
How to Enhance Scrapling with Scrapeless Cloud Browser (with Integration Code)
Expert Network Defense Engineer
In this tutorial, you will learn:
- What Scrapling is and what it offers for web scraping
- How to integrate Scrapling with the Scrapeless Cloud Browser
Let's get started!
PART 1: What is Scrapling?
Overview
Scrapling is an undetectable, powerful, flexible, and high-performance Python web scraping library designed to make web scraping simple and effortless. It is the first adaptive scraping library capable of learning from website changes and evolving along with them. While other libraries break when site structures update, Scrapling automatically repositions elements and keeps your scrapers running smoothly.
Key Features
- Adaptive Scraping Technology – The first library that learns from website changes and automatically evolves. When a site’s structure updates, Scrapling intelligently repositions elements to ensure continuous operation.
- Browser Fingerprint Spoofing – Supports TLS fingerprint matching and real browser header emulation.
- Stealth Scraping Capabilities – The StealthyFetcher can bypass advanced anti-bot systems like Cloudflare Turnstile.
- Persistent Session Support – Offers multiple session types, including FetcherSession, DynamicSession, and StealthySession, for reliable and efficient scraping.
Learn more in the [official documentation].
Use Cases
As the first adaptive Python scraping library, Scrapling can automatically learn and evolve with website changes. Its built-in stealth mode can bypass protections like Cloudflare, making it ideal for long-running, enterprise-level data collection projects. It is especially suitable for use cases that require handling frequent website updates, such as e-commerce price monitoring or news tracking.
PART 2: What is Scrapeless Browser?
Scrapeless Browser is a high-performance, scalable, and low-cost cloud browser infrastructure designed for automation, data extraction, and AI agent browser operations.
PART 3: Why Combine Scrapeless and Scrapling?
Scrapling excels at high-performance web data extraction, supporting adaptive scraping and AI integration. It comes with multiple built-in Fetcher classes — Fetcher, DynamicFetcher, and StealthyFetcher — to handle various scenarios. However, when facing advanced anti-bot mechanisms or large-scale concurrent scraping, several challenges may still arise:
- Local browsers can be easily blocked by Cloudflare, AWS WAF, or reCAPTCHA.
- High browser resource consumption limits performance during large-scale concurrent scraping.
- Although StealthyFetcher has built-in stealth capabilities, extreme anti-bot scenarios may still require stronger infrastructure support.
- Debugging failures can be complicated, making it difficult to pinpoint the root cause.
Scrapeless Cloud Browser effectively addresses these challenges:
- One-Click Anti-Bot Bypass – Automatically handles reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF, and other verifications. Combined with Scrapling’s adaptive extraction, success rates are significantly improved.
- Unlimited Concurrent Scaling – Each task can launch 50–1000+ browser instances within seconds, removing local performance bottlenecks and maximizing Scrapling’s high-performance potential.
- Cost Reduction by 40–80% – Compared to similar cloud services, Scrapeless costs only 20–60% overall and supports pay-as-you-go billing, making it affordable even for small projects.
- Visual Debugging Tools – Monitor Scrapling execution in real time with Session Replay and Live URL, quickly identify scraping failures, and reduce debugging costs.
- Flexible Integration – Scrapling’s DynamicFetcher and PlaywrightFetcher (built on Playwright) can connect to Scrapeless Cloud Browser via configuration without rewriting existing logic.
- Edge Service Nodes – Global nodes offer startup speed and stability 2–3× faster than other cloud browsers, with over 90 million trusted residential IPs across 195+ countries, accelerating Scrapling execution.
- Isolated Environments & Persistent Sessions – Each Scrapeless profile runs in an isolated environment, supporting persistent logins and session separation to improve stability for large-scale scraping.
- Flexible Fingerprint Configuration – Scrapeless can randomly generate or fully customize browser fingerprints. When paired with Scrapling’s StealthyFetcher, detection risk is further reduced and success rates increase.
Getting Started
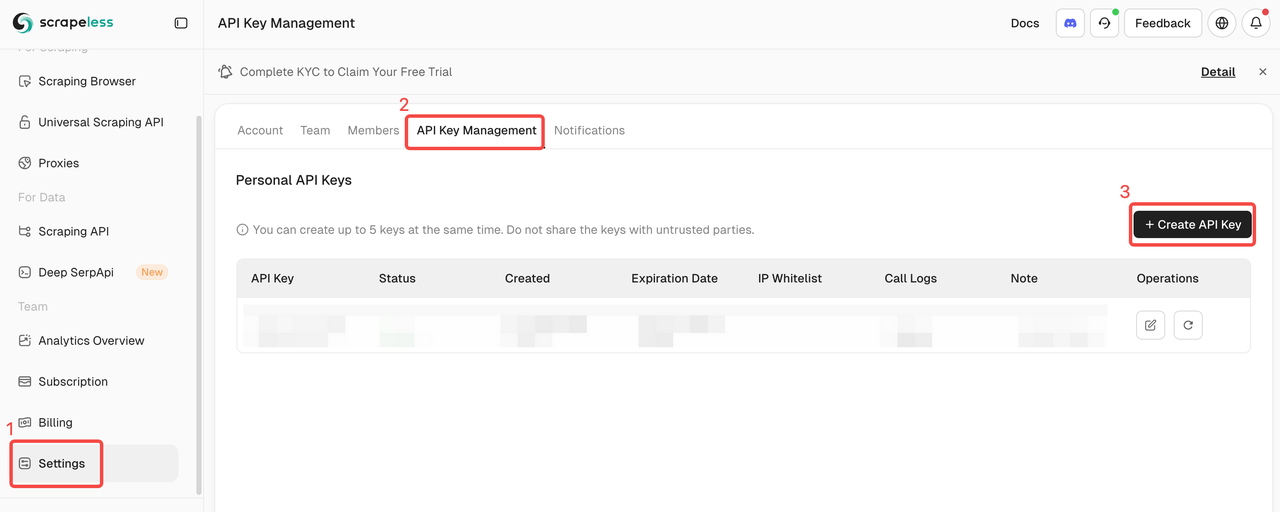
Log in to Scrapeless and get your API Key.
Prerequisites
- Python 3.10+
- A registered Scrapeless account with a valid API Key
- Install Scrapling (or use the Docker image):
bash
pip install scrapling
# If you need fetchers (dynamic/stealth):
pip install "scrapling[fetchers]"
# Install browser dependencies
scrapling install- Or use the official Docker image:
bash
docker pull pyd4vinci/scrapling
# or
docker pull ghcr.io/d4vinci/scrapling:latestQuickstart — Connect to Scrapeless Cloud Browser Using DynamicSession
Here is the simplest example: connect to the Scrapeless Cloud Browser WebSocket endpoint using DynamicSession provided by Scrapling, then fetch a page and print the response.
from urllib.parse import urlencode
from scrapling.fetchers import DynamicSession
# Configure your browser session
config = {
"token": "YOUR_API_KEY",
"sessionName": "scrapling-session",
"sessionTTL": "300", # 5 minutes
"proxyCountry": "ANY",
"sessionRecording": "false",
}
# Build WebSocket URL
ws_endpoint = f"wss://browser.scrapeless.com/api/v2/browser?{urlencode(config)}"
print('Connecting to Scrapeless...')
with DynamicSession(cdp_url=ws_endpoint, disable_resources=True) as s:
print("Connected!")
page = s.fetch("https://httpbin.org/headers", network_idle=True)
print(f"Page loaded, content length: {len(page.body)}")
print(page.json())Note: The Scrapeless Cloud Browser supports configurable proxy options, such as proxy country, custom fingerprint settings, CAPTCHA solving, and more.
Refer to the Scrapeless browser documentation for more detailed information.
Common Use Cases (with Full Examples)
Here we demonstrate a typical practical scenario combining Scrapling and Scrapeless.
💡 Before getting started, make sure that you have:
- Installed dependencies using
pip install "scrapling[fetchers]" - Downloaded the browser with
scrapling install; - Obtained a valid API Key from the Scrapeless dashboard;
- Python 3.10+ installed.
Scraping Amazon with Scrapling + Scrapeless
Below is a complete Python example for scraping Amazon product details.
The script automatically connects to the Scrapeless Cloud Browser, loads the target page, detects anti-bot protections, and extracts core information such as:
- Product title
- Price
- Stock status
- Rating
- Number of reviews
- Feature descriptions
- Product images
- ASIN
- Seller information
- Categories
# amazon_scraper_response_only.py
from urllib.parse import urlencode
import json
import time
import re
from scrapling.fetchers import DynamicSession
# ---------------- CONFIG ----------------
CONFIG = {
"token": "YOUR_SCRAPELESS_API_KEY",
"sessionName": "Data Scraping",
"sessionTTL": "900",
"proxyCountry": "ANY",
"sessionRecording": "true",
}
DISABLE_RESOURCES = True # False -> load JS/resources (more stable for JS-heavy sites)
WAIT_FOR_SELECTOR_TIMEOUT = 60
MAX_RETRIES = 3
TARGET_URL = "https://www.amazon.com/ESR-Compatible-Military-Grade-Protection-Scratch-Resistant/dp/B0CC1F4V7Q"
WS_ENDPOINT = f"wss://browser.scrapeless.com/api/v2/browser?{urlencode(CONFIG)}"
# ---------------- HELPERS (use response ONLY) ----------------
def retry(func, retries=2, wait=2):
for i in range(retries + 1):
try:
return func()
except Exception as e:
print(f"[retry] Attempt {i+1} failed: {e}")
if i == retries:
raise
time.sleep(wait * (i + 1))
def _resp_css_first_text(resp, selector):
"""Try response.css_first('selector::text') or resp.query_selector_text(selector) - return str or None."""
try:
if hasattr(resp, "css_first"):
# prefer unified ::text pseudo API
val = resp.css_first(f"{selector}::text")
if val:
return val.strip()
except Exception:
pass
try:
if hasattr(resp, "query_selector_text"):
val = resp.query_selector_text(selector)
if val:
return val.strip()
except Exception:
pass
return None
def _resp_css_texts(resp, selector):
"""Return list of text values for selector using response.css('selector::text') or query_selector_all_text."""
out = []
try:
if hasattr(resp, "css"):
vals = resp.css(f"{selector}::text") or []
for v in vals:
if isinstance(v, str) and v.strip():
out.append(v.strip())
if out:
return out
except Exception:
pass
try:
if hasattr(resp, "query_selector_all_text"):
vals = resp.query_selector_all_text(selector) or []
for v in vals:
if v and v.strip():
out.append(v.strip())
if out:
return out
except Exception:
pass
# some fetchers provide query_selector_all and elements with .text() method
try:
if hasattr(resp, "query_selector_all"):
els = resp.query_selector_all(selector) or []
for el in els:
try:
if hasattr(el, "text") and callable(el.text):
t = el.text()
if t and t.strip():
out.append(t.strip())
continue
except Exception:
pass
try:
if hasattr(el, "get_text"):
t = el.get_text(strip=True)
if t:
out.append(t)
continue
except Exception:
pass
except Exception:
pass
return out
def _resp_css_first_attr(resp, selector, attr):
"""Try to get attribute via response css pseudo ::attr(...) or query selector element attributes."""
try:
if hasattr(resp, "css_first"):
val = resp.css_first(f"{selector}::attr({attr})")
if val:
return val.strip()
except Exception:
pass
try:
# try element and get_attribute / get
if hasattr(resp, "query_selector"):
el = resp.query_selector(selector)
if el:
if hasattr(el, "get_attribute"):
try:
v = el.get_attribute(attr)
if v:
return v
except Exception:
pass
try:
v = el.get(attr) if hasattr(el, "get") else None
if v:
return v
except Exception:
pass
try:
attrs = getattr(el, "attrs", None)
if isinstance(attrs, dict) and attr in attrs:
return attrs.get(attr)
except Exception:
pass
except Exception:
pass
return None
def detect_bot_via_resp(resp):
"""Detect typical bot/captcha signals using response text selectors only."""
checks = [
# body text
("body",),
# some common challenge indicators
("#challenge-form",),
("#captcha",),
("text:contains('are you a human')",),
]
# First try a broad body text
try:
body_text = _resp_css_first_text(resp, "body")
if body_text:
txt = body_text.lower()
for k in ("captcha", "are you a human", "verify you are human", "access to this page has been denied", "bot detection", "please enable javascript", "checking your browser"):
if k in txt:
return True
except Exception:
pass
# Try specific selectors
suspects = [
"#captcha", "#cf-hcaptcha-container", "#challenge-form", "text:contains('are you a human')"
]
for s in suspects:
try:
if _resp_css_first_text(resp, s):
return True
except Exception:
pass
return False
def parse_price_from_text(price_raw):
if not price_raw:
return None, None
m = re.search(r"([^\d.,\s]+)?\s*([\d,]+\.\d{1,2}|[\d,]+)", price_raw)
if m:
currency = m.group(1).strip() if m.group(1) else None
num = m.group(2).replace(",", "")
try:
price = float(num)
except Exception:
price = None
return currency, price
return None, None
def parse_int_from_text(text):
if not text:
return None
digits = "".join(filter(str.isdigit, text))
try:
return int(digits) if digits else None
except:
return None
# ---------------- MAIN (use response only) ----------------
def scrape_amazon_using_response_only(url):
with DynamicSession(cdp_url=WS_ENDPOINT, disable_resources=DISABLE_RESOURCES) as s:
# fetch with retry
resp = retry(lambda: s.fetch(url, network_idle=True, timeout=120000), retries=MAX_RETRIES - 1)
if detect_bot_via_resp(resp):
print("[warn] Bot/CAPTCHA detected via response selectors.")
try:
resp.screenshot(path="captcha_detected.png")
except Exception:
pass
# retry once
time.sleep(2)
resp = retry(lambda: s.fetch(url, network_idle=True, timeout=120000), retries=1)
# Wait for productTitle (polling using resp selectors only)
title = _resp_css_first_text(resp, "#productTitle") or _resp_css_first_text(resp, "#title")
waited = 0
while not title and waited < WAIT_FOR_SELECTOR_TIMEOUT:
print("[info] Waiting for #productTitle to appear (response selector)...")
time.sleep(3)
waited += 3
resp = s.fetch(url, network_idle=True, timeout=120000)
title = _resp_css_first_text(resp, "#productTitle") or _resp_css_first_text(resp, "#title")
title = title.strip() if title else None
# Extract fields using response-only helpers
def get_text(selectors, multiple=False):
if multiple:
out = []
for sel in selectors:
out.extend(_resp_css_texts(resp, sel) or [])
return out
for sel in selectors:
v = _resp_css_first_text(resp, sel)
if v:
return v
return None
price_raw = get_text([
"#priceblock_ourprice",
"#priceblock_dealprice",
"#priceblock_saleprice",
"#price_inside_buybox",
".a-price .a-offscreen"
])
rating_text = get_text(["span.a-icon-alt", "#acrPopover"])
review_count_text = get_text(["#acrCustomerReviewText", "[data-hook='total-review-count']"])
availability = get_text([
"#availability .a-color-state",
"#availability .a-color-success",
"#outOfStock",
"#availability"
])
features = get_text(["#feature-bullets ul li"], multiple=True) or []
description = get_text([
"#productDescription",
"#bookDescription_feature_div .a-expander-content",
"#productOverview_feature_div"
])
# images (use attribute extraction via response)
images = []
seen = set()
main_src = _resp_css_first_attr(resp, "#imgTagWrapperId img", "data-old-hires") \
or _resp_css_first_attr(resp, "#landingImage", "src") \
or _resp_css_first_attr(resp, "#imgTagWrapperId img", "src")
if main_src and main_src not in seen:
images.append(main_src); seen.add(main_src)
dyn = _resp_css_first_attr(resp, "#imgTagWrapperId img", "data-a-dynamic-image") \
or _resp_css_first_attr(resp, "#landingImage", "data-a-dynamic-image")
if dyn:
try:
obj = json.loads(dyn)
for k in obj.keys():
if k not in seen:
images.append(k); seen.add(k)
except Exception:
pass
thumbs = _resp_css_texts(resp, "#altImages img::attr(src)") or _resp_css_texts(resp, ".imageThumbnail img::attr(src)") or []
for src in thumbs:
if not src:
continue
src_clean = re.sub(r"\._[A-Z0-9,]+_\.", ".", src)
if src_clean not in seen:
images.append(src_clean); seen.add(src_clean)
# ASIN (attribute)
asin = _resp_css_first_attr(resp, "input#ASIN", "value")
if asin:
asin = asin.strip()
else:
detail_texts = _resp_css_texts(resp, "#detailBullets_feature_div li") or []
combined = " ".join([t for t in detail_texts if t])
m = re.search(r"ASIN[:\s]*([A-Z0-9-]+)", combined, re.I)
if m:
asin = m.group(1).strip()
merchant = _resp_css_first_text(resp, "#sellerProfileTriggerId") \
or _resp_css_first_text(resp, "#merchant-info") \
or _resp_css_first_text(resp, "#bylineInfo")
categories = _resp_css_texts(resp, "#wayfinding-breadcrumbs_container ul li a") or _resp_css_texts(resp, "#wayfinding-breadcrumbs_feature_div ul li a") or []
categories = [c.strip() for c in categories if c and c.strip()]
currency, price = parse_price_from_text(price_raw)
rating_val = None
if rating_text:
try:
rating_val = float(rating_text.split()[0].replace(",", ""))
except Exception:
rating_val = None
review_count = parse_int_from_text(review_count_text)
data = {
"title": title,
"price_raw": price_raw,
"price": price,
"currency": currency,
"rating": rating_val,
"review_count": review_count,
"availability": availability,
"features": features,
"description": description,
"images": images,
"asin": asin,
"merchant": merchant,
"categories": categories,
"url": url,
"scrapedAt": time.strftime("%Y-%m-%dT%H:%M:%SZ", time.gmtime()),
}
return data
# ---------------- RUN ----------------
if __name__ == "__main__":
try:
result = scrape_amazon_using_response_only(TARGET_URL)
print(json.dumps(result, indent=2, ensure_ascii=False))
with open("scrapeless-amazon-product.json", "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
except Exception as e:
print("[error] scraping failed:", e)Sample Output:
{
"title": "ESR for iPhone 15 Pro Max Case, Compatible with MagSafe, Military-Grade Protection, Yellowing Resistant, Scratch-Resistant Back, Magnetic Phone Case for iPhone 15 Pro Max, Classic Series, Clear",
"price_raw": "$12.99",
"price": 12.99,
"currency": "$",
"rating": 4.6,
"review_count": 133714,
"availability": "In Stock",
"features": [
"Compatibility: only for iPhone 15 Pro Max; full functionality maintained via precise speaker and port cutouts and easy-press buttons",
"Stronger Magnetic Lock: powerful built-in magnets with 1,500 g of holding force enable faster, easier place-and-go wireless charging and a secure lock on any MagSafe accessory",
"Military-Grade Drop Protection: rigorously tested to ensure total protection on all sides, with specially designed Air Guard corners that absorb shock so your phone doesn\u2019t have to",
"Raised-Edge Protection: raised screen edges and Camera Guard lens frame provide enhanced scratch protection where it really counts",
"Stay Original: scratch-resistant, crystal-clear acrylic back lets you show off your iPhone 15 Pro Max\u2019s true style in stunning clarity that lasts",
"Complete Customer Support: detailed setup videos and FAQs, comprehensive 12-month protection plan, lifetime support, and personalized help."
],
"description": "BrandESRCompatible Phone ModelsiPhone 15 Pro MaxColorA-ClearCompatible DevicesiPhone 15 Pro MaxMaterialAcrylic",
"images": [
"https://m.media-amazon.com/images/I/71-ishbNM+L._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/71-ishbNM+L._AC_SX342_.jpg",
"https://m.media-amazon.com/images/I/71-ishbNM+L._AC_SX679_.jpg",
"https://m.media-amazon.com/images/I/71-ishbNM+L._AC_SX522_.jpg",
"https://m.media-amazon.com/images/I/71-ishbNM+L._AC_SX385_.jpg",
"https://m.media-amazon.com/images/I/71-ishbNM+L._AC_SX466_.jpg",
"https://m.media-amazon.com/images/I/71-ishbNM+L._AC_SX425_.jpg",
"https://m.media-amazon.com/images/I/71-ishbNM+L._AC_SX569_.jpg",
"https://m.media-amazon.com/images/I/41Ajq9jnx9L._AC_SR38,50_.jpg",
"https://m.media-amazon.com/images/I/51RkuGXBMVL._AC_SR38,50_.jpg",
"https://m.media-amazon.com/images/I/516RCbMo5tL._AC_SR38,50_.jpg",
"https://m.media-amazon.com/images/I/51DdOFdiQQL._AC_SR38,50_.jpg",
"https://m.media-amazon.com/images/I/514qvXYcYOL._AC_SR38,50_.jpg",
"https://m.media-amazon.com/images/I/518CS81EFXL._AC_SR38,50_.jpg",
"https://m.media-amazon.com/images/I/413EWAtny9L.SX38_SY50_CR,0,0,38,50_BG85,85,85_BR-120_PKdp-play-icon-overlay__.jpg",
"https://images-na.ssl-images-amazon.com/images/G/01/x-locale/common/transparent-pixel._V192234675_.gif"
],
"asin": "B0CC1F4V7Q",
"merchant": "Minghutech-US",
"categories": [
"Cell Phones & Accessories",
"Cases, Holsters & Sleeves",
"Basic Cases"
],
"url": "https://www.amazon.com/ESR-Compatible-Military-Grade-Protection-Scratch-Resistant/dp/B0CC1F4V7Q",
"scrapedAt": "2025-10-30T10:20:16Z"
}This example demonstrates how DynamicSession and Scrapeless can work together to create a stable, reusable long-session environment.
Within the same session, you can request multiple pages without restarting the browser, maintain login states, cookies, and local storage, and achieve profile isolation and session persistence.
FAQ
What is the difference between Scrapling and Scrapeless?
Scrapling is a Python SDK mainly responsible for sending requests, managing sessions, and parsing content. Scrapeless, on the other hand, is a cloud browser service that provides a real browser execution environment (supporting the Chrome DevTools Protocol). Together, they enable highly anonymous scraping, anti-detection, and persistent sessions.
Can Scrapling be used alone?
Yes. Scrapling supports local execution mode (without cdp_url), which is suitable for lightweight tasks. However, if the target site employs Cloudflare Turnstile or other advanced bot protections, it is recommended to use Scrapeless to improve success rates.
What is the difference between StealthySession and DynamicSession?
- StealthySession: Designed specifically for anti-bot scenarios, it automatically applies browser fingerprint spoofing and anti-detection techniques.
- DynamicSession: Supports long sessions, persistent cookies, and profile isolation. It is ideal for tasks requiring login, shopping, or maintaining account states.
Does Scrapeless support concurrency or multiple sessions?
Yes. You can assign different sessionNames for each task, and Scrapeless will automatically isolate the browser environments. It supports hundreds to thousands of concurrent browser instances without being limited by local resources.
Summary
By combining Scrapling with Scrapeless, you can perform complex scraping tasks in the cloud with extremely high success rates and flexibility:
| Feature | Recommended Class | Use Case / Scenario |
|---|---|---|
| High-Speed HTTP Scraping | Fetcher / FetcherSession | Regular static web pages |
| Dynamic Content Loading | DynamicFetcher / DynamicSession | Pages with JS-rendered content |
| Anti-Detection & Cloudflare Bypass | StealthyFetcher / StealthySession | Highly protected target websites |
| Persistent Login / Profile Isolation | DynamicSession | Multiple accounts or consecutive operations |
This collaboration marks a significant milestone for Scrapeless and Scrapling in the field of web data scraping.
In the future, Scrapeless will focus on the cloud browser domain, providing enterprise clients with efficient, scalable data extraction, automation, and AI Agent infrastructure support. Leveraging its powerful cloud capabilities, Scrapeless will continue to deliver customized and scenario-based solutions for industries such as finance, retail, e-commerce, SEO, and marketing, empowering businesses to achieve true automated growth in the era of data intelligence.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


