
PythonでGoogleニュースをスクレイピングする方法
Advanced Data Extraction Specialist
Googleニュースとは何か
Googleニュースは、Googleが提供するニュース収集サービスです。世界中の主要なニュースウェブサイトから最新のニュース記事を収集、整理、表示します。キーワード、トピック、地域、情報源などでフィルタリングでき、Googleニュースのアルゴリズムはユーザーの興味や閲覧履歴に基づいてパーソナライズされたニュースコンテンツを推薦します。
Googleニュースのデータは主に権威のあるニュース機関、ブログ、政府発表などから取得されるため、世界中のリアルタイム情報の重要な情報源となっています。
Googleニュースから取得できるデータ
- ニュースタイトル(title) - 記事の中心となる内容
- ニュースリンク(link) - 記事の元のソースURL
- 公開日(date) - 記事が公開された時刻(数分前、数時間前、または特定の時刻)
- ニューススニペット(snippet) - 記事内容の簡単なプレビュー
- ニュースソース(source) - CNN、BBC、NYTimesなど、記事が掲載されたメディア機関
- ニュースカテゴリ(category) - テクノロジー、スポーツ、金融、健康など、記事が属するカテゴリ
- 画像リンク(thumbnail) - 記事に添付されている画像へのリンク
- 関連ニュース(related news) - 類似または関連するレポートへのリンク
- ビデオコンテンツ(video) - 含まれるビデオニュース
....
なぜGoogleニュースのデータをクロールするのか
Googleニュースのデータクロールには、多くの実用的なアプリケーションシナリオがあります。最も一般的な用途をいくつか紹介します。
- 市場分析とビジネスインテリジェンス
- 金融および投資分析
- SEOとコンテンツマーケティング
- 機械学習とAI研究
- メディアとニュースアグリゲーションアプリケーション
PythonによるGoogleニュースのスクレイピング方法
ステップ1:Googleニュースデータクロール環境の構築
まず、データクロール環境を構築し、以下のツールを用意する必要があります。
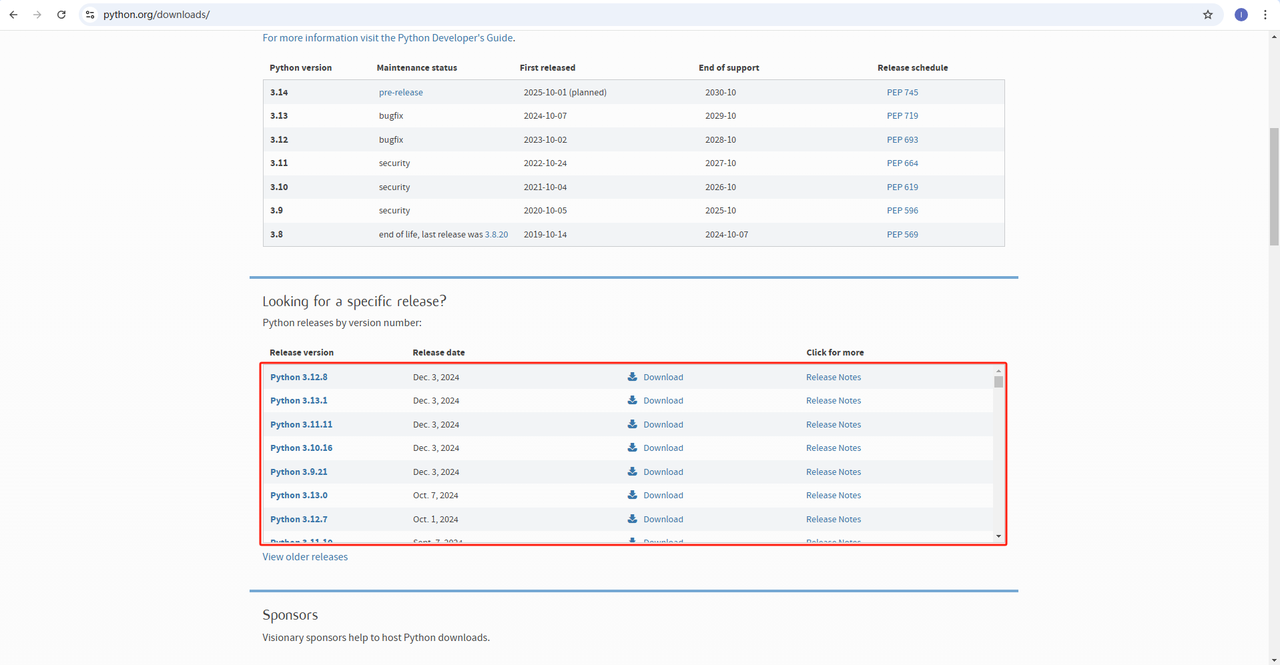
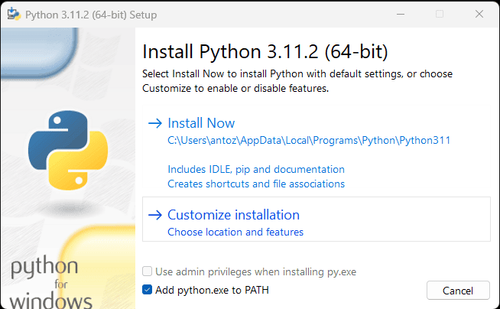
- Python: https://www.python.org/downloads/ これはPythonを実行するためのコアソフトウェアです。下記の図のように公式サイトのリンクから必要なバージョンをダウンロードできますが、最新バージョンをダウンロードしないことをお勧めします。最新バージョンから1~2つ前のバージョンをダウンロードすることをお勧めします。
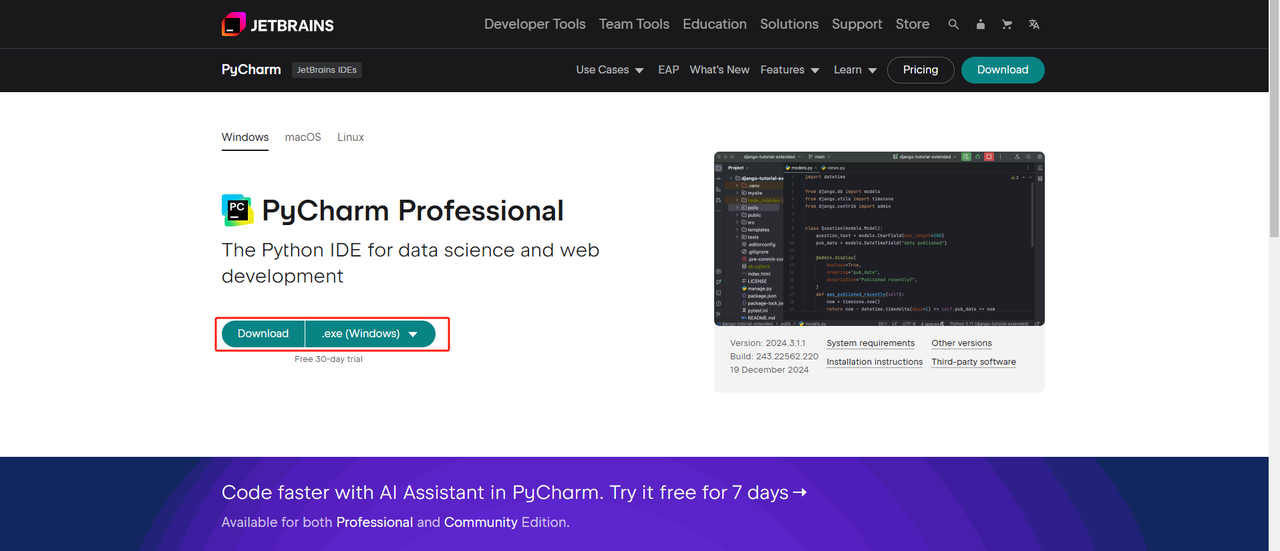
- Python IDE:PythonをサポートするIDEであればどれでも構いませんが、Python専用に設計されたIDE開発ツールソフトウェアであるPyCharmをお勧めします。PyCharmのバージョンについては、無料のPyCharm Community Editionをお勧めします。
- Pip:Python Package Indexを使用して、単一のコマンドでプログラムの実行に必要なライブラリをインストールできます。
注:Windowsユーザーの場合は、インストールウィザードで「Add python.exe to PATH」オプションを選択することを忘れないでください。これにより、WindowsはターミナルでPythonとコマンドを使用できるようになります。Python 3.4以降にはデフォルトで含まれているため、手動でインストールする必要はありません。
上記の手順により、Googleニュースデータクロールのための環境が設定されます。次に、ダウンロードしたPyCharmとScraperlessを組み合わせてGoogleニュースデータをクロールできます。
ステップ2:PyCharmとScrapelessを使用したGoogleニュースデータのスクレイピング
- PyCharmを起動し、メニューバーから[ファイル]>[新規プロジェクト…]を選択します。
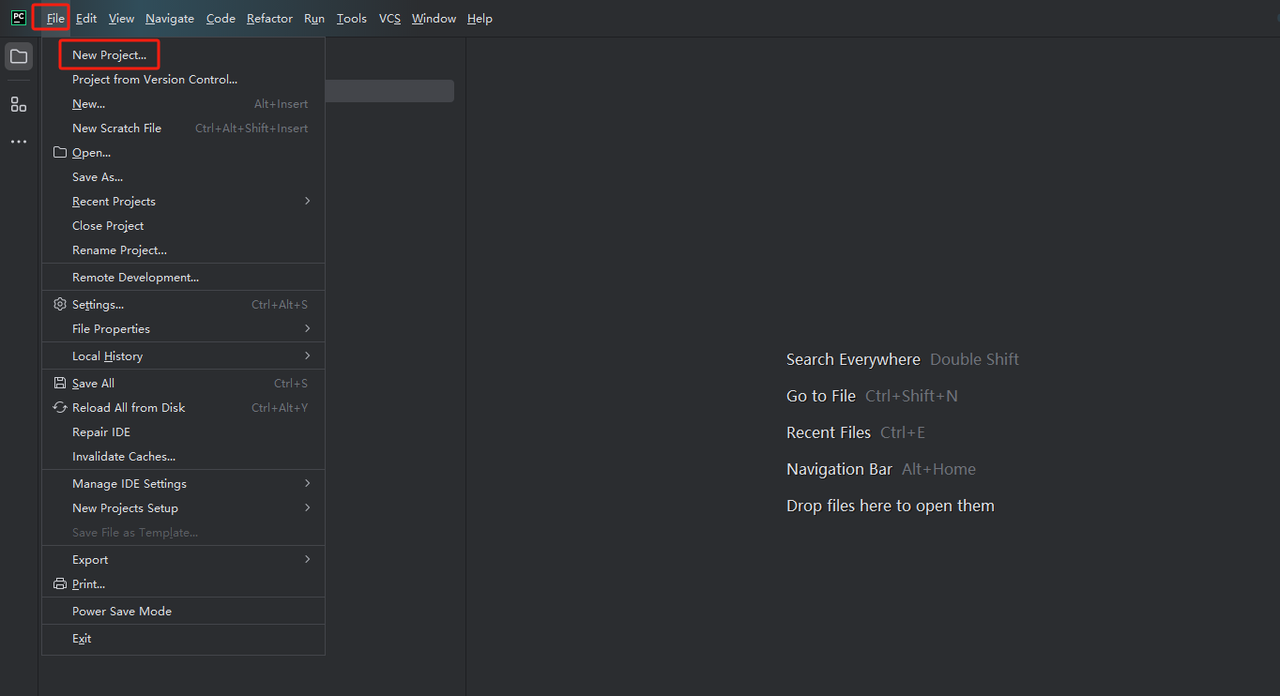
- 次に、表示されるウィンドウで、左側のメニューから[Pure Python]を選択し、プロジェクトを次のように設定します。
注:下の赤いボックスで、環境設定の最初のステップでダウンロードしたPythonのインストールパスを選択します。
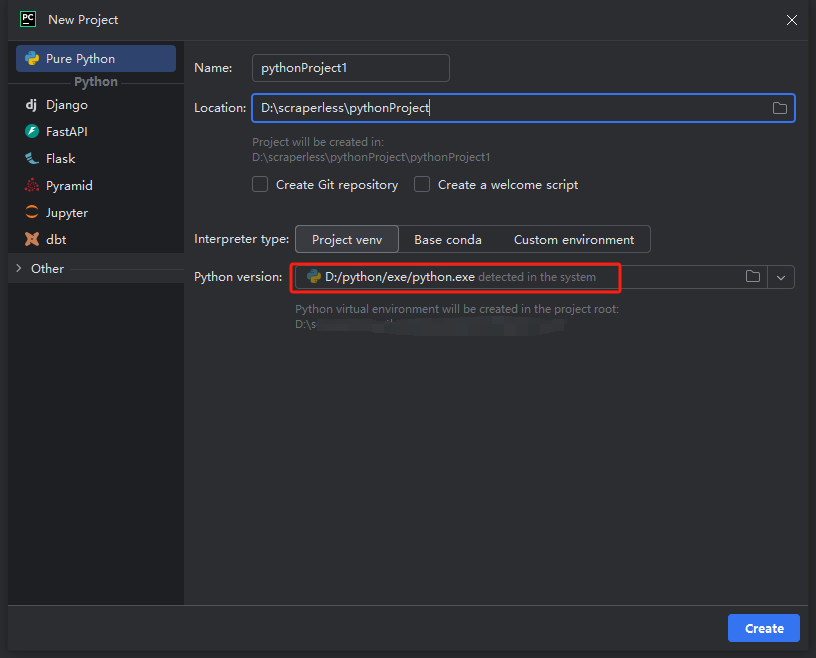
python-scraperというプロジェクトを作成し、「Create main.py welcome script option in the folder」にチェックを入れて「作成」ボタンをクリックします。PyCharmがしばらくプロジェクトを設定した後、次のようになります。
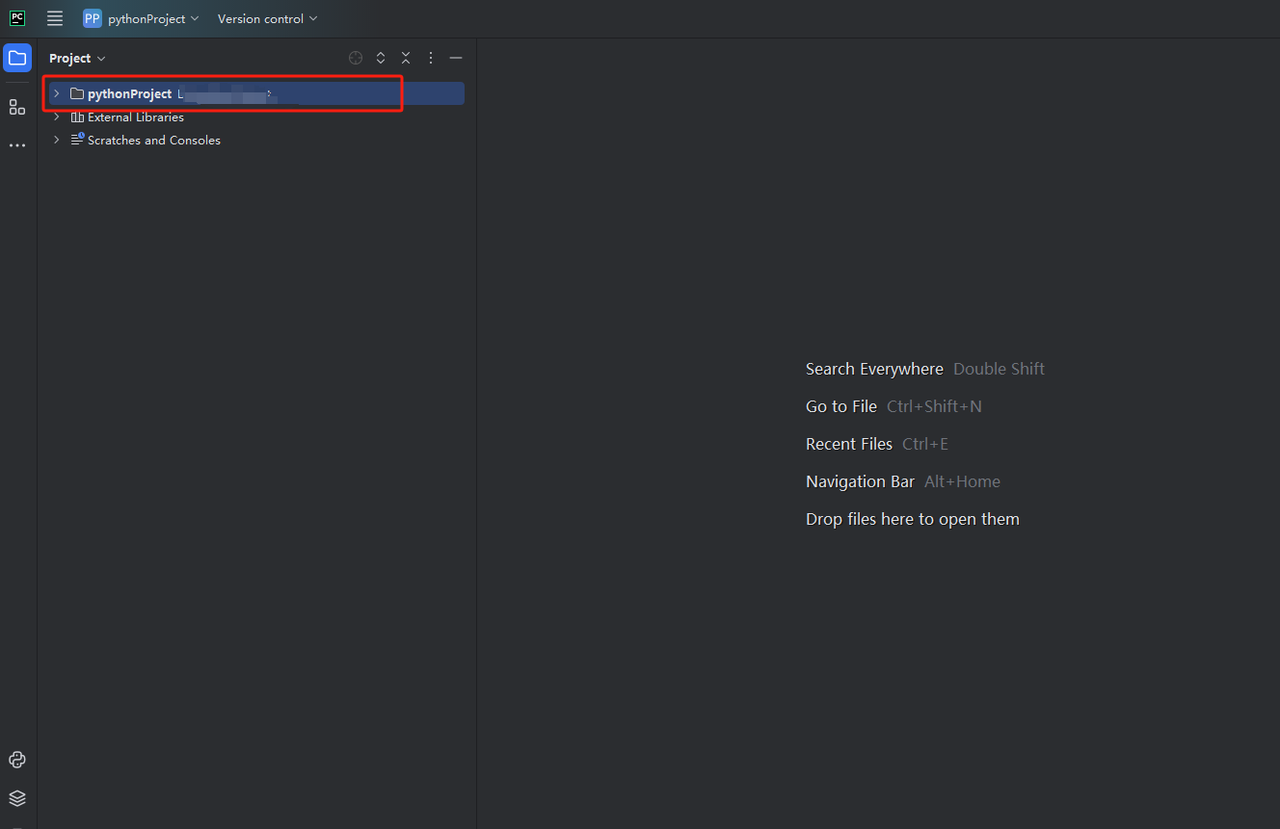
- 次に、右クリックして新しいPythonファイルを作成します。
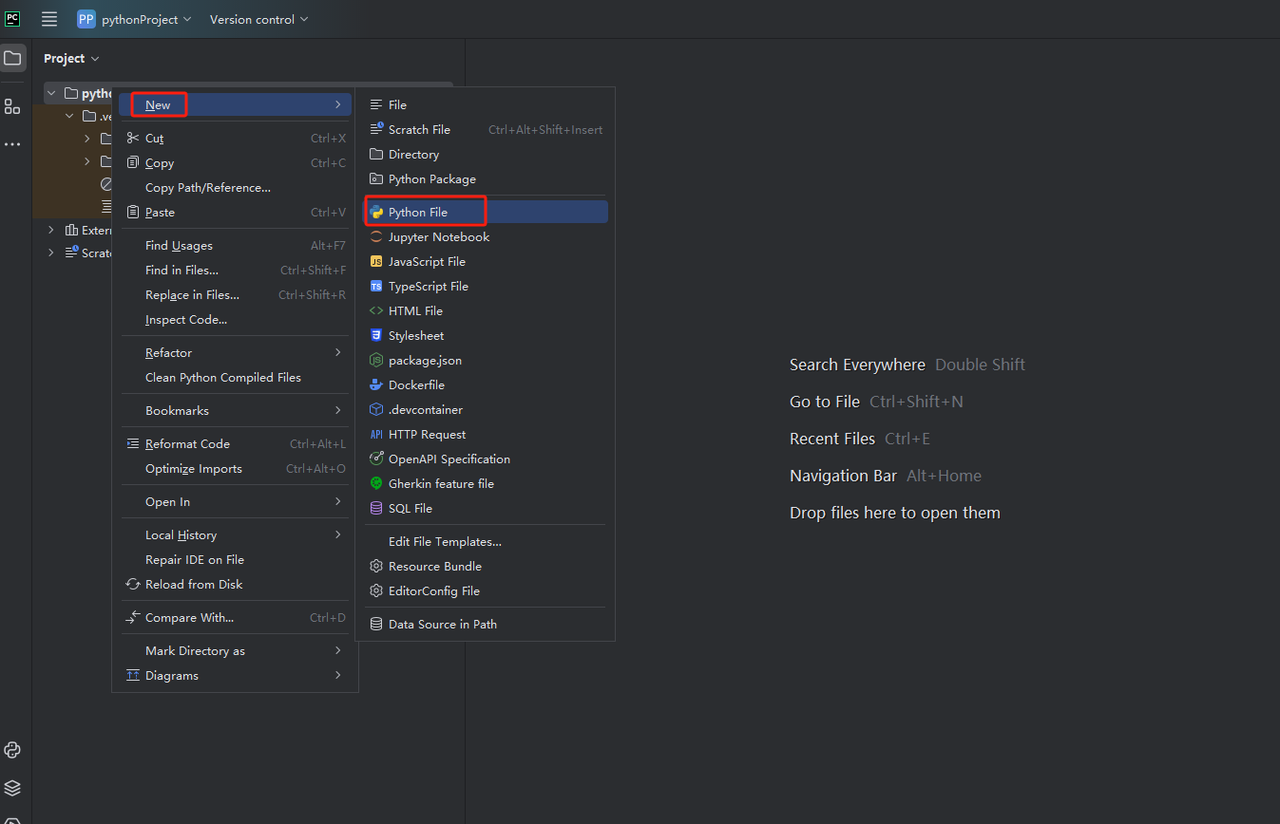
- すべてが正しく機能していることを確認するには、画面下部の[ターミナル]タブを開き、「python main.py」と入力します。このコマンドを実行すると、「Hi, PyCharm.」が表示されます。
ステップ3:Scrapeless APIキーの取得
これで、ScrapelessのコードをPyCharmに直接コピーして実行できるため、GoogleニュースのJSON形式データを取得できます。ただし、最初にScrapeless APIキーを取得する必要があります。手順は次のとおりです。
アカウントをお持ちでない場合は、Scrapelessにサインアップしてください。サインアップ後、ダッシュボードにログインします。
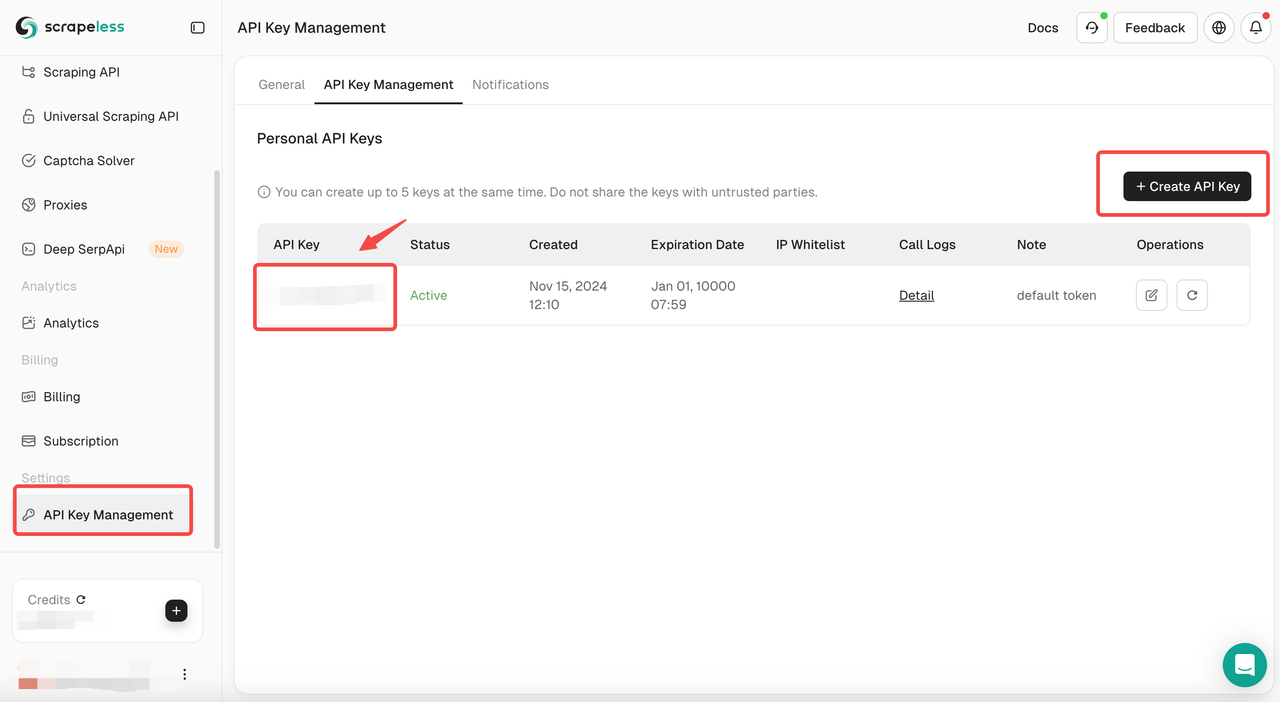
Scrapelessダッシュボードで、APIキー管理に移動し、APIキーの作成をクリックします。APIキーが取得されます。マウスをキーの上に置いてクリックすると、コピーできます。このキーは、Scrapeless APIを呼び出す際の認証に使用されます。
ステップ4:スクレイピングツールへのScrapeless APIの統合方法
APIキーを取得したら、独自のスクレイピングツールにScrapeless APIを統合できます。Pythonとrequestsを使用してScrapeless APIを呼び出し、データを取得する方法の例を次に示します。
Scrapeless APIを使用したGoogleニュース情報のクロールサンプルコード:
python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_news",
"q": "pizza",
"gl": "us",
"hl": "en",
}
payload = Payload("scraper.google.news", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()IPブロック、CAPTCHA、絶えず変化するHTML構造に対処することにうんざりしていませんか?
Scrapeless Google News APIを使用すると、制限を回避し、リアルタイムのニュースデータを抽出し、開発時間を節約できます。すべて簡単なAPI呼び出しで行えます!
なぜ自分でスクレイピングするのではなくScrapelessを選ぶのか
✅ 超低価格、1,000クエリあたりわずか0.1ドル
独自のクローラーを構築したり、プロキシIPを維持したり、反クローラー対策を回避したりするのに比べて、SerpApiの価格は非常に競争力があり、1,000クエリあたりわずか0.1ドルで、データ取得のコストを大幅に削減できます。
✅ 超高速レスポンス、3秒以内にデータが返されます
Scrapelessは超高速のデータクロール機能を備えており、リクエスト後3秒以内に構造化されたJSONデータを返すことができます。これは、従来のクローラーの処理速度よりもはるかに高速です。
✅ メンテナンス不要、IPブロックと反クローラー対策を心配する必要はありません
Googleは異常なトラフィックを検出し、IPをブロックし、さらに認証コードの確認を要求する場合があります。Scrapelessはすべての反クローラーの問題に対処し、APIリクエストが常に利用可能であり、CAPTCHAやIPブロックをトリガーしないようにします。
✅ 精度の高い検索、オンデマンドでニュースデータをフィルタリング
キーワード、公開日時、ニュースソースなどの条件でニュースをフィルタリングし、最も関連性の高いデータを取得し、無関係な情報の干渉を回避できます。
Scrapeless Google News API
🔹 超低価格 – 1,000クエリあたりわずか0.1ドル
🔹 超高速 – 3秒以内にデータが返されます
🔹 安定性と効率性 – IPブロックなし、メンテナンス不要
👉 Googleニュースデータを簡単にスクレイピングするには、今すぐScrapelessをお試しください!
Scrapeless Deep SerpAPI:より高速で幅広いデータクロールソリューション

より包括的で効率的なデータ取得ソリューションが必要な場合は、Scrapeless Deep SerpAPIを試してみる価値があります!
✅ より幅広いデータカバレッジ – 20以上のGoogle検索APIシナリオインターフェース
✅ リアルタイムデータの更新 – 過去24時間のデータはいつでも利用可能
✅ 超低コスト – 1,000クエリあたりわずか0.10ドル
✅ 超高速レスポンス – データは1~2秒で返され、従来のAPIをはるかに上回ります
👉 今すぐScrapeless Deep SerpAPIを試して、Google検索データを簡単にクロールしましょう!
無料の開発者サポート:
Scrapeless Deep SerpApiをAIツール、アプリケーション、またはプロジェクトに統合します(すでにDifyをサポートしており、Langchain、Langflow、FlowiseAIなどのフレームワークも今後サポートする予定です)。
統合結果をソーシャルメディアで共有すると、1~12ヶ月の無料開発者サポート(月間最大500,000回の使用)を受けられます。
この機会にプロジェクトを改善し、より多くの開発サポートをお楽しみください!
まとめ
この記事では、Pythonを使用してGoogleニュースをスクレイピングする方法について説明しました。コンテンツをスクレイピングする際には、Googleの使用ポリシーと制限事項に従い、法令遵守を確保する必要があります。
関連リソース
Kayakからのフライトデータのスクレイピング方法
PowerShellでのSeleniumの使い方
Scrapelessを使用したGoogle求人のスクレイピングによる求人リストの作成方法
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


