
Scrapeless Fully Integrates Google AI Overviews, AI Mode, and Gemini: The Ultimate Data Optimization Framework for the GEO Era
Expert Network Defense Engineer
From Google AI Overviews to Gemini 3, from AI Mode’s reasoning chains to structured data extraction—Scrapeless delivers a fully integrated scraping and analysis system that reveals how AI Search truly works in 2026 and shows you where the real opportunities lie.
Introduction: The Massive Shift in Search Traffic Allocation
Since early 2025, Google has dramatically accelerated the convergence of Search and AI.
With the rollout of AI Mode, the expanded coverage of AI Overviews, and the deeper integration of Gemini 2.5 Pro into the search pipeline, Google has built the technical foundation for GEO 2.0.
By November 2025, the release of Gemini 3 marked a major inflection point—one that fundamentally reshapes how search traffic is distributed.
This is not a simple product upgrade.
It is a paradigm shift in how search visibility and traffic are allocated.
The Old World (SEO): Ranking #1 = Most Traffic
Google Search used to be a static leaderboard.
Everyone saw the same blue links, and ranking determined everything.
But that era is over.
The GEO Era Is Different
GEO (Generative Engine Optimization) changes the rules entirely:
Traffic is no longer determined by rankings.
It is determined by how AI models interpret, select, and cite your content.
AI summaries, deep search modes, and generative LLMs now choose which pages to reference, combine, and present.
Your traffic now depends on:
- Whether AI can see your content
- Whether AI can understand your content
- Whether AI decides to cite your content
- Whether your content fits the model’s preferred structures and reasoning chains
For example, searching for “best xxxx tools” may now surface three parallel AI-driven channels:
1. Google AI Overviews
A synthesized top-of-SERP AI answer citing 3–5 external websites.
2. Google AI Mode
A full-page generative answer with:
- step-by-step reasoning chains
- reference sources
- expanded sub-questions
3. Gemini App Search
A more personalized, structured response using Gemini’s multimodal reasoning.
These three channels coexist—but each uses different rules for content selection:
| Channel | What Determines Whether You’re Cited |
|---|---|
| AI Overviews | Clarity, structure, factual density, extractability |
| AI Mode | Coverage of expanded sub-questions; depth & evidence |
| Gemini Search | Authority, reasoning consistency, structured data |
This is the harsh reality of the GEO era.
And everything is evolving quarter by quarter.
Gemini 3 has already surpassed GPT-5 Pro in core benchmarks just days after launch.
With 650M monthly Gemini users and the world’s largest search index, every Google update reshapes the entire AI search ecosystem.
❓So How Do You Understand and Optimize for These Three Channels?
The answer—and the purpose of this article—is clear:
Use Scrapeless Browser to unlock Google’s entire AI Search pipeline.
Part 1: The Core Logic of GEO
From “Rank #1” → “Be Structured, Understandable, and AI-Citable”
Traditional SEO was 1-dimensional:
Higher ranking → more traffic.
GEO is multi-dimensional.
With Gemini 3, AI Mode, and AI Overviews running simultaneously, you are competing across three evolving dimensions:
Dimension 1: Gemini 3’s Deep Reasoning Ability
Gemini 3 scores 37.4 on the Humanity’s Last Exam benchmark—beating GPT-5 Pro.
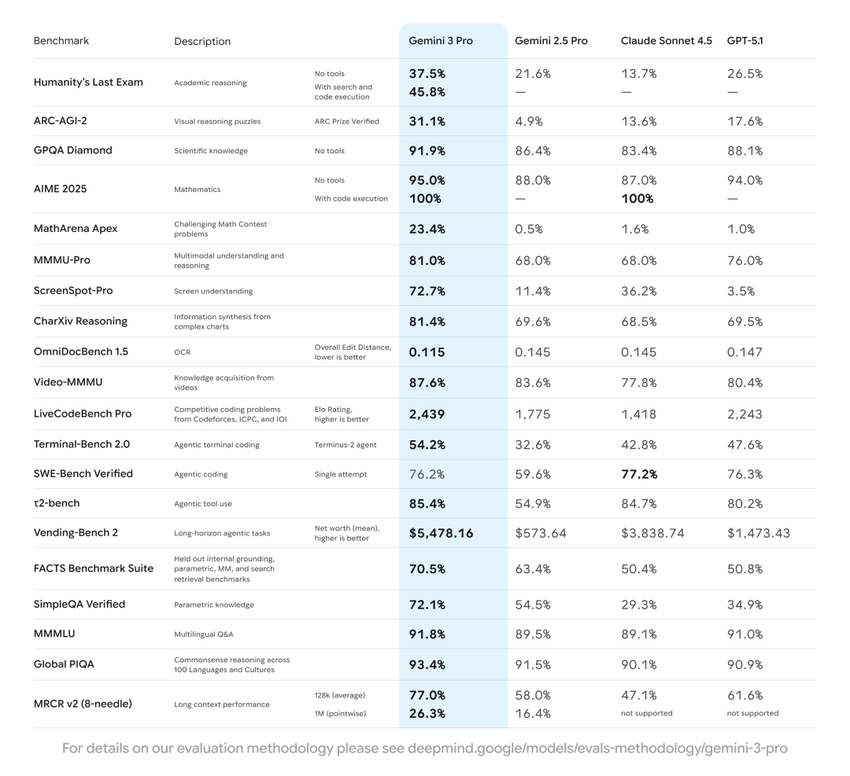
It introduces:
- explicit chain-of-thought reasoning
- self-critique
- evidence-weighted answer scoring
This means Gemini constantly asks:
“Is this answer supported by enough evidence?”
To be selected, your content must:
- answer surface and implicit sub-questions
- provide data and factual grounding
- include examples and validation
- maintain internal logical consistency
And more importantly:
Gemini prefers memorized, high-authority content from its internal knowledge.
It only performs live internet searches when needed.
Long-term GEO strategy is clear:
Make your content authoritative enough to enter the training data of the next-generation models.
Dimension 2: AI Mode’s Automatic Query Expansion
When a user asks one question, AI Mode automatically generates:
➡️ 8–12 sub-questions
➡️ Searches each independently
➡️ Selects different websites for each answer
Ranking #1 does not guarantee citation, because your competitor—ranked #5—may perfectly fit a sub-question.

This leads to a bold conclusion:
Don’t write one 5,000-word “ultimate guide.”
Write ten 500-word deep-dive answers, each targeting one atomic question.
Dimension 3: The Extractability Rules of AI Overviews
AI Overviews aims to produce a fast, accurate summary.
To be cited, your content must offer:
✔️ Clear structure
Headers, subheaders, and self-contained paragraphs.
✔️ Fact-based statements
Tables, numbers, step-by-step logic.
✔️ Extractable sentences
Short, precise, logically complete statements.
✔️ Comprehensive coverage
So AI can pull multiple fragments from your page.
Being cited does not always mean clicks—but it does deliver:
- Brand visibility
- Model-level authority gain
- Higher long-term citation probability
- Referral traffic when users check the cited sources
In one line:
AI Overviews is not a ranking competition—it is an extractability competition.
Part 2: Why Scrapeless Browser Is Essential for GEO Data Collection
The Root Problem: The Three Major Failures of Traditional Crawlers
Many people ask:
“Why not just use Puppeteer or Selenium to connect to a browser and scrape directly?”
The answer lies in three structural problems that traditional crawlers can no longer handle in the GEO era.
Challenge 1: IP Detection and Rapid Blocking
In mid-September 2025, Google quietly removed a parameter that had existed for nearly 20 years: num=100.
This wasn’t just a parameter removal—it marked a major upgrade in Google’s anti-bot architecture.
When you send a large number of search requests through a traditional crawler, Google will instantly:
- Identify your IP
- Trigger reCAPTCHA v3
- If you continue, block your IP for 24–72 hours
What does this mean in practice?
If you need to track 100 keywords in Google AI Overviews, a traditional crawler might require 20–30 rotating proxy IPs, still with a high chance of detection.
Google’s detection system has evolved far beyond IP checks. It now evaluates:
- Request timing patterns (too regular = bot)
- Browser fingerprints (is this a real browser?)
- Interaction patterns (mouse movement, click delay, dwell time)
- Cross-domain continuity (does this look like a human search session?)
Traditional crawlers simply cannot simulate these behaviors reliably.
Challenge 2: Incomplete JavaScript Rendering
Google AI Overviews, AI Mode, and Gemini all generate their answers dynamically.
This content is not present in the initial HTML. It is built through multiple layers of JavaScript rendering.
If you simply run:
js
await page.goto(url);and scrape immediately, you will often see:
- AI answer container exists, but content is empty
- Citation lists have not loaded yet
- Reasoning steps in AI Mode are missing
Why?
Because Google uses a multi-step asynchronous rendering pipeline:
- Load structural framework
- Trigger inference
- Render answer
- Render citations
- Render interactive elements
Unless your browser correctly waits for each stage, your output will be incomplete.
Challenge 3: Obtaining Stable and Reproducible Data
In AI Mode and Gemini, personalized context dramatically influences results.
Google personalizes answers based on:
- Search history
- Geographic location
- Device attributes
- Gmail / YouTube activity
- Prior interaction patterns
Example:
User A (fitness enthusiast) searches “quick healthy breakfast”
→ AI Mode suggests high-protein meal plans
User B (baking hobbyist) searches the same term
→ AI Mode suggests bread recipes
If you scrape using a real user account, your results become deeply tied to that user’s history.
This destroys reproducibility, which is critical for GEO analytics.
Scrapeless Browser solves this with:
- Ghost-user simulation (no history, no preferences, no login data)
- Clean, isolated environments for each session
- Consistent, reproducible output across all runs
This eliminates personalization noise and ensures the data is reliable for analysis.
Scrapeless Browser: The Purpose-Built Solution for GEO Data Collection
Scrapeless Browser is specifically engineered to overcome all three challenges above.
Solution 1: Cloud Browsers + Intelligent Proxy Rotation
Scrapeless provides not just IPs, but full cloud browser instances.
Each instance includes:
- An isolated browser process
- Dedicated browser profiles
- Global IP pools (195+ countries)
- Realistic network latency and human-like interaction patterns
- Fingerprint customization (randomized or fully controlled)
From Google’s perspective, every request looks like a different real human, with:
- A different location
- A different device
- A different browser
- Natural browsing behavior
Examples:
js
// Request 1: Chrome user in Tokyo
wss://browser.scrapeless.com/api/v2/browser?proxyCountry=JP&sessionName=User_Tokyo_001
// Request 2: Safari user in Singapore
wss://browser.scrapeless.com/api/v2/browser?proxyCountry=SG&sessionName=User_Singapore_001
// Request 3: Edge user in London
wss://browser.scrapeless.com/api/v2/browser?proxyCountry=GB&sessionName=User_London_001This is simply impossible for traditional crawlers.
Solution 2: A Full, Real JavaScript Execution Environment
Scrapeless does not fetch static HTML.
It loads the page as a real browser, executing all JavaScript required to fully generate:
- AI answers
- Citations
- Reasoning chains
- Dynamic UI blocks
- Any DOM components built after page load
Example:
js
const geminiInput = await page.waitForSelector('div[role="textbox"]');
await geminiInput.type('best shopee scraper tool');
await geminiInput.press('Enter');
// Wait for AI answer to finish generating
await new Promise(resolve => setTimeout(resolve, 10000));Core Advantages
- Captures all dynamic AI content—not just initial DOM
- Mirrors human-visible results perfectly
- Guarantees full, complete answer extraction
Solution 3: Session Management and Reproducibility
The greatest advantage of Scrapeless Browser is its session architecture.
Scrapeless offers:
-
Persistent sessions (sessionTTL):
Keep cookies, localStorage, and environment state consistent. -
Ghost-user environments:
No search history, no logged-in context, no personalization.
This ensures:
- Stable results
- Reproducible data
- No personalization bias
- Clean environments suitable for GEO benchmarking
Part 3: Full-Code Integration — Using Scrapeless to Extract Data from All Three Google Platforms
Platform 1: Monitoring Google AI Overviews
Google AI Overviews appears at the top of the search results page as an AI-generated summary.
Monitoring this allows you to understand:
- Which websites Google is citing
- How those websites structure their content
- What type of information the AI considers “high-quality”
Full Code Example
js
const puppeteer = require('puppeteer-core');
async function scrapeWithGoogle() {
const query = new URLSearchParams({
sessionTTL: 900,
sessionRecording: "true",
sessionName: "AskGemini",
proxyCountry: 'US',
token: "SCAPELESS API KEY",
});
const browserWSEndpoint = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`;
console.log('browserWSEndpoint: ', browserWSEndpoint);
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto("https://google.com");
// Accept cookies
const dialogButtons = await page.$$('[role="dialog"] div > button > div[role="none"]');
const agentButton = dialogButtons?.length ? dialogButtons[dialogButtons.length - 1] : null;
if (agentButton) {
await agentButton.click();
await new Promise((resolve) => setTimeout(resolve, 1500));
}
await page.waitForSelector("textarea");
await page.type("textarea", "best shopee scraper tool");
await page.keyboard.press("Enter");
// Wait for AI Overview to load
await new Promise((resolve) => setTimeout(resolve, 5000));
// Save output as screenshot
await page.screenshot({ path: 'result.png', fullPage: true });
} catch (err) {
console.error(err);
}
}
scrapeWithGoogle().then();Platform 2: Tracking Reasoning Chains in Google AI Mode
Google AI Mode is Google’s newest deep-search mode. It generates detailed reasoning, structured answers, and visible reference sources.
Monitoring AI Mode helps you:
- Understand the AI’s composite answer
- See which pages the model cites
- Trace the AI’s reasoning steps and information hierarchy
Full Code Example
js
const puppeteer = require('puppeteer-core');
async function scrapeGemini() {
const query = new URLSearchParams({
sessionTTL: 900,
sessionRecording: "true",
sessionName: "GoogleAI",
proxyCountry: 'US',
token: "SCRAPELESS API KEY",
});
const browserWSEndpoint = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`;
console.log('browserWSEndpoint: ', browserWSEndpoint);
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto('https://google.com/ai', { waitUntil: "domcontentloaded" });
// Input query
const textArea = await page.waitForSelector('textarea[placeholder="Ask anything"]');
await textArea.type('best shopee scraper tool');
await textArea.press('Enter');
// Wait for reasoning + answers
await new Promise((resolve) => setTimeout(resolve, 10000));
await page.screenshot({ path: 'result.png', fullPage: true });
await browser.disconnect();
} catch (err) {
console.error(err);
}
}
scrapeGemini().then();Platform 3: Monitoring Gemini (Google’s Most Powerful LLM)
Gemini is Google’s top-tier LLM, featuring advanced reasoning and strict citation selection.
Monitoring Gemini helps you:
- See how your queries perform under a high-reasoning model
- Observe how the model generates answers
- Identify which sources Gemini trusts and cites
Full Code Example
js
const puppeteer = require('puppeteer-core');
async function scrapeGemini() {
const query = new URLSearchParams({
sessionTTL: 900,
sessionRecording: "true",
sessionName: "AskGemini",
proxyCountry: 'US',
token: "SCRAPELESS API KEY", // XiaoLu
});
const browserWSEndpoint = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`;
console.log('browserWSEndpoint: ', browserWSEndpoint);
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto('https://gemini.google.com/app', { timeout: 60000 });
// Input query in Gemini
const geminiInput = await page.waitForSelector('div[role="textbox"]');
await geminiInput.type('best shopee scraper tool');
await geminiInput.press('Enter');
// Wait for Gemini's answer generation
await new Promise((resolve) => setTimeout(resolve, 10000));
await page.screenshot({ path: 'result.png', fullPage: true });
await browser.disconnect();
} catch (err) {
console.error(err);
}
}
scrapeGemini().then();Part 4: From Data to Action — How to Use These Insights to Improve Your Rankings
Now you have detailed data from all three platforms.
The key question becomes: How do you use this data to actually improve your product or content ranking?
Use Case 1: Identify Missing “Sub-Question Coverage”
Data Source:
Google AI Mode’s referenced sites and generated sub-questions
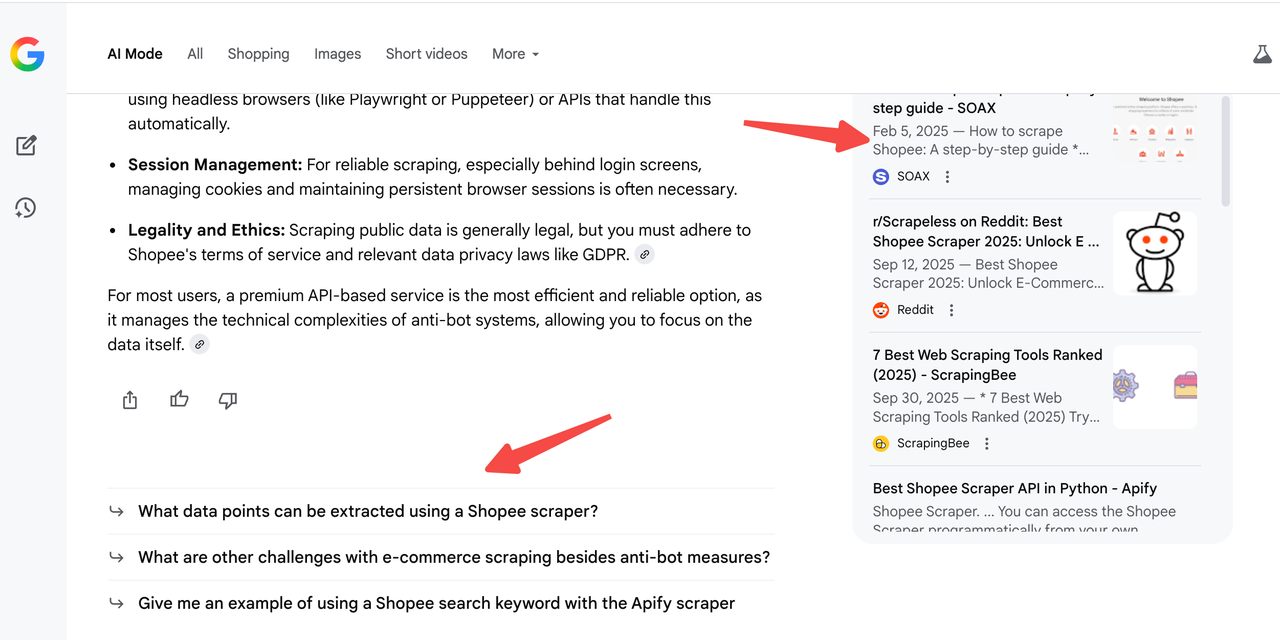
When you run the AI Mode scraper, you will receive a complete list of sub-questions.
For example, if you query “best shopee scraper tool”, AI Mode may generate 10 sub-questions on the right panel—yet your website may only cover 3 of them.
Action Plan
- Create a 500–800 word dedicated article for each missing sub-question.
- Use the sub-question itself directly as the article title—do not rephrase or simplify.
- Start the article with an H1 tag that answers the sub-question immediately, followed by additional details.
Use Case 2: Learn From Competitors With the Most AI Citations
Data Source:
Referenced sites extracted from all three platforms
If you notice a competitor being cited 7 times across 10 sub-questions while you’re cited only 2 times, it means their content structure aligns better with AI expectations.
Action Plan
-
Visit the exact competitor pages being cited.
-
Analyze the common structure across those pages:
- Do they use clear subheadings?
- Do they include comparison tables?
- Do they provide real examples or data?
- What is the typical paragraph length?
-
Rewrite or update your content following those structural patterns.
Use Case 3: Track Knowledge Updates Inside the Gemini Model
Data Source:
Gemini’s answers and citation patterns
Gemini updates monthly. Some topics shift from "requires live search" to "the model already knows the answer."
This reveals what information has likely entered the model’s training set.
Action Plan
-
Run a monthly monitoring session and document how Gemini’s answers change for your core topics.
-
When a question becomes something the model “already answers well,” do not abandon the topic. Instead, upgrade your content:
- Add 2025-level updated information (e.g., “tools launched at the end of 2024”).
- Add real user cases—the model can’t scrape these.
- Compare with new competitors the model may not know about yet.
Use Case 4: Detect Shifts in User Interest
Data Source:
Keywords and question breakdowns from Google AI Mode + Gemini
AI-generated answers reflect aggregated user behavior—the sub-questions and answer paragraphs reveal which pain points users care about the most.
Action Plan
- Compare AI answers over time and track the most frequent keywords and sub-questions.
- Update your content and push high-interest topics to the top of the page.
- Use FAQ blocks, H2/H3 headings, and schema markup to increase alignment with search and AI citation patterns.
Conclusion
In the generative search era, the old SEO mindset of “rankings first” is being replaced.
The real competition is no longer about who ranks higher on a traditional SERP—
it’s about whose content AI chooses, trusts, and cites in the answer itself.
Scrapeless gives companies complete visibility into AI decision-making and turns those insights into an actionable GEO strategy.
Why Scrapeless Is the Core Engine for GEO
Scrapeless Browser provides unmatched advantages:
- Global Proxy Network: 195+ countries to capture market-specific AI results
- Human-like Simulation: Automatically handles anti-bot systems, browser fingerprints, CAPTCHA
- Complete Data Extraction: AI answers, citations, HTML structure, and more
- Zero Maintenance Cloud Environment: No local browser or server required—cuts operational costs by 95%
- Full GEO Tool Suite: AI citation monitoring, structured content analysis, global data capture
Generative Engine Optimization is no longer optional—it is the foundation of enterprise content competitiveness.
If you want to win strategic visibility in the AI search era, Scrapeless provides the most complete GEO data solution available.
Scrapeless offers not only browser-based GEO automation, but also more advanced tools and data strategies to help you fully understand and influence AI citation mechanisms.
We have also launched full LLM API access (ChatGPT, Perplexity, Gemini, and more).
If you're interested, contact us to receive free trial access.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


