
TikTokから動画情報を取得するためのスクレイピング方法
Expert Network Defense Engineer
TikTokは、膨大なトラフィックを誇る主要なソーシャルメディアプラットフォームの一つです。TikTokがどれだけの価値あるデータを提供できるか想像してみてください!
この記事では、TikTok動画情報のスクレイピング方法を説明します。さらに、TikTokの隠されたAPIや埋め込まれたJSONデータセットを通じてこのデータのスクレイピングを実演します。始めましょう!
なぜTikTokをスクレイピングするのか?
TikTokは莫大なソーシャルエンゲージメントを誇り、様々なユースケースで様々なインサイトを収集することを可能にします。
トレンド分析
TikTokのトレンドは急速に変化するため、ユーザーの最新の好みを把握することが困難です。TikTokのスクレイピングは、これらのトレンドの変化とその影響を効果的に捉え、ユーザーの興味に合わせたマーケティング戦略の改善を可能にします。
リードジェネレーション
TikTokデータのスクレイピングにより、企業はマーケティングの機会と新規顧客を特定できます。これは、フォロワーの属性が関連するビジネスセクターと一致するインフルエンサーを特定することで実現できます。
センス分析
TikTokのウェブスクレイピングは、コメントからテキストデータを収集するための優れた情報源として機能し、センチメントモデルを通じて分析することで、特定のトピックに関する意見を収集できます。
TikTokスクレイピングの課題
TikTokスクレイピングとは、TikTokから公開されているデータを抽出するプロセスです。手動と自動の両方のアクティビティを含む場合がありますが、通常はウェブクローラーまたはTikTokのAPI(アプリケーションプログラミングインターフェース)とやり取りするカスタムスクリプトによって実行される自動化されたプロセスです。
データには、次のような様々な種類の情報が含まれる場合があります。
- ユーザープロフィール: プロフィール名、バイオ、フォロワー数など、TikTokユーザーに関する情報。
- 属性: 年齢、性別、場所、興味など、ユーザーの特性に関するデータ。
- 動画: ユーザーが投稿した短い動画で、キャプション、いいね、コメント、シェア、視聴回数など。
- ハッシュタグ: TikTokコンテンツを分類するために使用されるキーワードまたはフレーズ。
- コメント: テキストコンテンツ、タイムスタンプ、いいね数など、ユーザーが送信したテキストレスポンス。
- エンゲージメント指標: ユーザーがコンテンツとどのようにやり取りするかについての情報(いいね、コメント、シェア、視聴回数)。
- トレンド: TikTokで人気のあるトピック、テーマ、またはスタイルに関するデータ。
TikTokスクレイピングツールの構築方法?
簡単にしましょう!TikTok動画データのスクレイピングのステップバイステップのプロセスを正式に開始します。TikTokが提供する計り知れない価値を体験しましょう!
実際のスクレイピングプロセスを開始する前に、まずTikTokの動画コンテンツ構造を一緒に調べましょう。これにより、必要な情報をより効率的に見つけ出し、より簡単な方法でデータ抽出を完了することができます。
動画からスクレイピングできるデータ
- 動画URL
- 動画の説明
- 音楽名
- 公開日
- タグ
- 視聴回数
- いいね数
- コメント数
- シェア数
- ブックマーク数
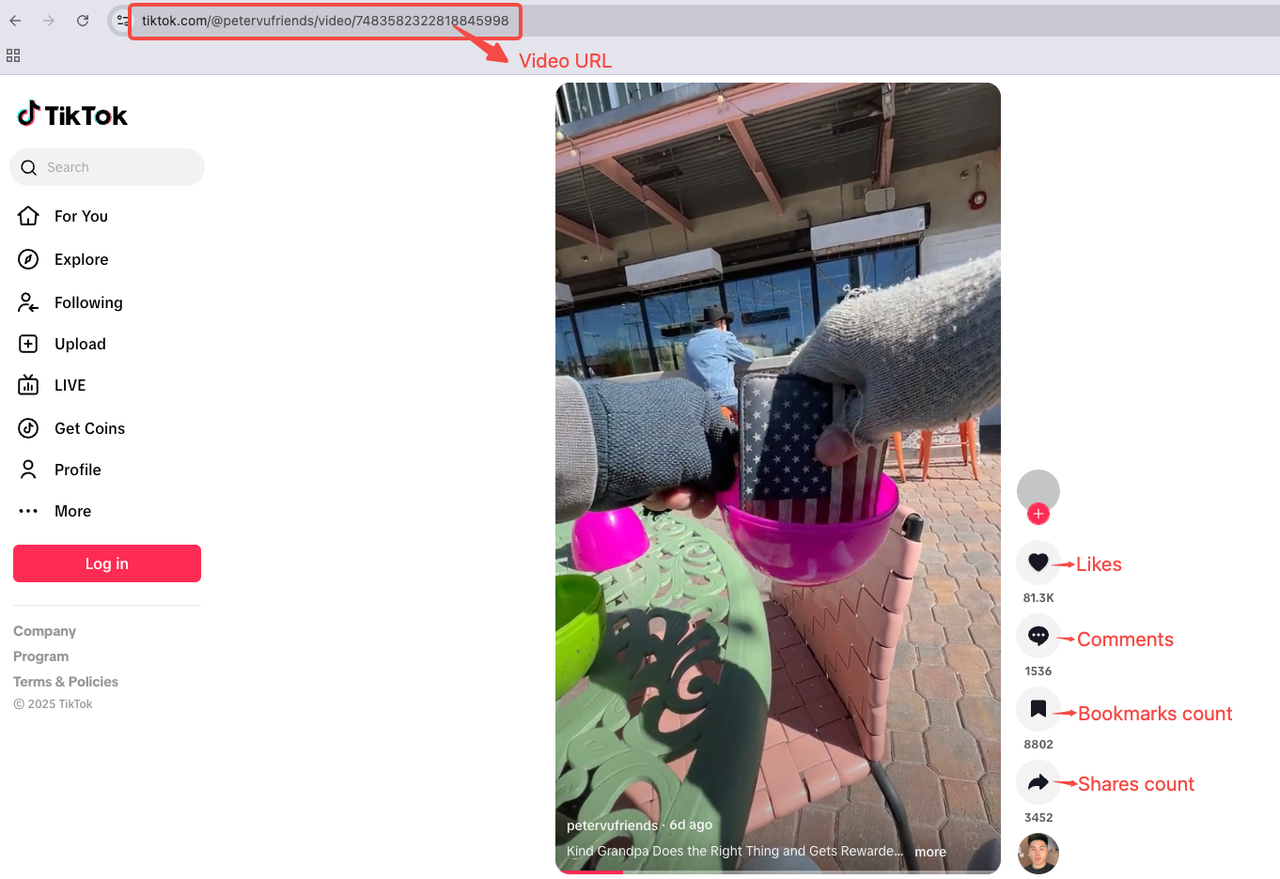
動画ページ分析
データスクレイピングをより直感的にするために、次の動画を参考として分析します。https://www.tiktok.com/@petervufriends/video/7476546872253893934
ウェブサイトのプライバシーを厳守します。このブログのすべてのデータは公開されており、クロールプロセスのデモンストレーションのみに使用されます。情報は一切保存しません。
必要なデータの探し方
HTML構造を詳しく見ていきましょう!この動画から抽出する必要があるものは次のとおりです。
視聴回数
視聴回数は通常、動画ページで目立つように表示されています。開発者ツールを開き、関連するタグを探してください。
Python
<strong data-e2e="video-views" class="video-count css-dirst9-StrongVideoCount e148ts222">281.4K</strong>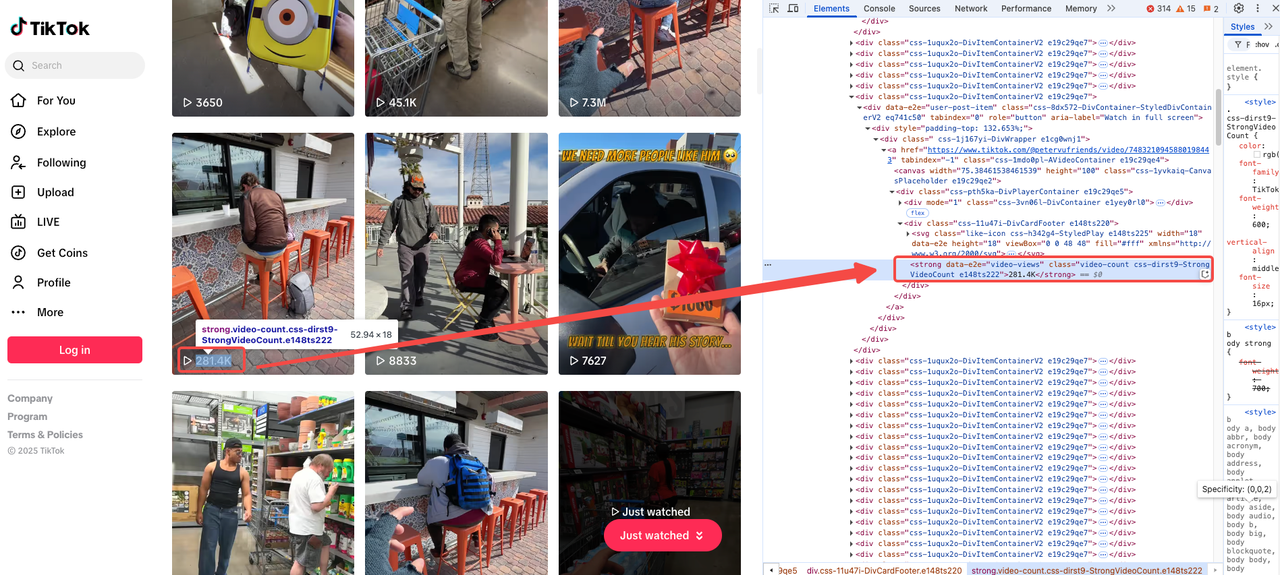
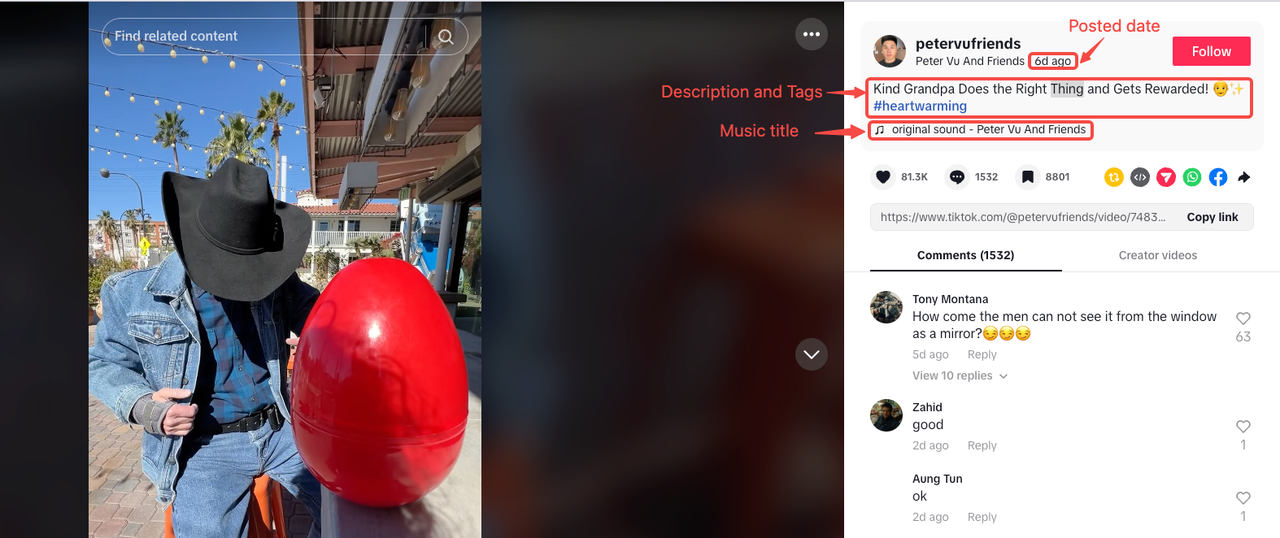
動画の説明とタグ
最初に観察したように、動画の説明とタグは通常同じセクションに表示されます。ただし、一部の動画には説明やタグがない場合があります。
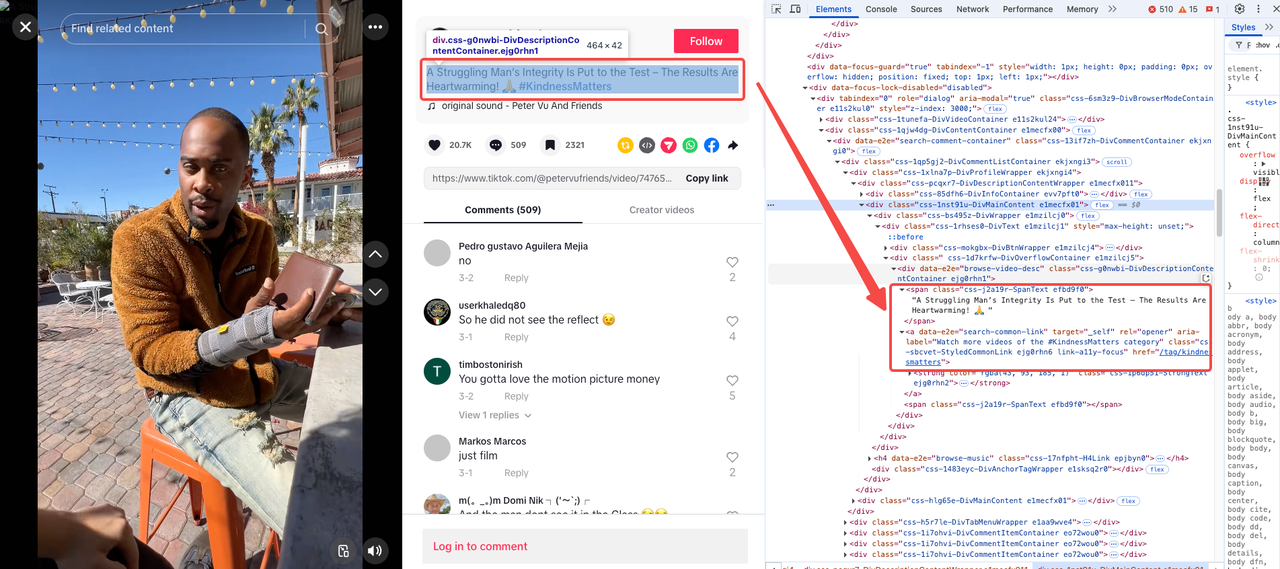
- 動画の説明は、一意のクラス
css-j2a19r-SpanTextを持つ<span>内にあります。 - 動画タグは別々ですが、同じ属性
data-e2e="search-common-link"を共有しています。
音楽タイトル
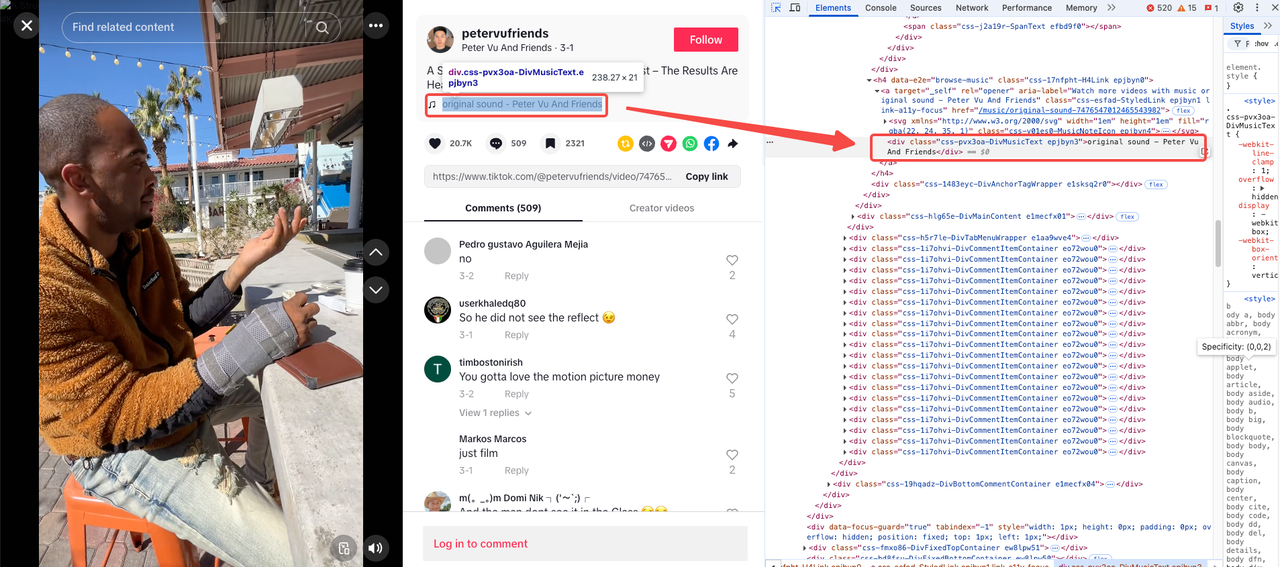
アップロード日
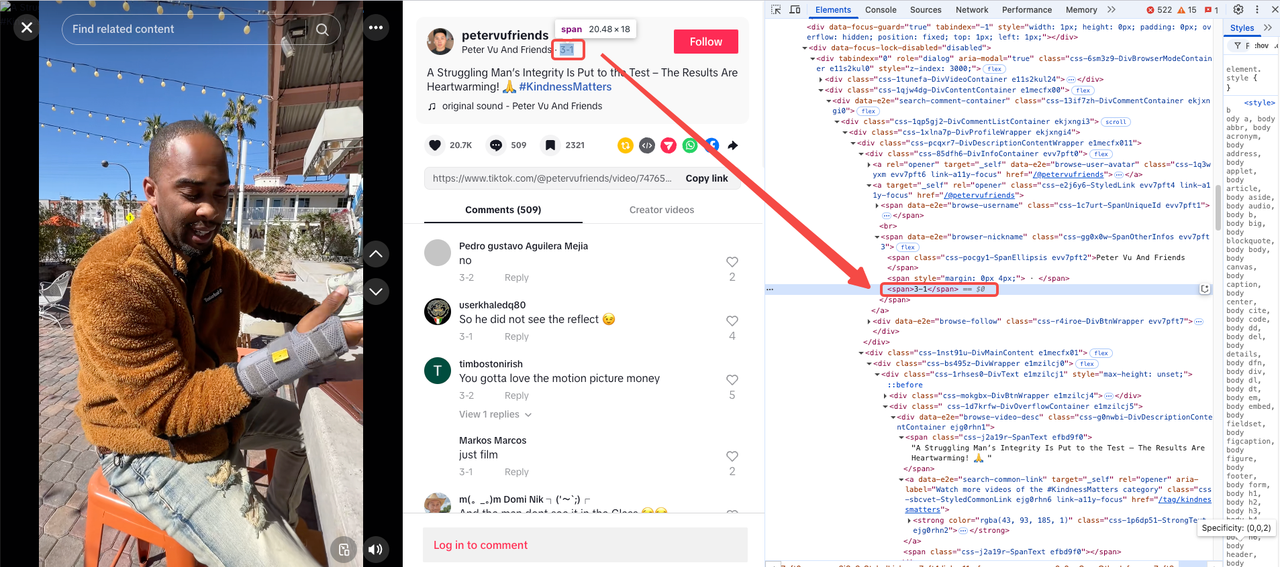
日付は、属性data-e2e="browser-nickname"を含む親要素内の最後の<span>として分離されています。
いいね数、コメント数、ブックマーク数
これらの指標は通常一緒に表示され、同じコレクションの下で見つけることができます。
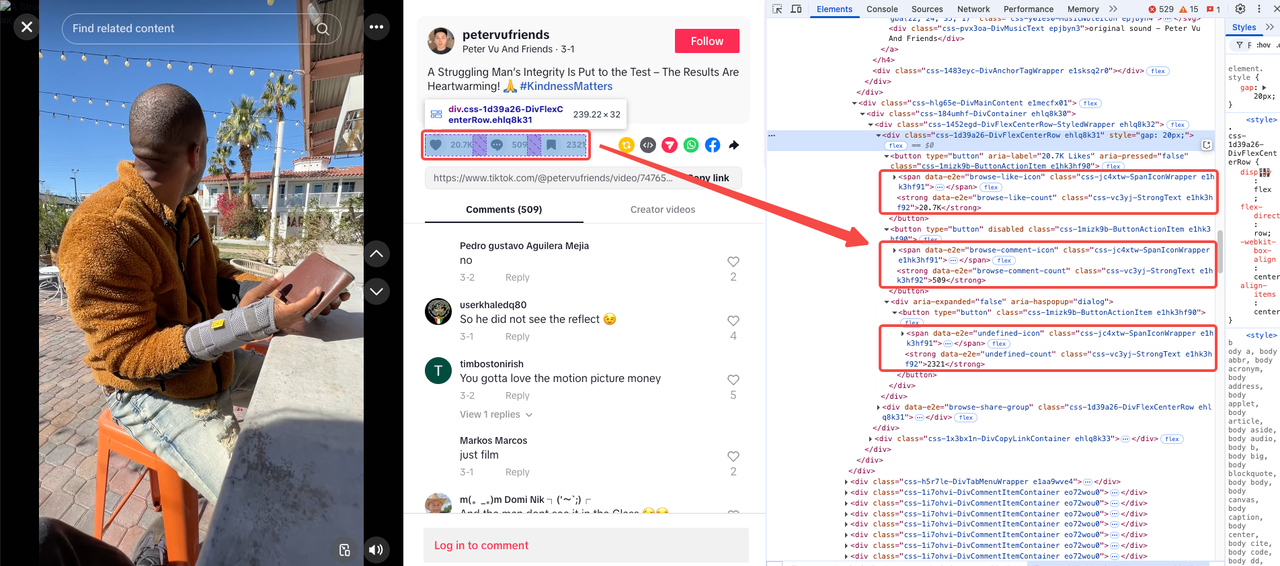
スクレイピングプロセスを簡素化するために、重要なセレクターの概要を次に示します。
- 動画URL:
<meta property="og:url"> - 動画の説明:
['span.css-j2a19r-SpanText'] - 音楽タイトル:
['.css-pvx3oa-DivMusicText'] - アップロード日:
['span[data-e2e="browser-nickname"] span:last-child'] - タグ:
[data-e2e="search-common-link"] - 視聴回数:
[data-e2e="video-views"] - いいね数:
[data-e2e="like-count"] - コメント数:
[data-e2e="comment-count"] - シェア数:
[data-e2e="share-count"] - ブックマーク数:
[data-e2e="undefined-count"]
おめでとうございます!これで、必要なデータの場所が完全に理解できました。次に、スクレイパーを正式に構築しましょう!
完全なスクレイピングコード
不要な説明をスキップします。すぐに実装できる、すぐに使えるスクレイピングコードを次に示します。
Python
from playwright.async_api import async_playwright
import asyncio, random, json, logging, time, os, yt_dlp
from urllib.parse import urlparse
# ログを設定する
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('tiktok_scraper.log'),
logging.StreamHandler()
]
)
class TikTokScraper:
def __init__(self):
self.DOWNLOAD_VIDEO = True
self.SAVE_DIR = "downloaded_videos"
self.USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
self.VIEWPORT = {'width': 1280, 'height': 720}
self.TIMEOUT = 300 # 5分間のタイムアウト
async def random_sleep(self, min_seconds=1, max_seconds=3):
"""ランダムな遅延"""
delay = random.uniform(min_seconds, max_seconds)
logging.info(f" {delay:.2f}秒間スリープします...")
await asyncio.sleep(delay)
async def handle_captcha(self, page):
"""確認コードの処理"""
try:
captcha_dialog = page.locator('div[role="dialog"]')
if await captcha_dialog.count() > 0 and await captcha_dialog.is_visible():
logging.warning("CAPTCHAが検出されました。手動で解決してください。")
await page.wait_for_selector('div[role="dialog"]', state='detached', timeout=self.TIMEOUT*1000)
logging.info("CAPTCHAが解決されました。再開します...")
await self.random_sleep(0.5, 1)
except Exception as e:
logging.error(f"CAPTCHA処理エラー: {str(e)}")
async def extract_video_info(self, page, video_url):
"""動画の詳細を抽出する"""
logging.info(f"情報抽出中: {video_url}")
try:
await page.goto(video_url, wait_until="networkidle")
await self.random_sleep(2, 4)
await self.handle_captcha(page)
# 主要な要素の読み込みを待機する
await page.wait_for_selector('[data-e2e="like-count"]', timeout=10000)
video_info = await page.evaluate("""() => {
const getTextContent = (selectors) => {
for (let selector of selectors) {
const element = document.querySelector(selector);
if (element && element.textContent.trim()) {
return element.textContent.trim();
}
}
return 'N/A';
};
const getTags = () => {
const tagElements = document.querySelectorAll('a[data-e2e="search-common-link"]');
return Array.from(tagElements).map(el => el.textContent.trim());
};
return {
likes: getTextContent(['[data-e2e="like-count"]', '[data-e2e="browse-like-count"]']),
comments: getTextContent(['[data-e2e="comment-count"]', '[data-e2e="browse-comment-count"]']),
shares: getTextContent(['[data-e2e="share-count"]']),
bookmarks: getTextContent(['[data-e2e="undefined-count"]']),
views: getTextContent(['[data-e2e="video-views"]']),
description: getTextContent(['span.css-j2a19r-SpanText']),
musicTitle: getTextContent(['.css-pvx3oa-DivMusicText']),
date: getTextContent(['span[data-e2e="browser-nickname"] span:last-child']),
author: getTextContent(['a[data-e2e="browser-username"]']),
tags: getTags(),
videoUrl: window.location.href
};
}""")
logging.info(f"情報抽出成功: {video_url}")
return video_info
except Exception as e:
logging.error(f"{video_url}からの情報抽出失敗: {str(e)}")
return None
def download_video(self, video_url):
"""動画をダウンロードする"""
if not os.path.exists(self.SAVE_DIR):
os.makedirs(self.SAVE_DIR)
ydl_opts = {
'outtmpl': os.path.join(self.SAVE_DIR, '%(id)s.%(ext)s'),
'format': 'best',
'quiet': False,
'no_warnings': False,
'ignoreerrors': True
}
try:
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(video_url, download=True)
filename = ydl.prepare_filename(info)
logging.info(f"動画ダウンロード成功: {filename}")
return filename
except Exception as e:
logging.error(f"動画ダウンロードエラー: {str(e)}")
return None
async def scrape_single_video(self, video_url):
"""単一のショート動画をスクレイピングする"""
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context(
viewport=self.VIEWPORT,
user_agent=self.USER_AGENT,
)
page = await context.new_page()
result = {}
try:
# ショート動画の情報を抽出する
video_info = await self.extract_video_info(page, video_url)
if not video_info:
raise Exception("動画情報の抽出に失敗しました")
result.update(video_info)
# TikTokショート動画をダウンロードする
if self.DOWNLOAD_VIDEO:
filename = self.download_video(video_url)
if filename:
result['local_path'] = filename
except Exception as e:
logging.error(f"動画スクレイピングエラー: {str(e)}")
finally:
await browser.close()
return result
def save_results(self, data, filename="tiktok_video_data.json"):
"""結果をJSONファイルに保存する"""
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=2, ensure_ascii=False)
logging.info(f"結果を{filename}に保存しました")
async def main():
# クローラーを初期化する
scraper = TikTokScraper()
# ターゲットとするTikTokショート動画のURL
video_url = "https://www.tiktok.com/@petervufriends/video/7476546872253893934" # 参考として
# ショート動画をスクレイピングする
video_data = await scraper.scrape_single_video(video_url)
# スクレイピング結果を保存する
if video_data:
scraper.save_results(video_data)
logging.info("\nスクレイピング完了。結果:")
for key, value in video_data.items():
logging.info(f"{key}: {value}")
else:
logging.error("動画データのスクレイピングに失敗しました")
if __name__ == "__main__":
asyncio.run(main())スクレイピング結果
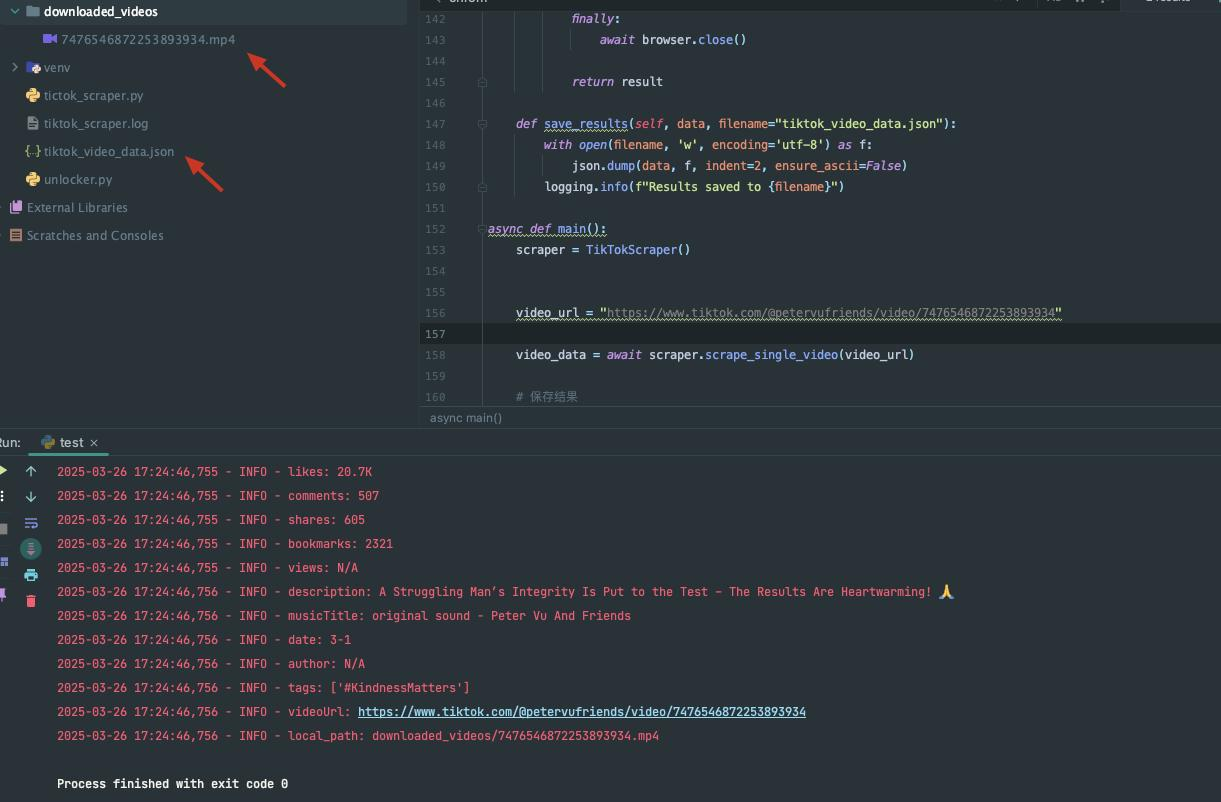
明らかに、データクロールを実現するには、複雑なプログラミングと対策(遅延の設定、CAPTCHAの回避など)が必要です。では、どのようにしてTikTokデータを迅速に取得すれば良いのでしょうか?強力なサードパーティのスクレイピングAPIが最適な選択肢です!
スクレイピングAPI:TikTokデータを簡単に収集
Walmart製品の詳細を取得するためにAPIを使用する理由
1. 効率の向上
製品データの手動検索は遅く、エラーが発生しやすいです。APIを使用すると、Walmart製品情報を自動的に取得できるため、高速で一貫性のあるデータ収集が保証されます。
2. 正確でリアルタイムのデータ
Scrapeless APIは、Walmart製品ページから直接データを抽出するため、取得した情報が最新で正確であることが保証されます。これにより、手動入力の遅延や古い情報源によるエラーを防ぐことができます。
3. 様々なビジネスシナリオに適用可能
- 価格監視:競合他社の価格を比較し、価格戦略を調整します。
- 在庫追跡:サプライチェーン管理を最適化するために、製品の在庫状況を確認します。
- レビュー分析:顧客のフィードバックを分析して、製品とサービスを改善します。
- 市場調査:人気のある製品を特定し、情報に基づいたビジネス上の意思決定を行います。
TikTokスクレイパーの機能
このTikTokデータスクレイパーは、独自のデータプロジェクト、ビジネスレポート、および新しいアプリケーションの基礎として、大規模なTikTokデータをあなたに提供する強力な非公式TikTok APIです。この最高のTikTokスクレイパーを使用すると、次のような情報を取得できます。
- 詳細を含む選択したハッシュタグからのすべての結果:人気の動画、タイムスタンプ、視聴回数、シェア数、コメント数、動画数など。
- 詳細を含む選択したユーザープロフィールからのすべての投稿:名前、ニックネーム、ID、バイオ、フォロワー/フォロー数、再生回数、シェア数、コメント数など。
- 特定の動画URLを含む個々の動画投稿。
- 動画と音楽関連データ。
APIを使用したTikTokデータのスクレイピング
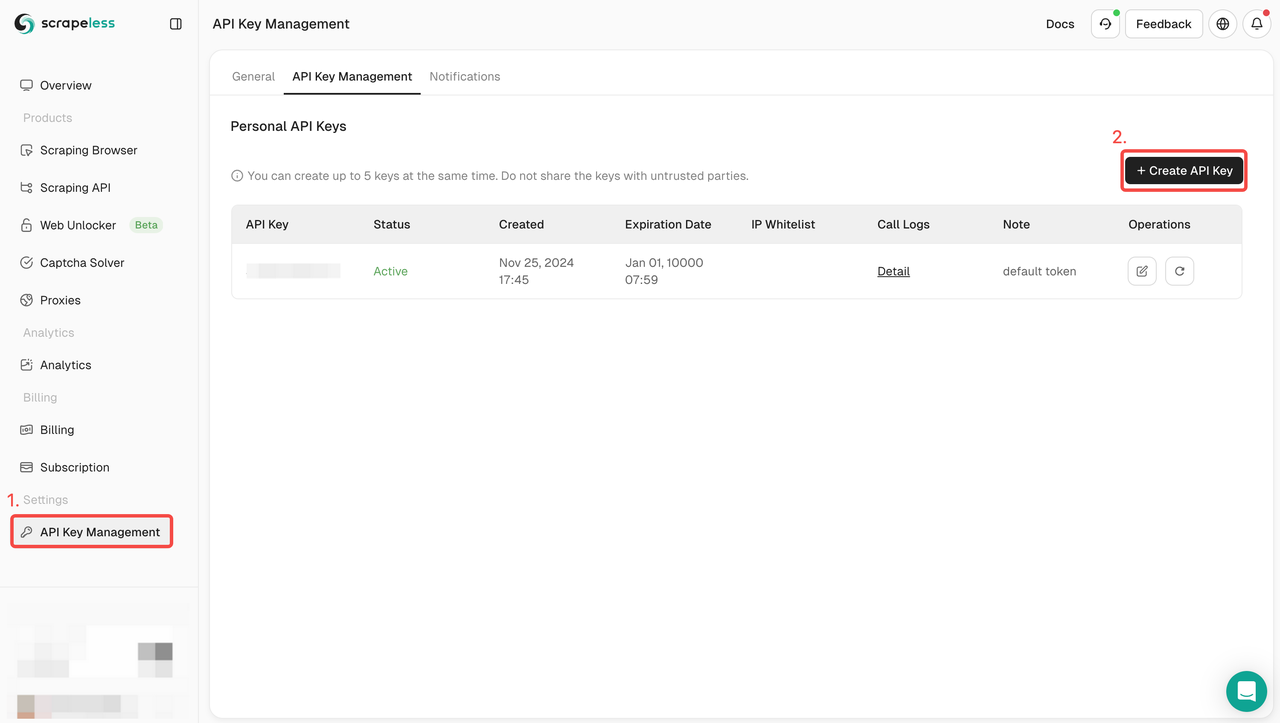
手順1. APIトークンの作成
開始するには、ScrapelessダッシュボードからAPIキーを取得する必要があります。
- Scrapelessダッシュボードにログインします。
- APIキー管理に移動します。
- 作成をクリックして、独自のAPIキーを生成します。
- 作成後、APIキーをクリックしてコピーします。
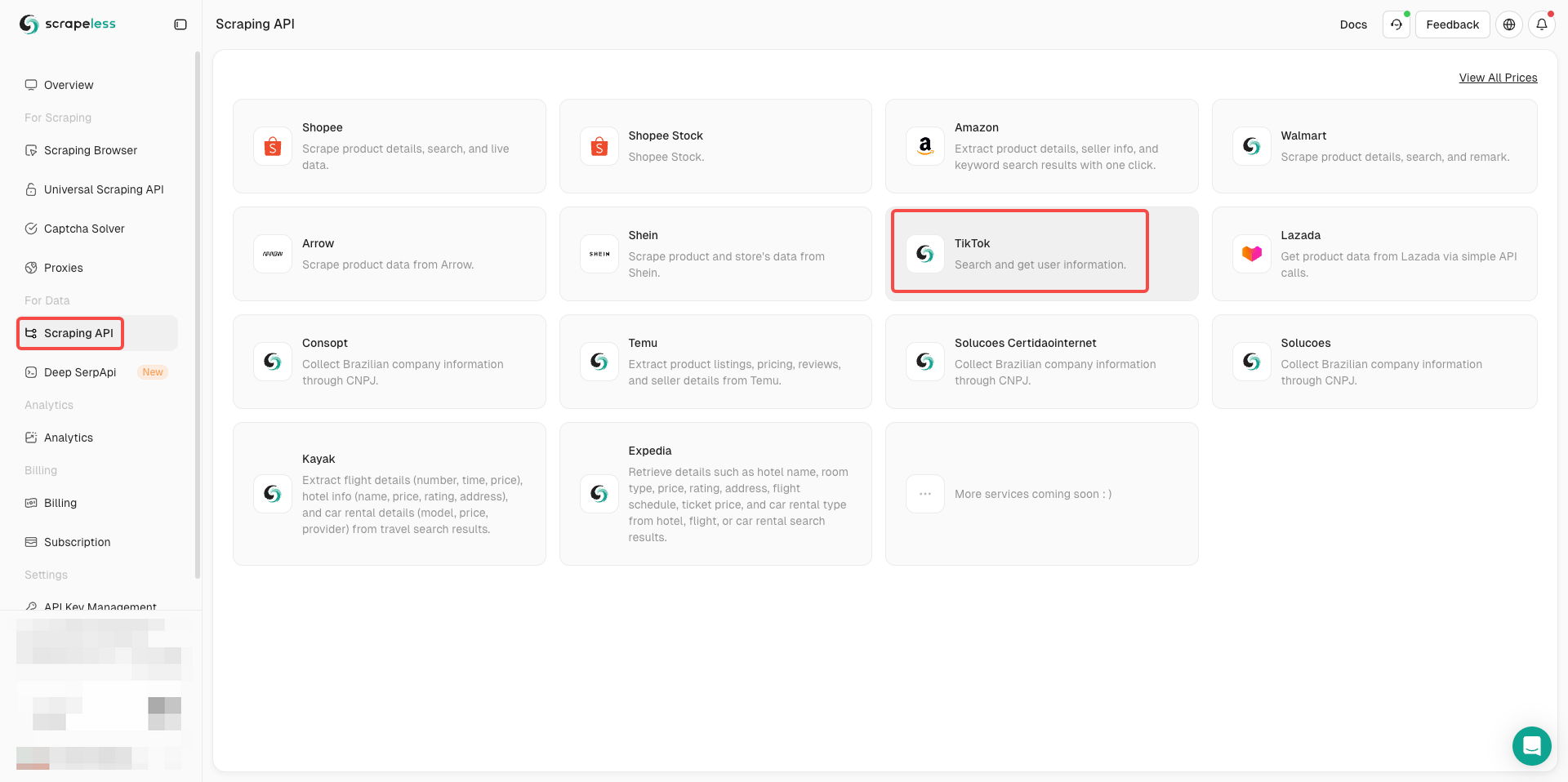
手順2. TikTok APIへの入力
- データ用にあるスクレイピングAPIをクリックします。
- TikTokを見つけて入力します。
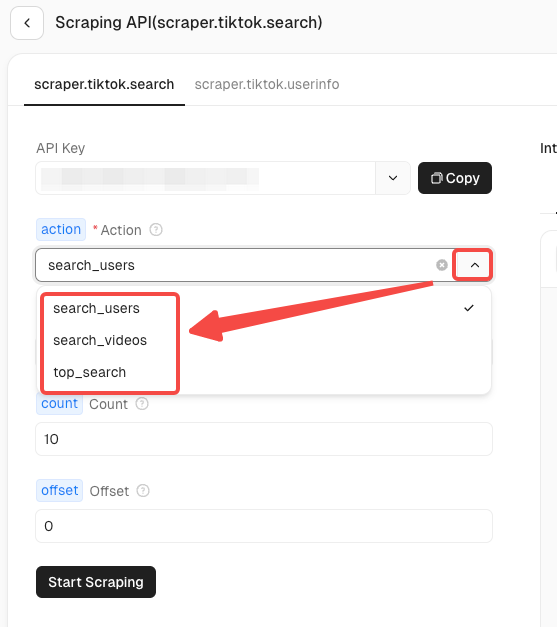
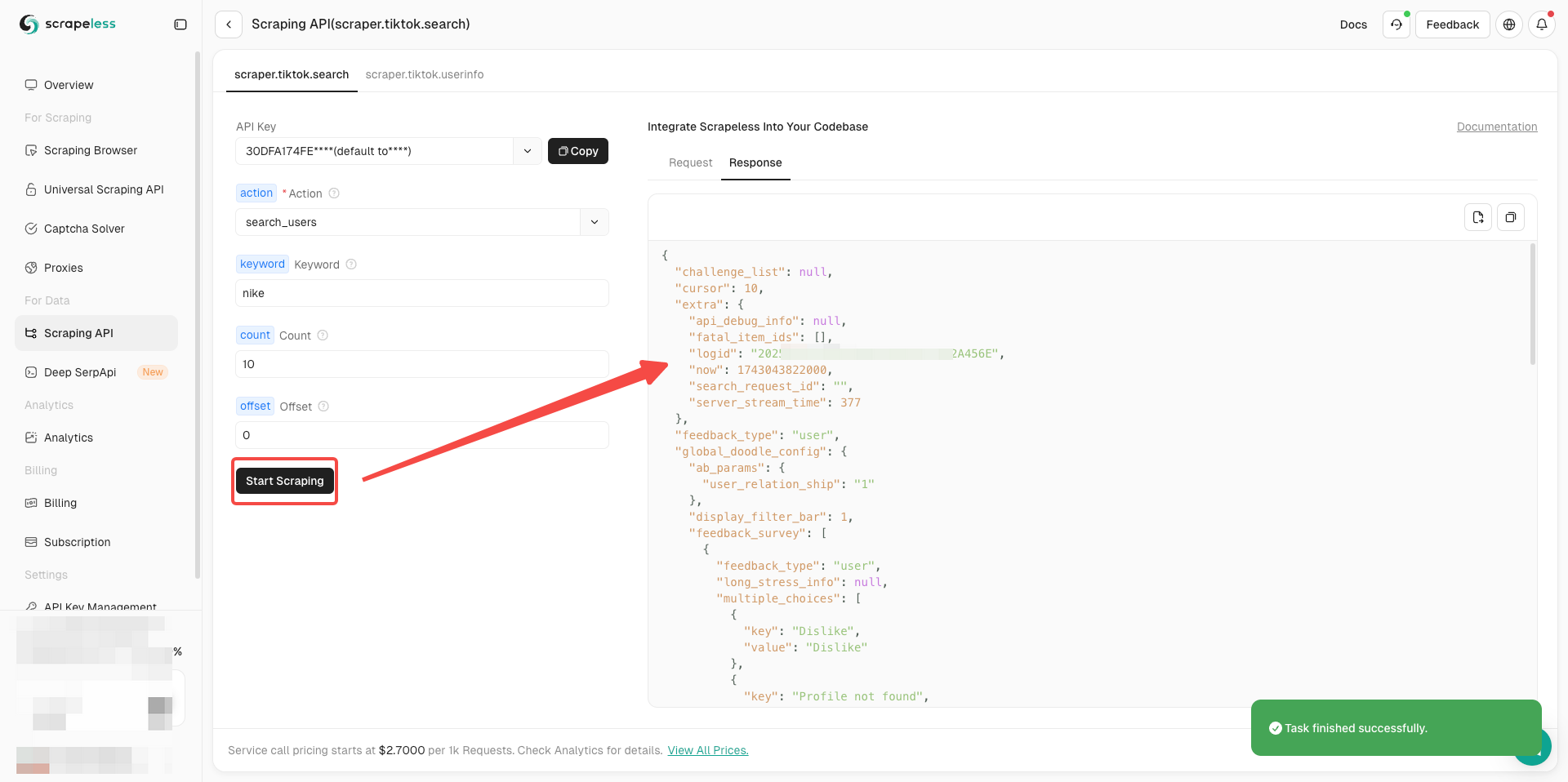
手順3. 要求パラメーターの設定
TikTokアクターには現在、2つのスクレイピングシナリオがあります。
- TikTok検索情報: 特定のキーワードの動画検索結果をスクレイピングします。
- TikTokユーザー情報: 指定されたユーザーのプロフィール情報をスクレイピングします。
各シナリオには、異なるアクションリクエストがあります。折りたたみ矢印をクリックして、正確にスクレイピングする必要があるデータ情報を見つけることができます。「TikTok検索情報」を例に取ると:
準備はできましたか?基本情報が理解できたら、正式にデータのスクレイピングを開始できます!
- 必要に応じて、アクターの左側のパラメーター設定を完了するだけです。
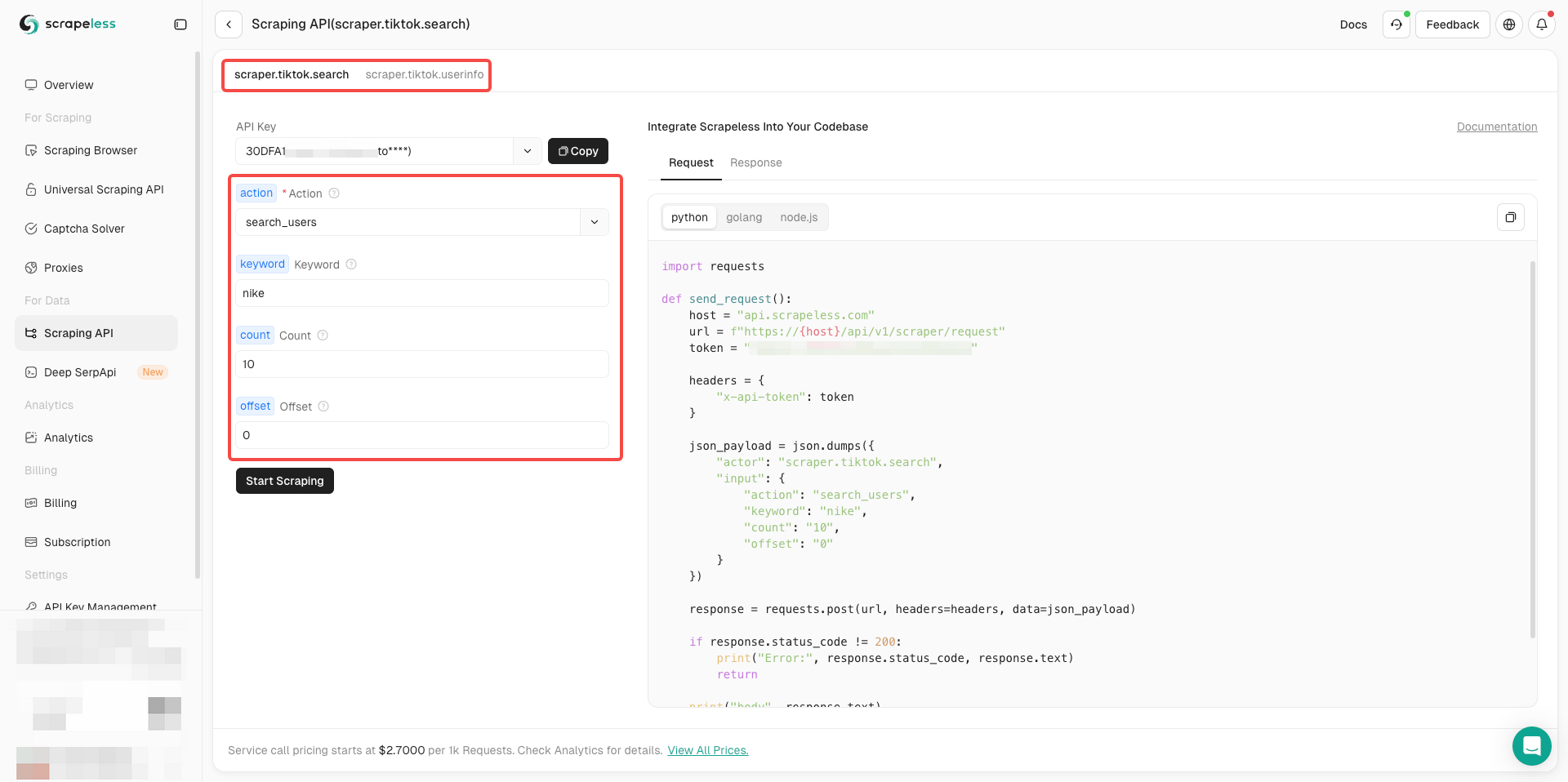
- すべてが正しいことを確認したら、「スクレイピング開始」をクリックするだけで、簡単にスクレイピング結果を取得できます。
今すぐTikTok動画データを取得しましょう!
これで、TikTokからデータを抽出できる動作するスクレイパーができました。これは素晴らしいスタートですが、さらに進めることができます。
TikTokのトレンド分析、調査の実施、データへの好奇心の充足のいずれであっても、多くの頭痛の種を抱えることなく、TikTokデータウェアハウスを探求するための強力なツールが手に入りました。
ScrapelessスクレイピングAPIは、複雑なコードの手間を省きます。いくつかのパラメーターを設定するだけで、最新のデータをすぐに取得できます。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


