
8 Free No-Code Web Scrapers | Best Select 2025
Senior Web Scraping Engineer
What Are No-Code Scrapers?
No code web scraping tools, also known as managed or hosted scraping, are a web scraping method that helps you extract data from websites without having to build or maintain code infrastructure. These tools are usually built with a visual interface or a streamlined workflow that makes it easy for users to set up and execute web scraping tasks.
One of the core benefits of codeless scraping is that it significantly reduces the time and effort required to collect data from the web. You can upload your target URL, use pre-built scraping templates for popular websites or common use cases, and get data almost instantly.
These tools eliminate the need for manual coding and infrastructure management, allowing you to focus more on analyzing and gaining valuable insights from extracted data.
Scalability is another benefit that comes with codeless scraping tools. For example, using Scrapeless’s API service, you can schedule scraping tasks using cron jobs or custom intervals for greater automation and scalability.
This is especially useful if you want to continuously monitor your competitors. Yes, they may change their prices and listing keywords every day, so you should keep up with these developments to stay competitive.
Why Should We Choose No-Code Scraper?
- Visual Interface: No code web scraping tools often provide a drag-and-drop interface or point-and-click functionality, where users can select elements from a website that they want to scrape, without needing to know how to write code.
- Pre-configured Templates: Many no-code web scrapers come with pre-built templates for common web scraping tasks, making it even easier to get started.
- Automation: These tools often automate repetitive scraping tasks, so users can schedule or trigger scraping jobs without needing to manually intervene every time.
- Compatibility: No-code web scrapers can handle data from static and dynamic websites, including those that use JavaScript, by leveraging built-in browsers or cloud environments to render the pages.
- Data Export: They allow users to export scraped data in various formats, like CSV, Excel, or even API integration, making the data easily accessible for analysis or use in other systems.
- No Programming Knowledge Required: The primary benefit is that users can build complex scraping workflows without learning programming languages like Python, JavaScript, or others.
Core Evaluation Criteria for No-Code Scrapers
- Ease of Use: Is the operation intuitive and straightforward? For me, choosing a tool that is easy to get started with is a top priority. If the tool is too complex or cumbersome to operate, no matter how powerful its features are, I would feel overwhelmed. A good No Code web scraping tool should at least have a clean user interface and clear operational steps.
- Data Scraping Capability: Can it scrape complex dynamic web pages? The most important function of a No Code web Scraper is its ability to accurately and quickly scrape web data. Especially, can it handle dynamic websites and JavaScript-rendered pages? After all, many websites now load content via JavaScript, which ordinary tools often cannot process.
- Anti-Detection Capability: Can it bypass a website's anti-scraping mechanisms? When I use a No-Code web Scraper for scraping, many websites have anti-scraping measures in place (such as IP restrictions, CAPTCHAs, etc.). This often leads to blocks or CAPTCHA challenges when using some tools.
- API & Automation: Does it support integration and automated tasks? As someone who frequently needs to scrape data repeatedly, I hope my tool supports APIs, so I can automate scraping tasks and even integrate them into my existing business processes.
- Pricing and Cost-Effectiveness: Is the cost of the tool reasonable? I usually opt for tools that offer good value for money. While free tools are nice, often their features and limitations do not meet my needs. If a paid version is feature-rich and reasonably priced, it is a very worthwhile investment.
Ranking: Analysis of the 8 Best No-Code Scraper Tools
The following are the 8 best no-code web scraping tools that we have carefully selected for you. They have different functions, and you need to choose a product that suits your actual needs.
Overview Comparison
| Main Features | Paid Plan | Free Trial | Easy of Use | |
|---|---|---|---|---|
| Scrapeless | Comprehensive, stable, and highly successful | From $49 | One-month free trial for all services | ⭐⭐⭐⭐⭐ |
| ParseHub | Suitable for non-technical users | From $189 | With $99 value | ⭐⭐⭐⭐⭐ |
| Diffbot | AI web structure parsing | From $299 | Long-term with functional limitations | ⭐⭐⭐⭐ |
| Outscraper | For Google search category data | According to your needs | For the first 500 actions | ⭐⭐⭐⭐ |
| WebHarvy | Perfect for small-scale data collection tasks | From $129 | Not support | ⭐⭐⭐⭐ |
| DataMiner | Crawling structured data such as tables and lists | From $19.99 | The free plan gives 500 pages/month | ⭐⭐⭐ |
| Simplescraper | For small projects | From $39 | 100 free starter credits | ⭐⭐⭐ |
| Browse AI | Ideal for competitive analysis and price tracking | From $19 | 50 credits | ⭐⭐⭐ |
#1 Scrapeless – A comprehensive and stable no code web scraper
Scrapeless is a cloud-based web scraping tool powered by Browserless technology, designed to provide users with a stable scraping environment. It supports bypassing IP restrictions through intelligent proxies, making it especially suitable for e-commerce, news, and SEO data extraction.
For users with no programming skills or those who prefer not to spend too much time on coding, Scrapeless offers a simple API interface that can quickly integrate with internal business systems to automate data scraping tasks. Scrapeless' API fully supports JavaScript rendering through its powerful development capabilities. With just a few clicks and simple configurations, users can complete what would normally be a complex scraper setup.
Scrapeless is also set to launch an AI Agent service. Overall, it is ideal for users who need long-term, large-scale data scraping, particularly due to its superior anti-detection capabilities compared to traditional No-Code Scrapers.
How to deploy Scrapeless? Here are the most clear steps:
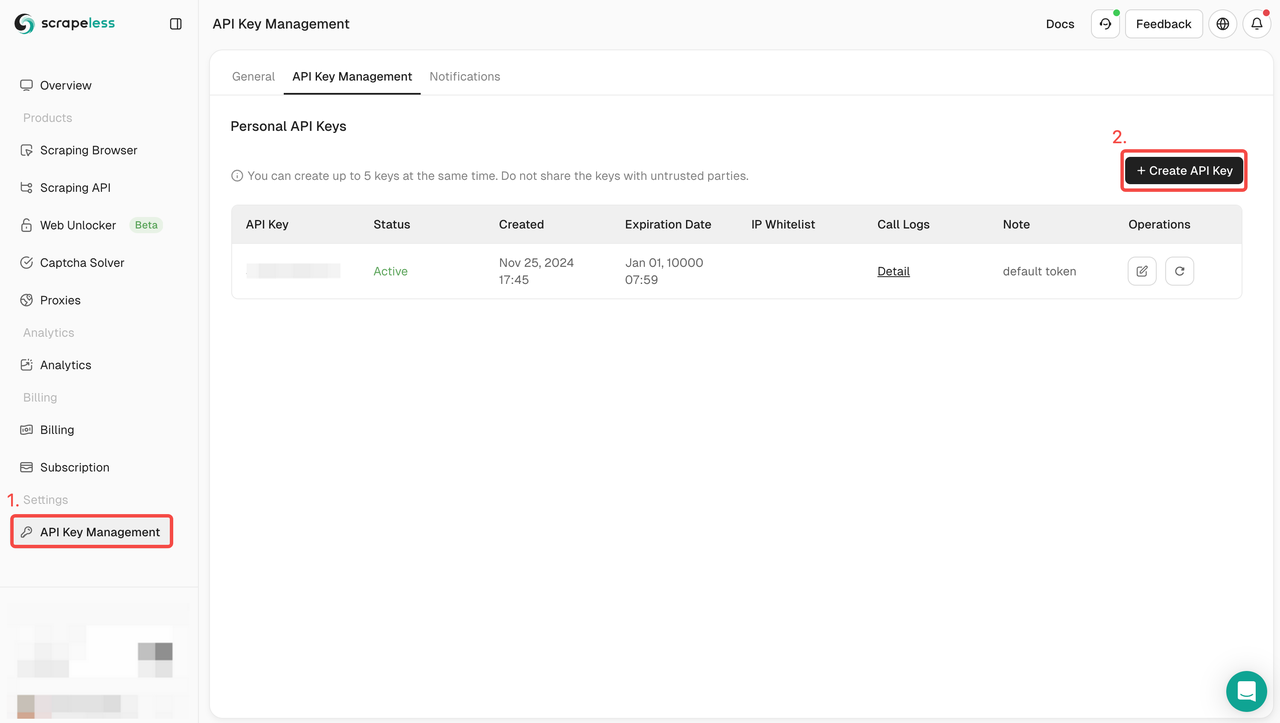
Step 1. Obtain Your API Key
To get started, you’ll need to obtain your API Key from the Scrapeless Dashboard:
- Log in to the Scrapeless Dashboard.
- Navigate to API Key Management.
- Click Create to generate your unique API Key.
- Once created, simply click on the API Key to copy it.
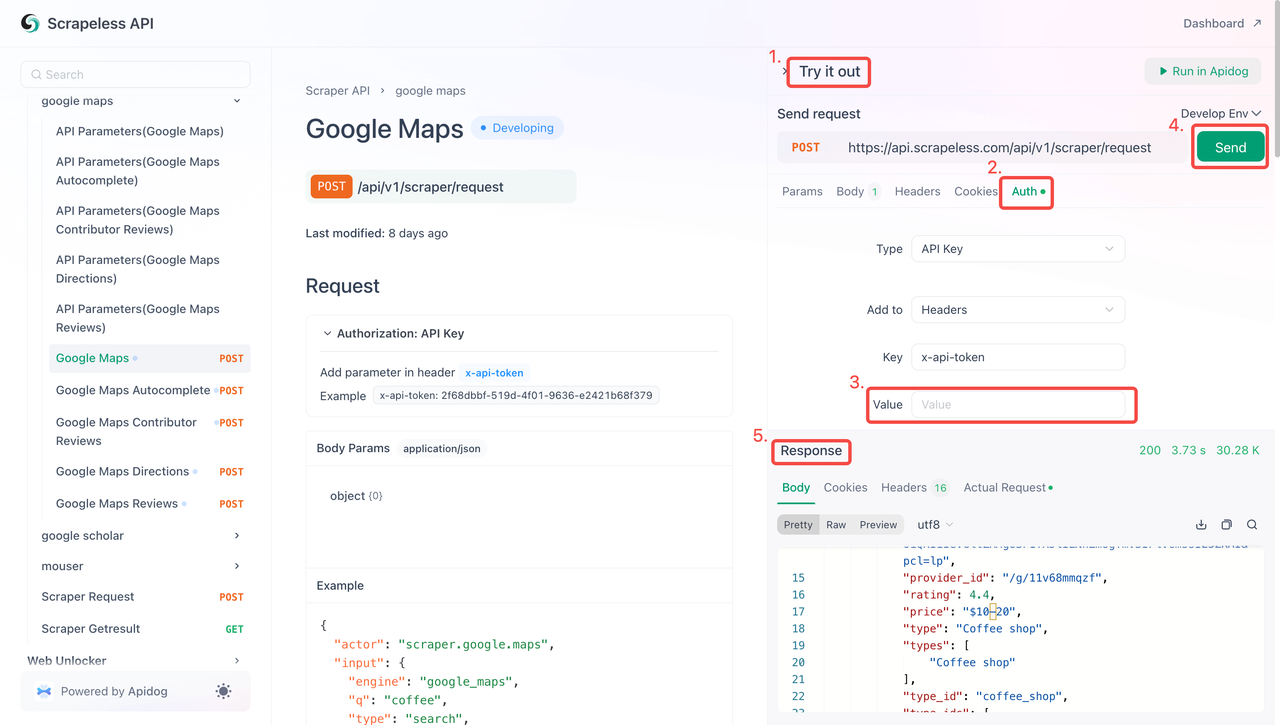
Step 2: Use Your API Key in the Code
You can now use your API Key to integrate Scrapeless into your project. Follow these steps to test and implement the API:
- Visit the API Documentation.
- Click "Try it out" for the desired endpoint.
- Enter your API Key in the "Auth" field.
- Click "Send" to get the scraping response.
Below is a sample code snippet that you can directly integrate into your Google Maps Scraper:
Python
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.maps",
"input": {
"engine": "google_maps",
"q": "coffee",
"type": "search",
"ll": "@40.7455096,-74.0083012,14z",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))JavaScript
JavaScript
var myHeaders = new Headers();
myHeaders.append("Content-Type", "application/json");
var raw = JSON.stringify({
"actor": "scraper.google.maps",
"input": {
"engine": "google_maps",
"q": "coffee",
"type": "search",
"ll": "@40.7455096,-74.0083012,14z",
"hl": "en",
"gl": "us"
}
});
var requestOptions = {
method: 'POST',
headers: myHeaders,
body: raw,
redirect: 'follow'
};
fetch("https://api.scrapeless.com/api/v1/scraper/request", requestOptions)
.then(response => response.text())
.then(result => console.log(result))
.catch(error => console.log('error', error));#2 ParseHub – A visual scraping tool for complex websites
- Main features:
✅ Visual interface, suitable for non-technical users
✅ Web scraping scheduling
ParseHub offers powerful visual data collection features, making it an excellent choice for users without programming experience. It also supports handling JavaScript-rendered websites. However, the free version has limited features, making it particularly appealing to web data enthusiasts who want to try web scraping without fully committing.
#3 Diffbot – AI web structure parsing, ideal for news and article scraping
- Main features:
✅ AI content recognition, no need to manually set rules
✅ Suitable for unstructured data, such as articles, comments, etc.
Diffbot is a tool that uses AI technology to parse web structures, making it especially suitable for extracting data from unstructured content such as news websites and blogs. With its powerful AI model, users can easily extract the required information without having to manually set scraping rules.
#4 Outscraper – Ideal for Google Search and Maps data scraping
- Main features:
✅ Specifically designed for Google data, excellent scraping performance
✅ Provides API support for automated data collection
✅ Can extract data from Google Maps and Search results
Outscraper focuses on scraping Google-related data, such as Google Maps and Google Search results, making it highly suitable for local business data analysis. Through its API, users can quickly integrate and automate their data collection tasks.
#5 WebHarvy – Windows Desktop Web Scraping Tool
- Main features:
✅ User-friendly interface, ideal for small-scale data scraping tasks
✅ Lifetime use after purchase
WebHarvy is a Windows desktop-based visual scraper, perfect for small-scale data collection tasks. Its user-friendly interface is designed for non-technical users, allowing them to easily set scraping rules through a graphical interface.
#6 DataMiner – Lightweight Chrome extension for small crawlers
- Main features:
✅ Ready to use after installation, low threshold
✅ Suitable for crawling structured data such as tables and lists
DataMiner is a lightweight Chrome extension suitable for small-scale data scraping tasks. It is easy to install and use, making it ideal for extracting structured data such as tables and lists.
#7 Simplescraper – API-friendly lightweight scraping tool
- Main features:
✅ Quick API access, supports automated scraping
✅ Easy to use, suitable for non-technical users
✅ Ideal for small projects with stable API performance
Simplescraper offers a user-friendly API, perfect for users of small to medium-sized projects, enabling rapid web data scraping and automated processing. It is well-suited for developers looking to integrate scraping workflows into their existing systems.
#8 Browse AI – Designed for monitoring website changes
- Main features:
✅ Automatically tracks changes in web data
✅ Ideal for competitive analysis and price tracking
✅ Features a visual setup interface
Browse AI specializes in monitoring changes in website data, making it suitable for regular tasks such as price tracking and market surveillance. It can automatically monitor updates on specified web pages, catering to competitive analysis and SEO data monitoring needs.
Conclusion
No-code web scrapers bridge the gap between data collection and non-technical teams, but they can also benefit technical teams by allowing them to quickly collect data without having to develop complex infrastructure from scratch.
Navigating public web data collection can be a tricky task. However, with the above-mentioned 8 great no-code web scraping tools, non-programmers can now easily take advantage of web scraping. All that’s left to do is to choose the tool that meets your project requirements.
Want to know more about website scraping and automation tools? Read on for more effective solutions!
FAQs
1. Is it legal to use no-code scrapers?
Generally, scraping publicly available data is legal. However, scraping personal data, intellectual property, or data behind a login can raise legal concerns.
2. How does a no-code scraper work?
No-code scrapers provide a user-friendly interface that allows users to extract data from websites without writing code. Users can select elements on a webpage to define the data to be extracted. The tool then automates the process of navigating the website, extracting the specified data, and exporting it in a structured format like CSV or JSON.
3. Can I use no-code scrapers to scrape data from any website?
While no-code scrapers can be used on many websites, it's crucial to ensure that your scraping activities comply with the website's terms of service and applicable laws.
4. Is the data obtained by no-code scrapers reliable?
Yes. Let's take Scrapeless as an example. Scrapeless guarantees a 99% success rate and reliability. The stability and accuracy of Google Trends scraping has reached nearly 100%!
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


