Scrapeless Cloud Browser in Action: Adapting Puppeteer for Automation, Fingerprint, and CAPTCHA Handling
Specialist in Anti-Bot Strategies
In web automation and data scraping scenarios, developers often face three core technical challenges:
- Environment Isolation:
When running dozens or even hundreds of independent browser sessions simultaneously, traditional local deployment solutions suffer from high resource consumption, complex management, and cumbersome configuration.
- Fingerprint Detection Risks:
Repeated visits using the same browser fingerprint can easily trigger anti-bot and fingerprint detection mechanisms on target websites.
- CAPTCHA Interruptions:
Once triggered, verifications like reCAPTCHA or Cloudflare Turnstile interrupt automation scripts. Integrating third-party CAPTCHA-solving services not only increases development cost and complexity, but also reduces execution efficiency.
These problems often require developers to spend significant time setting up local environments or integrating external services, driving up both time and operational costs.
Essentially, what’s needed is a tool capable of the following:
- Massively Isolated Environments:
Generate independent browser profiles via API, with each profile representing a fully isolated browser instance.
- Automatic Fingerprint Randomization:
Randomize key parameters such as User-Agent, timezone, language, and screen resolution—all while maintaining full consistency with real browser environments.
- Built-in CAPTCHA Handling:
Automatically recognize and solve common CAPTCHA challenges without human intervention or third-party integrations.
So, what about fingerprint browsers?
In domestic enterprise automation, locally deployed fingerprint browsers are widely used. However, they often consume large amounts of system resources, are difficult to maintain consistently across instances, and still require third-party CAPTCHA services for verification handling.
By contrast, modern cloud-based headless browsers like Scrapeless.com offer a more scalable and efficient alternative. They allow developers to:
- Create isolated browser profiles via API,
- Natively randomize fingerprints, and
- Automatically handle CAPTCHA challenges,
all in the cloud—greatly reducing development and maintenance costs while supporting high-concurrency workloads.
In the following sections, we’ll explore several benchmark scenarios to evaluate how cloud-based headless browsers perform in terms of fingerprint isolation, concurrency, and CAPTCHA handling.
⚠️ Disclaimer:
When using any browser automation solution, always comply with the target website’s Terms of Service, robots.txt rules, and relevant laws and regulations.
Data scraping for unauthorized or illegal purposes, or infringing on others’ rights, is strictly prohibited.
We assume no liability for any legal consequences or losses resulting from misuse.
Environment Setup
First, install the Scrapeless Node SDK. If you don't have Node installed, please install Node beforehand.
bash
npm install @scrapeless-ai/sdk puppeteer-coreBasic connection test
js
// set your API key
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer } from "@scrapeless-ai/sdk";
const browser = await Puppeteer.connect({
sessionName: "sdk_test",
sessionTTL: 180,
proxyCountry: "ANY",
sessionRecording: true,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto("https://www.scrapeless.com");
console.log(await page.title());
await browser.close();If the page title is printed, the environment is configured successfully.
Ready to supercharge your web automation? Try Scrapeless Cloud Browser today and experience seamless profile management, independent fingerprints, and automated CAPTCHA handling—all in the cloud!
Case 1: Random Browser Fingerprint Verification
Goal: Verify that the browser fingerprint generated by each profile is truly independent.
This example:
- Creates multiple independent profiles
- Visits the fingerprint testing site: https://xfreetool.com/zh/fingerprint-checker
- Extracts and compares the browser fingerprint ID of each profile
- Validates fingerprint independence and randomness
The site https://xfreetool.com/zh/fingerprint-checker is a website that checks browser fingerprints and automatically captures fingerprint information from the visiting browser.
Example Code:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from "@scrapeless-ai/sdk";
// Configuration constants
const MAX_PROFILES = 3; // Maximum number of profiles needed
// Initialize client
const client = new ScrapelessClient();
/**
* Get the browser fingerprint ID from the CreepJS page
* @param {Object} page - Puppeteer page object
* @returns {Promise<string>} Browser fingerprint ID
*/
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector(
'#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div'
);
return fpContainer.textContent;
});
};
/**
* Run a single task
* @param {string} profileId - Profile ID
* @param {number} taskId - Task ID
* @returns {Promise<string>} Browser fingerprint ID
*/
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'My Browser',
sessionTTL: 45000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
const page = await browser.newPage();
page.setDefaultTimeout(45000);
await page.goto('https://xfreetool.com/zh/fingerprint-checker', {
waitUntil: 'networkidle0'
});
// Retrieve and print cookie information
const cookies = await page.cookies();
console.log(`[${taskId}] Cookies:`);
cookies.forEach(cookie => {
// console.log(` Name: ${cookie.name}, Value: ${cookie.value}, Domain: ${cookie.domain}`);
});
const fpId = await getFPId(page);
console.log(`[${taskId}] ✓ Browser fingerprint ID = ${fpId}`);
return fpId;
} finally {
await browser.close();
}
};
/**
* Create a new profile
* @returns {Promise<string>} Newly created profile ID
*/
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('My Profile' + randomString());
console.log('Profile created:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('Failed to create profile:', error);
throw error;
}
};
/**
* Get or create the required list of profiles
* @param {number} count - Number of profiles needed
* @returns {Promise<string[]>} List of Profile IDs
*/
const getProfiles = async (count) => {
try {
// Get existing profiles
const response = await client.profiles.list({
page: 1,
pageSize: count
});
const profiles = response?.docs || [];
// Create new profiles if existing ones are insufficient
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate)
.fill(0)
.map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [
...profiles.map(p => p.profileId),
...newProfiles
];
}
// Return the first `count` profiles if enough exist
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('Failed to get profiles:', error);
throw error;
}
};
/**
* Run tasks concurrently
*/
const runTasks = async () => {
try {
// Get or create the required profiles
const profileIds = await getProfiles(MAX_PROFILES);
// Create tasks for each profile
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
await Promise.all(tasks);
console.log('All tasks completed successfully');
} catch (error) {
console.error('Error running tasks:', error);
}
};
// Execute tasks
await runTasks();Test Results:
- 3 profiles run concurrently, each environment is completely independent.
- The browser fingerprint ID for each profile is completely different.
Explanation of Results:
-
Fingerprint Uniqueness
3 profiles return different fingerprint IDs. Each time a profile is created, the browser fingerprint is randomly generated, avoiding detection due to duplicate fingerprints.
-
Environment Isolation Verification
Cookies for each profile are completely independent:- Cookies from Profile 1 do not appear in Profiles 2 or 3
- Multiple profiles can log into different accounts simultaneously without affecting each other
Case 2: High Concurrency & Environment Isolation Test
Goal: Verify environment isolation of profiles under high concurrency scenarios, and test the ability to batch create and manage profiles.
In many cases, to speed up data scraping or log into multiple accounts, tools need to support high concurrency and environment isolation—equivalent to having dozens or hundreds of independent browser instances simultaneously. Scrapeless supports adding profiles manually or operating profiles via API.
This example:
- Creates 10 independent profiles via API
- Each profile first visits https://abrahamjuliot.github.io/creepjs/ to get the browser fingerprint ID
- Then visits https://minecraftpocket-servers.com/login/ and takes a screenshot
- Verifies fingerprint independence and environment isolation
Example Code:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from '@scrapeless-ai/sdk';
// Configuration constants
const MAX_PROFILES = 5; // Maximum number of profiles needed
// Initialize client
const client = new ScrapelessClient({});
/**
* Get the browser fingerprint ID from the CreepJS page
* @param {Object} page - Puppeteer page object
* @returns {Promise<string>} Browser fingerprint ID
*/
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector(
'#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div'
);
return fpContainer.textContent;
});
};
/**
* Run a single task
* @param {string} profileId - Profile ID
* @param {number} taskId - Task ID
* @returns {Promise<string>} Browser fingerprint ID
*/
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'My Browser',
sessionTTL: 30000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
// Step 1: Get browser fingerprint
let page = await browser.newPage();
page.setDefaultTimeout(30000);
await page.goto('https://abrahamjuliot.github.io/creepjs/', {
waitUntil: 'networkidle0'
});
const fpId = await getFPId(page);
await page.close(); // Close the first page
// Step 2: Use a new page for screenshot
page = await browser.newPage();
const screenshotPath = `fp_${taskId}_${fpId}.png`;
await page.goto('https://minecraftpocket-servers.com/login/', {
waitUntil: 'networkidle0'
});
await page.screenshot({
fullPage: true,
path: screenshotPath
});
console.log(`[${taskId}] ✓ Fingerprint ID: ${fpId}, Screenshot saved to: ${screenshotPath}`);
return fpId;
} finally {
await browser.close();
}
};
/**
* Create a new profile
* @returns {Promise<string>} Newly created profile ID
*/
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('My Profile' + randomString());
console.log('Profile created:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('Failed to create profile:', error);
throw error;
}
};
/**
* Get or create the required list of profiles
* @param {number} count - Number of profiles needed
* @returns {Promise<string[]>} List of Profile IDs
*/
const getProfiles = async (count) => {
try {
const response = await client.profiles.list({
page: 1,
pageSize: count
});
const profiles = response?.docs || [];
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate)
.fill(0)
.map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [
...profiles.map(p => p.profileId),
...newProfiles
];
}
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('Failed to get profiles:', error);
throw error;
}
};
/**
* Run tasks concurrently
*/
const runTasks = async () => {
try {
console.log(`Starting tasks, need ${MAX_PROFILES} profiles`);
const profileIds = await getProfiles(MAX_PROFILES);
console.log(`Retrieved ${profileIds.length} profiles`);
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
const results = await Promise.all(tasks);
console.log('All tasks completed successfully!');
console.log('Fingerprint ID list:', results);
} catch (error) {
console.error('Error running tasks:', error);
}
};
// Execute tasks
await runTasks();Test Results:
- Fingerprint Independence: Fingerprints and environment parameters are randomly generated and mutually distinct.
- Environment Isolation: Each task runs in an independent profile; browser data (Cookie, LocalStorage, Session, etc.) is not shared.
- Concurrency Stability: 10 profiles successfully created and executed concurrently.
Example Result Explanation:
- Profile Creation & Connection Process
Output shows the full profile creation and browser connection process:
Profile created: a27cd6f9-7937-4af0-a0fc-51b2d5c70308
Profile created: d92b0cb1-5608-4753-92b0-b7125fb18775
...
info Puppeteer: Successfully connected to Scrapeless browser {}
...
All tasks completed successfullyAll 10 profiles are created and connected to Scrapeless Cloud Browser almost simultaneously, demonstrating stability under high concurrency.
-
Fingerprint Independence Verification
Each profile returns a completely different fingerprint ID.The 10 unique fingerprints prove that each profile’s browser fingerprint is independently and randomly generated, with no duplicates.
-
High Concurrency Execution Stability
All 10 tasks run simultaneously, successfully completing without errors or conflicts. -
Multiple Ways to Create Profiles
Scrapeless provides multiple ways to create and manage profiles:
- Dashboard Manual Creation: Create profiles directly from the Dashboard for quick start and individual operations.
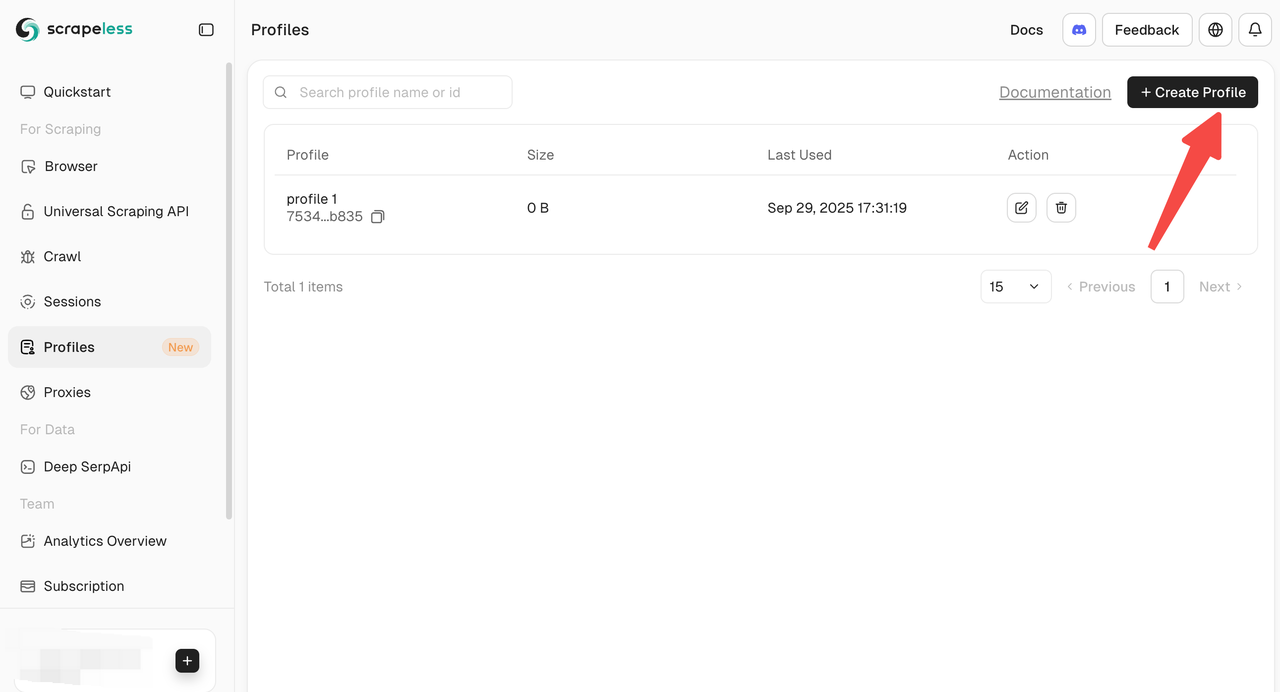
- API Creation: Create profiles programmatically via the Create Profile API for batch operations.
- SDK Creation: Use the official SDK to create profiles, ideal for high concurrency or custom automated workflows.
Case 3: Cloudflare Challenge + Google reCAPTCHA – Fully Automated CAPTCHA Bypass without Manual Intervention
Goal: Test whether Scrapeless Cloud Browser can automatically detect and pass reCAPTCHA or Cloudflare challenges when visiting sites, and record reproducible verification processes and results.
This example:
- Visits the Amazon search page https://www.amazon.com/s?k=toy (high probability of triggering reCAPTCHA)
- Automatically handles the CAPTCHA and extracts product data
- Verifies the automated CAPTCHA handling capability
Example Code:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from '@scrapeless-ai/sdk';
const client = new ScrapelessClient();
const MAX_PROFILES = 1; // Maximum number of profiles needed
// Get browser fingerprint ID from CreepJS page
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector('#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div');
return fpContainer.textContent;
});
};
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'My Browser',
sessionTTL: 45000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
let page = await browser.newPage();
page.setDefaultTimeout(45000);
await page.goto('https://www.amazon.com/s?k=toy&crid=37T7KZIWF16VC&sprefix=to%2Caps%2C351&ref=nb_sb_noss_2');
await page.waitForSelector('[role="listitem"]', { timeout: 15000 });
console.log('Page loaded successfully...');
const products = await page.evaluate(() => {
const items = [];
const productElements = document.querySelectorAll('[role="listitem"]');
productElements.forEach((product) => {
const titleElement = product.querySelector('[data-cy="title-recipe"] a h2 span');
const title = titleElement ? titleElement.textContent.trim() : 'N/A';
console.log(title);
const priceWhole = product.querySelector('.a-price-whole');
const priceFraction = product.querySelector('.a-price-fraction');
const price = priceWhole && priceFraction
? `$${priceWhole.textContent}${priceFraction.textContent}`
: 'N/A';
const ratingElement = product.querySelector('.a-icon-alt');
const rating = ratingElement ? ratingElement.textContent.split(' ')[0] : 'N/A';
const imageElement = product.querySelector('.s-image');
const imageUrl = imageElement ? imageElement.src : 'N/A';
const asin = product.getAttribute('data-asin') || 'N/A';
items.push({
title,
price,
rating,
imageUrl,
asin
});
});
return items;
});
console.log(JSON.stringify(products, null, 2));
return products;
} finally {
await browser.close();
}
};
// Create a new profile
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('My Profile' + randomString());
console.log('Profile created:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('Failed to create profile:', error);
throw error;
}
};
// Get or create required profiles
const getProfiles = async (count) => {
try {
const response = await client.profiles.list({ page: 1, pageSize: count });
const profiles = response?.docs;
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate).fill(0).map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [...profiles.map(p => p.profileId), ...newProfiles];
}
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('Failed to get profiles:', error);
throw error;
}
};
// Run tasks concurrently
const runTasks = async () => {
try {
const profileIds = await getProfiles(MAX_PROFILES);
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
await Promise.all(tasks);
console.log('All tasks completed successfully');
} catch (error) {
console.error('Error running tasks:', error);
}
};
// Execute tasks
await runTasks();Test Results:
- Amazon search page automatically handled the triggered reCAPTCHA
- Successfully extracted product title, price, rating, image, ASIN, and other data
- Entire process required no human intervention; CAPTCHA was automatically detected and passed
Example Result Explanation:
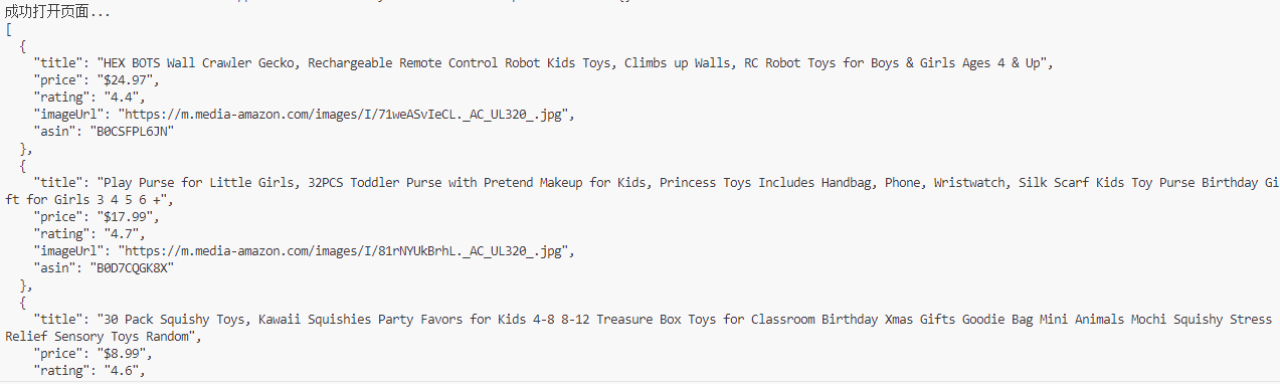
- Successful CAPTCHA Bypass & Data Extraction:
Page loads successfully, and product data is extracted:
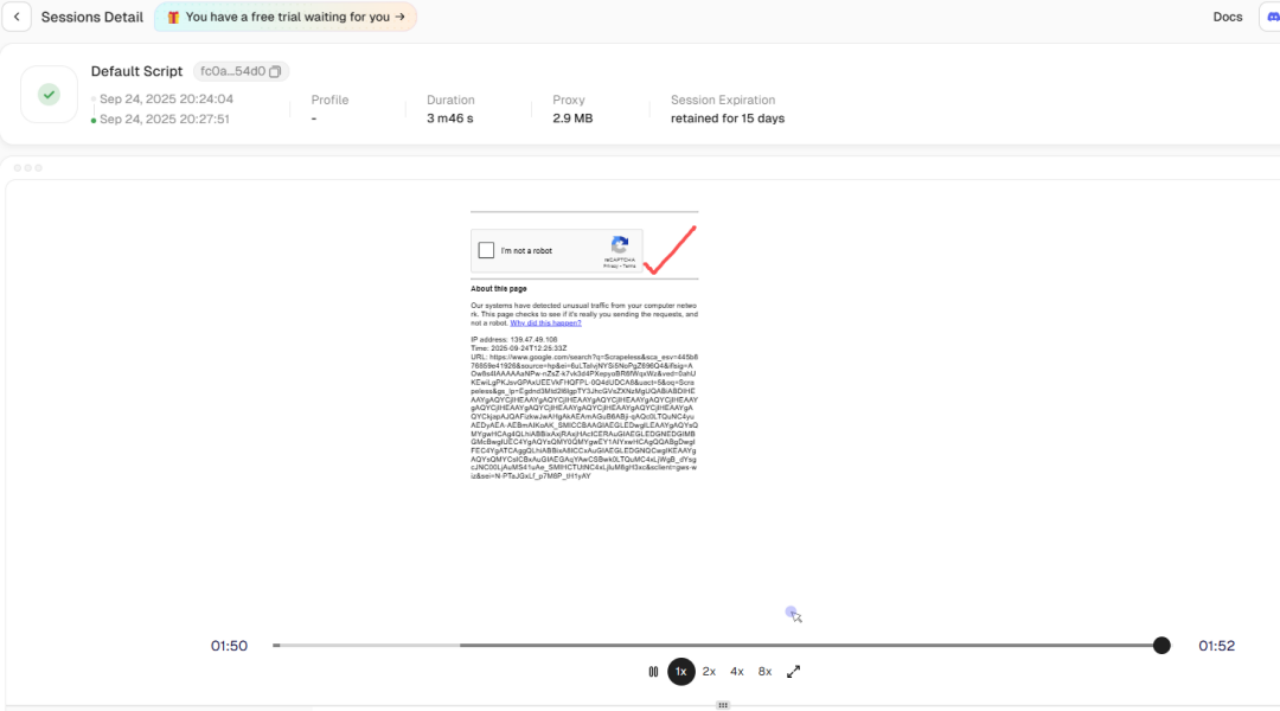
- Automated CAPTCHA Handling:
Using the Session History playback feature, you can see that risk verification was triggered during data scraping, but Scrapeless internally bypassed the reCAPTCHA automatically. This solves the obstacle of blocked data scraping in the background.
Normally, visiting Amazon search pages may trigger reCAPTCHA that requires manual interaction. With Scrapeless Cloud Browser:
- reCAPTCHA is automatically detected
- Built-in API completes verification flow automatically
- Script continues executing and extracts product data
- Cloud Observability:
Scrapeless panel provides:
- Live Sessions: Real-time monitoring of browser instances to observe script execution
- Sessions History: Replay past sessions for debugging and reviewing CAPTCHA handling
Even though the browser runs in the cloud, it provides an experience similar to local debugging, greatly reducing the difficulty of cloud browser debugging.
Summary
From the three practical scenarios, we can summarize Scrapeless Cloud Browser’s performance across key dimensions:
- Concurrency & Environment Isolation
- Supports batch creation and management of profiles
- Each profile’s fingerprint, cookies, cache, and browser data are fully isolated
- Supports 10+ concurrent tasks in the examples without conflicts or resource contention; can scale to thousands of concurrent tasks
- Equivalent to having hundreds or thousands of independent browser instances simultaneously
- Random Browser Fingerprints
- Each profile creation randomly generates core parameters such as user-agent, timezone, language, and screen resolution
- Fingerprint closely mimics real browser environments
- Reduces likelihood of being detected as automated access
- Built-in CAPTCHA Automation
- Supports automated recognition of reCAPTCHA, Cloudflare Turnstile/Challenge, and other CAPTCHA types
- Completes verification automatically without human intervention
- Cloud Browser Observability
- Live Sessions: Monitor browser execution in real time
- Sessions History: Replay past sessions for debugging and verification
For automation scenarios requiring multi-environment isolation, high concurrency, and CAPTCHA bypass, Scrapeless Cloud Browser is a strong option.
Ready to supercharge your web automation? Try Scrapeless Cloud Browser today and experience seamless profile management, independent fingerprints, and automated CAPTCHA handling—all in the cloud!
Disclaimer: Any automation tool usage should comply with target site terms of service and relevant laws. This article is for technical research and validation purposes only.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


