
如何在Scrapeless中设置未被检测的ChromeDriver?
Advanced Data Extraction Specialist
发现如何使用未检测到的ChromeDriver 绕过反爬虫系统进行网页抓取,以及逐步指导、高级方法和关键限制。此外,了解Scrapeless - 一个更强大的专业抓取需求替代方案。
在本指南中,您将学习:
- 什么是未检测到的ChromeDriver,以及它如何有用
- 它如何最小化机器人检测
- 如何在Python中使用它进行网页抓取
- 高级用法和方法
- 其关键限制和缺点
- 推荐替代方案:Scrapeless
- 反爬虫检测机制的技术分析
让我们深入探讨吧!
什么是未检测到的ChromeDriver?
未检测到的ChromeDriver是一个Python库,它提供了Selenium的ChromeDriver的优化版本。这个版本经过修补,以限制被反爬虫服务检测,例如:
- Imperva
- DataDome
- Distil Networks
- 以及更多……
它还可以帮助 绕过某些Cloudflare保护,虽然这可能更具挑战性。
如果您曾经使用浏览器自动化工具(如Selenium),您会知道它们允许您以编程方式控制浏览器。为了实现这一点,它们以不同于普通用户设置的方式配置浏览器。
反爬虫系统寻找这些差异或“泄漏”,以识别自动化浏览器机器人。未检测到的ChromeDriver修补Chrome驱动程序,以最小化这些明显的迹象,从而减少机器人检测。这使其成为抓取受到反抓取措施保护的网站的理想选择!
未检测到的ChromeDriver是如何工作的?
未检测到的ChromeDriver通过采用以下技术减少来自Cloudflare、Imperva、DataDome和类似解决方案的检测:
- 重命名Selenium变量,使其模仿真实浏览器使用的变量
- 使用合法的、真实世界的User-Agent字符串以避免检测
- 允许用户模拟自然的人际互动
- 在浏览网站时妥善管理cookie和会话
- 启用使用代理以 绕过IP封锁 和防止速率限制
这些方法有助于由库控制的浏览器有效绕过各种反抓取防御。
使用未检测到的ChromeDriver进行网页抓取:逐步指南
步骤 #1:先决条件和项目设置
未检测到的ChromeDriver具有以下先决条件:
- 最新版本的Chrome
- Python 3.6+:如果您的计算机上未安装Python 3.6或更高版本,请从官方网站下载并按照安装说明进行操作。
注意: 该库会自动下载并修补驱动程序二进制文件,因此无需手动下载ChromeDriver。
为您的项目创建一个目录:
language
mkdir undetected-chromedriver-scraper
cd undetected-chromedriver-scraper
python -m venv env激活虚拟环境:
language
# 在Linux或macOS上
source env/bin/activate
# 在Windows上
env\Scripts\activate步骤 #2:安装未检测到的ChromeDriver
通过pip包安装未检测到的ChromeDriver:
language
pip install undetected_chromedriver该库将自动安装Selenium,因为它是其依赖项之一。
步骤 #3:初始设置
创建一个scraper.py文件并导入undetected_chromedriver:
language
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
# 初始化Chrome实例
driver = uc.Chrome()
# 连接到目标页面
driver.get("https://scrapeless.com")
# 抓取逻辑...
# 关闭浏览器
driver.quit()步骤 #4:实施抓取逻辑
现在让我们添加从Apple页面提取数据的逻辑:
language
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
import time
# 创建一个Chrome网络驱动程序实例
driver = uc.Chrome()
# 连接到Apple网站
driver.get("https://www.apple.com/fr/")
# 给页面一些时间来完全加载
time.sleep(3)
# 用于存储产品信息的字典
apple_products = {}
try:
# 查找产品部分(使用提供的HTML中的类)
product_sections = driver.find_elements(By.CSS_SELECTOR, ".homepage-section.collection-module .unit-wrapper")
for i, section in enumerate(product_sections):
try:
# 提取产品名称(标题)
headline = section.find_element(By.CSS_SELECTOR, ".headline, .logo-image").get_attribute("textContent").strip()
# 提取描述(副标题)
```python
subhead_element = section.find_element(By.CSS_SELECTOR, ".subhead")
subhead = subhead_element.text
# 获取链接(如果可用)
link = ""
try:
link_element = section.find_element(By.CSS_SELECTOR, ".unit-link")
link = link_element.get_attribute("href")
except:
pass
apple_products[f"product_{i+1}"] = {
"name": headline,
"description": subhead,
"link": link
}
except Exception as e:
print(f"处理第 {i+1} 个部分时出错: {e}")
# 导出抓取的数据为 JSON
with open("apple_products.json", "w", encoding="utf-8") as json_file:
json.dump(apple_products, json_file, indent=4, ensure_ascii=False)
print(f"成功抓取了 {len(apple_products)} 个苹果产品")
except Exception as e:
print(f"抓取过程中发生错误: {e}")
finally:
# 关闭浏览器并释放资源
driver.quit()运行命令:
language
python scraper.py无检测 ChromeDriver:高级用法
现在您知道这个库的工作原理,您可以探讨一些更高级的场景。
选择特定的 Chrome 版本
您可以通过设置 version_main 参数来指定库使用的特定版本的 Chrome:
language
import undetected_chromedriver as uc
# 指定目标 Chrome 版本
driver = uc.Chrome(version_main=105)使用 with 语法
为了避免在不再需要驱动程序时手动调用 quit() 方法,您可以使用 with 语法:
language
import undetected_chromedriver as uc
with uc.Chrome() as driver:
driver.get("https://example.com")
# 代码的其余部分...无检测 ChromeDriver 的限制
尽管 undetected_chromedriver 是一个强大的 Python 库,但它确实存在一些已知的限制:
IP 阻止
该库并不能隐藏您的 IP 地址。如果您在数据中心运行脚本,被检测的可能性很高。同样,如果您的家庭 IP 声誉不佳,您也可能会被阻止。
要隐藏您的 IP,您需要将受控浏览器与代理服务器集成,正如之前演示的那样。
不支持 GUI 导航
由于模块的内部工作原理,您必须通过 get() 方法以编程的方式浏览。避免使用浏览器 GUI 进行手动导航——通过键盘或鼠标与页面交互会增加被检测的风险。
对无头模式支持有限
官方上,undetected_chromedriver 库并不完全支持无头模式。不过,您可以使用以下代码进行实验:
language
driver = uc.Chrome(headless=True)稳定性问题
结果可能由于众多因素而有所不同。除了不断努力理解和对抗检测算法外,不提供其他保证。今天成功绕过反机器人系统的脚本,明天可能会因保护方法的更新而失败。
推荐替代方案:Scrapeless
考虑到无检测 ChromeDriver 的局限性,Scrapeless 提供了一个更强大和可靠的网络抓取替代方案,避免被阻止。
我们严格保护网站的隐私。本文博客中的所有数据都是公开的,仅用于演示抓取过程。我们不保存任何信息和数据。
为什么 Scrapeless 更优秀
Scrapeless 是一个远程浏览器服务,解决了使用无检测 ChromeDriver 方法的固有问题:
-
持续更新:与可能在反机器人系统更新后停止工作的无检测 ChromeDriver 不同,Scrapeless 由其团队持续更新。
-
内置 IP 轮换:Scrapeless 提供自动 IP 轮换,消除了无检测 ChromeDriver 的 IP 阻止问题。
-
优化配置:Scrapeless 浏览器已经优化以避免检测,这大大简化了过程。
-
自动解决 CAPTCHA:Scrapeless 可以自动解决您可能遇到的 CAPTCHA。
-
与多种框架兼容:与 Playwright、Puppeteer 和其他自动化工具配合使用。
登录 Scrapeless 以获取免费试用。
如何使用 Scrapeless 抓取网络(不被阻止)
以下是如何使用 Scrapeless 和 Playwright 实现类似解决方案的步骤:
步骤 1:注册并 登录 Scrapeless
步骤2:获取 Scrapeless API 密钥
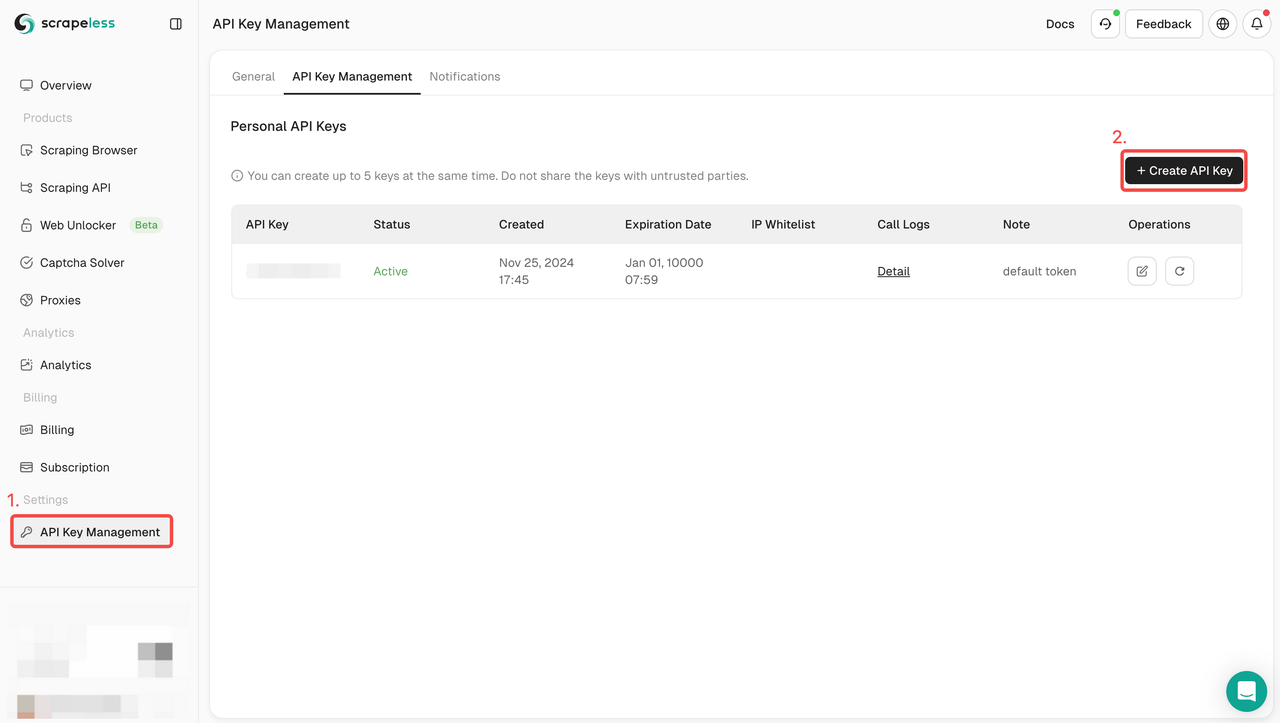
步骤3:您可以将以下代码集成到您的项目中
language
const {chromium} = require('playwright-core');
// 带有您的令牌的 Scrapeless 连接 URL
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOUR_TOKEN_HERE&session_ttl=180&proxy_country=ANY';
(async () => {
// 连接到远程 Scrapeless 浏览器
const browser = await chromium.connectOverCDP(connectionURL);
try {
// 创建一个新页面
const page = await browser.newPage();
// 导航到苹果公司的网站
console.log('正在导航到苹果网站...');
await page.goto('https://www.apple.com/fr/', {
waitUntil: 'domcontentloaded',
timeout: 60000
});
console.log('页面加载成功');
// 等待产品部分可用
await page.waitForSelector('.homepage-section.collection-module', { timeout: 10000 });
// 从主页获取精选产品
const products = await page.evaluate(() => {
const results = [];
// 获取所有产品部分
const productSections = document.querySelectorAll('.homepage-section.collection-module .unit-wrapper');
productSections.forEach((section, index) => {
try {
// 获取产品名称 - 可能在 .headline 或 .logo-image 中
const headlineEl = section.querySelector('.headline') || section.querySelector('.logo-image');
const headline = headlineEl ? headlineEl.textContent.trim() : '未知产品';
// 获取产品描述
const subheadEl = section.querySelector('.subhead');
const subhead = subheadEl ? subheadEl.textContent.trim() : '';
// 获取产品链接
const linkEl = section.querySelector('.unit-link');
const link = linkEl ? linkEl.getAttribute('href') : '';
results.push({
name: headline,
description: subhead,
link: link
});
} catch (err) {
console.error(`处理部分 ${index} 时出错: ${err.message}`);
}
});
return results;
});
// 显示结果
console.log('找到的苹果产品:');
console.log(JSON.stringify(products, null, 2));
console.log(`找到的产品总数: ${products.length}`);
} catch (error) {
console.error('发生错误:', error);
} finally {
// 关闭浏览器
await browser.close();
console.log('浏览器已关闭');
}
})();您还可以加入 Scrapeless 的 Discord,参与开发者支持计划,并获得高达 50 万次 SERP API 使用积分的免费赠送。
增强技术分析
机器人检测:其工作原理
反机器人系统使用几种技术来检测自动化行为:
-
浏览器指纹识别:收集数十个浏览器属性(字体、画布、WebGL 等)以创建唯一签名。
-
WebDriver 检测:检测 WebDriver API 或其痕迹的存在。
-
行为分析:分析鼠标移动、点击、打字速度的差异,这些在用户和机器人之间存在不同。
-
导航异常检测:识别可疑模式,如请求过快或缺少图像/CSS 加载。
推荐阅读:如何绕过反机器人
Undetected ChromeDriver 如何绕过检测
Undetected ChromeDriver 通过以下方式规避这些检测:
-
移除 WebDriver 指示:消除
navigator.webdriver属性和其他 WebDriver 痕迹。 -
修补 Cdc_:修改 Chrome Driver Controller 变量,这些变量是 ChromeDriver 的已知签名。
-
使用逼真的用户代理:用最新的字符串替换默认的用户代理。
-
最小化配置更改:减少对 Chrome 浏览器默认行为的更改。
技术代码展示了 Undetected ChromeDriver 如何修补驱动程序:
language
简化版的 Undetected ChromeDriver 源代码摘录
def _patch_driver_executable():
"""
修补 ChromeDriver 二进制文件以消除自动化的证据
"""
linect = 0
replacement = os.urandom(32).hex()
with io.open(self.executable_path, "r+b") as fh:
for line in iter(lambda: fh.readline(), b""):
if b"cdc_" in line.lower():
fh.seek(-len(line), 1)
newline = re.sub(
b"cdc_.{22}", b"cdc_" + replacement.encode(), line
)
fh.write(newline)
linect += 1
return linect为什么 Scrapeless 更有效
Scrapeless采取不同的方法:
-
预配置环境:使用已经优化的浏览器,模拟人类用户。
-
基于云的基础设施:在云中运行浏览器,具有适当的指纹识别。
-
智能代理轮换:根据目标网站自动轮换IP。
-
高级指纹管理:在整个会话中保持一致的浏览器指纹。
-
WebRTC、Canvas和插件抑制:阻止常见的指纹识别技术。
登录Scrapeless以获得免费试用。
结论
在这篇文章中,您已经了解了如何使用Undetected ChromeDriver处理Selenium中的机器人检测。这个库提供了一个经过修补的ChromeDriver版本,用于网络抓取而不会被阻止。
挑战在于,像Cloudflare这样的高级反机器人技术仍然能够检测和阻止您的脚本。像undetected_chromedriver这样的库不够稳定——它们今天可能有效,但明天可能就不行。
对于专业的抓取需求,像Scrapeless这样的基于云的解决方案提供了更强大的替代方案。它们提供预配置的远程浏览器,专门设计用于绕过反机器人措施,具有IP轮换和CAPTCHA解决等额外功能。
选择Undetected ChromeDriver和Scrapeless取决于您的具体需求:
- Undetected ChromeDriver:适合较小的项目,免费且开源,但需要更多维护,可能不够可靠。
- Scrapeless:更适合专业抓取需求,更可靠,持续更新,但需要支付订阅费用。
通过了解这些反机器人绕过技术的工作原理,您可以为您的网页抓取项目选择合适的工具,并避免自动数据收集的常见陷阱。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


