
Scrapelessを使ったGoogle Lens結果のスクレイピング方法
Advanced Data Extraction Specialist
Google Lens とは何ですか?
Google Lensは、人工知能と画像認識技術に基づいたアプリケーションで、カメラや画像を通してオブジェクト、テキスト、ランドマーク、その他のコンテンツを識別し、関連情報を提供できます。
Google Lensからのデータスクレイピングは合法ですか?
Google Lensデータのスクレイピングは違法ではありませんが、従うべき様々な法的および倫理的なガイドラインがあります。ユーザーは、Googleの利用規約、データプライバシー法、知的財産権を理解して、活動が準拠していることを確認する必要があります。ベストプラクティスに従い、法的な動向に関する情報を常に得ることで、ウェブスクレイピングに関連する法的問題のリスクを最小限に抑えることができます。
Google Lensスクレイピングの課題
- 高度な反ボット技術:Googleはネットワークトラフィックパターンを監視しています。クローラーからの多数の繰り返し要求は迅速に検出され、IP禁止につながり、クロールプロセスを停止します。
推奨読書:Anti-Bot:それは何か、そしてそれを回避する方法 - JavaScriptでレンダリングされたコンテンツ:Google Lensのデータの大部分はJavaScriptによって動的に生成されるため、従来のクローラーではアクセスできず、PuppeteerやSeleniumなどのヘッドレスブラウザを使用する必要がありますが、これにより複雑さとリソース消費が増加します。
- CAPTCHA保護:GoogleはCAPTCHAを使用して人間のユーザーを認証します。クローラーは、プログラムで解決が難しいCAPTCHAの課題に遭遇する可能性があります。
- 頻繁なウェブサイトの更新:GoogleはGoogle Lensの構造とレイアウトを定期的に変更します。クロールコードはすぐに古くなり、データ抽出に使用されるXPathまたはCSSセレクターが機能しなくなる可能性があります。継続的な監視と更新が必要です。
Pythonを使用したGoogle Lensスクレイピングの手順ガイド
手順1. 環境の設定
- Python:ソフトウェアはPythonを実行するためのコアです。下記のように公式ウェブサイトから必要なバージョンをダウンロードできます。ただし、最新バージョンをダウンロードすることはお勧めしません。最新バージョンより1.2バージョン前のバージョンをダウンロードできます。
- Python IDE:PythonをサポートするIDEであればどれでも機能しますが、PyCharmをお勧めします。Python用に特別に設計された開発ツールです。PyCharmのバージョンについては、無料のPyCharm Community Editionをお勧めします。
注記: Windowsユーザーの場合は、インストールウィザードで「Add python.exe to PATH」オプションをチェックすることを忘れないでください。これにより、WindowsはターミナルでPythonとコマンドを使用できるようになります。Python 3.4以降にはデフォルトで含まれているため、手動でインストールする必要はありません。
これで、ターミナルまたはコマンドプロンプトを開いて次のコマンドを入力することで、Pythonがインストールされているかどうかを確認できます。
python --version手順2. 依存関係のインストール
プロジェクトの依存関係を管理し、他のPythonプロジェクトとの競合を避けるために、仮想環境を作成することをお勧めします。ターミナルでプロジェクトディレクトリに移動し、次のコマンドを実行して、google_lensという名前の仮想環境を作成します。
python -m venv google_lensシステムに基づいて仮想環境をアクティブ化します。
Windows:
google_lens_env\Scripts\activateMacOS/Linux:
source google_lens_env/bin/activate仮想環境をアクティブ化した後、ウェブスクレイピングに必要なPythonライブラリをインストールします。Pythonでリクエストを送信するためのライブラリはrequestsで、データスクレイピングの主なライブラリはBeautifulSoup4です。次のコマンドを使用してインストールします。
pip install requests
pip install beautifulsoup4
pip install playwright手順3. データのスクレイピング
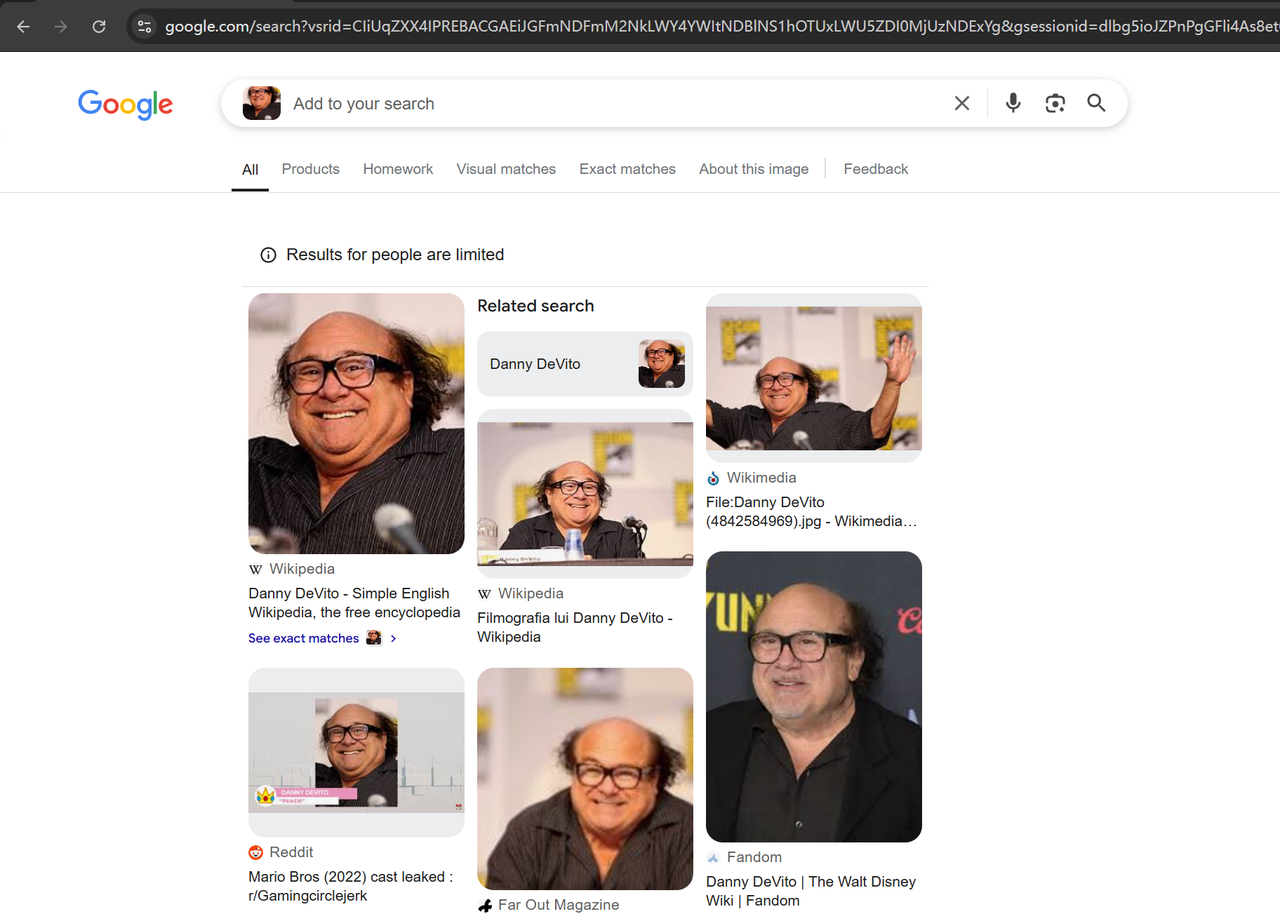
ブラウザでGoogle Lens(https://www.google.com/?olud)を開き、「https://i.imgur.com/HBrB8p0.png」を検索します。検索結果は次のとおりです。
タイトルと画像情報のスクレイピング
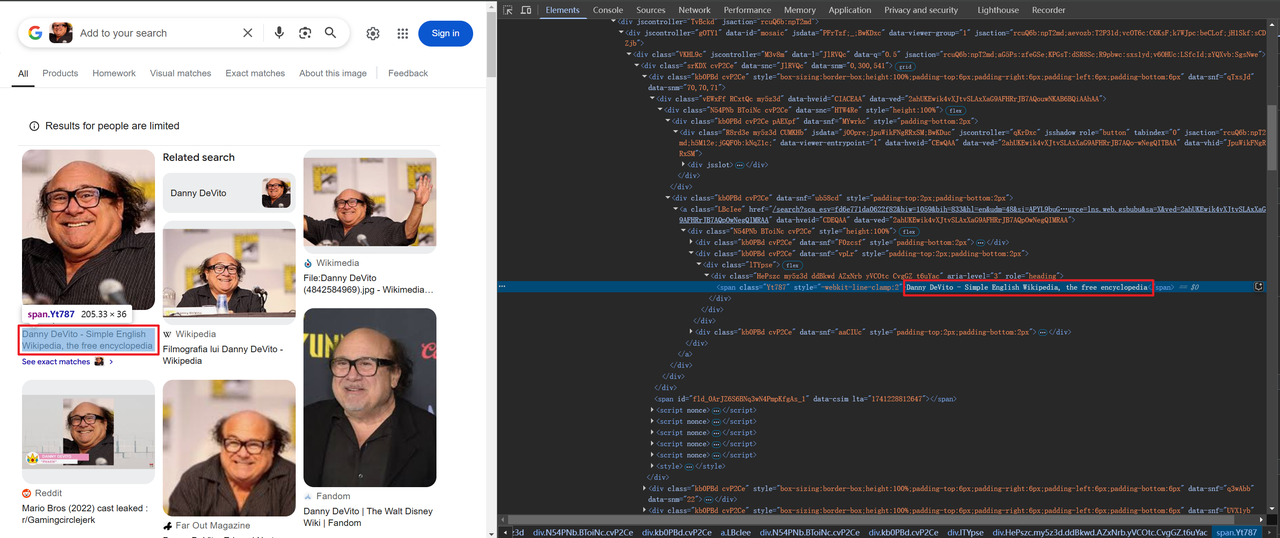
一部の画像はbase64でエンコードされ、その他はHTTPを介してリンクされています。例:
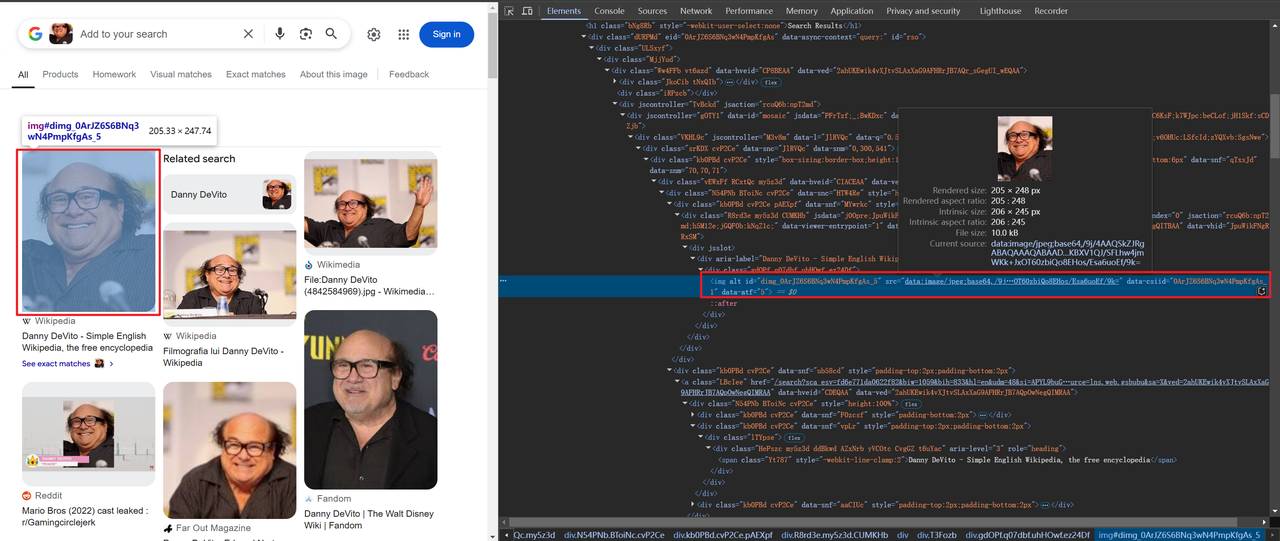
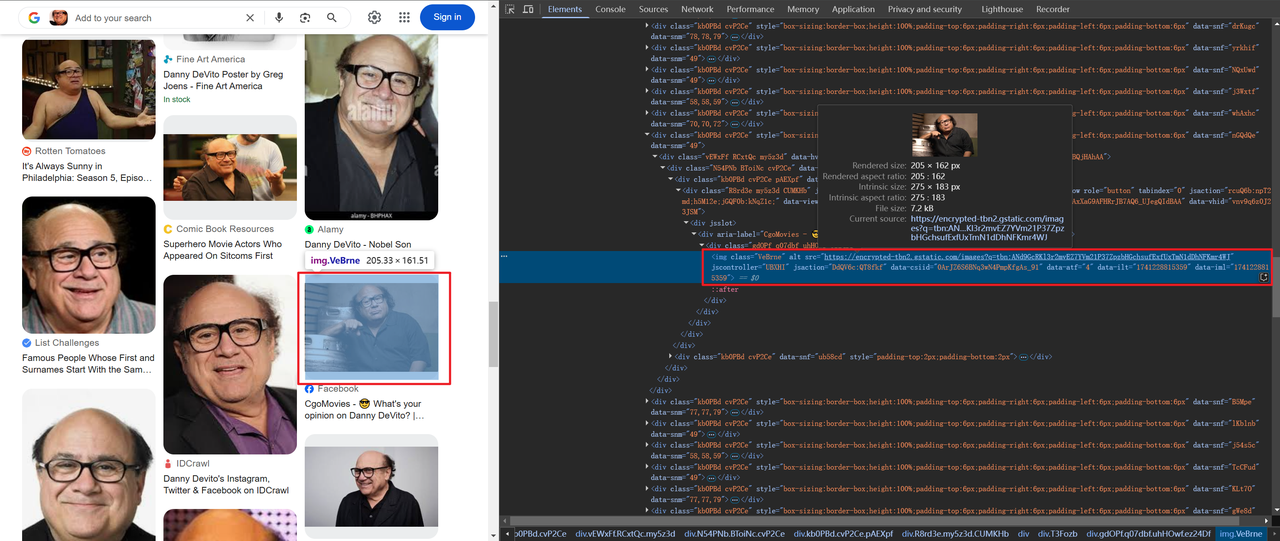
タイトルと画像情報を取得するためのコードは次のとおりです。
# lens情報を辞書に格納
img_info = {
'title': item.find("span").text,
'thumbnail': item.find("img").attrs['src'],
}ページ上のすべてのデータ(1つだけではない)をスクレイピングする必要があるため、ループして上記のデータをスクレイピングする必要があります。完全なコードは次のとおりです。
import json
from bs4 import BeautifulSoup
from playwright.sync_api import sync_playwright
def scrape(url: str) -> str:
with sync_playwright() as p:
# ブラウザを起動し、検出を引き起こす可能性のある機能を無効にする
browser = p.chromium.launch(
headless=True,
args=[
"--disable-blink-features=AutomationControlled",
"--disable-dev-shm-usage",
"--disable-gpu",
"--disable-extensions",
],
)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
bypass_csp=True,
)
page = context.new_page()
page.goto(url)
page.wait_for_selector("body", state="attached")
# ページが完全に読み込まれたりレンダリングされたりするのを確認するために2秒間待つ
page.wait_for_timeout(2000)
html_content = page.content()
browser.close()
return html_content
def main():
url = "https://lens.google.com/uploadbyurl?url=https%3A%2F%2Fi.imgur.com%2FHBrB8p0.png"
html_content = scrape(url)
soup = BeautifulSoup(html_content, 'html.parser')
# ページのメインデータを取得する
items = soup.find('div', {'jscontroller': 'M3v8m'}).find("div")
# 円形アセンブリ
assembly = lens_info(items)
# 結果をJSONファイルに保存する
with open('google_lens_data.json', 'w') as json_file:
json.dump(assembly, json_file, indent=4)
def lens_info(items):
lens_data = []
for item in items:
# lens情報を辞書に格納
img_info = {
'title': item.find("span").text,
'thumbnail': item.find("img").attrs['src'],
}
lens_data.append(img_info)
return lens_data
if __name__ == "__main__":
main()手順4. 結果の出力
PyCharmディレクトリにgoogle_lens_data.jsonという名前のファイルが生成されます。出力は次のとおりです(部分的な例)。
[
{
"title": "Danny DeVito - Wikipedia",
"thumbnail": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBxAQEhAQEBAQEB
},
{
"title": "Devito Danny Royalty-Free Images, Stock Photos & Pictures | Shutterstock",
"thumbnail": "https://encrypted-tbn1.gstatic.com/images?q=tbn:ANd9GcSO6Pkv_UmXiianiCh52nD5s89d7KrlgQQox-f-K9FtXVILvHh_"
},
{
"title": "DATA | Celebrity Stats | Page 62",
"thumbnail": "https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcQ9juRVpW6sjE3OANTKIJzGEkiwUpjCI20Z1ydvJBCEDf3-NcQE"
},
{
"title": "Danny DeVito, Grand opening of Buca di Beppo italian restaurant on Universal City Walk Universal City, California - 28.01.09 Stock Photo - Alamy",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQq_07f-Unr7Y5BXjSJ224RlAidV9pzccqjucD4VF7VkJEJJqBk"
}
]より効率的なツール:Scrapelessを使用したGoogle Lensの結果のスクレイピング
Scrapelessは、開発者が複雑なコードを記述することなく、Google Lensの検索結果を簡単にスクレイピングできる強力なツールを提供します。Scrapeless APIをPythonクローラーツールに統合する詳細な手順を以下に示します。
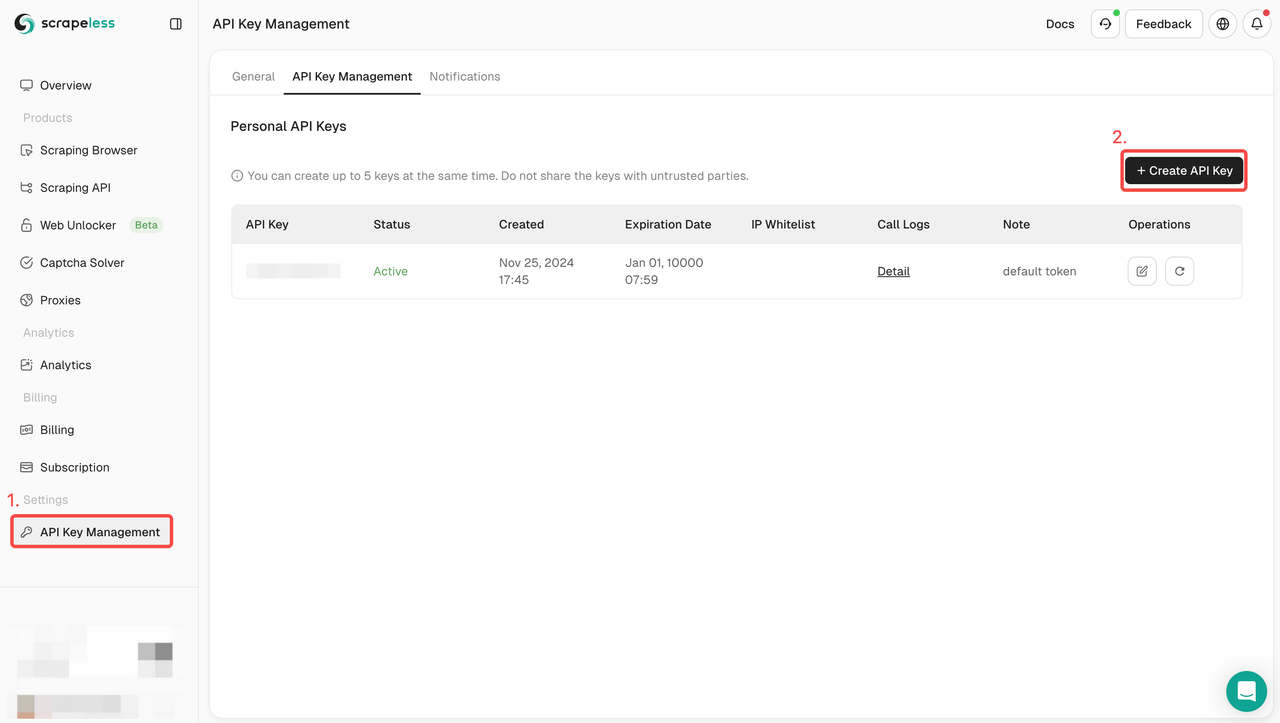
手順1:ScrapelessにサインアップしてAPIキーを取得する
- まだScrapelessアカウントを持っていない場合は、Scrapeless Webサイトにアクセスしてサインアップしてください。
- サインアップしたら、ダッシュボードにログインします。
- ダッシュボードで、APIキー管理に移動し、APIキーの作成をクリックします。生成されたAPIキーをコピーします。これは、Scrapeless APIを呼び出す際の認証資格情報になります。
手順2:Scrapeless APIを統合するPythonスクリプトを作成する
Scrapeless APIを使用してGoogle Lensの結果をスクレイピングするためのサンプルコードを以下に示します。
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
engine: "google_lens",
hl: "en",
country: "jp",
url: "https://s3.zoommer.ge/zoommer-images/thumbs/0170510_apple-macbook-pro-13-inch-2022-mneh3lla-m2-chip-8gb256gb-ssd-space-grey-apple-m25nm-apple-8-core-gpu_550.jpeg",
}
payload = Payload("scraper.google.lens", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()注記
APIキーのセキュリティ:パブリックコードリポジトリでAPIキーを公開しないようにしてください。
クエリ最適化:より正確な結果を得るために、必要に応じてクエリパラメータを調整します。APIパラメータの詳細については、Scrapelessの公式APIドキュメントを確認できます。
Google LensのスクレイピングにScrapelessを選択する理由
Scrapelessは、効率的で安定したWebスクレイピングのために設計された強力なAI駆動型Webスクレイピングツールです。
1. リアルタイムデータと高品質の結果
ScrapelessはリアルタイムのGoogle Lens検索結果を提供し、1〜2秒以内にGoogle Lens検索結果を返すことができます。ユーザーが取得するデータが常に最新の状態であることを保証します。
2. 手頃な価格
Scrapelessの価格は非常に競争力があり、1,000件のクエリあたりわずか0.1ドルという価格です。
3. 強力な機能サポート
Scrapelessは、20以上のGoogle検索結果シナリオを含む複数の検索タイプをサポートしています。JSON形式で構造化されたデータを返すことができ、ユーザーは迅速に解析して使用できます。
Scrapeless Deep SerpAPI:強力なリアルタイム検索データソリューション
Scrapeless Deep SerpApiは、AIアプリケーションと検索拡張生成(RAG)モデル用に設計されたリアルタイム検索データプラットフォームです。リアルタイムで正確かつ構造化されたGoogle検索結果データを提供し、Google検索、Googleトレンド、Googleショッピング、Googleフライト、Googleホテル、Googleマップなど、20種類以上のGoogle SERPタイプをサポートしています。

主要機能
- リアルタイムデータ更新:過去24時間以内のデータ更新に基づいて、情報のタイムリーさと正確性を確保します。
- 多言語および地理位置情報のサポート:多言語および地理位置情報をサポートし、ユーザーの位置、デバイスの種類、言語に基づいて検索結果をカスタマイズできます。
- 高速な応答:平均応答時間はわずか1〜2秒で、高頻度および大規模なデータ取得に適しています。
- シームレスな統合:Python、Node.js、Golangなどの主流のプログラミング言語と互換性があり、既存のプロジェクトに簡単に統合できます。
- 費用対効果が高い:1,000件のクエリあたり0.1ドルという価格で、市場で最も費用対効果の高いSERPソリューションです。
特別オファー
- 無料トライアル:無料トライアルが提供されており、ユーザーはすべての機能を体験できます。
- デベロッパーサポートプログラム:最初の100人のユーザーは、50ドル相当(500,000件のクエリ)の無料APIコールクォータを取得でき、テストおよび拡張プロジェクトに適しています。
DiscordリンクをクリックしてLiamに連絡すると、ご質問やカスタマイズ要件についてお問い合わせいただけます。
まとめ
この記事では、Scrapelessを使用してGoogle Lensの検索結果をクロールする方法について詳しく説明しました。Scrapelessが提供する強力なAPIにより、開発者と研究者は、複雑なコードを記述したり、反クロールメカニズムを心配したりすることなく、リアルタイムで高品質の視覚データを取得できます。Scrapelessの効率性と柔軟性により、Google Lensデータの処理に最適なツールとなっています。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。



{kind=link}