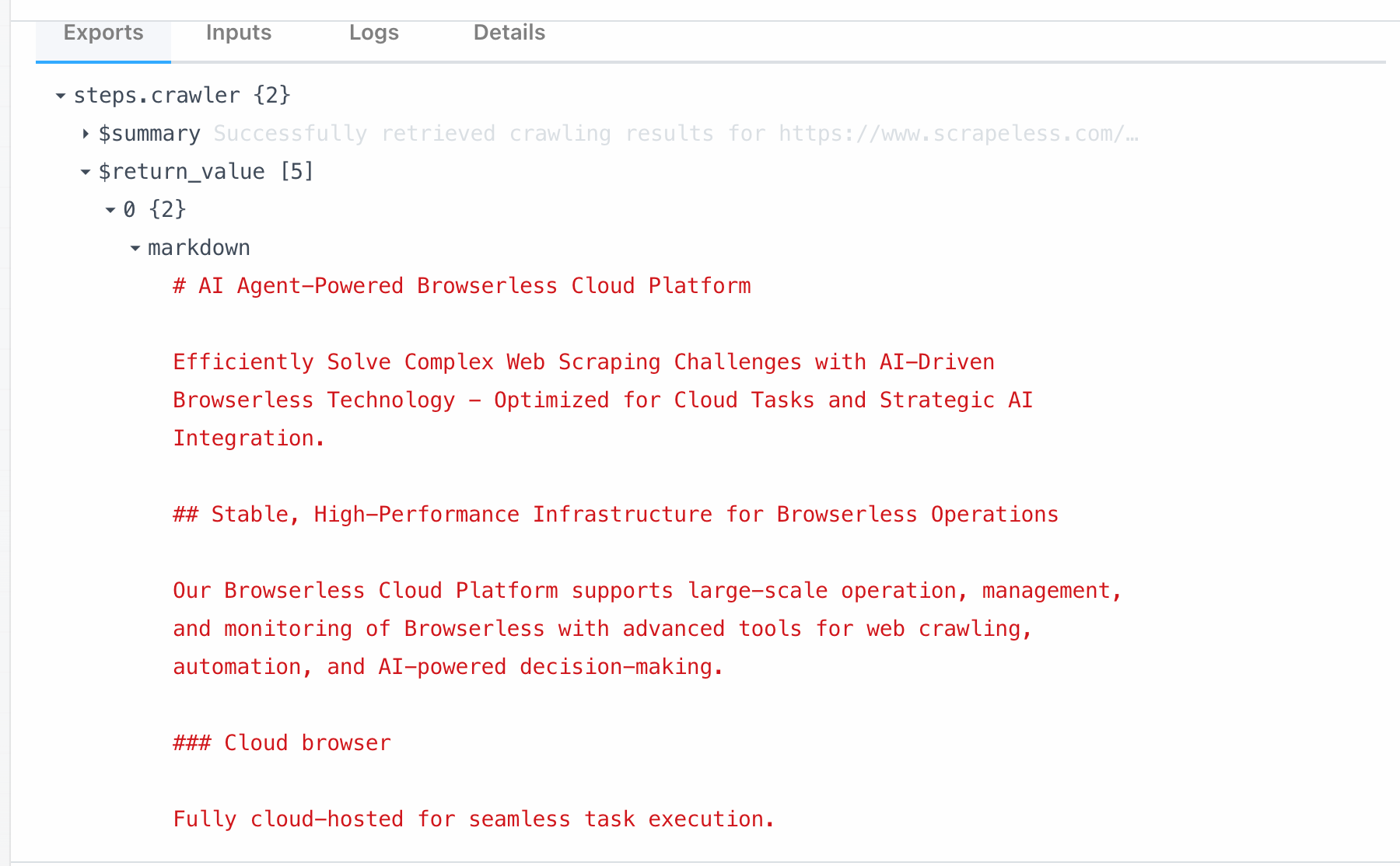
- クローラースクレイプ:単一のウェブページの内容をクロールし、構造化データを抽出するために使用されます。
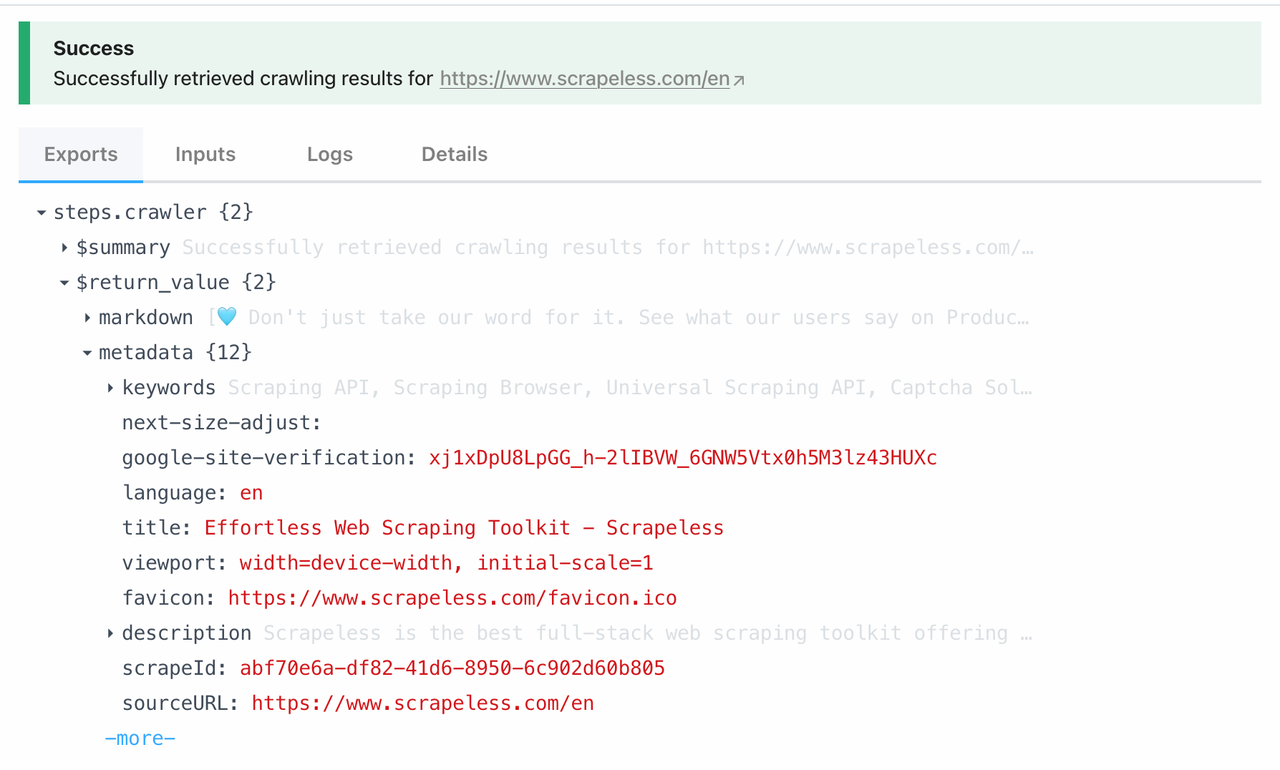
スクレイプノードは、Scrapeless Crawlの下のスクレイプ機能に直接リンクされています。このモジュールを呼び出すことで、単一のページからすべてのデータをワンクリックでスクレイピングできます。以下は、https://www.scrapeless.com/enからクロールして得られるものです:
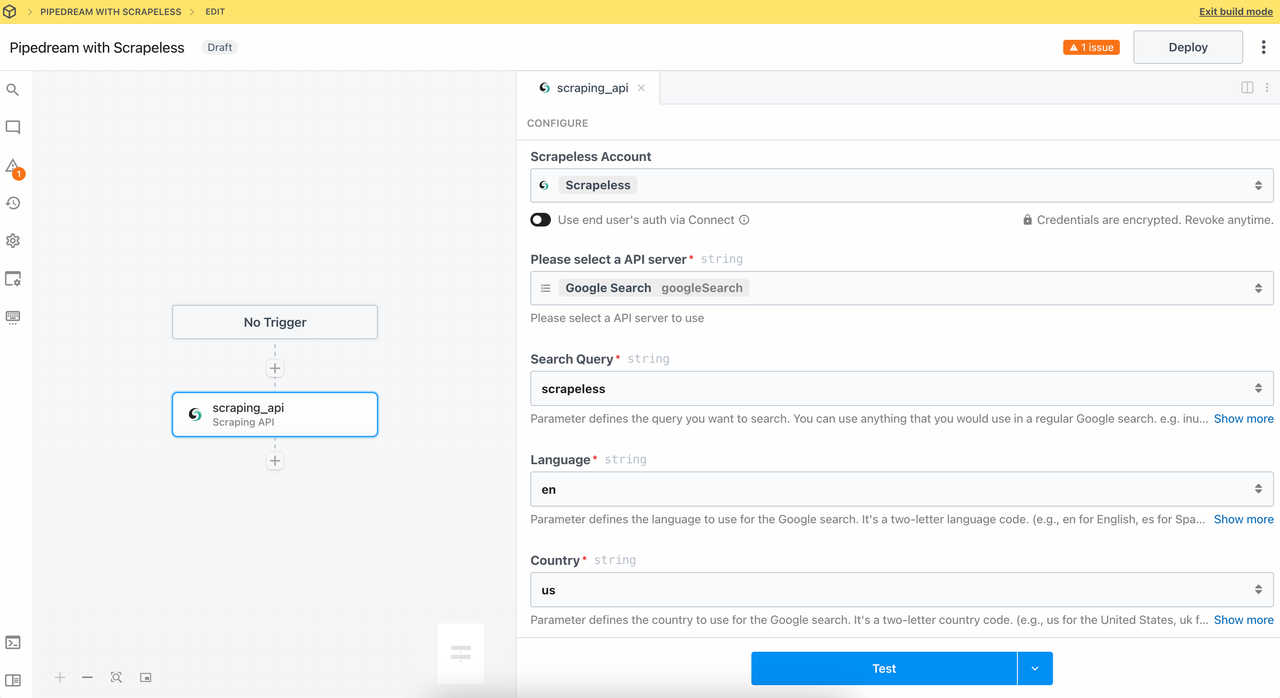
2. スクレイピングAPIモジュール
スクレイピングAPIモジュールを呼び出すことで、Google検索やGoogleトレンドなどのデータソースにワンクリックでアクセスし、検索結果やトレンドデータを簡単に取得できます。複雑なリクエストを書く必要も、自分でレスポンスを処理する必要もありません。
設定を行いましょう:
- クエリ:
Scrapeless - 言語:
en - 国:
us
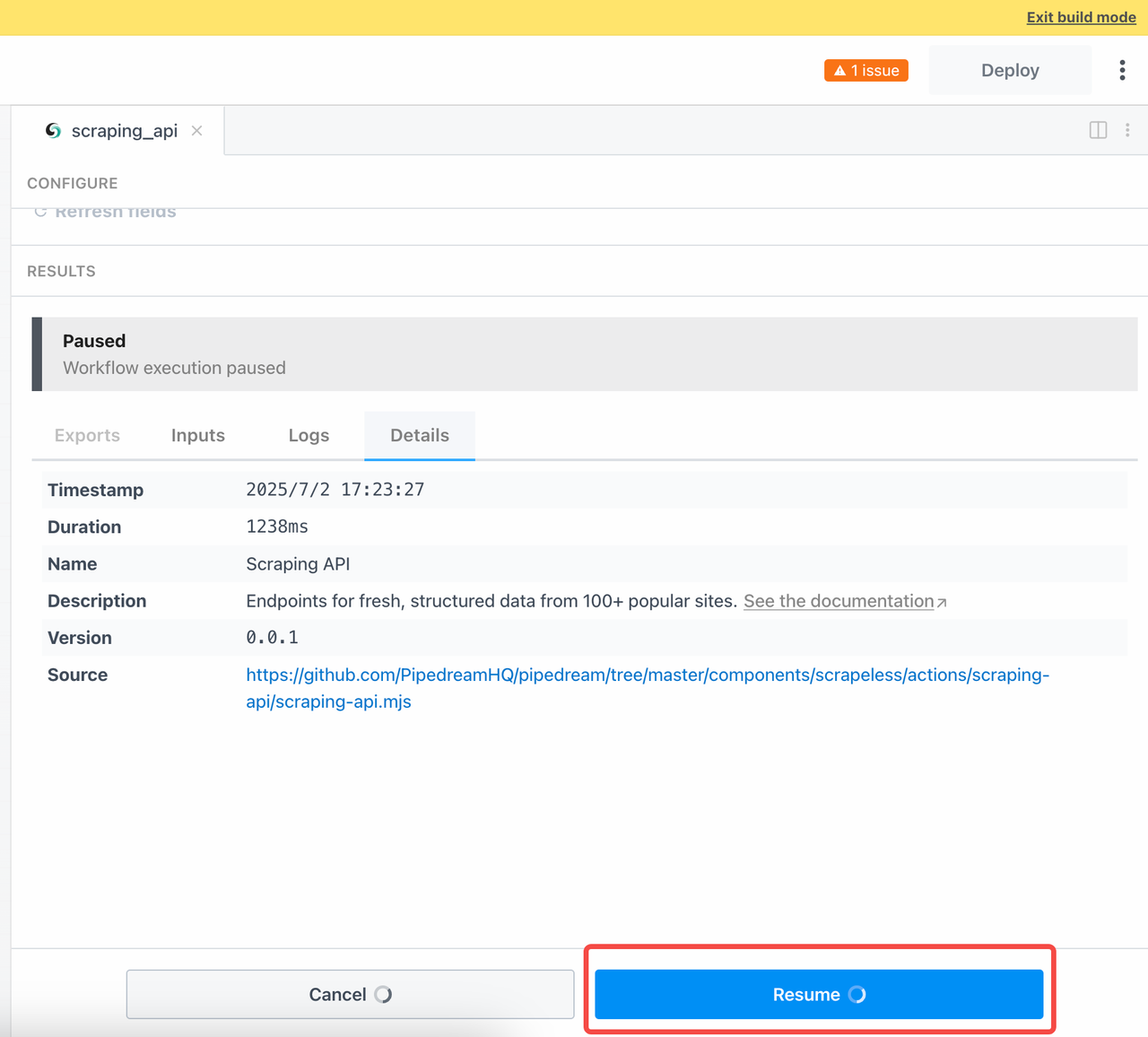
非同期タスクの結果を待つために、クエリを送信した後に手動で再開をクリックする必要があります:
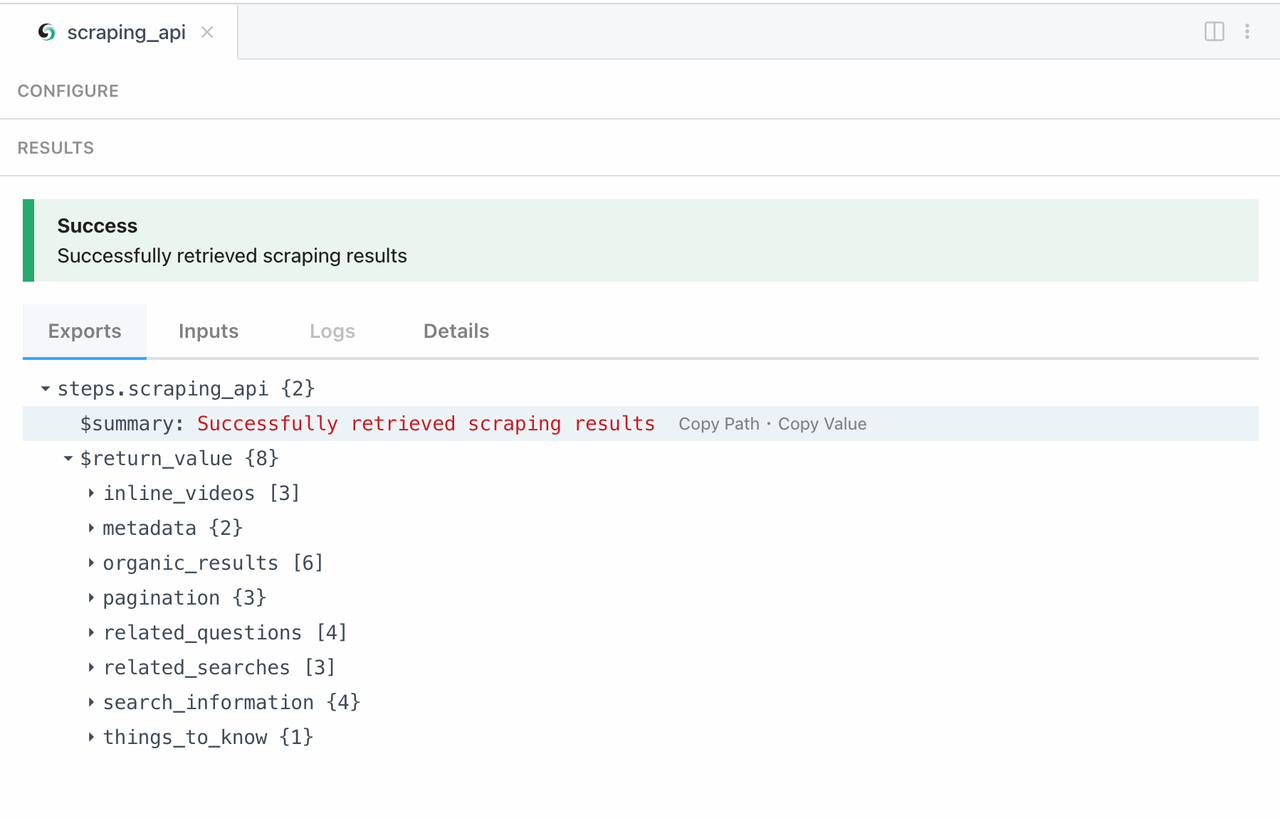
さて、スクレイピング結果を確認してみましょう:
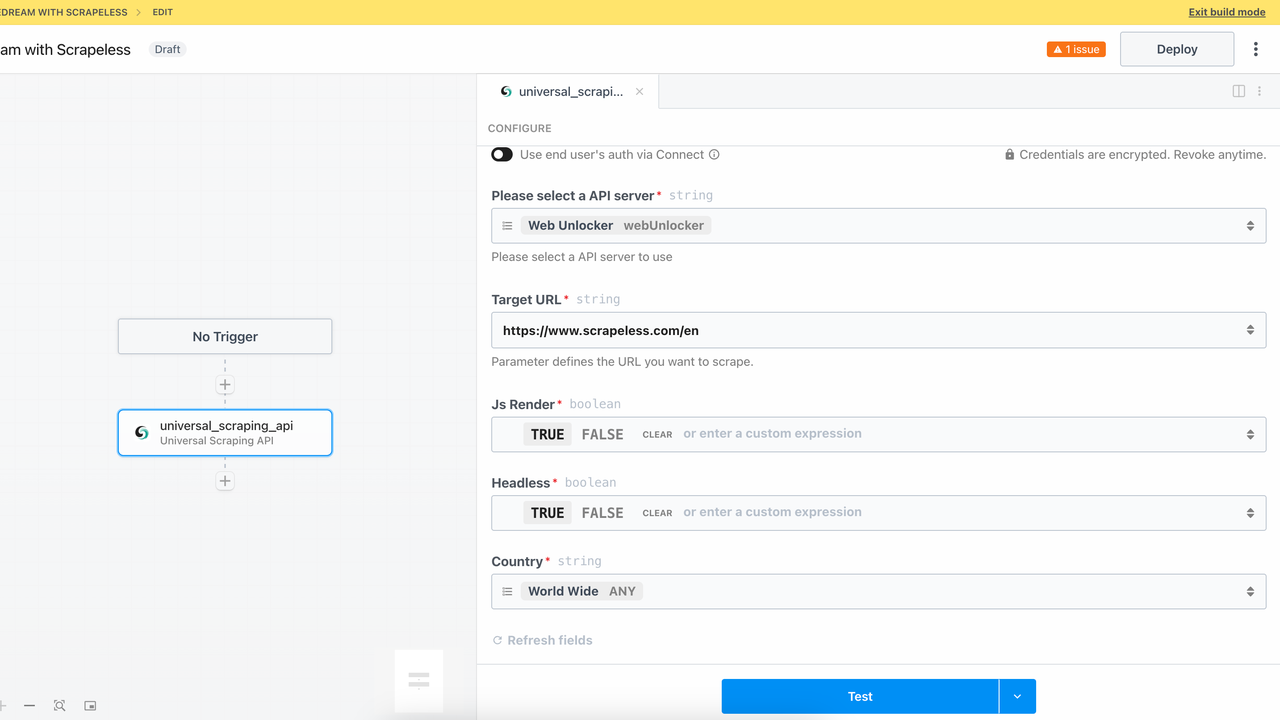
3. ユニバーサルスクレイピングAPIモジュール
ウェブサイトのアンロックモジュールを追加することで、ScrapelessのユニバーサルスクレイピングAPIサービスを正常に呼び出すことができます。JavaScriptレンダリングページ、ログイン検証、対スクレイピングメカニズムなどの複雑なページに直面した場合、このモジュールは自動的にさまざまな障害を処理し、ブラウザのようにページにアクセスしてデータを抽出します。
以下は返されたHTML結果です:
はじめに!
公開ウェブページのスクレイピング、検索トレンドの抽出、高度に保護された動的ページへのアクセスを行いたい場合でも、Scrapeless + Pipedreamを使用すれば、最小限のコードで最も複雑なデータ自動化タスクを完了できます。
🔗 今すぐ試してみてください -> PipedreamでScrapeless
さらなる読み物
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


