
How to Bypass Cloudflare Challenge in 2025: Full Guide
Advanced Data Extraction Specialist
Cloudflare is constantly evolving its security measures, making it increasingly difficult for traditional scraping methods to bypass challenges like cloudflare-challenge and Cloudflare Turnstile. Open-source tools such as FlareSolverr have become ineffective due to Cloudflare’s updates, leaving developers searching for new solutions.
In this guide, we will explore the most effective methods in 2025 to bypass Cloudflare security challenges, including:
- Scrapeless Scraping Browser – A headless browser API for seamless scraping
- Scrapeless Web Unlocker – A robust API for JS rendering and interaction
Whether you're a web automation expert or a beginner, this guide provides step-by-step solutions to help you extract data without hitting roadblocks.
PART1: Understanding Cloudflare Challenges and Security Layers
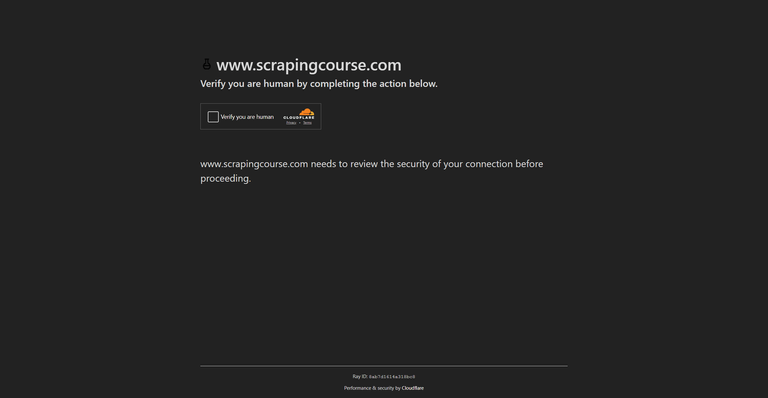
Before diving into solutions, it’s essential to understand Cloudflare’s key security mechanisms that block automated requests:
1. Cloudflare JS Challenge
The Cloudflare JavaScript challenge (cloudflare-challenge) requires browsers to execute a script before accessing the requested page. This script generates a clearance token stored in cookies (cf_clearance). Bots and scrapers without JavaScript execution capabilities fail this challenge.
2. Cloudflare Turnstile
Turnstile is Cloudflare’s CAPTCHA alternative, dynamically detecting non-human traffic. It often requires JavaScript execution and behavioral tracking to complete.
3. Browser Fingerprinting
Cloudflare uses advanced fingerprinting to detect non-human interactions. This includes analyzing:
- TLS fingerprinting (JA3 signatures)
- HTTP headers and order
- WebGL, Canvas, and Audio Fingerprinting
4. Rate Limiting and IP Bans
Even if you bypass the challenge once, repeated requests from the same IP can trigger bans or increased security levels.
PART2: How Is Cloudflare JS Challenge Different Than Other Challenges?
Unlike CAPTCHA, which requires user interaction, the JS Challenge runs automatically in the background, making it less intrusive for legitimate users while still blocking suspicious traffic. However, for web scrapers and automation tools, bypassing the JS Challenge can be challenging since many basic HTTP clients and headless browsers cannot execute JavaScript correctly.
PART3: Bypassing Cloudflare JS Challenge with Scrapeless Scraping Browser
3.1 What is Scrapeless Scraping Browser?
Scrapeless Scraping Browser is a high-performance solution that provides a headless browser environment, allowing you to bypass JavaScript challenges without maintaining your own infrastructure. It integrates with Puppeteer and Playwright for seamless automation.
Scrapeless Scraping Browser is the most advanced Cloudflare bypass tool, it provides:
✔️ 99.9% success rate to bypass Cloudflare challenge
✔️ Seamless compatibility with Puppeteer / Playwright
✔️ AI-driven, automatically adapt to the latest security policies
✔️ Global proxy support, reduce the risk of ban
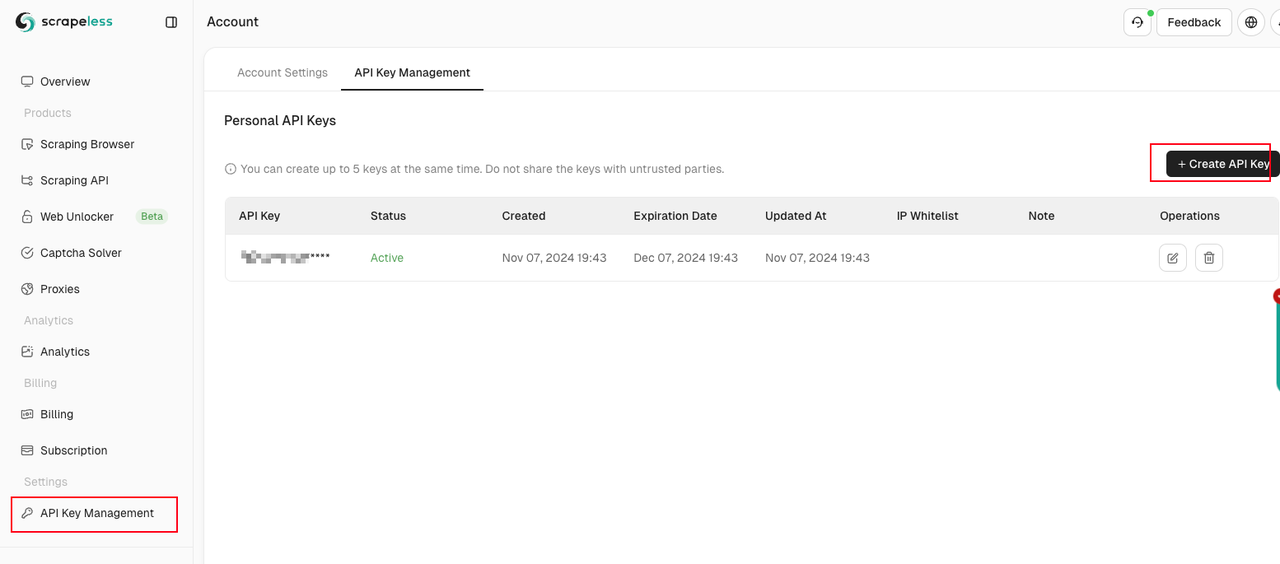
3.2 Setup & API Key Configuration
Before using Scrapeless Scraping Browser, obtain an API key:
- Sign up on the Scrapeless dashboard
- Retrieve your API key from the settings tab
🎁 Get 10,000 API requests for free for new users! Sign up now
3.3 Implementing Cloudflare Bypass with Scrapeless Browser
When we connect to a browser to access a target website, Scrapeless automatically detects and solves CAPTCHAs. However, we need to ensure that the CAPTCHA has been successfully solved. How can we achieve this? Good news! The Scrapeless Scraping Browser extends the standard CDP (Chrome DevTools Protocol) with a set of powerful custom functions.
You can directly observe the status of the CAPTCHA solver by checking the results returned from the CDP API:
Captcha.detected: CAPTCHA detectedCaptcha.solveFinished: CAPTCHA solved successfullyCaptcha.solveFailed: CAPTCHA solving failed
Rather than saying more, let’s dive straight into an example code snippet:
JavaScript
import puppeteer from "puppeteer-core";
import EventEmitter from 'events';
const emitter = new EventEmitter()
const scrapelessUrl = 'wss://browser.scrapeless.com/browser?token=your_api_key&session_ttl=180&proxy_country=ANY';
export async function example(url) {
const browser = await puppeteer.connect({
browserWSEndpoint: scrapelessUrl,
defaultViewport: null
});
console.log("Verbonden met Scrapeless browser");
try {
const page = await browser.newPage();
// Listen for captcha events
console.debug("addCaptchaListener: Start listening for captcha events");
await addCaptchaListener(page);
console.log("Navigated to URL:", url);
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 30000 });
console.log("onCaptchaFinished: Waiting for captcha solving to finish...");
await onCaptchaFinished()
// Screenshot for debugging
console.debug("Taking screenshot of the final page...");
await page.screenshot({ path: 'screenshot.png', fullPage: true });
} catch (error) {
console.error(error);
} finally {
await browser.close();
console.log("Browser closed");
}
}
async function addCaptchaListener(page) {
const client = await page.createCDPSession();
client.on("Captcha.detected", (msg) => {
console.debug("Captcha.detected: ", msg);
});
client.on("Captcha.solveFinished", async (msg) => {
console.debug("Captcha.solveFinished: ", msg);
emitter.emit("Captcha.solveFinished", msg);
client.removeAllListeners()
});
}
async function onCaptchaFinished(timeout = 60_000) {
return Promise.race([
new Promise((resolve) => {
emitter.on("Captcha.solveFinished", (msg) => {
resolve(msg);
});
}),
new Promise((_, reject) => setTimeout(() => reject('Timeout'), timeout))
])
}This example workflow visits the target website and confirms that the CAPTCHA was solved successfully by listening to the Captcha.solveFinished CDP event. Finally, it captures a screenshot of the page for verification.
This example defines two main methods:
addCaptchaListener: for listening to CAPTCHA events within the browser sessiononCaptchaFinished: for waiting until the CAPTCHA has been solved
The sample code above can be used to listen to CDP events for the three common CAPTCHA types discussed in this article: reCAPTCHA v2, Cloudflare Turnstile, and Cloudflare 5s Challenge.
Find more details on the document!
It is important to note that the Cloudflare 5s Challenge is a bit special. Sometimes, it doesn’t trigger an actual challenge, and relying solely on CDP event detection for success may result in a timeout. Therefore, waiting for the appearance of specific elements on the page after the challenge is a more stable solution.
So, be sure to read on!
Connecting to Scrapeless Browserless WebSocket
Scrapeless provides a WebSocket connection that allows Puppeteer to interact directly with a headless browser, thus bypassing the Cloudflare challenge.
👉 Full WebSocket connection address:
wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANYCode Sample: Bypassing the Cloudflare Challenge
We only need to prepare the following code to connect to Scrapeless's browserless service.
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180', // The life cycle of a browser session, in seconds
proxy_country: 'GB', // Agent country
proxy_session_id: 'test_session_id', // The proxy session id is used to keep the proxy ip unchanged. The session time is 3 minutes by default, based on the proxy_session_duration setting.
proxy_session_duration: '5' // Agent session time, unit minutes
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Connected!')📢 Try Scrapeless for free today and easily bypass Cloudflare! 👉 Sign up now
Visit a Cloudflare-protected website & screenshot verification
Next, we use scrapeless browserless to directly access the cloudflare-challenge test site and add a screenshot, which allows us to see the effect very intuitively. Before taking the screenshot, please note that you need to use waitForSelector to wait for elements on the page, ensuring that the Cloudflare challenge has been successfully bypassed.
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {waitUntil: 'domcontentloaded'});
// By waiting for elements in the site page, ensuring that the Cloudflare challenge has been successfully bypassed.
await page.waitForSelector('main.page-content .challenge-info', {timeout: 30 * 1000})
await page.screenshot({path: 'challenge-bypass.png'});Congratulations! 🎉 you bypassed cloudflare challenge with the scrapeless browserless.

Retrieving the cf_clearanceCookie and Headers
In addition, after passing the Cloudflare challenge, you can also retrieve the request headers and the cf_clearance cookie from the success page.
const cookies = await browser.cookies()
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.valueTurn on request interception to capture request headers,match page requests after cloudflare challenge.
await page.setRequestInterception(true);
page.on('request', request => {
// Match page requests after cloudflare challenge
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});PART4: Bypassing Cloudflare Turnstile with Scrapeless Scraping Browser
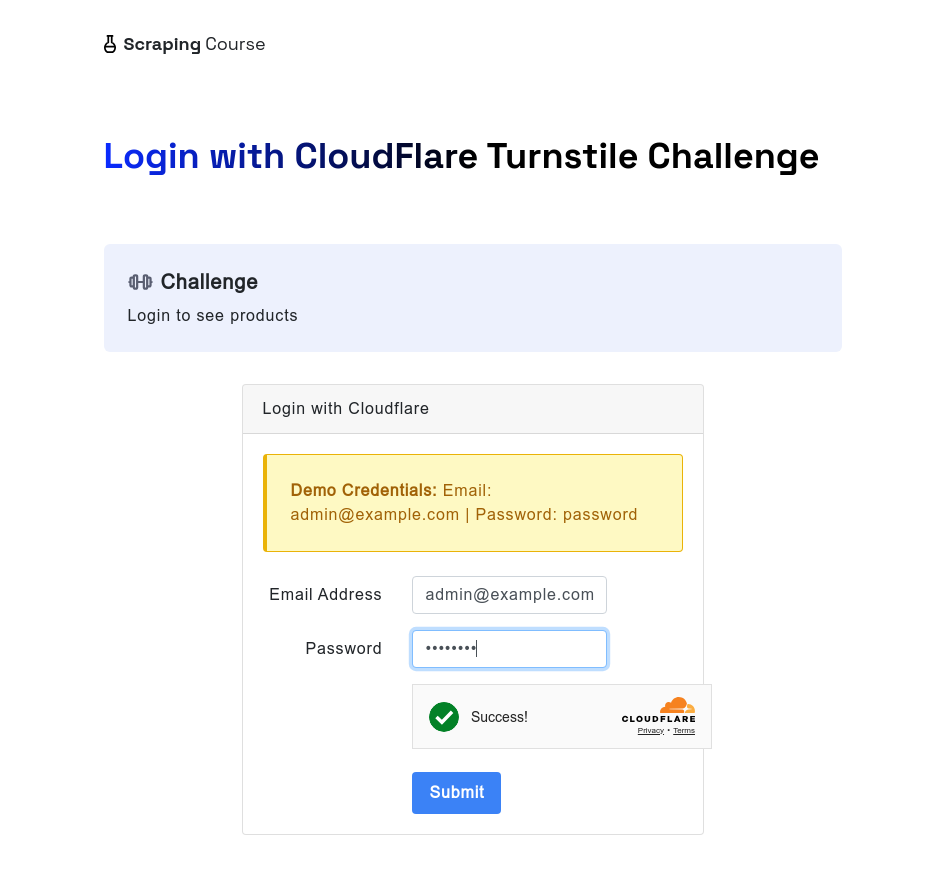
Similarly, when facing Cloudflare Turnstile, the scrapeless browser can still handle it automatically. The example below visits the cloudflare-turnstile test site. After entering the username and password, it uses the waitForFunction method to wait for data from window.turnstile.getResponse(), ensuring that the challenge has been successfully bypassed. It then takes a screenshot and clicks the login button to navigate to the next page.
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com')
await page.locator('input[type="password"]').fill('password')
// Wait for turnstile to unlock successfully
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
await page.screenshot({ path: 'challenge-bypass-success.png' });
await page.locator('button[type="submit"]').click()
await page.waitForNavigation()
await page.screenshot({ path: 'next-page.png' });Upon executing this script, you will be able to see the unlocking effect through the screenshot.
PART5: Using Scrapeless Web Unlocker for JavaScript Rendering
Scrapeless Web Unlocker allows JavaScript rendering and dynamic interactions, making it an effective tool for bypassing Cloudflare.
JavaScript Rendering
JavaScript rendering enables handling of dynamically loaded content and SPAs (Single Page Applications). Enables a complete browser environment, supporting more complex page interactions and rendering requirements.
js_render=true,we will use the browser to request
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.google.com/",
"js_render": true
},
"proxy": {
"country": "US"
}
}JavaScript Instructions
Provides an extensive set of JavaScript directives that allow you to dynamically interact with web pages.
These directives enable you to click elements, fill out forms, submit forms, or wait for specific elements to appear, providing flexibility for tasks such as clicking a “read more” button or submitting a form.
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://example.com",
"js_render": true,
"js_instructions": [
{
"wait_for": [
".dynamic-content",
30000
]
// Wait for element
},
{
"click": [
"#load-more",
1000
]
// Click element
},
{
"fill": [
"#search-input",
"search term"
]
// Fill form
},
{
"keyboard": [
"press",
"Enter"
]
// Simulate key press
},
{
"evaluate": "window.scrollTo(0, document.body.scrollHeight)"
// Execute custom JS
}
]
}
}Challenge Bypass Example
The following sample code uses axios to make a request to Scrapeless's Web Unlocker service. It enables js_render and uses the js_instructions parameter's wait_for directive to wait for an element on the page after the Cloudflare challenge has been bypassed:
import axios from 'axios'
async function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v1/unlocker/request`;
const API_KEY = 'your_api_key'
const payload = {
actor: "unlocker.webunlocker",
proxy: {
country: "US"
},
input: {
url: "https://www.scrapingcourse.com/cloudflare-challenge",
js_render: true,
js_instructions: [
{
wait_for: [
"main.page-content .challenge-info",
30000
]
}
]
},
}
try {
const response = await axios.post(url, payload, {
headers: {
'Content-Type': 'application/json',
'x-api-token': API_KEY
}
});
console.log("[page_html_body] =>", response.data);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();🎉 After executing the above script, you'll be able to see the HTML of the page that has successfully bypassed the Cloudflare challenge in the console.
Scrapeless - A more powerful dynamic website unlocking solution
For dynamic websites, Ajax loading, and single-page applications (SPA), Scrapeless provides Web Unlocker, which can automatically resolve Cloudflare challenges to avoid being detected as a robot.
✅ AI-driven automatic bypass, adapting to Cloudflare anti-crawling updates
✅ Global proxy pool support, stable bypass of IP restrictions
✅ Seamless compatibility with Puppeteer / Playwright
💡 Try Scrapeless Web Unlocker now and easily crawl dynamic website data! 👉 Experience now
Faq About cloudflare challenge
Q: What is a Cloudflare challenge?
A: A Cloudflare challenge is a security measure used to protect websites from malicious activities like bot attacks and DDoS attacks. When Cloudflare detects suspicious behavior, it presents a challenge to the visitor to verify that they are a legitimate user.
Q: Why am I being challenged on a Cloudflare-protected site?
A: You might be challenged for several reasons, including a high threat score associated with your IP address, a history of suspicious activity from your IP, detection of bot-like automated traffic, or specific rules set by the website owner targeting your region or user agent. Cloudflare also verifies that your browser meets certain standards.
Q: What are the different types of Cloudflare challenges?
A: Cloudflare uses different types of challenges, including Managed Challenges, JS Challenges, and Interactive Challenges. Managed Challenges are recommended, where Cloudflare dynamically chooses the appropriate type of challenge based on the request characteristics. JS Challenges present a page that requires JavaScript processing by browser. Interactive Challenges require the visitor to interact with the page to solve puzzles.
Q: What is a Managed Challenge?
A: Managed Challenges are a dynamic system where Cloudflare selects the appropriate challenge type based on the characteristics of the request. This may include non-interactive challenge pages, custom interactive challenges or Private Access Tokens. The goal is to minimize the use of CAPTCHAs and reduce the time users spend solving them.
Join the Scrapeless Discord Community today! 🚀 Connect with expert scrapers, get exclusive tips on bypassing Cloudflare challenges, and stay updated on the latest features. Click here to join now.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


