
CAPTCHAはどのように動作しますか?
Advanced Bot Mitigation Engineer
マシンに自分が人間であることを証明する必要がなかった人を探すのは難しいでしょう。奇妙な謎を解くために消火栓を使用することは、認識の証明として奇妙に思えるかもしれません。このエッセイを読んだ後、それほど奇妙には思えなくなるでしょう。あなたはすぐにCAPTCHAの仕組みと、それらを解くことによってAIのトレーニングにどのように貢献しているかを学ぶでしょう。さらに、reCAPTCHAの仕組みも学ぶでしょう。
なぜCAPTCHAが必要なのでしょうか?
コンピューターと人間を区別する完全に自動化されたパブリックチューリングテストは、その頭字語であるCAPTCHAとして知られています。これは、Human Interaction Proof(HIP)としても知られています。CAPTCHAテストの目的は、人間とボットを区別することです。従来のCAPTCHAは、ユーザーに文字、数字、その他の文字を伸ばして歪ませることでテキストを認識させる課題を与えます。このタスクは人間にとっては簡単に見えるかもしれませんが、ロボットにとっては難しい場合があります。
現代のコンピューターの創始者と呼ばれることもあるアラン・チューリングは、1950年にチューリングテストを発表しました。この評価の目的は、ロボットが人間の思考プロセスを模倣できるかどうかを実証することでした。審問者は、テスト中に2人の参加者に一連の質問をします。参加者は2人おり、1人は人間、もう1人は機械です。審問者は、どちらがどちらであるか分からないため、応答に基づいてのみ推測する必要があります。審問者が参加者を特定できない場合、システムはテストに合格します。
名前が示すように、従来のCAPTCHAはチューリングテストに基づいています。
CAPTCHAはどのように運用されていますか?
ボットから人間を識別することは、CAPTCHAの目的です。CAPTCHAテストは、異なるユーザーに異なるグラフィックを表示することでこれを実現します。できるだけ多くの異なるバージョンを提供するために、CAPTCHAの膨大なデータベースが維持されています。ソリューションが常に同じであったり、画像の情報に隠されていたりすると、マシンはすぐにCAPTCHAコードを解読できます。
CAPTCHAは人間のみが完了することを意図していますが、誰もが最初の試みでCAPTCHAを完了できるわけではありません。専門家は、CAPTCHAの80%は人間によって解決できる一方、0.01%はコンピューターによって解決できるとしています。
コンピューターは人間ほど視覚データの分析が得意ではないため、従来のCAPTCHAテストのほとんどは視覚的知覚に依存しています。ほとんどの人はパターンを認識し、関連のないトピック間の関連付けを行うのが得意です。パレイドリアとは、存在しないときに以前に識別されたパターンを認識する能力です。たとえば、私たちの脳が情報をパターンに関連付けようとすると、雲の中に認識できる形を認識することができます。
視力の悪い人のために、CAPTCHAは音声形式で提供されます。ボットがこれらのテストに合格するのを防ぐために、音声には通常、バックグラウンドノイズが含まれています。
CAPTCHAの種類
CAPTCHAには、素材の種類に応じて、テキストベース、画像ベース、サウンドベースの3種類があります。
テキストベースのCAPTCHA
最も一般的な種類は、いくつかの正当化または表現、文字、数字を組み合わせています。
文字には、テクスチャのある背景や奇妙で歪んだ表示方法があるため、非人間にとって読み取るのがより困難になります。

画像ベースのCAPTCHA
通常、一般的なオブジェクトを描いた正方形の画像のグリッドです。ユーザーは、必要な要素を含む画像を選択する必要があります。Googleは、よく交差点や特定の種類の車両など、一般的なものを認識するためにストリートビューに依頼します。ほとんどの訪問者は、画像CAPTCHAを非常に迅速に完了します。ただし、ボットがオブジェクトを識別するには、さらに長い比較方法を実行する必要があり、目標達成が妨げられます。画像ベースの検査の複雑さのために、画像CAPTCHAはテキストCAPTCHAに比べて、より好まれるアンチボット戦術です。
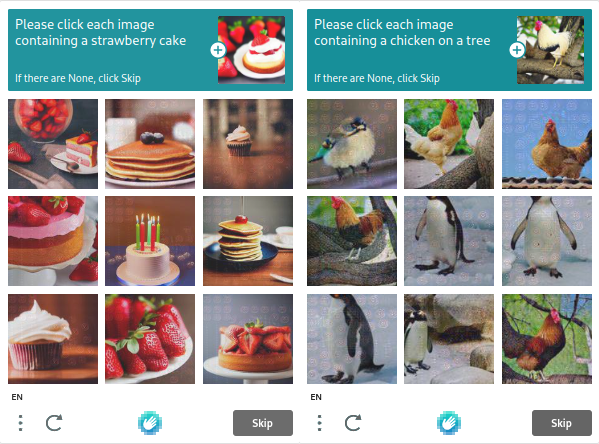
音声CAPTCHA
テキストベースと画像ベースのCAPTCHAは、音声CAPTCHAと頻繁に組み合わされます。サウンドトラックには、バックグラウンドノイズと、シンボルを綴る音声録音を含みます。ノイズは、通常、静電気などのさまざまな技術的なノイズであり、障壁の役割を果たします。ボットは、音声CAPTCHAでは、強調表示されたシンボルをバックグラウンドノイズから区別できません。
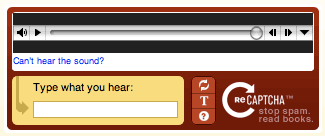
reCAPTCHAとは何ですか?
Googleは、標準的なCAPTCHAと同じ目的を果たすReCAPTCHAと呼ばれるツールを提供しています。これは、ウェブサイト向けの一般的な無料のウェブ保護ソリューションです。ユーザーが問題を解決するのではなく、ボックスをチェックするように求められるreCAPTCHAを見たことがあるかもしれません。私たちはこれらを「noCAPTCHA reCAPTCHA」と呼びます。ユーザーがボックスをチェックしてもシステムがまだ納得していない場合は、人間であることを確認するために身元の提示を求められます。
reCAPTCHAをどのように使用するか?
当初、本はデジタル化され、通りの名前の写真が使用され、新聞のテキストの断片が使用され、ユーザーは単語や単語の組み合わせをデコードするように求められました。人は画像から単語を簡単に解釈できますが、ボットは同じことをすることは困難です。
コンピューターがより高度になるにつれて、reCAPTCHAもより複雑になります。時間の経過とともに、他のreCAPTCHAの種類が作成されました。それらには、チェックボックス、画像認識、およびユーザーの入力なしで一般的なユーザー行動評価が含まれます。
reCAPTCHA V2とV3の比較
reCAPTCHA v3は、一見そう見えるかもしれませんが、単にreCAPTCHA v2のより高度なバージョンではありません。2つのソリューションは実際にはさまざまなニーズを満たし、互いに大きく異なります。
reCAPTCHA v2は、"私はロボットではありません"というラベルの付いたボックスをチェックすることとして定義されます。ほとんどの場合、これは試験の結論を示しますが、まれにユーザーは身元を検証するために追加の試験を受ける必要がある場合があります。
reCAPTCHA v3は、高度なリスク分析と機械学習を使用してバックグラウンドで動作するため、存在していることに気づかないかもしれません。ウェブマスターは、ユーザーの行動に基づいてreCAPTCHA v3からスコアを受け取ります。スコアに基づいて、あなたはボットまたは人間のどちらかに分類されます。スコアが高いほど、人間である可能性が高くなります。ウェブマスターは、ブロック、継続的なテスト、または通過を許可するかどうかを最終的に決定します。
V3とV2は特定の状況でのみ使用されます。reCAPTCHA v2は、自動化された訪問者を制限したい小規模なウェブサイトに適しています。ウェブサイトには、わずか2行のHTMLコードでv2を追加できます。
人工知能とCAPTCHA
CAPTCHAとreCAPTCHAは、人工知能(AI)トレーニングの完璧な例です。前述のように、アルゴリズムは、たとえば写真内の各猫をクリックするように要求した場合、他のユーザーの回答に基づいて回答が正しいかどうかを判断します。
さらに、このデータはAIにフィードされ、コンピューターが写真をより正確に認識できるようになります。
コンピューターは画像を認識するのが難しいです。たとえば、写真が異なる視点から撮影された場合、ロボットは人間の目と同じ関連付けを作成することはできません。しかし、今日の最も高度なテクノロジーでは、コンピューターはより複雑になり、ロボットは機械学習のおかげでますますインテリジェントになっています。
CAPTCHAをバイパスすることは可能ですか?
CAPTCHAを回避することで、これらのテストはより良くすることができます。ソリューションを改善するための最初のステップは、それが不足している場所を見つけることです。ボットがCAPTCHAを完了するたびに、より良い試験を開発するために一歩近づきます。それにもかかわらず、CAPTCHAを回避することは難しい課題です。
ブラックリストに載せられたり、CAPTCHAを受け取ったりすることは、オンラインスクレイピングで遭遇する最も一般的な問題の2つです。これらの困難は、大規模な公開データ収集の取り組みを中断する可能性があります。Scrapelessなどのいくつかの企業はすでに、CAPTCHAを回避する方法を発見しています。
CAPTCHAと継続的なウェブスクレイピングのブロックにうんざりしていませんか?
Scrapeless:最高のオールインワンオンラインスクレイピングソリューションをご利用ください!
強力なツールキットを活用して、データ抽出の潜在能力を最大限に引き出しましょう。
最高のCAPTCHAソルバー
複雑なCAPTCHAの自動解決により、継続的でスムーズなスクレイピングを保証します。
無料でお試しください!
要約
ウェブサイトは、CAPTCHAによってスパムや不正使用から保護されています。CAPTCHAは、人間ユーザーと自動化されたプログラムを区別するために、人間のみが完了できるテストを提示します。CAPTCHAは、チューリングテストから着想を得ています。
Googleは、ReCAPTCHAと呼ばれるCAPTCHAソリューションを提供しています。reCAPTCHAにはさまざまな形態があり、その中には人間の参加を必要としないものもあります。reCAPTCHAの正確な原因は不明ですが、考えられる原因には、ブラウザの履歴、Cookieの追跡、およびリアルタイムのウェブサイトのエンゲージメントが含まれます。
CAPTCHAの主な目的は、ボットが解決するのが難しいことであるため、コンピューターでCAPTCHAを回避することは困難です。一方、Web Scraper APIなどの特定のソリューションは、IP制限やCAPTCHAなしでウェブスクレイピングを可能にします。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


