
如何使用Python抓取需要登录的网站(2026)
Expert Network Defense Engineer
经过多年的爬虫构建,登录墙仍然是最具挑战性的难题之一。本指南重点介绍在实际项目中有效的方法:从简单的表单登录到CSRF保护以及由现代WAF和反机器人系统保护的网站。相关示例使用Python,并在最后展示如何使用远程浏览器(Scrapeless Browser)来处理最困难的保护措施。
本指南仅供教育使用。尊重网站的服务条款和隐私规则(例如GDPR)。请勿抓取您没有权限访问的内容。
本指南涵盖的内容
- 抓取需要简单用户名和密码的网站。
- 登录需要CSRF令牌的页面。
- 访问基本WAF保护后的内容。
- 使用通过Puppeteer控制的远程浏览器(Scrapeless Browser)处理高级反机器人保护。
您能否抓取需要登录的网站?
是的——从技术上讲,您可以获取登录后页面的内容。也就是说,法律和道德限制适用。社交平台和包含个人数据的网站尤其敏感。始终检查目标网站的爬虫政策、服务条款和适用法律。
从技术上讲,关键步骤是:
- 理解登录流程。
- 以编程方式重现必要的请求(和令牌)。
- 持久化已认证状态(cookies、会话)。
- 根据需要处理客户端检查。
1) 简单的用户名 + 密码登录(Requests + BeautifulSoup)
结论前置: 如果登录是一个基本的HTTP表单,请使用会话并POST凭证。
安装库:
bash
pip3 install requests beautifulsoup4示例脚本:
python
import requests
from bs4 import BeautifulSoup
login_url = "https://www.example.com/login"
payload = {
"email": "admin@example.com",
"password": "password",
}
with requests.Session() as session:
r = session.post(login_url, data=payload)
print("状态码:", r.status_code)
soup = BeautifulSoup(r.text, "html.parser")
print("页面标题:", soup.title.string)注意事项:
- 使用
Session()以便cookies(会话ID)在后续请求中保持。 - 检查响应代码和正文以确认登录成功。
- 如果网站使用重定向,
requests会默认跟随;必要时检查r.history。
2) CSRF保护的登录(获取令牌,然后POST)
结论前置: 许多网站需要CSRF令牌。首先GET登录页面,解析令牌,然后使用该令牌POST。
模式:
- GET登录页面。
- 从表单中解析隐藏令牌。
- 使用相同会话POST凭证 + 令牌。
示例:
python
import requests
from bs4 import BeautifulSoup
login_url = "https://www.example.com/login/csrf"
with requests.Session() as session:
r = session.get(login_url)
soup = BeautifulSoup(r.text, "html.parser")
csrf_token = soup.find("input", {"name": "_token"})["value"]
payload = {
"_token": csrf_token,
"email": "admin@example.com",
"password": "password",
}
r2 = session.post(login_url, data=payload)
soup2 = BeautifulSoup(r2.text, "html.parser")
products = []
for item in soup2.find_all(class_="product-item"):
products.append({
"名称": item.find(class_="product-name").text.strip(),
"价格": item.find(class_="product-price").text.strip(),
})
print(products)提示:
- 一些框架使用不同的令牌名称;检查表单以找到正确的输入名称。
- 发送适当的头部(User-Agent、Referer)以看起来像正常浏览器。
3) 基本WAF / 机器人检查 — 当Requests失败时使用无头浏览器
当头部和令牌不足时,使用Selenium或无头浏览器模拟真实浏览器。
Selenium + Chrome可以通过执行JavaScript和运行完整的浏览器环境来通过许多基本保护。如果使用Selenium,请添加现实的等待、鼠标/键盘操作和正常的浏览器头部。
然而,一些WAF通过navigator.webdriver或其他启发式方法检测自动化。工具如undetected-chromedriver有所帮助,但不能保证对高级检查的有效性。仅在合法、允许的使用场合下使用它们。
4) 高级反机器人保护 — 使用远程真实浏览器会话(Scrapeless Browser)
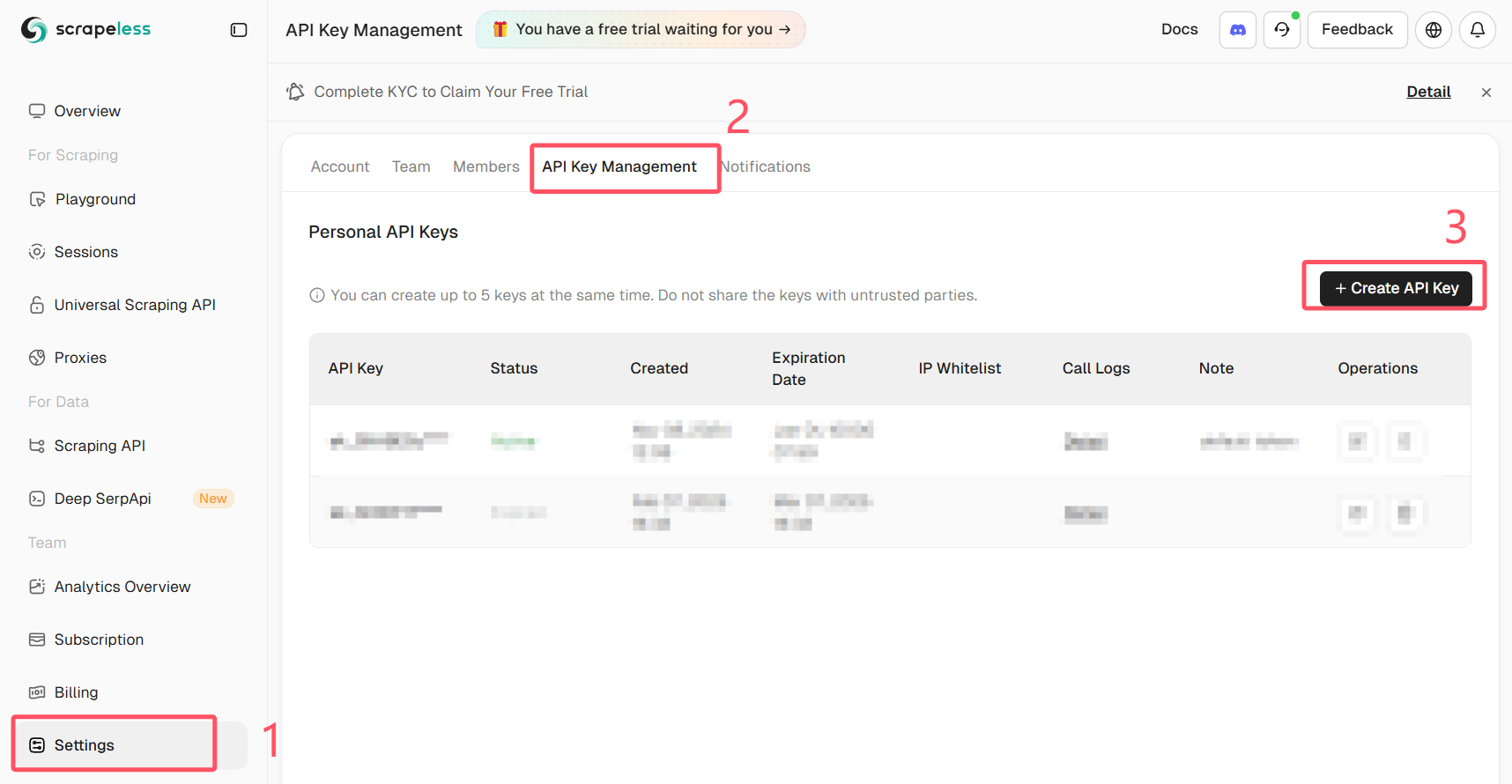
获取您的Scrapeless API密钥
登录Scrapeless并获取您的API密钥。
为了获得最稳健的方法,远程运行一个真实的浏览器(而不是本地的无头实例),并通过Puppeteer控制它。Scrapeless Browser提供了一个托管的浏览器端点,可以降低检测风险并减少代理/JS渲染复杂性。
为什么这样有帮助:
- 浏览器在一个托管环境中运行,模拟真实用户的会话。
- JS的执行方式与真实用户的浏览器完全相同,因此客户端检查通过。
- 您可以根据需要录制会话并使用代理路由。
下面是一个示例,展示如何将Puppeteer连接到Scrapeless浏览器并进行自动登录。该代码片段使用puppeteer-core连接到Scrapeless的WebSocket端点。将token、your_email@example.com和your_password替换为您自己的值,并且永远不要公开共享凭据。
**重要:**切勿将真实凭据或API令牌提交到公共代码中。安全地存储秘密(环境变量或秘密管理器)。
import puppeteer from "puppeteer-core"
// 💡启用“使用游乐场设置”将覆盖您的游乐场代码的连接参数。
const query = new URLSearchParams({
token: "your-scrapeless-api-key",
proxyCountry: "ANY",
sessionRecording: true,
sessionTTL: 900,
sessionName: "Automatic Login",
})
const connectionURL = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
})
const page = await browser.newPage()
await page.goto("https://github.com/login")
await page.locator("input[name='login']").fill("your_email@example.com")
await page.locator("input[name='password']").fill("your_password")
await page.keyboard.press("Enter")示例说明:
- 该示例使用
puppeteer-core连接到远程浏览器。Scrapeless暴露了一个WebSocket端点(browserWSEndpoint),Puppeteer可以使用。 - 会话录制和代理选项通过查询参数传递。根据您的Scrapeless计划和需求进行调整。
- 等待逻辑很重要:使用
waitUntil: "networkidle"或显式的waitForSelector以确保页面完全加载。 - 用您环境中的安全机密替换占位符令牌。
实用提示与反封堵检查表
- 如果存在,使用该网站的API。它更安全且更稳定。
- 避免快速并行请求;限制爬虫速率。
- 在合法且必要时轮换IP和会话指纹。使用信誉良好的代理提供商。
- 使用真实的请求头和Cookie处理。
- 检查robots.txt和网站条款。如果网站禁止抓取,请考虑请求许可或使用官方数据源。
- 记录爬虫执行的步骤以便于调试(请求、响应代码、重定向)。
总结
您学会了:
- 使用
requests登录并抓取接受简单用户名/密码的页面。 - 提取并使用CSRF令牌以安全认证。
- 在需要全JS渲染的网站上使用浏览器自动化工具。
- 通过Puppeteer使用远程托管浏览器(Scrapeless Browser)以绕过高级客户端保护,同时保持您自己的环境简单。
当保护措施较强时,托管浏览器方法通常是最可靠的途径。请负责任地使用,并保持凭据和API令牌的安全。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


