
Top 5 Scraping Browsers 2025 | Missed only Cryed!
Expert Network Defense Engineer
What Is Web Scraping and How It Is Used?
Web scraping is a technology for extracting data from the Internet, usually by automatically crawling and structuring the information on the website. Scraping usually involves accessing a web page by sending an HTTP request, obtaining the page content, and then parsing and extracting the required data, such as text, images, links, table data, etc.
Scraping is one of the core technologies for large-scale data collection and is widely used in many fields, such as price monitoring, market research, competition analysis, news aggregation, and academic research. Since the data of many websites are presented in the form of HTML pages, web scraping can convert these contents into structured data for subsequent analysis and use.
How Does Web Scraping Work?
Step 1. Sending a request: Your web scraping tool first sends an HTTP request to the target website to simulate the browsing behavior of real users.
Step 2. Getting web page content: The website will return the HTML page content, and the scraper parses it.
Step 3. Data parsing: It uses HTML parsing tools (such as BeautifulSoup, lxml, etc.) to extract specific data on the page.
Step 4. Data storage: The extracted data can be stored in formats such as CSV, JSON, or databases for subsequent processing and analysis.
Scraping browsers usually perform these steps automatically, providing a more efficient and reliable scraping process.
How to Choose a Web Page Scraper
There are many ways to access web data. Even if you have narrowed down to web scrapers, the tools with various confusing features that pop up in the search results can still make it difficult to make a decision.
Before choosing a web scraper, you can consider the following aspects:
- Device: If you are a Mac or Linux user, you should make sure that the tool supports your system as most web scrapers are only available for Windows.
- Cloud services: Cloud services are important if you want to access data across devices at any time.
- API access and IP proxy: Web scraping has its own challenges and anti-scraping techniques. IP rotation and API access will help you never get blocked.
- Integration: How will you use the data later? Integration options can better automate the entire data processing process.
- Training: If you are not good at programming, it is better to make sure that there are guides and support to help you throughout the data scraping process.
- Pricing: The cost of web page scrapers is always a factor to consider and it varies greatly from vendor to vendor.
Top 5 Scraping Browsers
1. Scrapeless
Scrapeless Scraping Browser provides a high-performance serverless platform designed to simplify the process of data extraction from dynamic websites. Through seamless integration with Puppeteer, developers can run, manage and monitor headless browsers without the need for dedicated servers, enabling efficient web automation and data collection.
With a global network covering 195 countries and over 70 million residential IPs, Scraping Browser provides 99.9% uptime and high success rates. It bypasses common obstacles like IP blocking and CAPTCHA, making it ideal for complex web automation and AI-driven data collection. Perfect for users who need a reliable, scalable web scraping solution.
How to integrate this web scraping tool into your project? Follow my steps now!
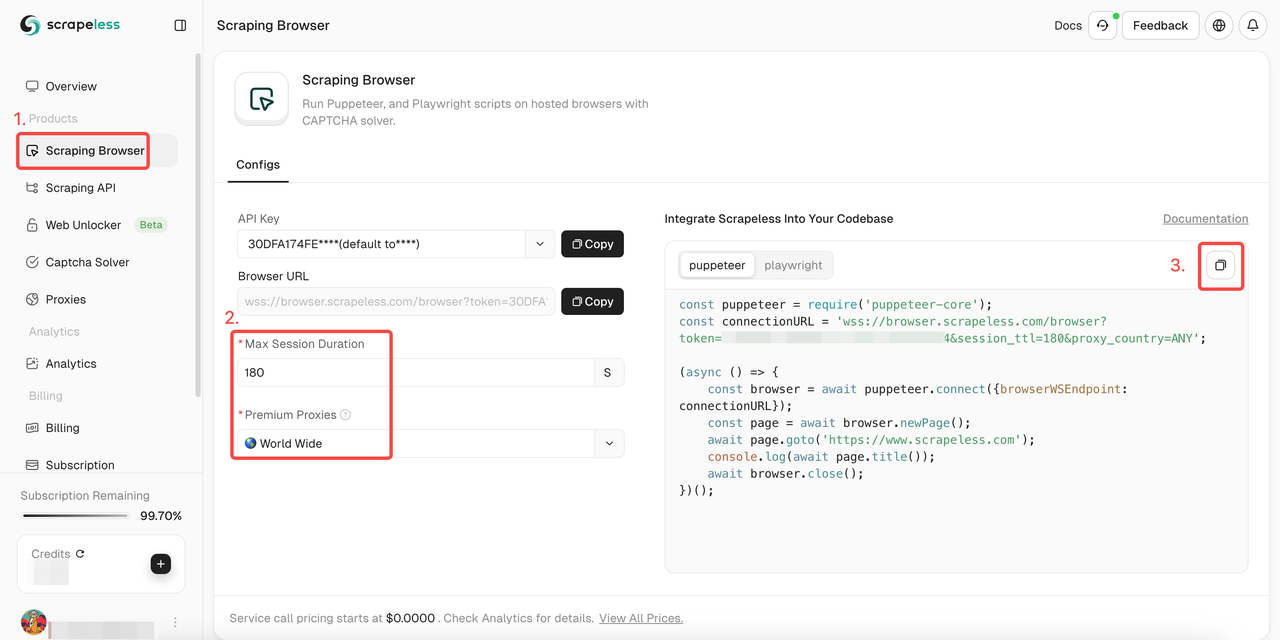
- Sign in Scrapeless
- Enter the "Scraping Browser"
- Set parameters according to your needs
- Copy the sample codes for integrating into your project
- Sample codes:
- Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input your token
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();- Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input your token
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();- Want to get more details? Our documentation will help you a lot!
2. ParseHub
Parsehub is a common web scraping tool that uses JavaScript, AJAX technology, cookies, etc. to collect data from websites. It supports Windows, Mac OS X, and Linux systems.
Parsehub uses machine learning technology to read, analyze web documents, and convert them into relevant data. But it is not completely free, you can only set up to five scraping tasks for free.
3. Import
Import.io is a unique SaaS web data integration software. It provides end users with a visual environment for designing and customizing data collection workflows.
It covers the entire web extraction lifecycle from data extraction to analysis on one platform. And you can also easily integrate into other systems.
In addition to the fully hosted scraping browser, we can also use powerful plugins or extensions:
4. Webscraper
Web Scraper has a Chrome extension and a cloud extension.
For the Chrome extension version, you can create a sitemap (plan) of how to navigate the website and what data should be scraped.
The cloud extension can scrape large amounts of data and run multiple scraping tasks simultaneously. You can export the data to CSV or store the data in Couch DB.
5. Dexi
Dexi.io is more for advanced users with proficient programming skills. It has three types of programs for you to create scraping tasks - extractors, crawlers, and pipelines. It provides a variety of tools that allow you to extract data more precisely. With its modern features, you will be able to handle detailed information on any website.
However, if you don't have programming skills, you may need to spend some time getting used to it before you can create a web scraping robot.
Why Scraping Browser Can Enhance Your Work?
Scraping browsers (such as Puppeteer, Playwright, etc.) can significantly improve the efficiency of web crawling for the following reasons:
- Support dynamic content: Scraping browsers can handle page content dynamically generated using JavaScript by providing full browser rendering capabilities, and crawl more valid data.
- Simulate real user behavior: Scraping browsers can simulate real user behavior, such as clicking, scrolling, entering data, etc., to avoid being detected by anti-crawling mechanisms.
- Improve stability: Scraping browsers can improve the success rate and stability of crawling by integrating proxy management, automated verification code solutions and other functions.
- Cross-platform support: Many crawling browsers support cross-platform operations and can run on different operating systems (Windows, Linux, MacOS, etc.), providing more flexibility.
- High concurrency support: Some crawling browsers (such as Browserless) also provide cloud services, support high-concurrency crawling and large-scale data collection, which is suitable for scenarios that need to process large amounts of data.
Final Thoughts
Which web scraping tool is most suitable for you, Scraping browser or scraping extensions? You definitely want to use the most convenient and efficient tool for fast web scraping. Try Scrapeless now!
Scrapeless scraping browser makes web scraping simply and efficiently. With CAPTCHA bypassing and IP smart rotation, you can avoid website blocking and easily achieve data scraping.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


