
Puppeteer を使用して Cloudflare をバイパスする方法
Advanced Data Extraction Specialist
データ収集とウェブクローリングの分野では、開発者はしばしば厄介な問題に直面します。それは、Cloudflareの保護メカニズムを効果的に回避する方法です。世界中で広く使用されているウェブサイトのセキュリティとパフォーマンス最適化サービスであるCloudflareの反クローリング機能とファイアウォール機能は、データクローリングに大きな課題をもたらします。この問題は、Puppeteerをウェブクローリングに使用する場合に特に顕著です。この記事では、Scrapeless Scraping BrowserとPuppeteerを組み合わせて、Cloudflareの制限を容易に突破し、効率的で安定したデータ収集の旅を始める方法を詳細に探ります。
Cloudflareがボットを検出する方法
Cloudflareは、以下の技術を組み合わせてボットを検出します。
- 振る舞い分析 - マウスの動き、キーストローク、スクロール動作、インタラクションパターンを監視して、人間のユーザーとボットを区別します。
- IPレピュテーション - グローバルな脅威インテリジェンスデータベースを使用して、過去の活動に基づいて疑わしいIPアドレスを特定します。
- チャレンジレスポンステスト - CAPTCHAやJavaScriptチャレンジを展開して、訪問者が人間かどうかを確認します。
- フィンガープリンティング - ブラウザの特性、HTTPヘッダー、デバイス属性を分析して、自動化を検出します。
- レート制限 - 高頻度または非人間のブラウジング動作など、異常なリクエストパターンにフラグを立てます。
- 機械学習 - 膨大な量のトラフィックデータでトレーニングされたAIモデルを使用して、ボットのような動作を特定します。
- TLSフィンガープリンティング - TLS接続の確立方法を調べて、実際のブラウザと自動化されたスクリプトを区別します。
- JavaScript実行監視 - JavaScriptが正しく実行されているかどうかをチェックして、スクリプトを無効にするヘッドレスブラウザとボットを検出します。
PuppeteerだけではCloudflareをバイパスできない理由
重要なキーワード「Cloudflareをバイパス」を含めた翻訳を以下に示します。
1. Cloudflareの複雑な検出メカニズム
Cloudflareは、振る舞い分析、IPレピュテーションチェック、HTTPフィンガープリンティングなど、複数の方法を使用して、人間のユーザーとPuppeteerのような自動化ツールを区別して検出します。これらのメカニズムにより、PuppeteerだけではCloudflareをバイパスすることが困難になります。
2. Puppeteerのデフォルトの動作は容易に識別される
デフォルトでは、Puppeteerは次のような、人間のユーザーとは異なる動作を示します。
- 典型的なブラウザと一致しない固定されたユーザーエージェント文字列。
- 不自然なマウスの動きやクリックパターンなど、人間のようなインタラクションの欠如。
- 自動化ツールであることを明らかにする独特のリクエストヘッダー。
3. Cloudflareのチャレンジメカニズム
Cloudflareが疑わしいトラフィックを検出すると、CAPTCHAや検証ステップなどのチャレンジがトリガーされます。Puppeteerだけではこれらのチャレンジを解決できないため、追加のツールなしではCloudflareをバイパスすることは不可能です。
4. 追加の設定とツールの必要性
Cloudflareをバイパスするには、Puppeteerに追加の設定が必要です。例えば:
- ランダムな遅延と現実的なインタラクションで人間の行動をシミュレートする。
- プロキシIPを使用してIPブロックを回避する。
- 実際ブラウザを模倣するようにリクエストヘッダーを変更する。
- 2CaptchaのようなCAPTCHA解決サービスを統合する。
5. 継続的に更新される検出ルール
Cloudflareは検出アルゴリズムを定期的に更新するため、古いバイパス方法は時間の経過とともに無効になります。
要約すると、PuppeteerだけではCloudflareの検出を回避することは困難です。人間の行動をシミュレートし、Cloudflareのチャレンジを効果的に処理するには、他の技術やツールと組み合わせる必要があります。
方法#1:puppeteer-extra-plugin-stealthを使用したCloudflareのバイパス
puppeteer-extra-plugin-stealthは、Puppeteerの自動化されたブラウザのプロパティをマスクし、実際のブラウザのように見せることでCloudflareをバイパスするのに役立つパッチです。
例えば、StealthプラグインはWebDriverプロパティをオーバーライドし、HeadlessChromeフラグをChromeに置き換えて自動化シグナルをマスクします。また、chrome.runtimeなど、他の正当なブラウザプロパティもモックし、ヘッドレスモードでもヘッドフルのように見せかけます。
Puppeteer Stealthプラグインは、基本Puppeteerと同様のAPIを使用するため、既にPuppeteerを使用している開発者にとって学習曲線はありません。
簡単なCloudflare保護のあるウェブサイトであるCoinTrackerをバイパスして、Puppeteer Stealthの動作を確認してみましょう。
まず、プラグインをインストールします。
npm install puppeteer-extra puppeteer-extra-plugin-stealth次に、必要なライブラリをインポートし、Stealthプラグインを追加します。その後、保護されたウェブサイトをリクエストし、ホームページのスクリーンショットを撮ります。
// npm install puppeteer-extra puppeteer-extra-plugin-stealth
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
// add the stealth plugin
puppeteer.use(StealthPlugin());
(async () => {
// set up browser environment
const browser = await puppeteer.launch();
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://sailboatdata.com/sailboat/11-meter/', {
waitUntil: 'load',
});
// take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();Puppeteer StealthプラグインはCloudflareをバイパスし、ウェブサイトのホームページのスクリーンショットを撮影します。
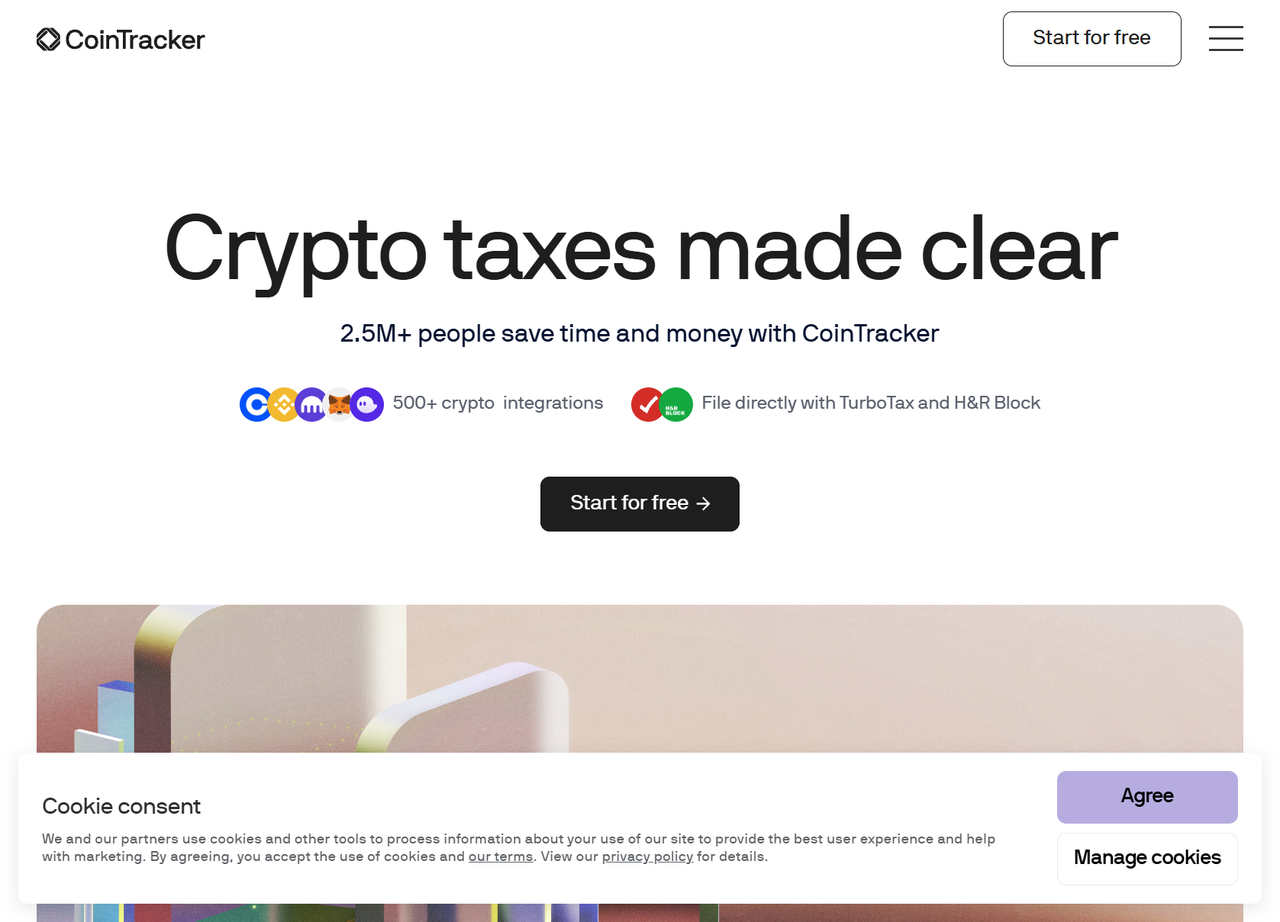
Cloudflareの検出を回避することに成功しました。
もちろん、現在のターゲットウェブサイトは高度な検出技術を適用していないため、アクセスが容易です。
Puppeteer Stealthプラグインは、より高度なセキュリティ対策を処理できますか?答えは…
図のように、Stealthプラグインはブロックされています。
Puppeteer Stealthプラグインの制限
一部のウェブサイトでは、他のウェブサイトよりも高度なCloudflareセキュリティチェックが使用されています。このような場合、Puppeteer-extra-plugin-stealth Cloudflare回避テクニックを使用してPuppeteerの自動化プロパティをマスクしても、突破するには不十分です。
たとえば、Cloudflare Challengeページにアクセスしようとしたときに、Puppeteer Stealthがブロックされました。
前のターゲットURLをチャレンジページURLに置き換えて、自分で試してみてください。
// npm install puppeteer-extra puppeteer-extra-plugin-stealth
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
// add the stealth plugin
puppeteer.use(StealthPlugin());
(async () => {
// set up browser environment
const browser = await puppeteer.launch();
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {
waitUntil: 'networkidle0',
});
// wait for the challenge to resolve
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
// take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();Stealthプラグインはブロックされました。
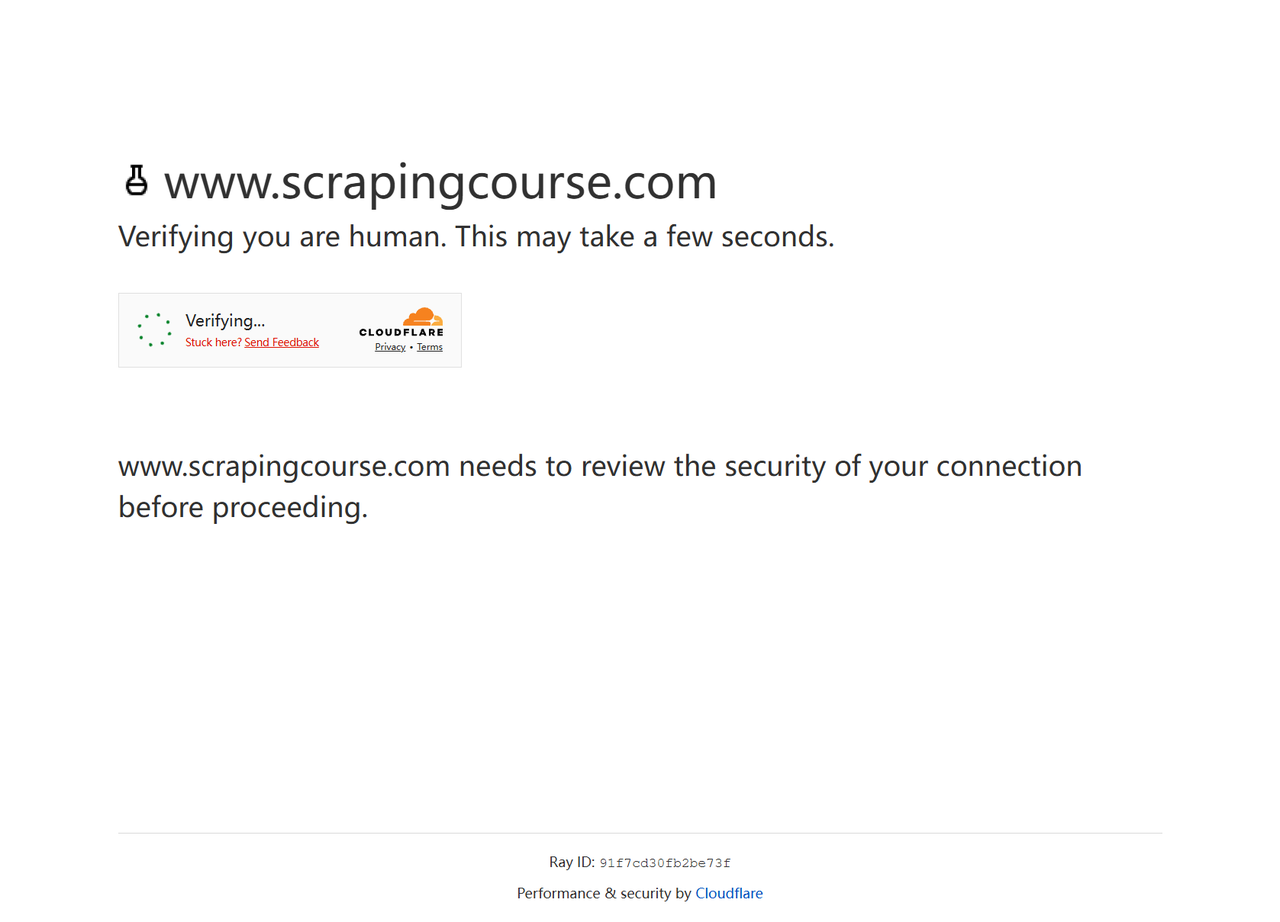
結果は、より高度なCloudflareボット対策システムがStealthプラグインをボットとして検出したことを示しています。Stealthプラグインには、不整合なWebGLまたはCanvasレンダリングなど、まだ検出可能な特性があり、ボットとして認識されています。
これらの制限をどのように解決し、複雑なウェブサイトからデータを取得できますか?答えはScrapelessです。
方法#2:ScrapelessとPuppeteerを使用したCloudflareのバイパス
PuppeteerとそのStealthプラグインの制限を回避する最も簡単な方法は、ライブラリをScrapeless Scraping Browserと統合することです。Scrapeless Scraping Browserを使用すると、Puppeteerスクレイパーは高度な回避策で強化され、人間のように見え、ボット対策検出をバイパスします。
必要なのは、既存のPuppeteerスクリプトに1行のコードを追加するだけで、Scraping Browserが主要なブラウザフィンガープリンティングの処理、不足しているプラグインと拡張機能の追加、住宅プロキシローテーションの管理などを支援します。
Scraping Browserはクラウドでも実行されるため、ローカルブラウザインスタンスを実行する際のメモリオーバーヘッドを防ぎます。この機能により、高度なスケーラビリティを実現します。
Scrapeless Scraping Browserの主な機能
Scrapeless Scraping Browserは、効率的で大規模なウェブデータ抽出のために設計されたツールです。
- ブラウザフィンガープリンティングやTLSフィンガープリンティング検出などの高度な反クローリングメカニズムをバイパスするために、実際の人間のインタラクション動作をシミュレートします。
- cf_challengeなど、複数の種類の検証コードの自動解決をサポートし、中断のないクロールプロセスを保証します。
- PuppeteerやPlaywrightなどの一般的なツールのシームレスな統合により、開発プロセスを簡素化し、1行のコードで自動化されたタスクの起動をサポートします。
Scrapeless Scraping BrowserとPuppeteerの統合方法
Scrapelessは、ChromeバイナリをダウンロードしないPuppeteerバージョンであるpuppeteer-coreを必要とします。そのため、インストールされていることを確認してください。
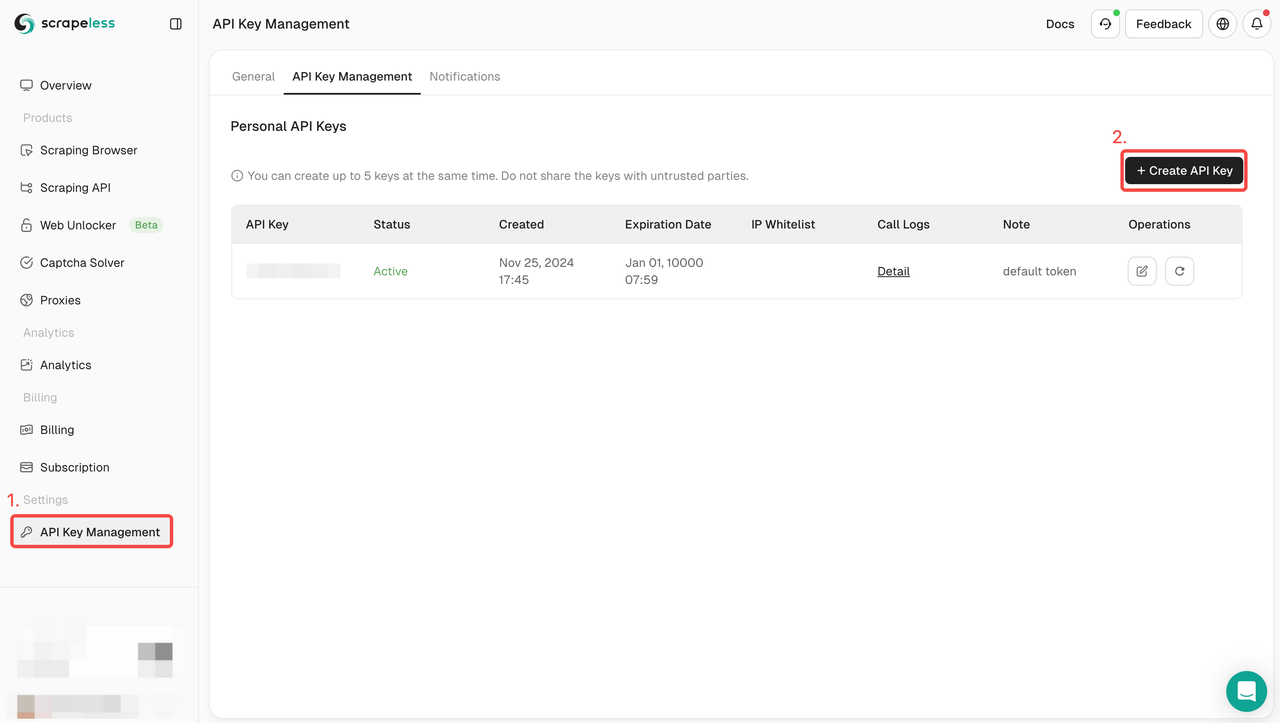
npm install puppeteer-core手順1. Scrapelessにサインアップし、APIキー管理> APIキーの作成をクリックしてScrapeless APIキーを作成します。
Scrapelessにサインアップして、無料トライアルを入手してください。ご不明な点がございましたら、DiscordからLiamにお問い合わせください。
手順2. 次に、Scraping Browserに移動して、ブラウザURLをコピーします。
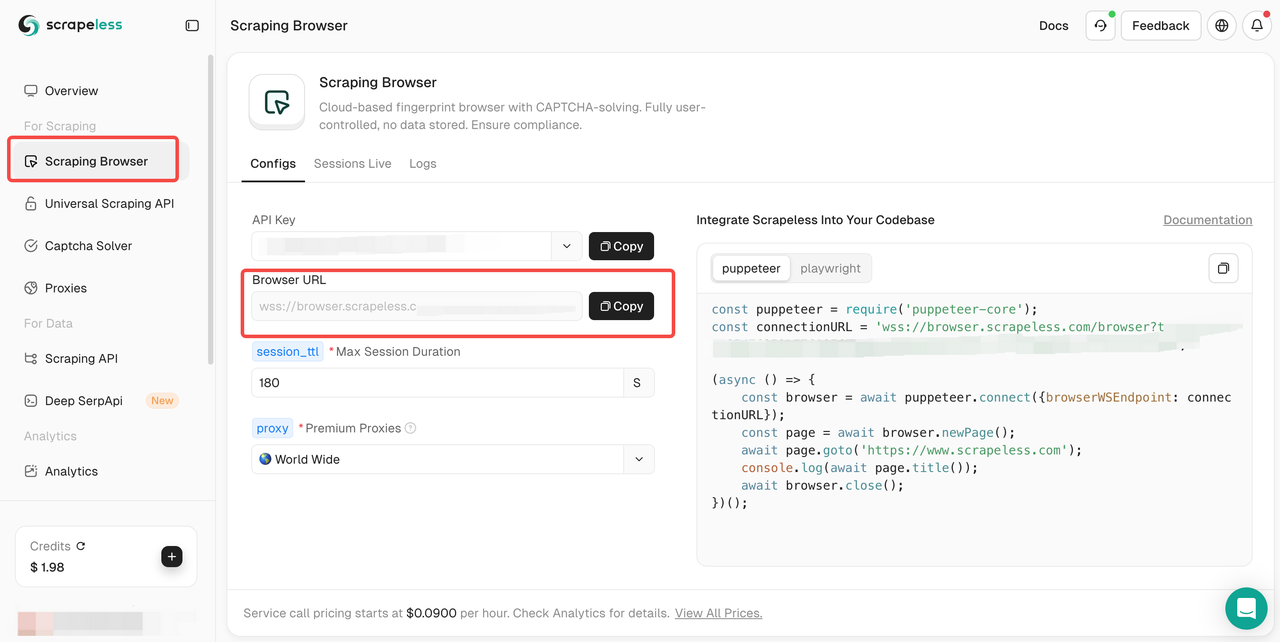
コピーしたブラウザURLを次のようにPuppeteerスクリプトに統合します。
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_Scrapeless_API_KEY>&session_ttl=180&proxy_country=ANY';
(async () => {
// set up browser environment
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
});
// create a new page
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {
waitUntil: 'networkidle0',
});
// wait for the challenge to resolve
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
//take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();
https://www.scrapingcourse.com/cloudflare-challengeを Cloudflare チャレンジのある任意のウェブサイトに置き換える必要があります。また、トークン部分にあなたのScrapeless APIキーを置き換えてください。
上記のコードは、保護されたページにアクセスしてスクリーンショットを撮ります。以下の結果をご覧ください。
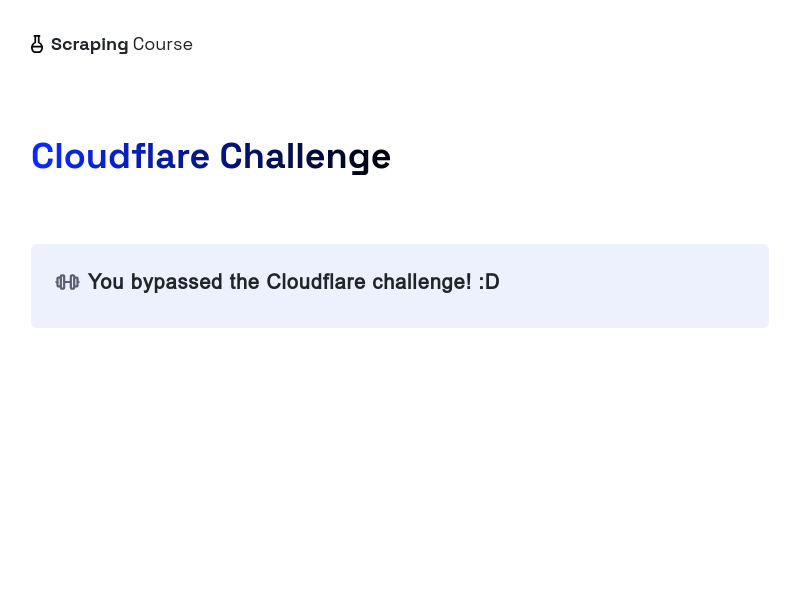
おめでとうございます🎉!PuppeteerとScrapelessを使用してCloudflareを正常にバイパスしました。
CloudflareのバイパスにPuppeteerにScrapeless Scraping Browserを統合するメリット
CloudflareをバイパスするためにPuppeteerにScrapeless Scraping Browserを統合すると、次のメリットがあります。
- ボット検出対策の強化
Puppeteer単体では、(navigator.webdriver属性、HeadlessChromeユーザーエージェントフラグなど)明確な自動化機能があるため、Cloudflareがボットとして識別しやすくなります。Scrapeless Scraping Browserは、実際ブラウザのフィンガープリント(タイプ、ユーザーエージェント、画面解像度など)を模倣することで、Puppeteerの自動化機能を効果的に隠蔽し、Cloudflare検出のリスクを軽減し、スクレイピングの成功率を高めます。
- 設定と統合の簡素化
Scrapeless Scraping Browserは、使いやすいAPIと統合方法を提供します。開発者は、既存のPuppeteerスクリプトに少量のコードを追加することで、Puppeteerの内蔵機能やCloudflareの反クローリングメカニズムを理解する必要なく、その強力なボット検出対策機能を活用できます。これにより、開発の障壁と作業負荷が軽減されます。
- コードの保守性の向上
Scrapeless Scraping Browserを使用することで、Puppeteerの基盤となる設定やカスタムスクリプトへの依存度が低減されます。これにより、コードがよりクリーンで明確になり、将来のメンテナンスとアップグレードが容易になります。
追加のリソース
Cloudflare Challengeバイパスの完全ガイド
まとめ
要約すると、PuppeteerでCloudflareをバイパスするには、効果的なツールと方法が必要です。Scrapeless Scraping Browserは、ボット検出対策の強化、統合の簡素化、保守性の向上により、シンプルながらも強力なソリューションを提供します。スクレイピングを行う際には、常に法令遵守を確保してください。
ビジネス効率を向上させ、Scrapeless Scraping Browserのエンタープライズレベルのカスタマイズされたソリューションを選択してください。私たちは、専門的で効率的なデータ収集サービスを提供します。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


