
2025年のベストウェブクローラー5選:効率的なデータスクレイピングのための完全ガイド
Advanced Data Extraction Specialist
さまざまなウェブクローラーがあり、データを抽出したり、ウェブページをインデックスしたり、自動化されたウェブスクレイピングを効率的に実行するのに役立ちます。ただし、すべてのクローラーが同じくらい効果的であるとは限らないことに気付くかもしれません。いくつかは機能が限られていたり、設定が難しかったり、リソースを大量に消費することがあります。時には、間違ったツールを選択することで、ワークフローが遅くなったり、IPが禁止されることさえあります。では、どのようにして正しいものを見つければよいのでしょうか?
この問題を解決するには、パフォーマンス、使いやすさ、スケーラビリティのバランスを取った最良のウェブクローラーが必要です。それを踏まえて、さまざまなスクレイピングニーズに強力な機能を提供する5つのベストウェブクローラーを選定し、レビューしました。読んでいくうちに、あなたの要求に最も適したものを見つけてください。
| 製品名 | 使いやすさ | 機能 | 最適な用途 | 種類 | 価格 |
|---|---|---|---|---|---|
| Scrapeless | 使いやすく、先進的な自動化機能を持つユーザーインターフェース | 先進のブロック防止技術、プロキシプール、高速データ抽出、動的レンダリングサポート、CAPTCHA解除、検知回避のための実ブラウザ | 高パフォーマンスのデータスクレイピングを必要とするプロフェッショナルおよび企業 | クラウドベース、大規模スクレイピング | 月額49ドルから、サブスクリプション割引あり |
| WebHarvy | 使いやすいポイントアンドクリックインターフェース | ビジュアルスクレイピングインターフェース、画像、リンク、テキストのスクレイピングをサポート、スケジューラーで自動化されたクロール | 構造化データをスクレイピングする中小企業 | デスクトップベース、グラフィカルインターフェース | 129ドルから |
| OutWit Hub | 中程度の使いやすさ、いくつかの技術的知識が必要 | パターンを自動検出、画像、リンク、テキストなどのデータタイプを抽出 | 柔軟でカスタマイズ可能なスクレイピングを必要とするユーザー | デスクトップベース、ブラウザ拡張 | 95ユーロから |
| ParseHub | 使いやすい、最小限の設定が必要 | 動的ウェブサイトをスクレイピング、複数のデータ形式をサポート、複雑なウェブ構造に対応 | 複雑または動的なウェブサイトをスクレイピングするユーザー | デスクトップベース、クラウドオプションあり | 月額189ドルから |
| Content Grabber | 中程度、しかし強力な機能には学習が必要 | 完全自動化、大規模データセットのスクレイピングをサポート、高度なデータエクスポートオプション | 大量のデータをスクレイピングするエージェンシーおよび開発者 | デスクトップベース、強力なスクリプトサポート | 449ドルから2495ドルまで |
さあ、詳細に入り、これらのツールといくつかのウェブクロールの基本について話し合いましょう。
ウェブクロールとは何ですか?
ウェブクロールは、自動化されたソフトウェアを使用してウェブサイトを閲覧し、データを抽出するプロセスです。このソフトウェアはウェブクローラーまたはスパイダーと呼ばれ、サイト内のリンクを辿って、テキスト、画像、その他のコンテンツなどのデータを集めてさらなる使用のために収集します。ウェブクロールはURLの発見と制御された取得から始まり、ウェブスクレイピングは取得したページから選択したフィールドを抽出します。責任あるクローラーはロボット排除プロトコルを解釈し、W3Cウェブアーキテクチャの原則に従って安定した識別子を維持する必要があります。大規模なクロールデータセットは、耐久性のあるストレージおよび処理形式も必要です。Common Crawlの一般公開クロールデータドキュメントは、クロールレコードにアクセスし、大規模に処理する方法を示しています。
ウェブクロールが重要な理由は何ですか?
ウェブクロールは以下のために不可欠です:
- 検索エンジンのインデックス付け: クローラーはGoogleなどの検索エンジンがウェブページをインデックスするのを助け、より良い検索結果を提供します。
- 市場調査: 企業はクローラーを使って、競合他社の価格、製品詳細、トレンドを監視します。
- データ収集: 大規模なデータセットを収集し、分析、機械学習、洞察のために役立ちます。
- 効率性: データ収集を自動化し、時間とリソースを節約します。
データをクロールするにはどうすればよいですか?
データをクロールするには、以下の手順に従ってください:
ターゲットウェブサイトを選択する: データを集めたいサイトを特定します。
クローラーを設定する: ツールやカスタムスクリプトを使用してプロセスを自動化します。
データを抽出する: 必要なデータを定義し、クローラーを設定します。
データを保存する: 抽出した情報を分析用に構造化された形式で保存します。
ウェブクロール技術
ウェブクローラーはさまざまな技術を使用します:
- HTMLパース: ウェブページのHTMLからデータを抽出します。
- APIクローリング: 構造化データの取得にAPIを使用します。
- ヘッドレスブラウザ: Puppeteerのようなツールは、JavaScriptが多く使用されているサイトからデータを抽出するのに役立ちます。
- プロキシとCAPTCHA解決: IPを回転させてセキュリティ対策を回避することで、ブロックを防ぎます。
ウェブクローラーとは何ですか?
ウェブクローラーとは、ウェブデータを収集および複製するために設計された自動化プログラムです。ほぼすべての業界において、企業や組織は最終的にさまざまな使用ケースのためにデータを抽出する必要があります。
しかし、ウェブクローラーは単に情報を大量コピーするための簡単なプログラムではありません。複数のソースからデータを抽出し、ブロックされずにデータを取得できるように人間の行動を巧妙に模倣するのに十分な性能を持っている必要があります。
なぜウェブクローラーを使用するのか?
大規模なデータ抽出に関しては、手動のオンラインスクレイピングは現実的ではありません。また、オートメーションは厳格なアルゴリズムを設定し、曖昧さを避けるのに役立ちます。ウェブクローラーを使用することで、手動の方法に対して以下の利点があります:
- より高い精度:自動化されたクローラーは、人為的なエラーなしに一貫してデータが収集されることを保証します。
- コスト効果:手動データ入力に関連するコストを削減します。
- データのコントロール:抽出するデータを具体的に定義することができます。
- 時間効率:ウェブクローラーはデータ抽出プロセスでかなりの時間を節約し、大規模なデータ収集を可能にします。
最も効果的なウェブクローラーのみを推薦するために、以下のテストを実施しました:
| 基準 | 詳細 |
|---|---|
| 🎉 テストした数 | オープンソースおよび商業ツールを含む10以上のウェブクローラー |
| 👀 クローリングした内容 | Eコマースウェブサイト、ニュースポータル、ソーシャルメディアプラットフォーム、および構造化データベース |
| 😎 重要視した点 | 価格、クロール速度、検知対策機能、実際のブラウザシミュレーション、プロキシのサポート、使いやすさ |
1. Scrapeless ★★★
価格: 月額$49から
最適: 大規模なウェブスクレイピングのために高度で効率的なソリューションを必要とする企業や開発者
Scrapelessは、現在市場で最高のウェブクローラーの一つであり、ウェブサイトからデータを効率的に抽出しながら、ブロック対策を扱うためのオールインワンソリューションを提供します。
Scrapelessを使用すると、Eコマース、市場調査、およびソーシャルメディアプラットフォームなど、さまざまなウェブサイトからデータをスクレイプできます。CAPTCHAの挑戦を回避するのが得意で、検知対策のための実際のブラウザシミュレーションを使用したり、他のクローラーがしばしば苦労する動的コンテンツを管理したりします。
このツールのブロック対策技術には、豊富なプロキシIPプール、迅速なCAPTCHA解除、およびTLSフィンガープリンティングの偽装などの機能が含まれており、スクレイピング活動が検出されず、安全にIP禁止から守られます。また、JavaScriptが多く使用されているページからデータを取得する能力でも知られており、現代の複雑なウェブサイトに最適です。検出のリスクなしに大規模なデータ抽出を必要とする企業にとって、強力なソリューションです。
追加の利点:
- Scrapeless: ウェブスクレイピングAPIへの完全アクセスが月額$49からです。
- Google SERP API: Google SERP APIの価格は1Kクエリあたり$0.3と非常に手頃で、頻繁な検索に適しています。AI結果、知識グラフ、地元ニュース、広告結果、Twitter結果など、30種類以上の検索結果タイプをカバーしています。
- Google Trends Scraping API:データを2秒以内に提供し、トレンドデータへの迅速なアクセスを提供します。
ScrapelessスクレイピングAPIを使用してデータをスクレイプする方法
Scrapelessでデータをスクレイプするのは簡単で効率的です。以下のステップに従って始めることができます:
-
アカウントにサインアップ:Scrapelessのウェブサイトにアクセスし、アカウントを作成します。
-
シナリオに応じたスクレイピングAPIを選択:左側から必要なスクレイピングAPIを選択できます。
また、Python、Node.js、またはその他のプログラミング言語を使用している場合は、API統合を設定してツールをワークフローに統合できます。Scrapeless APIドキュメントを参照してください。
- クロール対象の設定:クロールするウェブサイトを選択し、必要なクロール設定を構成します。ここではGoogle Flightsを例に取ります。
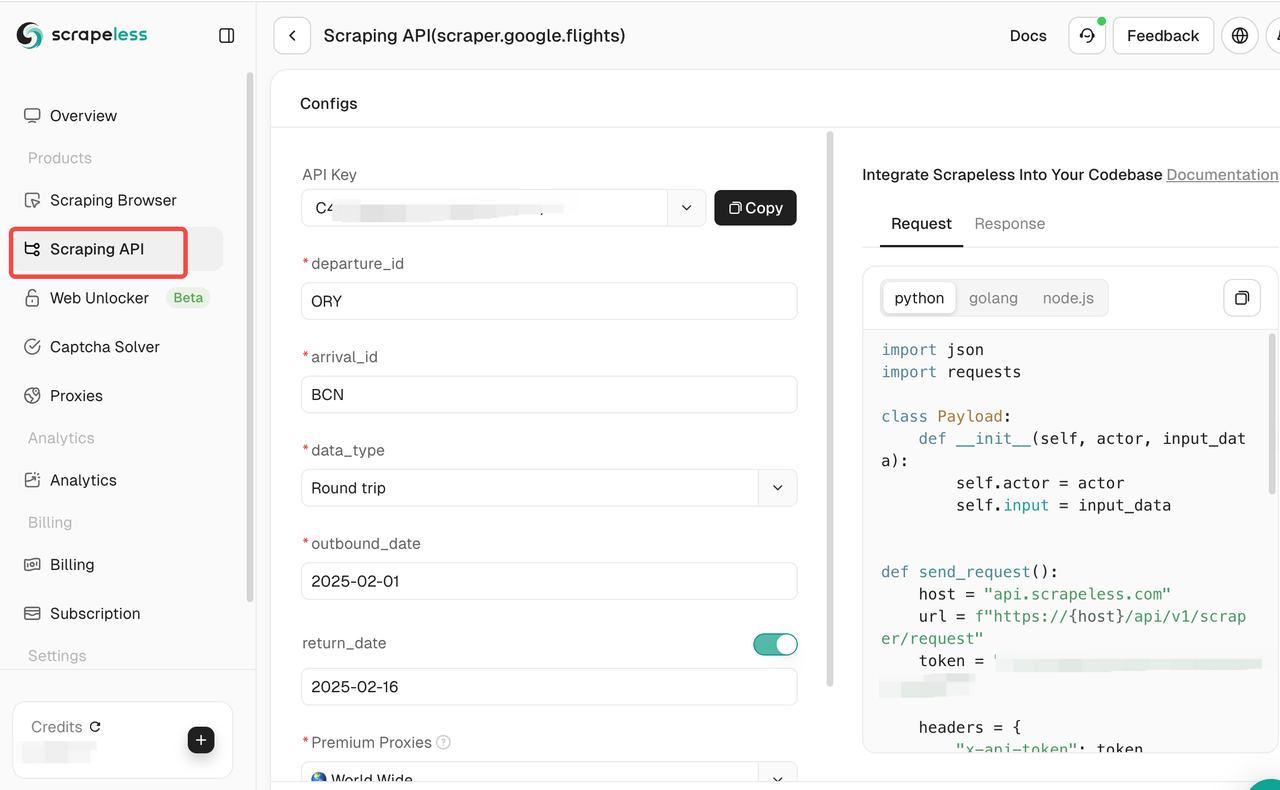
スクレイピングAPIをクリックし、Google Flightを選択して対応するスクレイピング要件を設定します。
- スクレイピングを開始:スクレイピングを開始するには「スクレイピング開始」をクリックし、結果が右側に表示されます。
JavaScriptのレンダリングやセッション管理が必要なページについては、Scrapeless Scraping Browserがブラウザレイヤーとして機能します。実装を選ぶ前に、クロールボリュームとセッションプロファイルに対するScrapelessの価格を確認してください。
2. WebHarvy
価格:129ドルから
最適な対象:シンプルなポイントアンドクリックのスクレイピングソリューションを求めるユーザー
WebHarvyは、初心者に最適な使いやすいウェブクローラーです。視覚的なポイントアンドクリックインターフェースにより、1行のコードを書くことなく簡単にスクレイピングできます。Scrapelessほど高度なアンチブロッキング機能はありませんが、eコマースサイトやブログからの製品データのスクレイピングには最適です。
利点:
- 使いやすさ:コーディングの知識が不要なユーザーフレンドリーなインターフェース
- 視覚的ポイントアンドクリックのスクレイピング:複雑な設定を学ぶ必要なくデータを抽出
- eコマースサイトに適している:製品リスト、画像、価格を抽出するのに優れている
欠点:
- 制限されたアンチブロック機能:高トラフィックサイトでのスクレイピング制限に対して脆弱
- 限られたスケーラビリティ:大規模で高頻度のスクレイピングプロジェクトには不向き
3. OutWit Hub
価格:95€から
最適な対象:シンプルなブラウザベースのスクレイパーを必要とする初心者
OutWit Hubは、リンク、メール、画像などをスクレイピングするためのブラウザ拡張機能に基づくウェブクローラーです。初心者や小さなスクレイピングタスクに最適ですが、複雑なスクレイピングやJavaScript重視のページを扱う高度な使用例には最適ではないかもしれません。
JSチャレンジに遭遇した場合は、こちらのチュートリアルをチェックすることができます:Cloudflareチャレンジを回避する方法
利点:
- ブラウザ統合:ブラウザ内で直接インストールして使用するのが簡単
- 使いやすいインターフェース:コーディング経験のない初心者に最適
- 柔軟性:リンクや画像、テキストなどのさまざまなデータタイプをスクレイピング可能
欠点:
- 高度な機能が不足:動的コンテンツや高ボリュームのスクレイピングを扱うサポートが欠けている
- 限られたスケーラビリティ:大規模または複雑なプロジェクトには不向き
4. ParseHub
価格:月額189ドルから
最適な対象:動的コンテンツをスクレイピングする必要がある高度なユーザー
ParseHubは、JavaScript重視のウェブサイトをスクレイピングするのに優れた高度なウェブクローラーです。複雑なサイトを扱うための強力な機能セットを提供しますが、高い価格帯と複雑さにより、経験の少ないユーザーには敬遠されるかもしれません。視覚的なインターフェースを提供しますが、WebHarvyよりも複雑です。
利点:
- 動的サイトをサポート:JavaScript重視のウェブサイトのスクレイピングに優れている
- 視覚的インターフェース:コーディングなしでスクレイピングプロジェクトを作成可能
- 高度な機能:スクレイピングタスクのスケジュール設定や自動化のオプションを提供
欠点:
- 価格設定:小規模またはカジュアルユーザーには高価
- 急な学習曲線:高度な機能は初心者には圧倒されることがある
- 遅いパフォーマンス:大規模なスクレイピングタスクにおいてScrapelessほど速くない
5. Content Grabber
価格:449ドルから2495ドルまで
最適な対象:エンタープライズレベルのスクレイピングソリューション
Content Grabberは、大規模なウェブスクレイピングタスクのために設計された機能豊富なウェブクローラーで、特に企業向けのユーザーに最適です。複数のウェブサイトにわたって構造化データをスクレイピングするのに優れていますが、高価な料金と高度な設定はカジュアルなユーザーには過剰かもしれません。
長所:
- 高度にカスタマイズ可能:大規模なデータセットのスクレイピングや複雑なワークフローの処理に適しています
- 高度な機能:API、プロキシローテーション、および CAPTCHA解決をサポート
- 企業使用に最適:高ボリュームのデータ抽出に理想的です
短所:
- 高コスト:料金は中小企業や個人には負担になる場合があります
- 複雑さ:効果的に学び、設定するには時間と労力が必要です
- 小規模プロジェクトには過剰:大規模な作業により適しています
ウェブクローラーに関するFAQ
1. ウェブスクレイピングとウェブクロールの違いは何ですか?
**回答:**ウェブスクレイピングとウェブクロールは両方ともウェブから情報を抽出することを含みますが、異なる目的があります。ウェブクロールは主に複数のウェブサイト間でコンテンツを発見し、インデックスを作成することに焦点を当てています。検索エンジンがウェブの構造をマッピングするために使用します。一方、ウェブスクレイピングは、特定のデータ(製品の詳細、価格、連絡先情報など)をウェブサイトから抽出する行為を指します。スクレイピングは通常、よりターゲットを絞ったもので、実用的なデータを収集するために設計されていますが、クロールはウェブ全体のデータの大きなセットを収集し、インデックス作成することに関するものです。
2. ウェブスクレイピングはどのように機能しますか?
**回答:**ウェブスクレイピングは、ウェブサイトからデータを抽出するために自動化されたソフトウェアやスクリプト(ウェブクローラー)を使用して機能します。このプロセスは、ウェブサイトにリクエストを送信し、HTMLコンテンツを取得し、テキスト、画像、リンクなどの役立つ情報を抽出するために解析することを含みます。Scrapelessのような高度なクローラーは、動的なウェブサイトを処理し、アンチスクレイピング対策を回避し、さらなる分析のためにさまざまな形式でデータをエクスポートできます。
3. 動的なウェブサイトのスクレイピングにウェブクローラーを使用できますか?
**回答:**はい、ScrapelessやParseHubなど、多くの現代的なウェブクローラーは動的なウェブサイトを処理するように設計されています。これらのクローラーは、JavaScriptをレンダリングし、実際のブラウザのようにウェブサイトと対話できるため、動的にコンテンツをロードするページからデータをスクレイピングすることが可能です。特にScrapelessは、アンチ検出技術や高速データ抽出のような機能を提供し、動的コンテンツが正確かつ効率的にスクレイピングされることを確保します。
最後の考察
全体として、2025年のデータスクレイピングに最適なウェブクローラーを選ぶことは、効率を最大化するために重要です。WebHarvy、OutWit Hub、ParseHubのようなツールはすべて良いオプションですが、Scrapelessはユーザーフレンドリーなインターフェース、高度な機能、競争力のある価格(月額49ドル)でリードしています。さらに、Scrapelessの機能を探検するために、無料で試すことができます。
Scrapeless Discordコミュニティに参加する機会をお見逃しなく、Scrapeless Discordに参加して、営業に連絡して無料トライアルを申し込んでください!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


