
如何通过Scrapeless抓取亚马逊数据?
Advanced Data Extraction Specialist
想在亚马逊上获得竞争优势吗?无论您是在跟踪价格、分析产品趋势,还是进行市场研究,保持领先的关键是有效地抓取亚马逊数据。但是,从亚马逊提取有用的信息可能会很棘手——尤其是在网站结构频繁变化、反机器人措施和IP阻塞的情况下。这就是 亚马逊抓取API 大显身手的地方。在本指南中,我们将向您展示如何使用Python抓取亚马逊产品数据,使从世界上最大的电子商务平台收集有价值的数据和信息变得比以往任何时候都容易。
什么是亚马逊抓取API?
亚马逊网页抓取API 像一个远程服务器,帮助您收集亚马逊数据。操作很简单——您向API端点发送包含目标URL和其他参数(例如地理位置)的请求。然后,API为您访问该网站。
亚马逊支持抓取以下数据类型:
1. 产品:
-
产品信息:可以抓取的内容包括基本信息,如产品名称、描述、价格、图片URL、ASIN(亚马逊标准识别号码)、品牌等。
-
销售数据:如产品排名、销量和评论等。
2. 卖家:
- 卖家信息:您可以获取卖家的名称、商户ID及其销售产品的相关信息。
- 卖家排名:通过抓取来自不同卖家的产品,您可以分析每个卖家的市场表现及其在特定类别中的竞争力。
3. 关键词:
- 关键词搜索结果:您可以根据特定关键词(如“笔记本电脑”或“动漫人物”)抓取相关产品列表及其详细信息。
亚马逊抓取的常见用例
亚马逊抓取为企业和营销人员提供了多种用途:
1. 价格监测: 通过抓取产品价格,企业可以跟踪竞争对手的定价并相应调整自己的策略。
2. 产品研究: 抓取评论、评分和产品细节有助于识别热门商品并了解客户偏好。
3. 销售优化: 营销人员抓取产品描述和促销信息以改善内容并创建有效的营销活动。
4. 库存水平跟踪: 抓取实时产品可用性数据帮助企业监控库存水平和需求。
5. 客户情感分析: 从亚马逊抓取的评论提供了客户满意度和改进领域的见解。
总之,亚马逊抓取简化了竞争分析、产品研究和营销策略。
抓取亚马逊的主要挑战(如CAPTCHA、频率限制)
- CAPTCHA挑战
亚马逊使用CAPTCHA验证来防止自动抓取,尤其是在检测到大量快速请求时。此类验证要求用户确认他们是人类,从而阻止自动工具成功获取数据。
亚马逊对请求频率有限制。如果您过于频繁地访问其网站,系统将自动延迟响应或暂时阻止进一步的请求。这使得抓取过程变得缓慢且不稳定。
提示: 对于大多数普通用户,亚马逊通常允许每分钟几十到几百个请求。超出此频率可能会遇到延迟或暂时阻断。亚马逊可能会对频繁的抓取请求设置更严格的限制。
- IP阻塞
频繁抓取可能会导致亚马逊暂时阻止IP地址。如果某个IP地址被标记为异常来源,抓取操作将完全被阻止,您需要更换IP或使用代理池来绕过此限制。一般来说,每秒5-10个请求可能会引发风险。
- 动态内容加载
亚马逊页面内容通常通过JavaScript动态加载,这意味着在抓取时需要额外处理页面渲染过程。传统的HTML抓取方法通常无法直接获取动态加载的数据。
- 布局频繁变化
亚马逊网站的页面布局经常变化,这给抓取脚本带来了挑战。抓取工具需要不断更新以适应页面的更新和变化,以确保数据提取的准确性和稳定性。
设置Python环境
在你开始编写Python代码之前,首先必须设置你的开发环境。这个步骤确保你拥有编写和执行Python代码所需的所有工具和库。在本节中,我们将引导你完成安装Python、设置虚拟环境以及配置集成开发环境(IDE)以优化工作流程的过程。
要使用Python,你需要下载以下配置
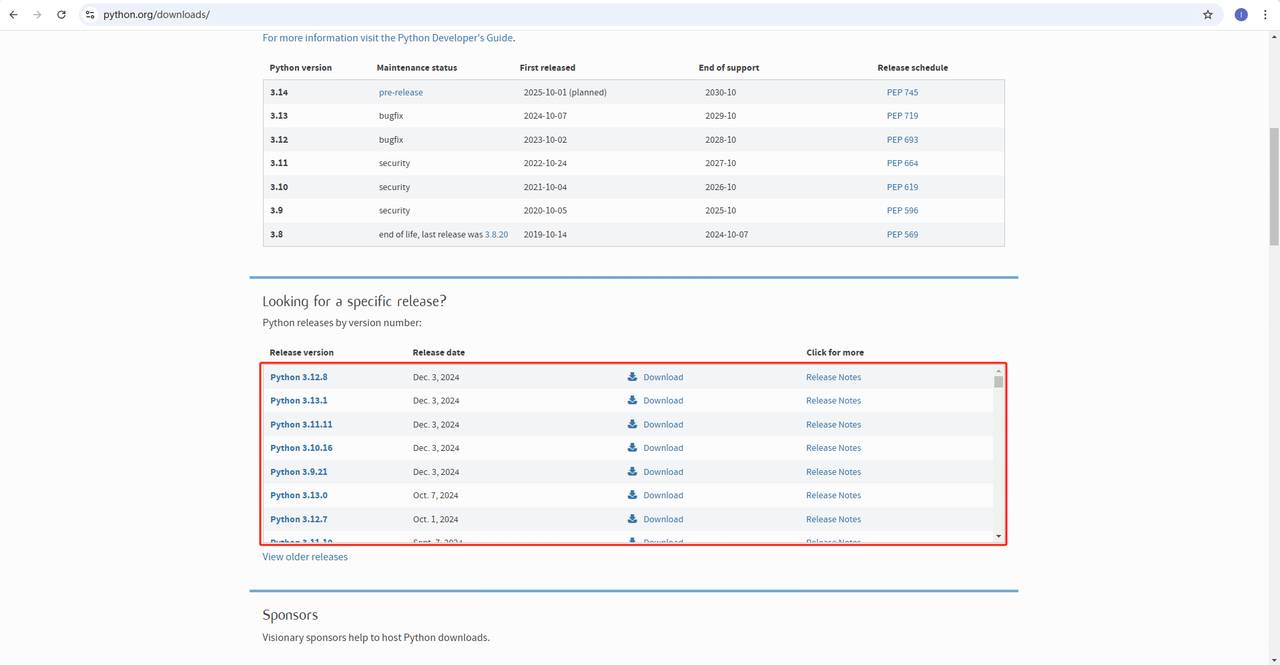
1. Python: https://www.python.org/downloads/ 这是运行Python的核心软件。你可以从官方网站下载我们需要的版本,如下所示,但建议不要下载最新版本。你可以下载最新版本的前1-2个版本。
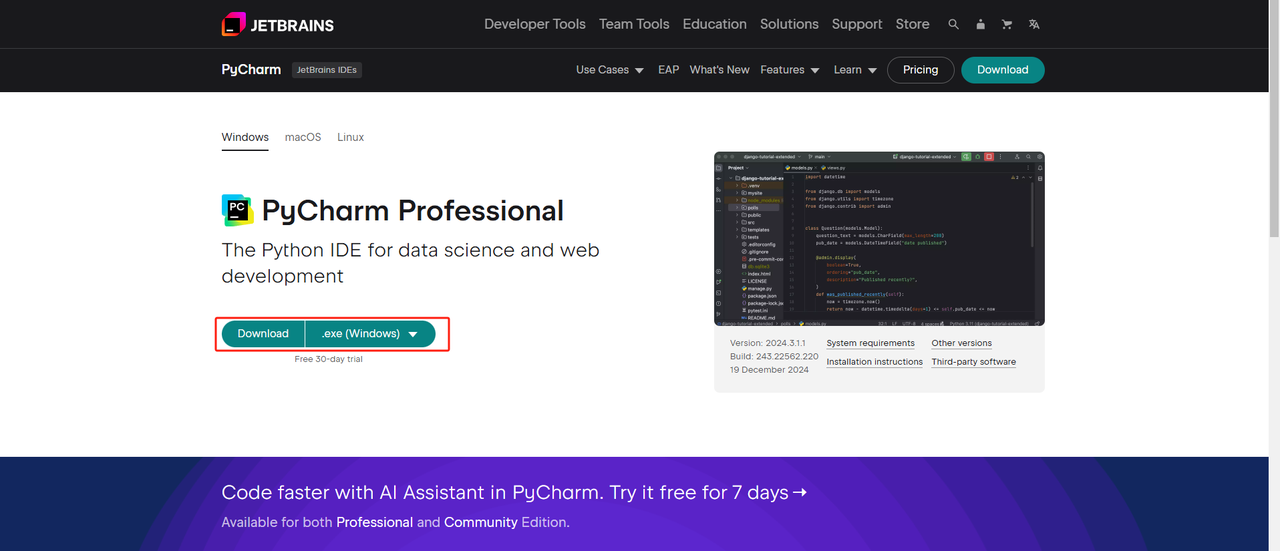
2. Python IDE: 任何支持Python的IDE都可以,但我们推荐使用PyCharm,这是专为Python设计的IDE开发工具软件。对于PyCharm版本,我们建议使用免费的PyCharm Community Edition。
3. pip: 你可以使用Python包索引(PyPi)通过单个命令安装库。
注意: 如果你是Windows用户,不要忘记在安装向导中勾选“将python.exe添加到PATH”选项。这样,Windows将能够在终端中使用python和命令。供你参考:由于Python 3.4或更高版本默认已包含此功能,因此你无需手动安装它。
初始化Python项目
启动PyCharm并在菜单栏上选择“文件 > 新建项目...”选项。

然后,它会打开一个弹出窗口。从左侧菜单中选择“纯Python”,然后按如下方式设置你的项目:
注意: 在下方红框中,选择我们在环境配置第一步下载的Python安装路径。
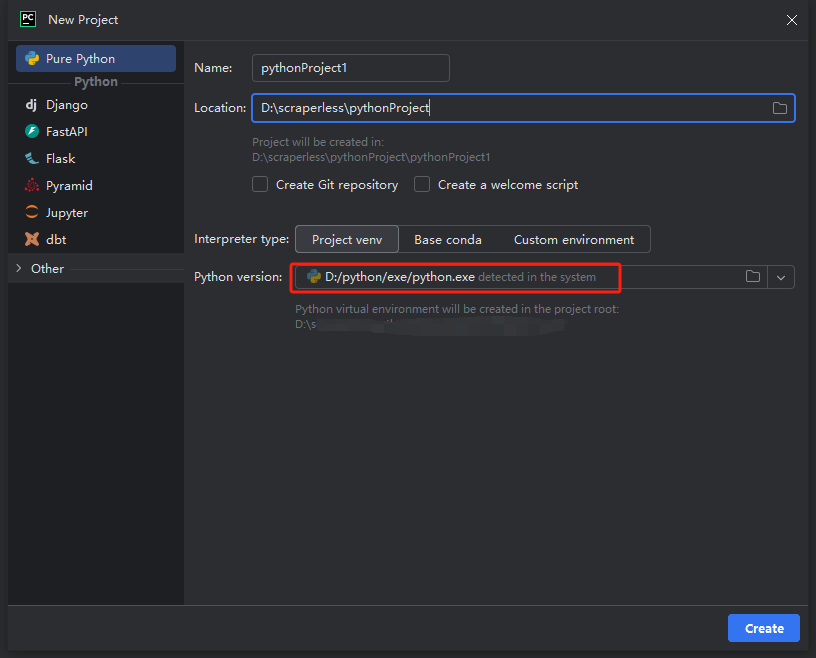
你可以创建一个名为python-scraper的项目,在文件夹中勾选“创建main.py欢迎脚本选项”,然后点击“创建”按钮。
等待一段时间让PyCharm设置你的项目后,你应该会看到以下内容:
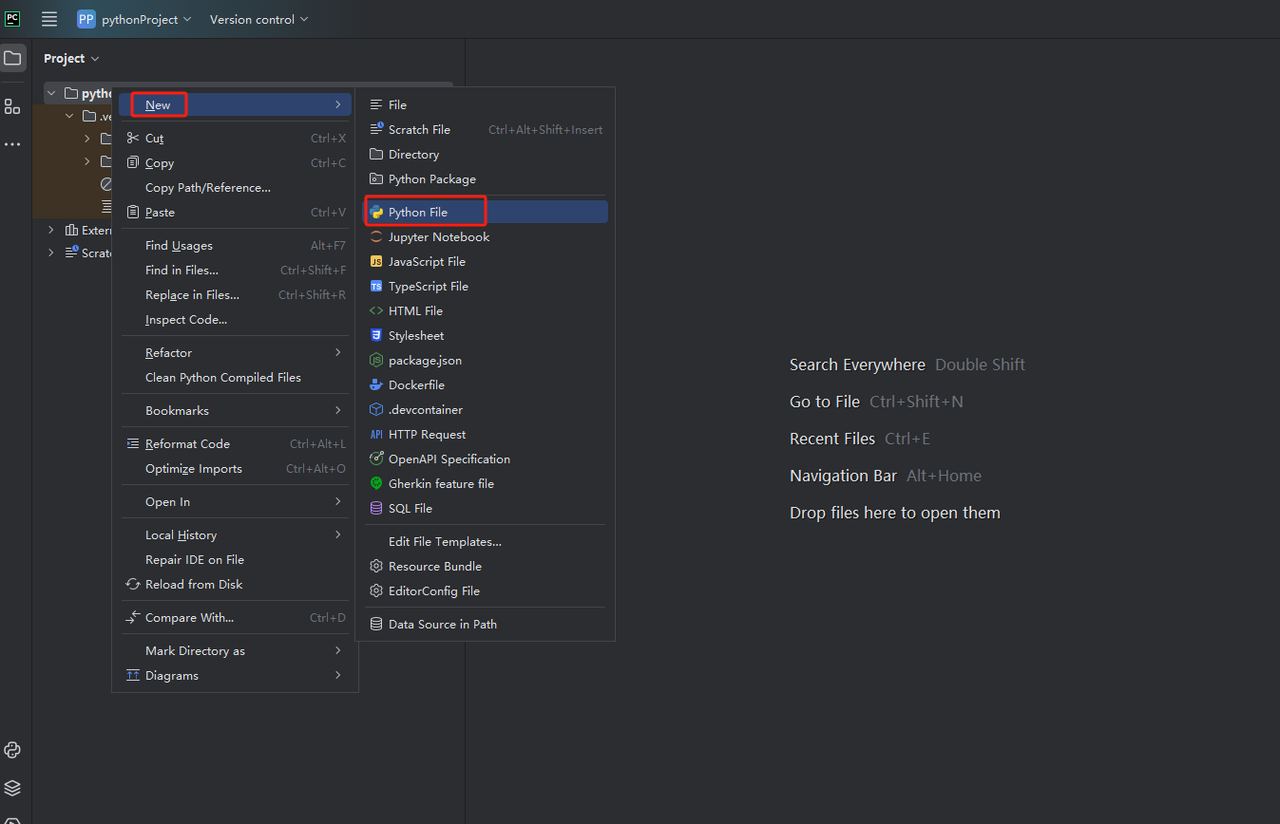
然后,右击创建一个新的Python文件。
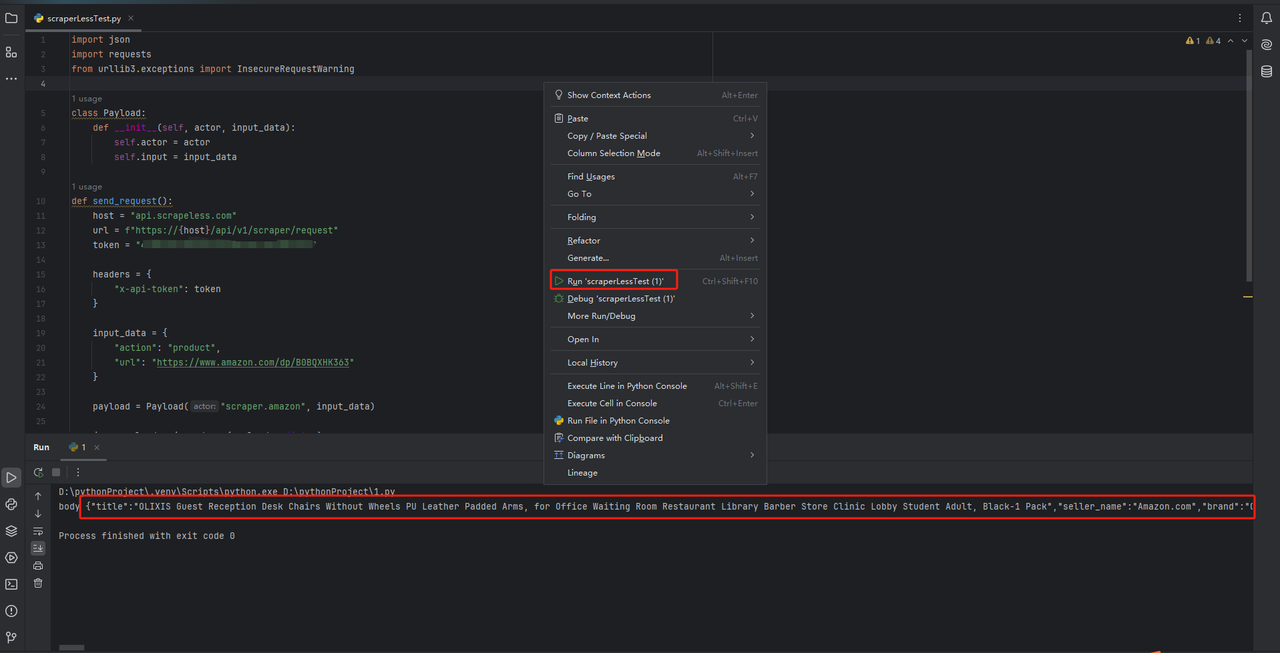
为了验证一切是否正常工作,打开屏幕底部的终端选项卡并输入:python main.py。执行此命令后,你应该得到:Hi, PyCharm。
你可以直接将scraperless中的代码复制到PyCharm并运行,这样我们就能获取亚马逊产品的json格式数据。
分步指南:抓取亚马逊产品数据
如上所述,在配置完成抓取亚马逊所需的环境后,你可以集成Scrapeless Python代码。
如何抓取亚马逊产品数据
你可以直接访问Scrapeless API文档来获取更完整的API代码信息,然后将Scrapeless Python代码集成到你的项目中。
请求示例 - 产品
import requests
import json
url = "https://api.scrapeless.com/api/v1/scraper/request"
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)如何抓取亚马逊卖家信息
同样,只需将Scrapeless API代码集成到你的抓取设置中,你就可以绕过亚马逊抓取障碍并抓取亚马逊卖家信息。
请求示例 - 卖家
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "",
"action": "seller"
}
})
headers = {'内容类型': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))
如何抓取亚马逊关键词搜索结果
按照上述步骤将请求示例 - 关键词集成到您的项目中,以获取亚马逊关键词搜索结果。
请求示例 - 关键词
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"action": "keywords",
"keywords": "iPhone 12",
"page": "5",
"domain": "com"
}
})
headers = {
'内容类型': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))通过简单的集成和配置,Scrapeless帮助您以更高效的方式获取亚马逊数据。您可以轻松抓取亚马逊平台上的关键数据,包括产品、卖家和关键词信息,从而提高数据分析的准确性和实时性。
有关抓取亚马逊数据的常见问题
1. 抓取亚马逊数据合法吗?
抓取公共产品信息(如标题、描述、价格和评级)是合法的,而抓取私人账户数据可能会引发隐私问题。此外,出于市场调研或竞争分析使用抓取的数据通常被认为是"合理使用"。
2. 可以从亚马逊抓取什么数据?
使用亚马逊抓取 API,您可以提取与产品、卖家、评论等相关的数据。这包括产品名称、价格、ASIN(亚马逊标准识别码)、品牌、描述、规格、类别、用户评论及其评级。
3. 如何有效抓取亚马逊数据?
有效抓取亚马逊数据的方法包括使用自动化脚本或 API,并遵循亚马逊的服务条款。为了避免被封锁,建议减少请求频率并合理控制负载。此外,使用验证码解决方案可以提高抓取的成功率。
结论:最佳亚马逊抓取 API 提供商
通过本文的介绍,您已经掌握如何使用 Python 高效抓取亚马逊上的产品数据。无论是获取产品详情、价格信息还是评论数据,Python 的强大和灵活性使得自动抓取变得更加容易和高效。然而,在抓取大规模数据时,您可能会遇到反爬虫机制的挑战。这时,Scrapeless 作为智能网络爬虫解决方案,可以帮助您绕过这些障碍,确保更顺畅和高效的抓取过程。如果您想提高数据抓取的速度和稳定性,不妨尝试使用 Scrapeless来进一步优化您的抓取工作流程。
加入 Scrapeless Discord 社区!🚀 与其他数据爱好者交流,获得快速和智能抓取的独家技巧,并随时了解我们的最新功能。无论您是初学者还是专业人士,这里都有您的一席之地。点击链接并立即开始交流!👾 立即加入
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


