Cloudflare से सुरक्षित वेबसाइट को कैसे बायपास करें?
Senior Web Scraping Engineer
Cloudflare से सुरक्षित वेबसाइटों को स्क्रैप करना सबसे कठिन कामों में से एक हो सकता है। इसका स्वचालित बॉट डिटेक्शन आपको Cloudflare के एंटी-स्क्रैपिंग उपायों को बायपास करने और इसके वेब पेज डेटा को निकालने के लिए एक शक्तिशाली वेब स्क्रैपिंग टूल का उपयोग करने की आवश्यकता होती है।
आज, हम आपको पायथन और ओपन सोर्स Cloudscraper लाइब्रेरी का उपयोग करके Cloudflare द्वारा सुरक्षित वेबसाइटों को स्क्रैप करना सिखाएंगे। कहा जा रहा है, जबकि कुछ मामलों में प्रभावी है, आप पाएंगे कि Cloudscraper में कुछ सीमाएँ हैं जिनसे बचना मुश्किल है।
Cloudflare बॉट मैनेजमेंट क्या है?
Cloudflare एक कंटेंट डिलीवरी और वेब सुरक्षा कंपनी है। यह क्रॉस-साइट स्क्रिप्टिंग (XSS), क्रेडेंशियल स्टफिंग और DDoS हमलों जैसे सुरक्षा खतरों से वेबसाइटों की सुरक्षा के लिए एक वेब एप्लिकेशन फ़ायरवॉल (WAF) प्रदान करता है।
Cloudflare WAF के मुख्य सिस्टमों में से एक बॉट मैनेजर है, जो वास्तविक उपयोगकर्ताओं को प्रभावित किए बिना दुर्भावनापूर्ण बॉट्स द्वारा किए जाने वाले हमलों को कम करता है। हालाँकि, जबकि Cloudflare Google जैसे ज्ञात क्रॉलर बॉट्स की अनुमति देता है, यह मानता है कि कोई भी अज्ञात बॉट ट्रैफ़िक (वेब क्रॉलर सहित) दुर्भावनापूर्ण है।
Cloudflare WAF का परिचय
Cloudflare WAF Cloudflare के मुख्य सुरक्षा प्रणाली में एक प्रमुख घटक है, जिसे वास्तविक समय में HTTP/HTTPS ट्रैफ़िक का विश्लेषण करके दुर्भावनापूर्ण अनुरोधों का पता लगाने और उन्हें ब्लॉक करने के लिए डिज़ाइन किया गया है। यह नियम सेट (पूर्वनिर्धारित नियमों और कस्टम नियमों सहित) के आधार पर SQL इंजेक्शन, क्रॉस-साइट स्क्रिप्टिंग (XSS), DDoS हमले आदि जैसे संभावित खतरों को फ़िल्टर करता है।
Cloudflare WAF IP प्रतिष्ठा डेटाबेस, व्यवहार विश्लेषण मॉडल और मशीन लर्निंग तकनीक को जोड़ता है, और नए हमलों का जवाब देने के लिए गतिशील रूप से सुरक्षा रणनीतियों को समायोजित कर सकता है। इसके अतिरिक्त, WAF को Cloudflare के CDN और DDoS सुरक्षा के साथ मूल रूप से एकीकृत किया गया है ताकि वैध उपयोगकर्ताओं के लिए कम विलंबता और उच्च उपलब्धता बनाए रखते हुए वेबसाइटों के लिए बहु-स्तरीय सुरक्षा प्रदान की जा सके।
नीचे दी गई तालिका से, आप WAF के सुरक्षा उपायों और क्रैकिंग की कठिनाई को स्पष्ट रूप से देख सकते हैं:
| सुरक्षा परत | तकनीकी सिद्धांत | क्रैकिंग की कठिनाई |
|---|---|---|
| IP प्रतिष्ठा पता लगाना | IP ऐतिहासिक व्यवहार (ASN/भौगोलिक स्थान) का विश्लेषण | ★★☆☆☆ |
| JS चुनौती | ब्राउज़र परिवेश को सत्यापित करने के लिए गतिशील रूप से गणित की समस्याएँ उत्पन्न करना | ★★★☆☆ |
| ब्राउज़र फ़िंगरप्रिंट | कैनवास/WebGL रेंडरिंग फ़ीचर निष्कर्षण | ★★★★☆ |
| गतिशील टोकन | टाइमस्टैम्प-आधारित एन्क्रिप्टेड टोकन सत्यापन | ★★★★☆ |
| व्यवहार विश्लेषण | माउस प्रक्षेपवक्र/क्लिक पैटर्न पहचान | ★★★★★ |
Cloudflare बॉट्स का पता कैसे लगाता है?
Cloudflare की बॉट प्रबंधन प्रणाली को दुर्भावनापूर्ण बॉट्स और वैध ट्रैफ़िक (जैसे खोज इंजन क्रॉलर) के बीच अंतर करने के लिए डिज़ाइन किया गया है। आने वाले अनुरोधों का विश्लेषण करके, यह असामान्य पैटर्न की पहचान करता है और आपकी साइटों और अनुप्रयोगों की अखंडता बनाए रखने के लिए संदिग्ध गतिविधि को अवरुद्ध करता है।
इसके पता लगाने के तरीके निष्क्रिय या सक्रिय हो सकते हैं। निष्क्रिय बॉट पता लगाने की तकनीक बैकएंड फ़िंगरप्रिंटिंग का उपयोग करती है, जबकि सक्रिय पता लगाने की तकनीक क्लाइंट-साइड विश्लेषण पर निर्भर करती है।
- निष्क्रिय बॉट पता लगाने की तकनीकें
- बॉटनेट का पता लगाना
- IP पता प्रतिष्ठा
- HTTP अनुरोध शीर्षलेख
- TLS फ़िंगरप्रिंटिंग
- HTTP/2 फ़िंगरप्रिंटिंग
- सक्रिय बॉट पता लगाने की तकनीकें
- CAPTCHAs
- कैनवास फ़िंगरप्रिंटिंग
- ईवेंट ट्रेसिंग
- पर्यावरण API क्वेरी
Cloudflare की 3 मुख्य त्रुटियाँ
- Cloudflare त्रुटि 1015: यह क्या है और इससे कैसे बचें
- Cloudflare त्रुटि 1006, 1007, 1008: वे क्या हैं और उन्हें कैसे ठीक करें
- Cloudflare 403 अस्वीकृत: इस समस्या को बायपास करें
Cloudflare से सुरक्षित वेबसाइट को कैसे स्क्रैप करें?
चरण 1: पर्यावरण सेट करें
सबसे पहले, सुनिश्चित करें कि आपके सिस्टम पर पायथन स्थापित है। इस प्रोजेक्ट के लिए कोड संग्रहीत करने के लिए एक नई निर्देशिका बनाएँ। इसके बाद, आपको cloudscraper और requests को स्थापित करने की आवश्यकता है। आप इसे pip के माध्यम से कर सकते हैं:
Shell
$ pip install cloudscraper requestsचरण 2: requests का उपयोग करके एक साधारण अनुरोध करें
अब, हमें https://sailboatdata.com/sailboat/11-meter/ पर पेज से डेटा स्क्रैप करने की आवश्यकता है। पेज सामग्री का एक हिस्सा इस तरह दिखता है:
हम वेबसाइट की गोपनीयता की दृढ़ता से रक्षा करते हैं। इस ब्लॉग में सभी डेटा सार्वजनिक हैं और इसका उपयोग केवल क्रॉलिंग प्रक्रिया के प्रदर्शन के रूप में किया जाता है। हम कोई भी जानकारी और डेटा सहेजते नहीं हैं।
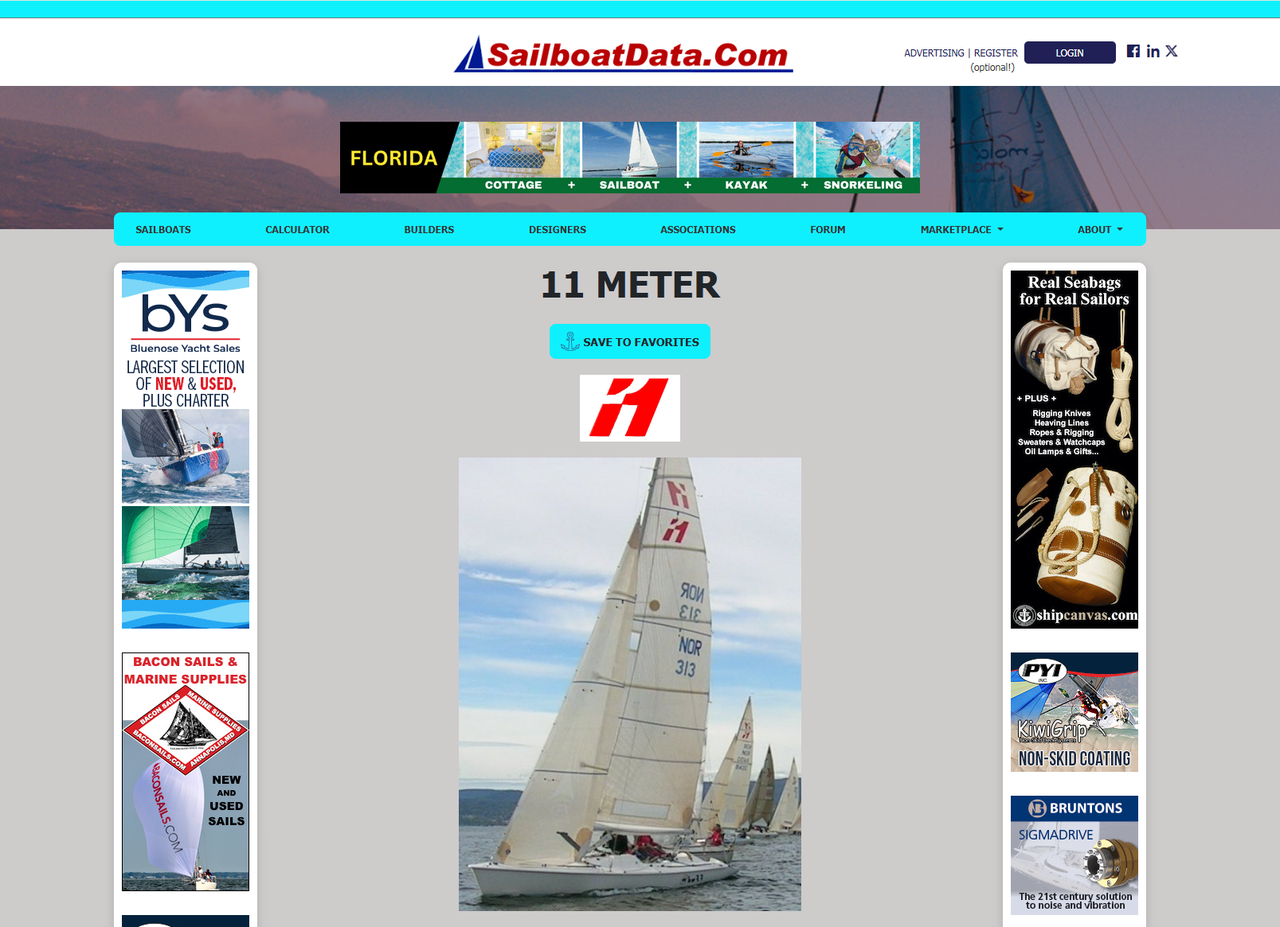
आइए पहले पुष्टि करने के लिए requests का उपयोग करके एक साधारण GET अनुरोध भेजने का प्रयास करें:
Python
def sailboatdata():
html = requests.get("https://sailboatdata.com/sailboat/11-meter/")
print(html.status_code) # 403
with open("response.html", "wb") as f:
f.write(html.content)जैसा कि अपेक्षित था, वेबपेज एक 403 निषिद्ध स्थिति कोड देता है। हमने प्रतिक्रिया को एक स्थानीय फ़ाइल में सहेजा है। लौटाई गई सामग्री का विशिष्ट स्रोत कोड नीचे दिखाया गया है:

लक्षित वेबसाइट सुरक्षित है, और स्थानीय फ़ाइल को ठीक से नहीं खोला जा सकता है। अब, हमें इसे बायपास करने का एक तरीका खोजने की आवश्यकता है।
चरण 3: Cloudscraper का उपयोग करके डेटा स्क्रैप करें
आइए लक्षित वेबसाइट पर समान GET अनुरोध भेजने के लिए Cloudscraper का उपयोग करें। यहाँ कोड दिया गया है:
Python
def sailboatdata_cloudscraper():
scraper = cloudscraper.create_scraper()
html = scraper.get("https://sailboatdata.com/sailboat/11-meter/")
print(html.status_code) # 200
with open("response.html", "wb") as f:
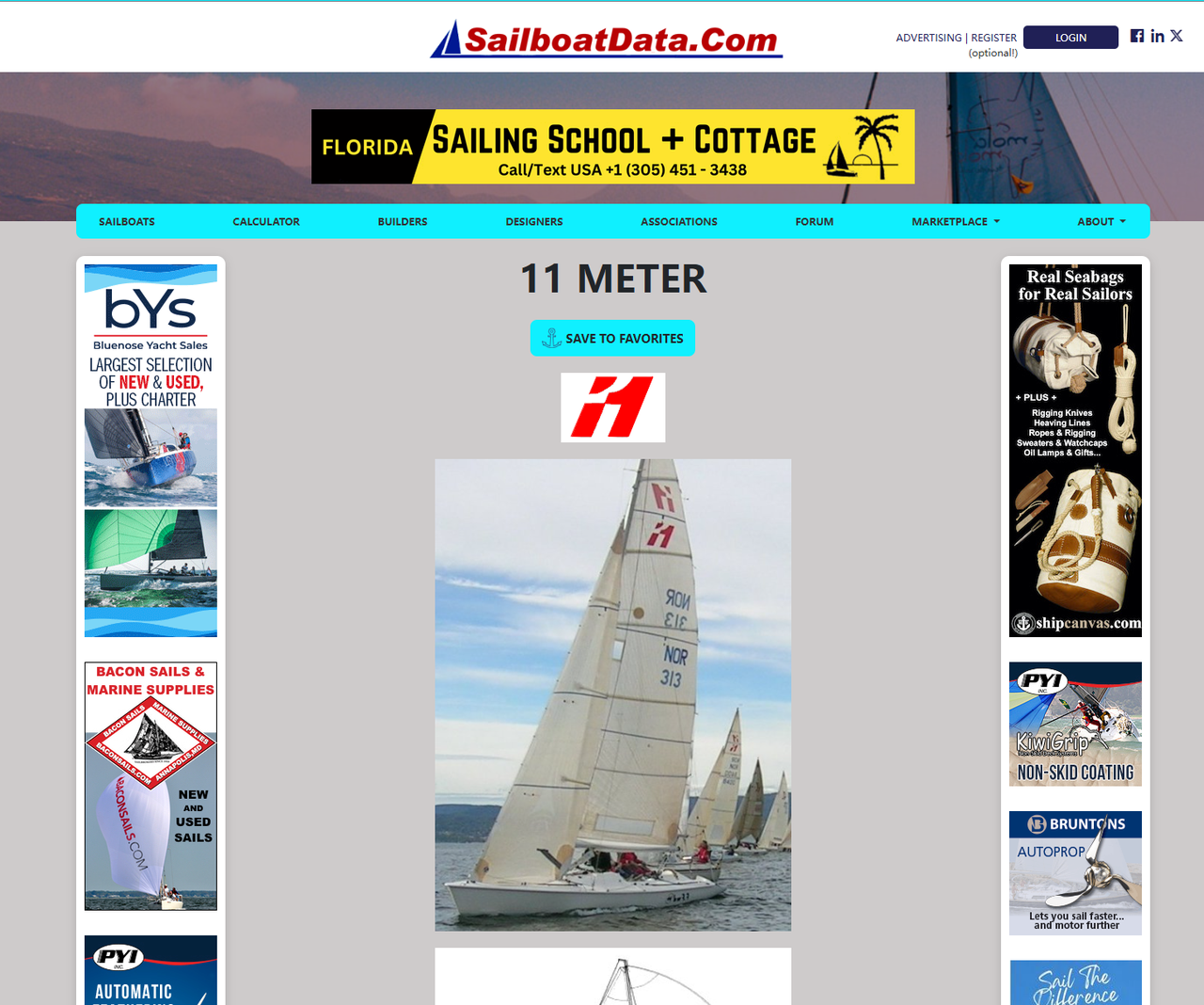
f.write(html.content)इस बार, Cloudflare ने हमारे अनुरोध को अवरुद्ध नहीं किया। हम सहेजी गई HTML फ़ाइल को स्थानीय रूप से खोलते हैं और इसे ब्राउज़र में देखते हैं। पेज इस तरह दिखता है:
Cloudscraper की उन्नत सुविधाएँ
अंतर्निहित CAPTCHA हैंडलिंग
JavaScript
scraper = cloudscraper.create_scraper(
captcha={
'provider': '2captcha',
'api_key': '2captcha_api_key'
}
)कस्टम प्रॉक्सी समर्थन
Python
proxies = {"http": "आपका प्रॉक्सी पता", "https": "आपका प्रॉक्सी पता"}
scraper = cloudscraper.create_scraper()
scraper.proxies.update(proxies)
html = scraper.get("https://sailboatdata.com/sailboat/11-meter/")Scrapeless स्क्रैपिंग ब्राउज़र: Cloudscraper का एक अधिक शक्तिशाली विकल्प
Cloudscraper की सीमाएँ
कुछ Cloudflare-सुरक्षित वेबसाइटों से निपटने के दौरान Cloudscraper में कुछ सीमाएँ हैं। सबसे उल्लेखनीय मुद्दा यह है कि यह Cloudflare के रोबोट पहचान v2 सुरक्षा तंत्र को बायपास नहीं कर सकता है। यदि आप ऐसी वेबसाइट से डेटा स्क्रैप करने का प्रयास करते हैं, तो आप निम्न त्रुटि संदेश ट्रिगर करेंगे:
JSON
cloudscraper.exceptions.CloudflareChallengeError: Detected a Cloudflare version 2 challenge, This feature is not available in the opensource (free) version.इसके अतिरिक्त, Cloudscraper Cloudflare की उन्नत JavaScript चुनौतियों का भी सामना करने में असमर्थ है। इन चुनौतियों में अक्सर जटिल गतिशील गणना या पृष्ठ तत्वों के साथ बातचीत शामिल होती है, जिन्हें सत्यापन पास करने के लिए Cloudscraper जैसे स्वचालित उपकरणों के लिए अनुकरण करना मुश्किल होता है।
एक और समस्या Cloudflare की दर सीमा नीति है। दुरुपयोग को रोकने के लिए, Cloudflare अनुरोध आवृत्ति को सख्ती से नियंत्रित करता है, और Cloudscraper में इन सीमाओं का प्रबंधन करने के लिए एक प्रभावी तंत्र का अभाव है, जिससे अनुरोध में देरी या विफलता हो सकती है।
अंत में, लेकिन कम से कम नहीं, जैसे ही Cloudflare अपनी बॉट पहचान तकनीक को अपग्रेड करता रहता है, एक ओपन सोर्स टूल के रूप में Cloudscraper के लिए इन परिवर्तनों के साथ तालमेल बिठाना मुश्किल है। समय के साथ, इसके कार्यक्षमता की प्रभावशीलता और स्थिरता धीरे-धीरे कम हो सकती है, खासकर सुरक्षा तंत्र के नए संस्करणों के सामने।
Scrapeless क्यों प्रभावी है?
स्क्रैपिंग ब्राउज़र गतिशील वेबसाइटों से बड़ी मात्रा में डेटा निकालने के लिए एक उच्च-प्रदर्शन समाधान है। यह डेवलपर्स को समर्पित सर्वर संसाधनों के बिना हेडलेस ब्राउज़र चलाने, प्रबंधित करने और मॉनिटर करने की अनुमति देता है। यह कुशल, बड़े पैमाने पर वेब डेटा निष्कर्षण के लिए डिज़ाइन किया गया है:
- ब्राउज़र फ़िंगरप्रिंटिंग और TLS फ़िंगरप्रिंटिंग पहचान जैसे उन्नत एंटी-क्रॉलर तंत्र को बायपास करने के लिए वास्तविक मानव संपर्क व्यवहार का अनुकरण करें।
- बिना किसी रुकावट के क्रॉलिंग प्रक्रिया सुनिश्चित करने के लिए cf_challenge सहित कई प्रकार के सत्यापन कोड के स्वचालित समाधान का समर्थन करें।
- विकास प्रक्रिया को सरल बनाने और स्वचालित कार्यों को शुरू करने के लिए सिंगल-लाइन कोड का समर्थन करने के लिए पुपेटियर और प्लेराइट जैसे लोकप्रिय टूल का सहज एकीकरण।
स्क्रैपिंग ब्राउज़र को Cloudflare को बायपास करने के लिए कैसे एकीकृत करें?
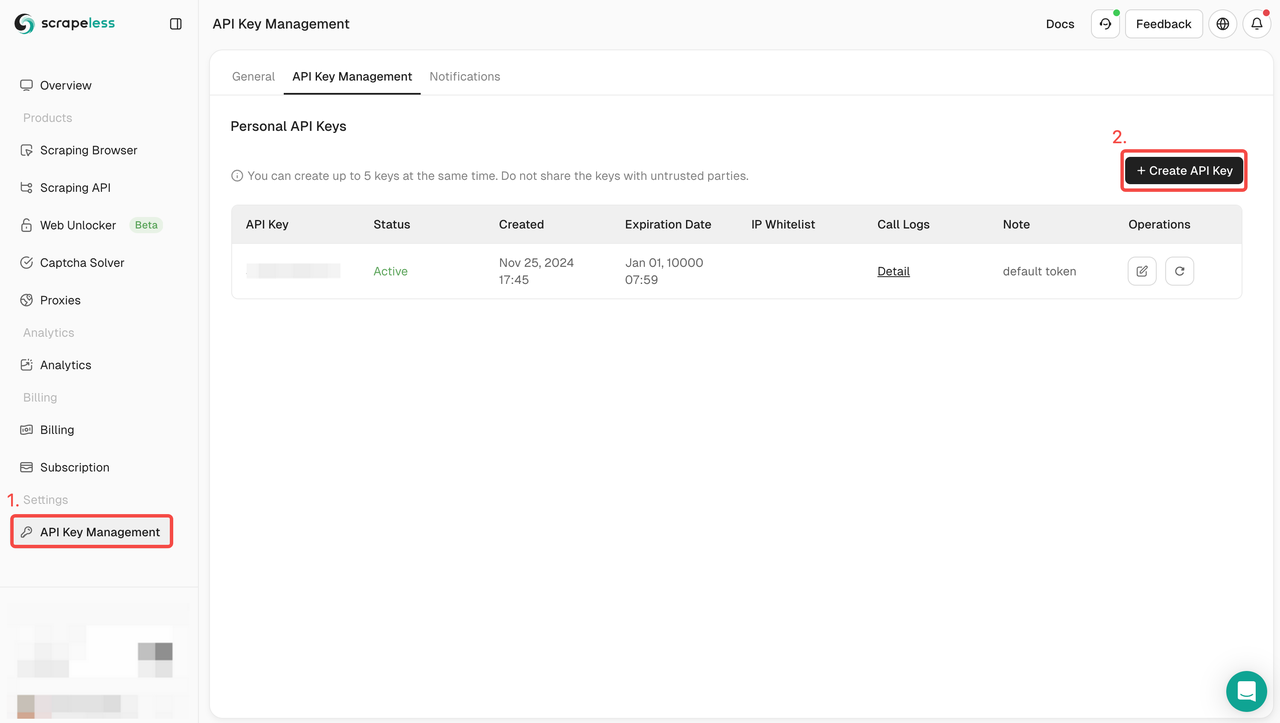
चरण 1. अपना API टोकन बनाएँ
- Scrapeless के लिए साइन अप करें
- API कुंजी प्रबंधन चुनें
- अपनी Scrapeless API कुंजी बनाने के लिए API कुंजी बनाएँ पर क्लिक करें।
Scrapeless निर्बाध वेब स्क्रैपिंग सुनिश्चित करता है।
🎁 Discord में शामिल हों और अभी अपना निःशुल्क परीक्षण प्राप्त करें!
चरण 2। फिर, स्क्रैपिंग ब्राउज़र पर जाएँ और अपना ब्राउज़र URL कॉपी करें।
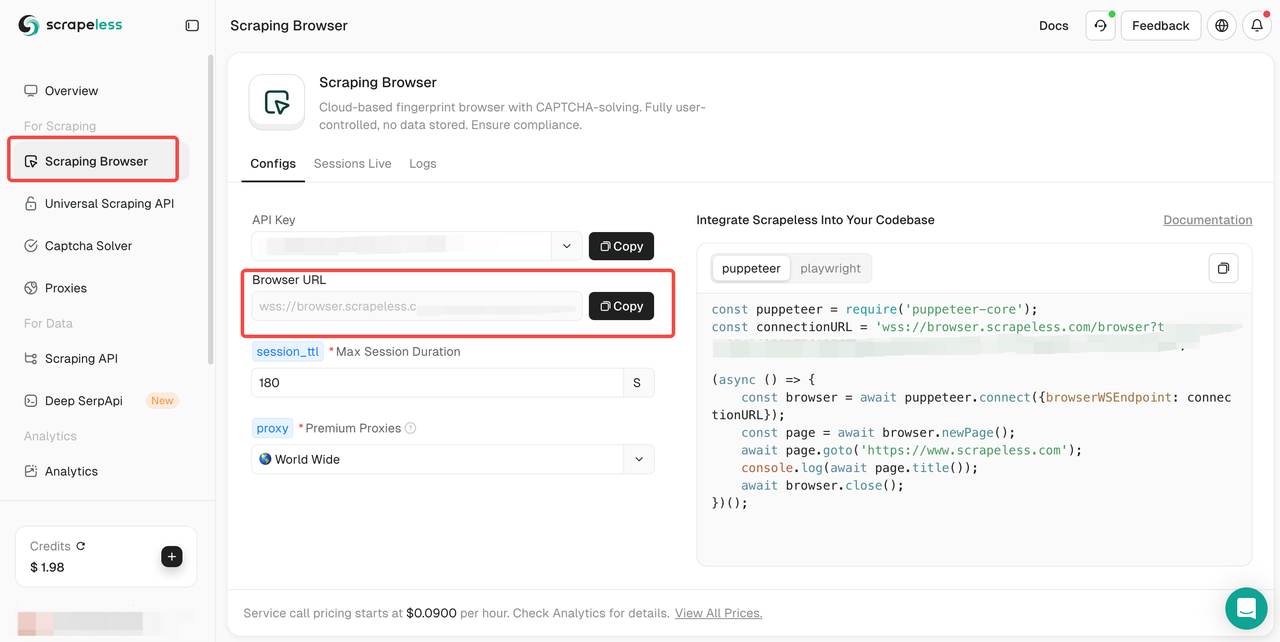
या आप संदर्भ के रूप में हमारे अनुरोध कोड की जांच कर सकते हैं:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_API_TOKEN>&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();चरण 3। अपने Puppeteer स्क्रिप्ट में कोड या ब्राउज़र URL को एकीकृत करें:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_Scrapeless_API_KEY>&session_ttl=180&proxy_country=ANY';
(async () => {
// ब्राउज़र वातावरण सेट करें
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
});
// एक नया पेज बनाएँ
const page = await browser.newPage();
// किसी URL पर नेविगेट करें
await page.goto('https://sailboatdata.com/sailboat/11-meter/', {
waitUntil: 'networkidle0',
}); // अपने लक्षित URL से बदलें
// चुनौती के हल होने का इंतजार करें
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
// पेज स्क्रीनशॉट लें
await page.screenshot({ path: 'screenshot.png' });
// ब्राउज़र उदाहरण बंद करें
await browser.close();
})();Cloudflare को बायपास करने के 4 सुझाव
यदि आप स्वयं Cloudflare को हैक करना चाहते हैं, तो यह बहुत कठिन होगा! आपको उन सभी बचावों पर विचार करना होगा जो Cloudflare बॉट्स के खिलाफ करता है और उन्हें दूर करने के तरीके खोजता है। अधिकांश लोग निश्चित रूप से ऐसा करना नहीं चुनेंगे।
क्या आप इसे आजमाना चाहेंगे? Cloudflare को बायपास करने में आपकी मदद करने के लिए यहां कुछ सुझाव दिए गए हैं:
जावास्क्रिप्ट रेंडरिंग
Cloudflare अक्सर बॉट्स का पता लगाने के लिए जावास्क्रिप्ट चुनौतियों का उपयोग करता है। ये स्क्रिप्ट वेब पेजों में एम्बेडेड होते हैं और यह निर्धारित करने के लिए ब्राउज़र के माध्यम से विशिष्ट जांच करते हैं कि आगंतुक बॉट है या नहीं। यदि किसी बॉट पर संदेह है, तो Cloudflare एक CAPTCHA (जैसे टर्नस्टाइल सत्यापन कोड) प्रदर्शित करेगा, अन्यथा यह सामान्य पहुंच की अनुमति देगा।
इसलिए, संरक्षित पृष्ठों को क्रॉल करने के लिए, आपको वास्तविक उपयोगकर्ता इंटरैक्शन का अनुकरण करने के लिए प्लेराइट, सेलेनियम या पुपेटियर जैसे ब्राउज़र ऑटोमेशन टूल का उपयोग करने की आवश्यकता है। हालाँकि, हेडलेस ब्राउज़र का डिफ़ॉल्ट कॉन्फ़िगरेशन एंटी-बॉट सिस्टम के लिए उजागर हो सकता है। ऑटोमेशन ट्रेस को छिपाने के लिए प्लेराइट स्टील्थ या पुपेटियर स्टील्थ लाइब्रेरी का उपयोग करने की सिफारिश की जाती है।
CAPTCHA समाधान
CAPTCHA बॉट्स को मनुष्यों से अलग करने के लिए एक प्रमुख परीक्षण है। इसमें सरल क्लिक सत्यापन या जटिल पहेलियाँ शामिल हो सकती हैं। स्वचालित रूप से CAPTCHA को पार्स करना मुश्किल है, इसलिए आप इसे पायथन तकनीक से बायपास करने का प्रयास कर सकते हैं या इसे स्वचालित रूप से हल करने के लिए ब्राइट डेटा के Cloudflare टर्नस्टाइल सॉल्वर का उपयोग कर सकते हैं।
दर सीमा से बचाव
Cloudflare थोड़े समय में बहुत अधिक अनुरोधों के लिए दर सीमा को ट्रिगर करेगा, जिससे IP अस्थायी रूप से या स्थायी रूप से अवरुद्ध हो सकता है। इस समस्या से बचने के लिए, IP रोटेशन को लागू करने और अनुरोध को वास्तविक डिवाइस के रूप में प्रच्छन्न करने के लिए प्रॉक्सी सेवा (जैसे आवासीय प्रॉक्सी) का उपयोग करने की अनुशंसा की जाती है।
ब्राउज़र स्पूफिंग
जबकि ब्राउज़र ऑटोमेशन टूल प्रभावी होते हैं, वे बहुत सारे संसाधन खपत करते हैं। यदि Cloudflare WAF को सख्ती से कॉन्फ़िगर नहीं किया गया है, तो आप वास्तविक ब्राउज़र व्यवहार की नकल करने के लिए HTTP अनुरोध भेजने के लिए ब्राउज़र स्पूफिंग तकनीक का उपयोग कर सकते हैं (जैसे User-Agent हेडर सेट करना)। हालाँकि, अधिक जटिल परिदृश्यों में, अकेले हेडर पर्याप्त नहीं हो सकते हैं, और आपको ब्राउज़र के TLS फ़िंगरप्रिंट की भी प्रतिलिपि बनाने की आवश्यकता हो सकती है (जैसे curl-impersonate टूल का उपयोग करके)।
अंत
इस लेख में, आपने Cloudflare द्वारा सुरक्षित वेबसाइटों को स्क्रैप करने के तरीके पर सुझाव और तरकीबें सीखीं। Cloudflare बाजार में सबसे लोकप्रिय CDN सेवा है, और यह उन्नत एंटी-बॉट समाधान भी प्रदान करती है।
जैसा कि इस लेख में दिखाया गया है, Cloudflare के एंटी-स्क्रैपिंग उपायों को बायपास करना चुनौतीपूर्ण है, लेकिन असंभव नहीं है। पेशेवर, तेज और विश्वसनीय स्क्रैपिंग समाधानों से सब कुछ आसान हो जाता है, जैसे:
- यूनिवर्सल स्क्रैपिंग API: निर्बाध सार्वजनिक वेब डेटा संग्रह के लिए स्वायत्त रूप से दर सीमा, फ़िंगरप्रिंटिंग और अन्य एंटी-बॉट प्रतिबंधों को बायपास करता है।
- स्क्रैपिंग ब्राउज़र: एक पूरी तरह से होस्ट किया गया ब्राउज़र जो आपको प्रक्रिया को स्वचालित करते हुए गतिशील वेब डेटा को स्क्रैप करने की अनुमति देता है।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


