
Node UnblockerでWebスクレイピングの課題を回避できるか?
Expert Network Defense Engineer
Node Unblockerは、IPローテーション、ヘッダーのカスタマイズ、暗号化などの機能を含めるようにカスタマイズできます。そのため、ウェブサイトのブロックを回避するためにNode Unblockerを構築することに慣れています。
Node Unblockerはウェブサイトの課題を回避することに優れていますが、実際には、依然としてその固有の問題に対処する必要があります。
Node Unblockerをより強力にするには?ウェブサイトの課題を直接完全に克服できる方法やツールはありますか?
この記事から最適な答えを見つけましょう!
Node Unblockerとは?
Node Unblockerは、Node.jsを使用して構築されたWebプロキシツールであり、ネットワークの制限またはウェブサイトへのアクセス制限を回避するのに役立ちます。ユーザーとターゲットウェブサイトの中間として機能し、地理的な制限、ネットワークフィルター、またはファイアウォールのためにブロックされる可能性のあるコンテンツと対話できるようにします。
Unblockerは、ユーザーのリクエストをNode.jsサーバーにルーティングすることでこれを実現し、サーバーは目的のコンテンツを取得してユーザーに返します。一般的に動的なコンテンツ処理をサポートしているため、最新のWebアプリケーションに適しています。
Node Unblockerの使い方?
まず、基本的なNode.jsサービスを作成します。次に、Node Unblockerを使用してミドルウェアを作成し、Nodeサービスに統合する方法について説明します。詳細については、Node Unblockerのドキュメントを直接参照してください。
前提条件
開始する前に、Node.jsをインストールする必要があります。Node.jsはこちらからダウンロードできます。
それでは、基本的なNode.jsサービスの作成を始めましょう。
- 新しいNode.jsプロジェクトを初期化します。まだプロジェクトを持っていない場合は、次のコマンドを使用して作成します。
Bash
mkdir node-unblocker-tutorial- プロジェクトディレクトリに移動し、プロジェクトを初期化し、必要な依存関係をインストールします。
Bash
cd node-unblocker-tutorial
npm init -y
pnpm add express unblocker- 新しいファイル
index.jsを作成してコードを整理します。
Bash
touch index.js基本的なNode.jsサービスの設定
- 必要なモジュール
expressとunblockerをインポートします。
JavaScript
import express from 'express';
import unblocker from 'unblocker';- 次に、Expressアプリケーションを作成します。
JavaScript
const app = express();- Unblockerのインスタンスを初期化し、そのプロキシプレフィックスを設定します。
JavaScript
const unblocker = new Unblocker({
prefix: '/proxy/'
});app.use()メソッドを使用して、UnblockerインスタンスをExpressアプリケーションに統合してください。
JavaScript
app.use(unblocker());- ポートを定義し、
app.listen()メソッドを使用してNode.jsサービスを開始します。
JavaScript
const PORT = process.env.PORT || 9090;
app.listen(PORT, () => {
console.log(`Server started on port ${PORT}`);
});- 設定の完全なコードを以下に示します。
JavaScript
import express from 'express';
import Unblocker from 'unblocker';
const app = express();
const unblocker = new Unblocker({ prefix: '/proxy/' });
app.use(unblocker);
const PORT = process.env.PORT || 9090;
app
.listen(PORT, () => {
console.log(`Server started on port ${PORT}`);
})
.on('upgrade', unblocker.onUpgrade);サービスの実行
Nodeを使用してindex.jsファイルを実行し、ポート9090でサーバーを開始します。プロキシプレフィックスにターゲットURLを追加してプロキシをテストします。この例では、https://ident.me/をターゲットページとして使用します。サービスを実行した後、ブラウザで次のリンクを開きます。
node index.js
現在のサービスのIPアドレスが表示されたページが表示されます。これは、セットアップが正常に機能していることを示しています。

Node Unblockerの5つの制限
- パフォーマンスのボトルネック
Node UnblockerはWebリクエストとレスポンスをリアルタイムで処理するため、多数の同時リクエストや大量のトラフィックを処理する場合、パフォーマンスのボトルネックになる可能性があります。
- リソース消費
Node Unblockerは、特に大きなファイル、マルチメディアコンテンツ、または非常に動的なWebページを処理する場合、リクエストの処理にサーバーリソースを必要とします。これにより、CPUとメモリの使用量が増加する可能性があります。
- バイパス機能の制限
Node Unblockerはいくつかの基本的な制限を回避できますが、CAPTCHA、JavaScriptフィンガープリンティング、またはIPベースのレート制限メカニズムなどの高度なアンチボットシステムには対応できません。
- スケーラビリティの課題
Node Unblockerは、本質的に分散型設定または高スケーラビリティ向けに構築されていません。そのため、大幅なカスタマイズを行わない限り、エンタープライズグレードまたは大規模なアプリケーションには適していません。
- HTTPS検査の欠如
Node UnblockerはHTTPSトラフィックを復号化または検査しないため、プロキシプロセス中に暗号化されたデータを変更または分析する機能が制限されます。
Node Unblockerを使用するためのベストプラクティス
1. ユーザーエージェントヘッダーをローテーションする
Webスクレイピングアクティビティが異なるユーザーから発信されているように見せるには、ユーザーエージェントヘッダーをローテーションすることが不可欠です。このプラクティスは、ウェブサイトがリクエストを自動化されたものとして検出する可能性を大幅に低減します。
2. IPローテーションを実装する
単一のプロキシIPに依存することは、ウェブサイトに直接アクセスするのと同じくらい危険であり、IPがフラグ付けまたはブロックされる可能性が高まります。IPローテーションを実装することで、検出を回避し、必要なWebデータの収集をシームレスに行うことができます。
3. リクエストの頻度を制限する
レート制限は、IPがフラグ付けされるのを防ぐための重要な手段です。短時間で同じIPから複数のリクエストを迅速に送信すると、ウェブサイトのアンチボット保護がトリガーされ、禁止される可能性があります。スクレイピングコードに遅延を組み込むことで、これらのリスクを最小限に抑え、スムーズな操作を維持できます。
4. エラー処理
効果的なエラー処理は、Webスクレイピングを成功させるために不可欠です。ターゲットウェブサイトが予期した応答を返さないシナリオに対処するために、コードにメカニズムを組み込み、スクレイピングプロセスが堅牢で効率的な状態を維持します。
高度な機能のためのScrapeless Web Unlockerの統合
Scrapelessがブロックを回避するのに効果的な理由
Scrapeless Web Unlockerは、7,000万を超える住宅用IPへのアクセスをサポートする、195カ国にわたるグローバルネットワークを活用しています。99.9%のアップタイムと優れた成功率により、ScrapelessはIPブロックやCAPTCHAなどの課題を容易に克服し、複雑なWeb自動化とAI駆動のデータ収集のための堅牢なソリューションとなります。
Scrapelessは高価ですか?
Scrapelessは、競争力のある価格で信頼性が高くスケーラブルなWebスクレイピングプラットフォームを提供し、ユーザーにとって優れた価値を提供します。
- Scraping Browser: 1時間あたり0.09ドルから
- Scraping API: 1,000 URLあたり1.00ドルから
- Web Unlocker: 1,000 URLあたり0.20ドル
- Captcha Solver: 1,000 URLあたり0.80ドルから
- Proxies: 1GBあたり2.80ドル
購読することで、各サービスで最大20%の割引を受けることができます。特定の要件がありますか?今すぐお問い合わせください。お客様のニーズに合わせてさらに大きな節約を提供いたします!
プロジェクトへのScrapelessの統合手順
前提条件
開始する前に、Scrapelessアカウントを登録する必要があります。公式ウェブサイトにアクセスして、Scrapelessの詳細を学ぶこともできます。
登録後、Scrapelessダッシュボードに移動し、左側のペインにあるWeb Unlockerメニューをクリックします。ここでは、プロキシ、JSレンダリング、リクエストメソッド、JS命令など、さまざまな構成オプションがあります。これらの機能は、Node Unblockerのいくつかの制限に対処し、要件に合わせてカスタマイズできます。
これらの構成オプションに慣れていない場合は、ページの「ドキュメント」リンクをクリックして詳細なドキュメントを参照できます。
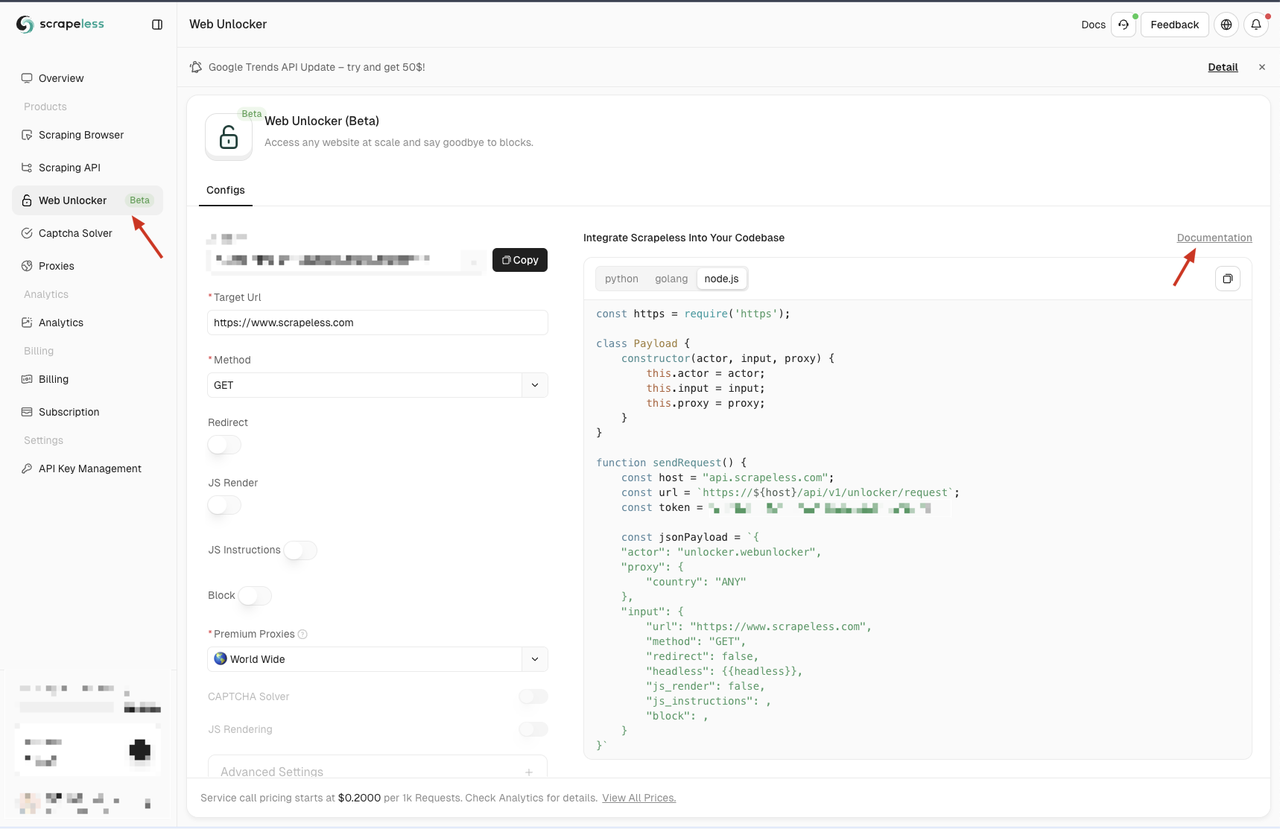
Scrapelessは、Python、Node.js、Golangの3つのプログラミング言語でコードサンプルも提供しています。統合に適した言語を選択できます。この例では、Node.jsを使用します。
CAPTCHAの回避
Scrapeless Web Unlockerは、CAPTCHA回避機能を自動的に有効にするため、CAPTCHAの課題に関する懸念を解消します。これを確認するには、まずCurlを使用して、検証が必要なサイト(例:https://app.ahrefs.com/user/login)にリクエストを行います。
以下のスクリーンショットでは、CurlリクエストはCAPTCHA検証ページを返します。応答にはCloudflareの検証の詳細が表示されています。
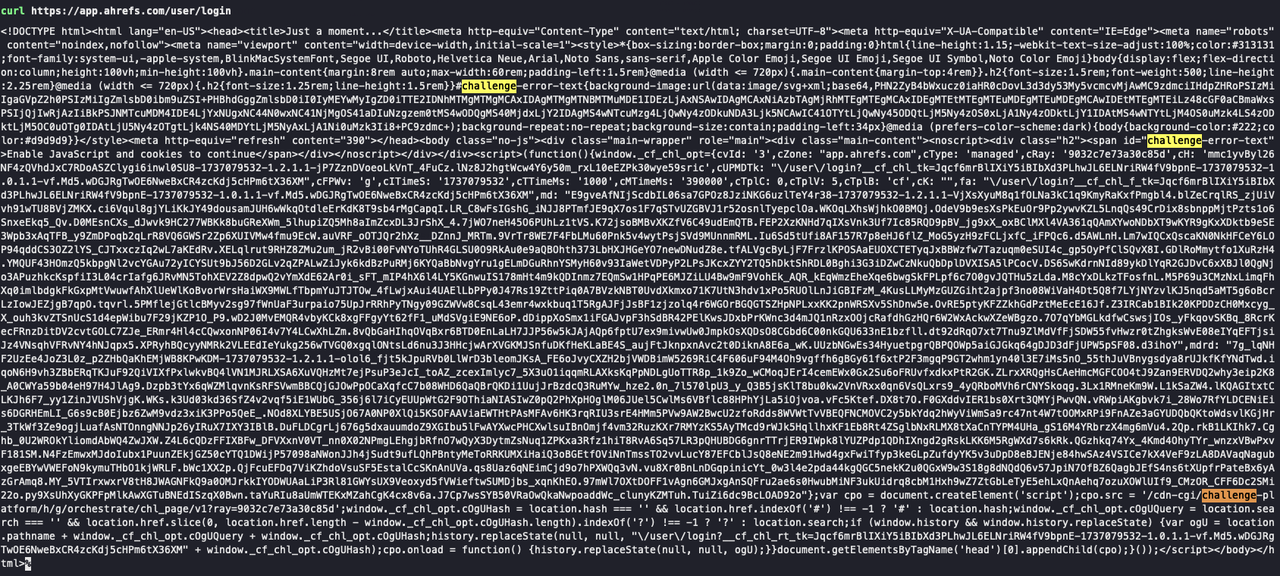
次に、Scrapeless Web Unlockerを使用して同じサイトをリクエストするには、次の手順に従います。
- 次のコードを含む
scrapeless-web-unlocker.jsファイルを作成します。
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input, proxy) {
this.actor = actor;
this.input = input;
this.proxy = proxy;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/unlocker/request`;
const token = ''; // your token
const inputData = {
url: 'https://app.ahrefs.com/user/login',
method: 'GET',
redirect: false,
};
const proxy = {
country: 'ANY',
};
const payload = new Payload('unlocker.webunlocker', inputData, proxy);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();node scrapeless-web-unlocker.jsでコードを実行します。
返された結果でCAPTCHA検証が正常にバイパスされ、ページのDOMコンテンツが取得されていることがわかります。さらに、ページコード内のタイトル「User login - Ahrefs」も結果で正常に取得できます。
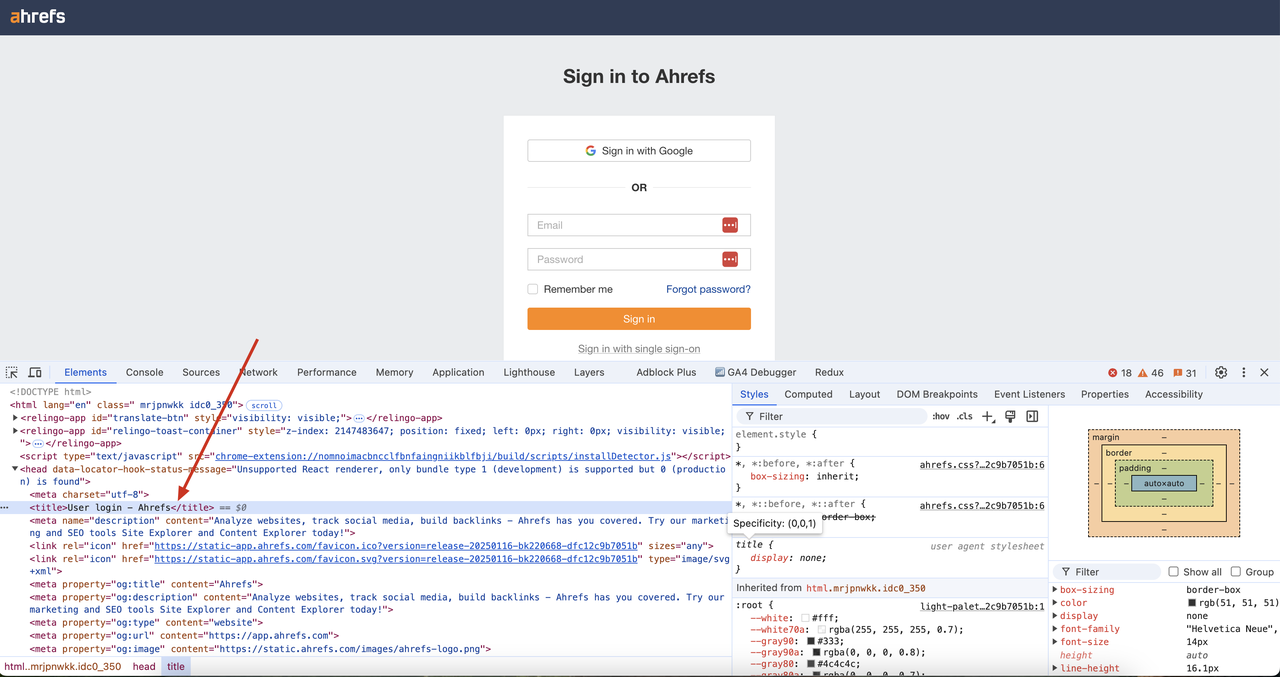

JavaScriptレンダリング
JavaScriptレンダリングは、動的に読み込まれたコンテンツとシングルページアプリケーション(SPA)を処理できます。完全なブラウザ環境を有効にし、より複雑なページのインタラクションとレンダリング要件をサポートします。ScrapelessのWeb Unlockerサービスは、Node UnblockerがJavaScriptを実行できないという問題を解決できます。ScrapelessのWeb UnlockerでJavaScriptレンダリング機能を有効にすれば、JavaScriptによってレンダリングされたページコンテンツを取得できます。
Cloudflareのダッシュボードログインページなど、JavaScriptレンダリングを使用するウェブサイトを見つけることができます。使用しているフレームワークテクノロジーはReact.jsであり、React.jsはシングルページアプリケーションフレームワークであり、そのコンテンツはJavaScriptによってレンダリングされます。
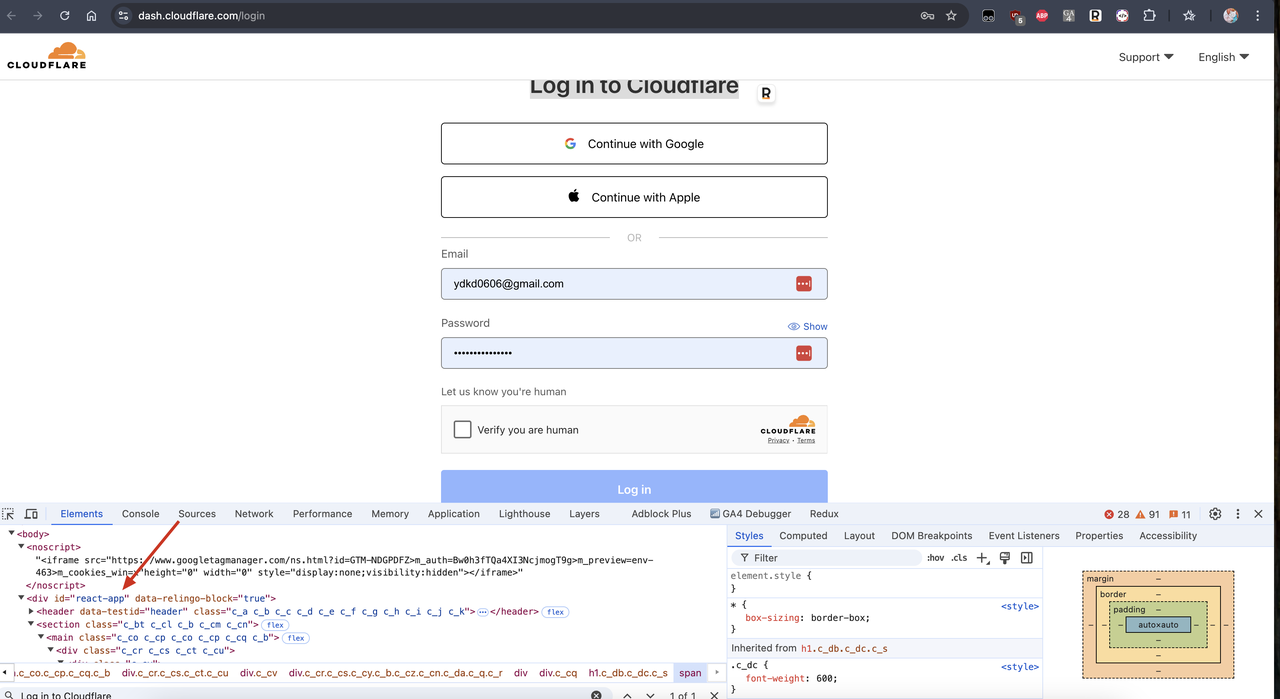
次に、コードを少し変更して、JavaScriptレンダリングを有効にせずにCloudflareのダッシュボードログインページのコンテンツを取得できるかどうかを確認します。コードを次のように変更します。
JavaScript
...
url: 'https://dash.cloudflare.com/login',
...返された結果でid="react-app"のdivが空であることがわかります。これは、JavaScriptレンダリング後のページコンテンツを取得できなかったことを意味します。
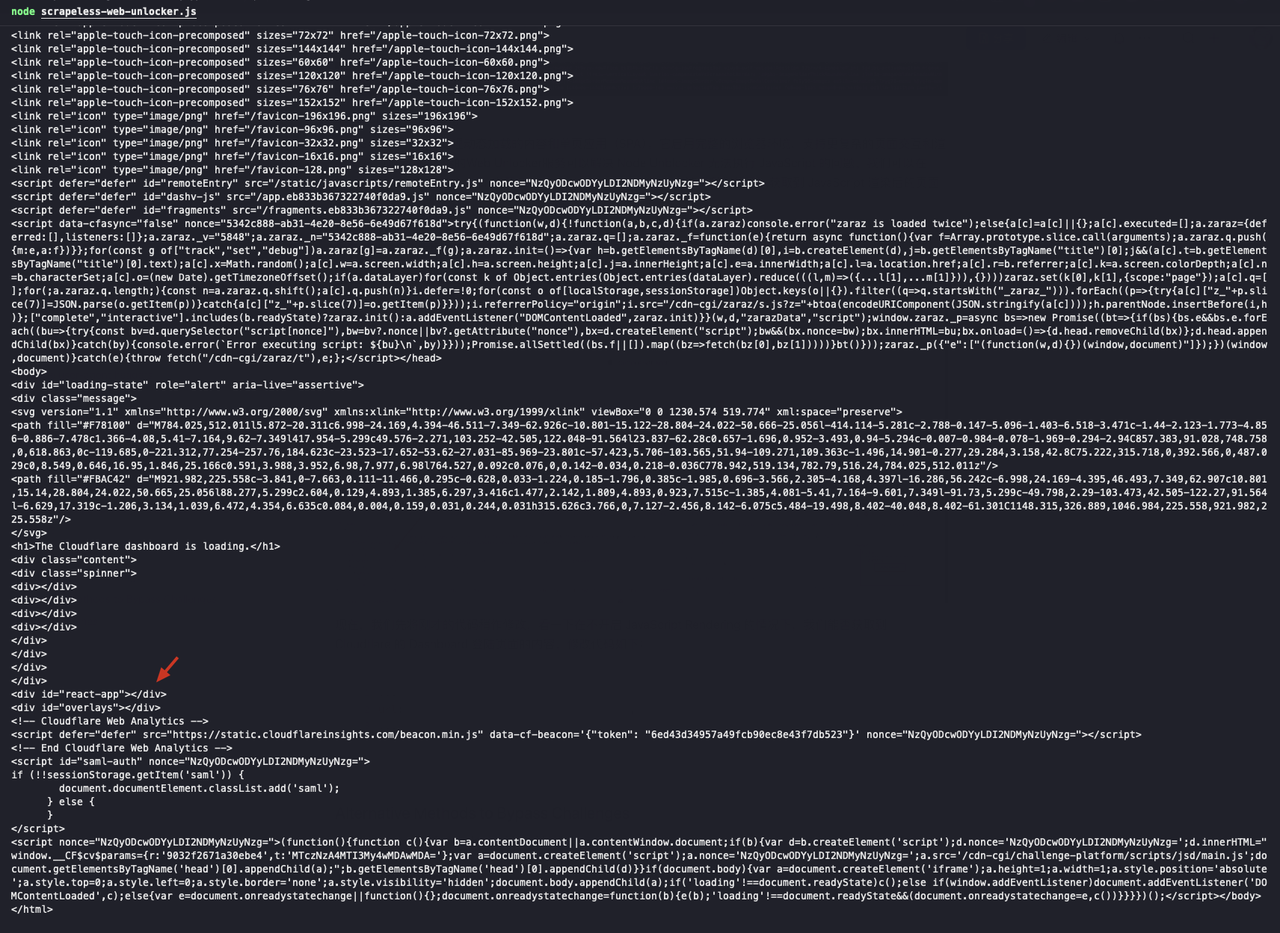
次に、JavaScriptレンダリング機能をオンにし、コードを次のように変更します。
JavaScript
const inputData = {
url: 'https://dash.cloudflare.com/login',
method: 'GET',
redirect: false,
js_render: true, // new option
js_instructions: [ // new option
{
wait: 20000,
},
],
};上記のコードでは、js_renderとjs_instructionsという2つの新しい構成オプションを追加しました。詳細な命令については、Scrapeless Docsを参照してください。
js_renderはJavaScriptレンダリング機能を有効にするために使用されますjs_instructionsはJavaScriptレンダリングの命令を設定するために使用されます。ここでは、ページが読み込まれた後に結果を返すために、20秒の待機命令を設定しています。
注記: 現在、多くのウェブサイトにはデフォルトで読み込みプロセスがあるため、ページが読み込まれたことを確認してから結果を返すためにしばらく待つ必要があります
これで、コードを再度実行すると、返された結果でCloudflareのダッシュボードログインページのコンテンツが正常に取得されていることがわかります。「Log in to Cloudflare」のテキストを取得することで、JavaScriptによってレンダリングされたページコンテンツを正常に取得できたことがわかります。
Bash
node scrapeless-web-unlocker.js
まとめ
Webコンテンツへのアクセスに関する課題が増加するにつれて、新しいソリューションが必要になっています。この記事では、Node Unblocker、データ処理を行いクライアントに転送するWebプロキシを提供するNodeJSライブラリについて検討しました。
しかし、その制限により、費用対効果の高いWebスクレイピングソリューションとしては不向きです。そのため、より効率的で安価なソリューションが必要とされました。誰もが同意するように、Scrapelessは優れたオールラウンドなサービスと低い価格で明確な勝者です。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


