
PythonでGoogle検索結果をスクレイピングする方法 - 最良のGoogle検索スクレイパー?
Specialist in Anti-Bot Strategies
Google SERPとは?
Google検索結果のウェブスクレイピングについて議論する際には、ほとんどの場合、「SERP」という略語に出くわすでしょう。SERPはSearch Engine Results Page(検索エンジン結果ページ)の略です。これは、検索バーにクエリを入力した後に表示されるページです。
以前は、Googleはクエリに対してリンクのリストを返していました。しかし今日では、全く異なる様相を呈しています。SERPには、検索エクスペリエンスを迅速かつ便利にする様々な機能と要素が含まれています。
通常、このページは以下で構成されています。
- オーガニック検索結果
- 有料検索結果
- おすすめスニペット
- ナレッジグラフ
- その他の要素: クエリに基づいて表示される地図、画像、ニュース記事など。
Google検索結果のスクレイピングは合法か?
Google検索結果をスクレイピングする前に、法的影響を理解することが不可欠です。Googleの利用規約では、そのポリシーに記載されているように、検索結果のスクレイピングを禁止しています。
「いかなる目的においても、サービスへのアクセスにスクレイピング、クロール、またはその他の自動手段を使用することはできません。」
これらの規約に違反すると、GoogleからIPアドレスの禁止、または法的措置を受ける可能性があります。ただし、スクレイピングの合法性は、管轄区域、スクレイピングするデータ、およびその使用方法によって異なります。
Googleスクレイピングの代替手段:
- Googleカスタム検索API: Googleは、ポリシーに違反することなくデータにアクセスするための法的かつ構造化された方法を提供する、検索結果を取得するための公式APIを提供しています。
- その他の検索API: Googleの使用にこだわらない場合は、BingやScrapelessなど、検索結果へのアクセスのためのAPIを提供する他の検索エンジンやサービスがあります。
Google SERPスクレイピングの4つの主な困難
Google SERPのスクレイピングは、多くの課題を提示するため、困難であると考えられています。これらには以下が含まれます。
- ボット検出: Googleは、以下を含むいくつかの手法を使用してボットを検出し、ブロックしています。
- CAPTCHA
- IPブロック
- レート制限
- 動的コンテンツ: Google検索結果は、多くの場合、JavaScriptを使用して動的に生成されるため、スクレイピングが複雑になる可能性があります。コンテンツはページの最初の読み込み後に読み込まれる場合があり、ページを完全にレンダリングするにはSeleniumなどのツールが必要です。
- HTML構造の変更: Googleは検索結果のレイアウトと構造を頻繁に変更するため、スクレイパーはコードの破損を避けるために迅速に適応する必要があります。
- 複雑なデータ: SERPには、広告、画像、ビデオ、リッチスニペットなど、さまざまな複雑な要素が含まれているため、意味のあるデータを一貫して抽出することが困難になります。
これらの課題にもかかわらず、適切な技術とツールを使用すれば、Google検索結果のスクレイピングは可能です。
では、Pythonを使用してGoogle検索結果をスクレイピングするプロセスを以下の手順に分解しましょう。
Pythonを使用したGoogle検索結果のスクレイピング方法
ステップ1:Googleへのリクエストの送信
スクレイピングを開始する前に、Googleの検索ページにリクエストを送信する必要があります。Googleはほとんどのボットからのリクエストをブロックするため、適切なUser-Agentヘッダーを設定して、実際のユーザーをシミュレートすることが不可欠です。
Python
import requests
from fake_useragent import UserAgent
# ランダムなユーザーエージェントを生成
ua = UserAgent()
headers = {'User-Agent': ua.random}
# Google検索クエリ
query = "How to scrape Google search results with Python"
url = f"https://www.google.com/search?q={query}"
# GETリクエストを送信
response = requests.get(url, headers=headers)
# リクエストが成功したかどうかを確認
if response.status_code == 200:
print(response.text)
else:
print("ページを取得できませんでした")ステップ2:HTMLコンテンツの解析
Google SERPのHTMLコンテンツを取得したら、BeautifulSoupを使用して必要なデータを取り出すことができます。
Python
from bs4 import BeautifulSoup
# ページコンテンツを解析
soup = BeautifulSoup(response.text, 'html.parser')
# すべての検索結果コンテナを見つける
search_results = soup.find_all('div', class_='BVG0Nb')
for result in search_results:
title = result.text
link = result.find('a')['href']
print(f"タイトル: {title}")
print(f"リンク: {link}\n")ステップ3:JavaScriptの処理(Seleniumの使用)
Seleniumは、コンテンツのレンダリングにJavaScriptに依存するページを処理するための優れたツールです。ブラウザを自動化し、ユーザーインタラクションをシミュレートするため、動的に生成されたコンテンツのスクレイピングに最適です。
Python
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# Selenium WebDriverを設定
driver = webdriver.Chrome(ChromeDriverManager().install())
# Googleを開いて検索を実行
driver.get("https://www.google.com/")
search_box = driver.find_element(By.NAME, 'q')
search_box.send_keys("How to scrape Google search results with Python")
search_box.submit()
# 結果の読み込みを待ってリンクを抽出
driver.implicitly_wait(5)
# 検索結果を取得
search_results = driver.find_elements(By.CLASS_NAME, 'BVG0Nb')
for result in search_results:
title = result.text
link = result.find_element(By.TAG_NAME, 'a').get_attribute('href')
print(f"タイトル: {title}")
print(f"リンク: {link}\n")
driver.quit()ステップ4:検出の回避
Googleによって検出およびブロックされる可能性を最小限に抑えるために、次のことを行う必要があります。
- ユーザーエージェントのローテーション: さまざまなブラウザからのリクエストをシミュレートするために、異なるユーザーエージェントを使用します。
- 遅延の追加: 人間のブラウジング動作を模倣するために、リクエスト間にランダムな遅延を導入します。
- プロキシの使用: リクエストを分散し、検出を回避するために、IPアドレスをローテーションします。
- robots.txtの尊重: 常にGoogleのrobots.txtファイルを確認し、倫理的なスクレイピングを実践します。
最適なGoogle検索スクレイピングAPI - Scrapeless
Googleを直接スクレイピングすることは可能ですが、面倒でエラーが発生しやすく、多くの場合ブロックされます。これが、Scrapelessが登場する理由です。強力なCAPTCHAソルバー、IPローテーション、インテリジェントプロキシ、Webアンロッカーを備えたScrapelessは、ブロックされることなく検索結果をスクレイピングするのに役立つように特別に設計された強力なAPIです。
Scrapelessを選択する理由
- 合法性: Scrapelessは、検索結果にアクセスするための法的かつ準拠した方法を提供します。
- 信頼性: このAPIは、洗練された技術を使用して検出を回避し、途切れることのないデータ収集を保証します。
- 使いやすさ: Scrapelessは、Pythonと簡単に統合できるシンプルなAPIを提供するため、検索結果データへの迅速なアクセスを必要とする開発者にとって理想的です。
- カスタマイズ可能: オーガニックリスト、広告など、コンテンツの種類を指定するなど、ニーズに合わせて結果を調整できます。
Scrapeless Google検索スクレイピングAPI - 手順の使用:
ターゲットを絞った特定のデータを作成するために、この記事ではGoogleトレンドを例としてクロールします。
ウェブブロックとGoogle検索スクレイピングにうんざりしていませんか?
コミュニティに参加して、無料トライアルで効果的な解決策を得ましょう!
ステップ1. Scrapelessダッシュボードにログインし、「Google検索API」に移動します。
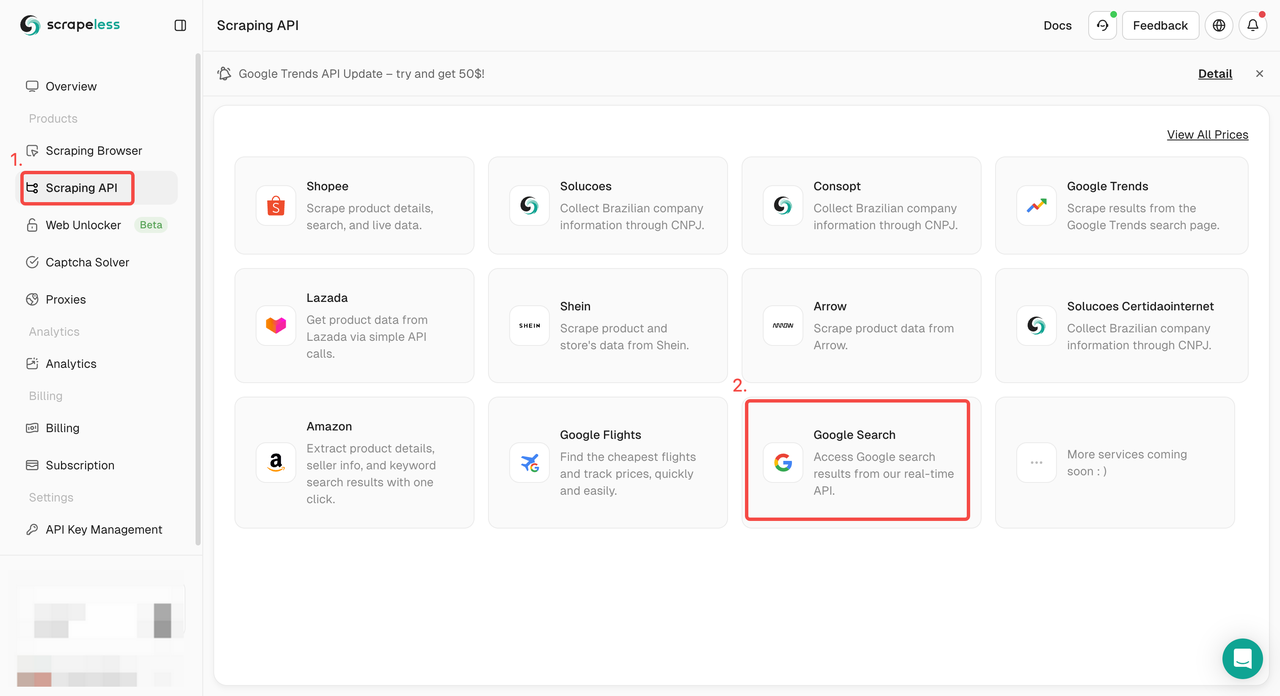
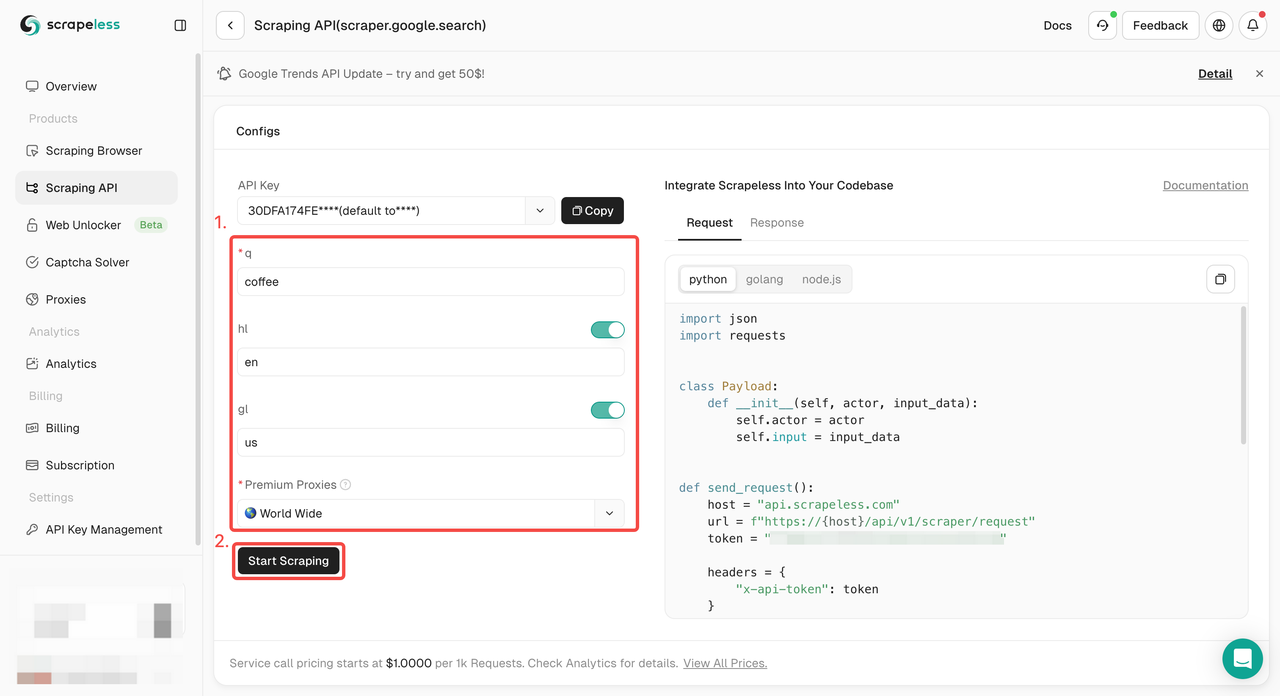
ステップ2. 左側で必要なキーワード、地域、言語、プロキシなどの情報を設定します。すべてが問題ないことを確認したら、「スクレイピング開始」をクリックします。
q: パラメータは、検索するクエリを定義します。gl: パラメータは、Google検索に使用する国を定義します。hl: パラメータは、Google検索に使用する言語を定義します。
ステップ3. クロール結果を取得してエクスポートします。
プロジェクトに統合するためのサンプルコードが必要ですか?ご用意しております!または、必要な言語のAPIドキュメントをご覧ください。
- Python:
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}終わりに
Google検索結果のスクレイピングは難しい場合がありますが、適切なツールと技術を使用すれば、間違いなく達成可能です!重要なのは、コードを書くことだけではありません。検出を回避する方法、法的境界線を尊重する方法、必要に応じて代替手段を見つける方法を知ることも重要です。
ScrapelessスクレイピングAPIは、Google検索結果のスクレイピングの世界であなたの最高の友達になるかもしれません!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


