
如何使用Scrapeless的无头浏览器抓取网页
Advanced Data Extraction Specialist
为什么选择Scrapeless的抓取浏览器进行网页抓取?
网页抓取已成为企业收集实时数据(从竞争对手定价到市场趋势)的重要工具。Statista最近的一项调查发现,超过70%的企业依靠网页抓取来提取有价值的数据,使其成为数据驱动决策的关键部分。
随着网页抓取市场的增长,预计到2025年将达到54亿美元(MarketsandMarkets),企业越来越多地采用抓取工具来提高效率和可扩展性。但是,诸如IP封锁、CAPTCHA和动态内容之类的挑战可能会扰乱抓取过程。
Scrapeless通过其AI驱动的解决方案解决了这些问题,即使面对常见的反抓取障碍也能确保无缝数据提取。
从今天开始,使用Scrapeless的抓取浏览器更智能地进行抓取!使用我们用户友好的工具轻松从网页中提取数据,该工具旨在处理最复杂的网站。立即试用,体验前所未有的无缝数据提取!
Scrapeless提供先进的AI驱动网页抓取解决方案,旨在帮助企业克服这些常见的障碍。Scrapeless工具包专为那些寻求从网络中高质量、可靠和快速提取数据的人而设计。无论您是想抓取电子商务网站、社交媒体平台还是新闻聚合器,Scrapeless都能提供合适的工具来完成工作。
Scrapeless的主要优势包括:
- 无缝代理管理:通过IP轮换和全球覆盖保护您的抓取会话。
- AI驱动的CAPTCHA解决方案:自动解决CAPTCHA挑战,确保您的数据收集不会中断。
- 高级浏览器技术:在不出现错误的情况下浏览复杂、动态的网页。
- 可扩展的解决方案:从小型数据提取任务到大型抓取操作,Scrapeless都可以根据您的需求进行扩展。
Scrapeless不仅仅是另一个抓取工具。它是一个全面的平台,解决了与网页抓取相关的关键挑战,确保您的数据收集保持快速、高效和可靠。无论您是初创企业还是大型企业,Scrapeless的灵活性都允许您根据自己的特定需求定制抓取任务。从代理管理到处理具有动态内容的复杂网站,Scrapeless提供了简化网页抓取操作并节省宝贵时间的所有必要工具。
Scrapeless抓取浏览器:
Scrapeless网页抓取解决方案的核心是抓取浏览器。Scrapeless的抓取浏览器经过优化,可以处理最具挑战性的抓取场景,并与Scrapeless工具包无缝集成,提供卓越的抓取体验。
Scrapeless抓取浏览器的关键功能:
- 🌐 动态内容处理:轻松抓取具有大量JavaScript和动态内容的网站,而其他工具通常难以处理这些内容。
- 🖥️ 无头模式:无需启动完整的浏览器窗口即可运行抓取任务,从而提高性能并减少资源使用。
- 🛡️ 反检测技术:使用高级技术(如浏览器指纹和隐身模式)防止检测。
- ⚡ 卓越的效率:比传统的浏览器模式快10倍,在服务器端运行以加快响应时间并支持大规模并发访问。
- ⏱️ 99.99%的正常运行时间:可靠的24/7可用性确保您的抓取任务始终按计划运行。
使用Scrapeless的抓取浏览器,您的数据提取过程将变得更快、更可靠、更轻松,确保您可以专注于提取有价值的见解,而不是处理抓取的技术挑战。
开始使用Scrapeless的抓取浏览器
API密钥(应用程序编程接口密钥)是用于验证身份并授权访问API的工具。它通常是一串唯一的字母、数字和符号。访问API时,API密钥充当身份验证“通行证”,确保请求是由合法用户或应用程序发出的。
✅您可以按照以下步骤获取API密钥:
- 单击**登录Scrapeless**后,您可以自动获得相应的API密钥。
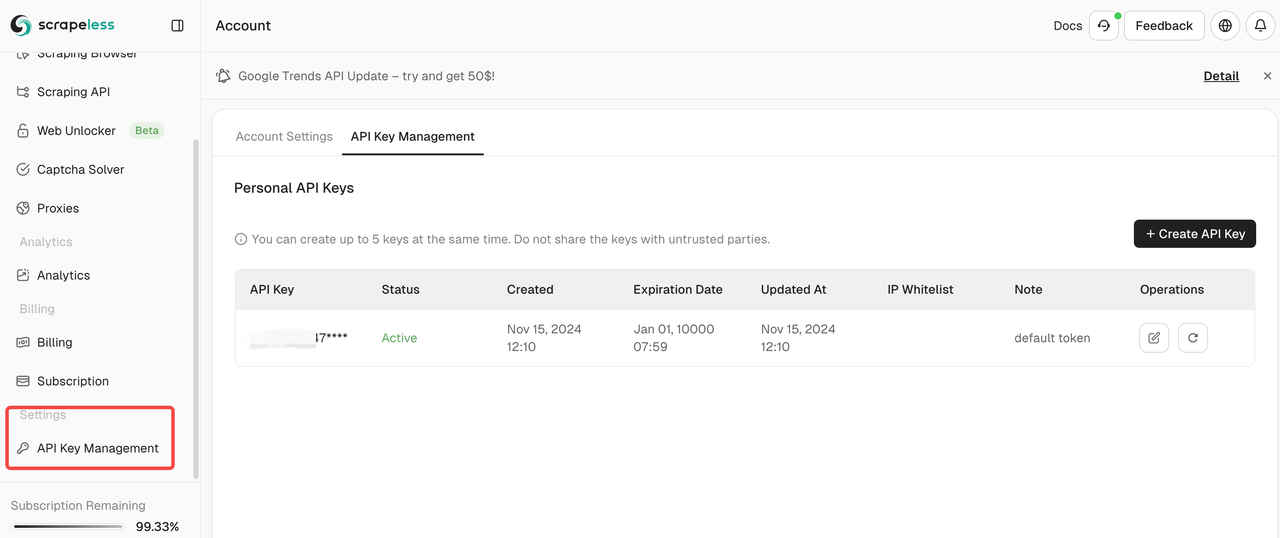
- 您可以在API密钥管理中查看您的API密钥:
使用Scrapeless逐步抓取网页的指南
在本节中,我们将使用scrapeless + puppeteer演示如何在亚马逊上抓取产品内容。
Puppeteer是由Google开发的Node.js库,它提供了一个高级API,用于通过Chromium或Chrome浏览器执行自动化操作。它可以像人类用户一样操作浏览器、点击、输入、导航等,还可以抓取页面内容、生成屏幕截图和PDF、测试网页等。
首先,我们需要获取API密钥scrapeless。您可以参考上一节了解如何获取和查看您的API密钥。
使用Scrapeless逐步抓取网页的指南:
- 通过npm命令安装puppeteer
npm i puppeteer-core- 准备scrapeless的连接参数。您可以设置会话时间和代理国家/地区配置。
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOU_TOKEN&session_ttl=180&proxy_country=ANY';- 开始准备在亚马逊上抓取产品数据、
- 使用浏览器的开发者工具(F12)获取输入框和搜索元素,并获取元素的选择器。
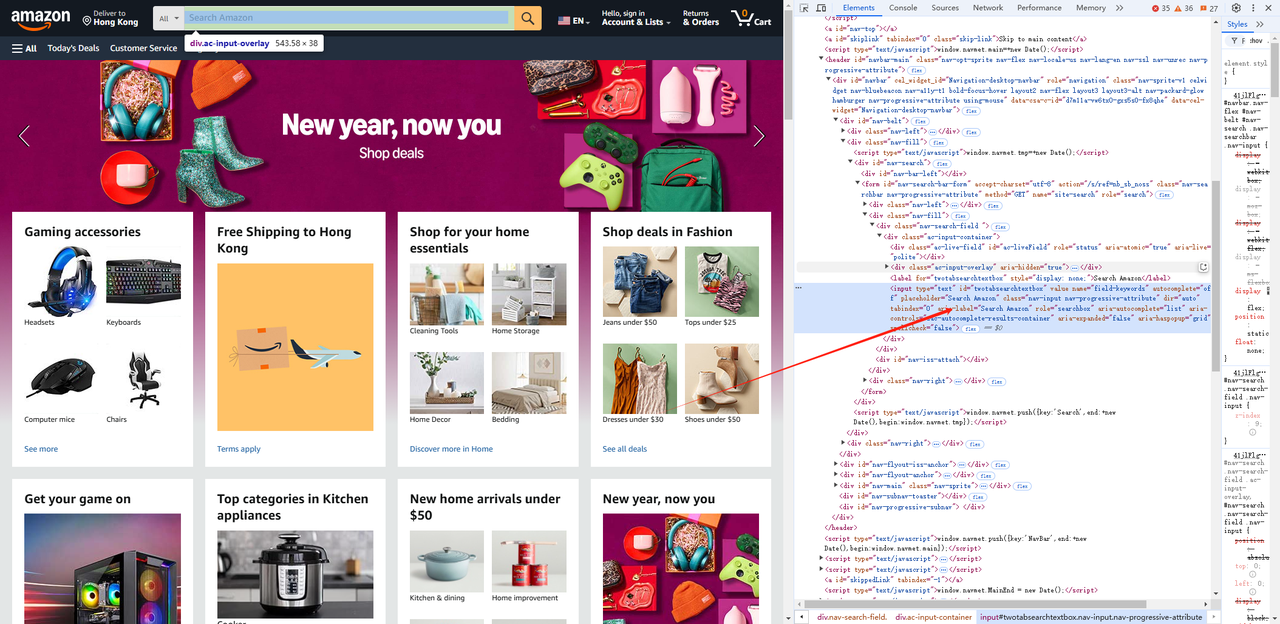
await page.waitForSelector('#twotabsearchtextbox')
await page.type('#twotabsearchtextbox', 'iphone 15', { delay: 100 })
await page.click('#nav-search-submit-button')您可以将iphone 15替换为您要抓取的内容。
- 然后我们进入产品列表页面,我们获取所有role属性为listitem的div元素。
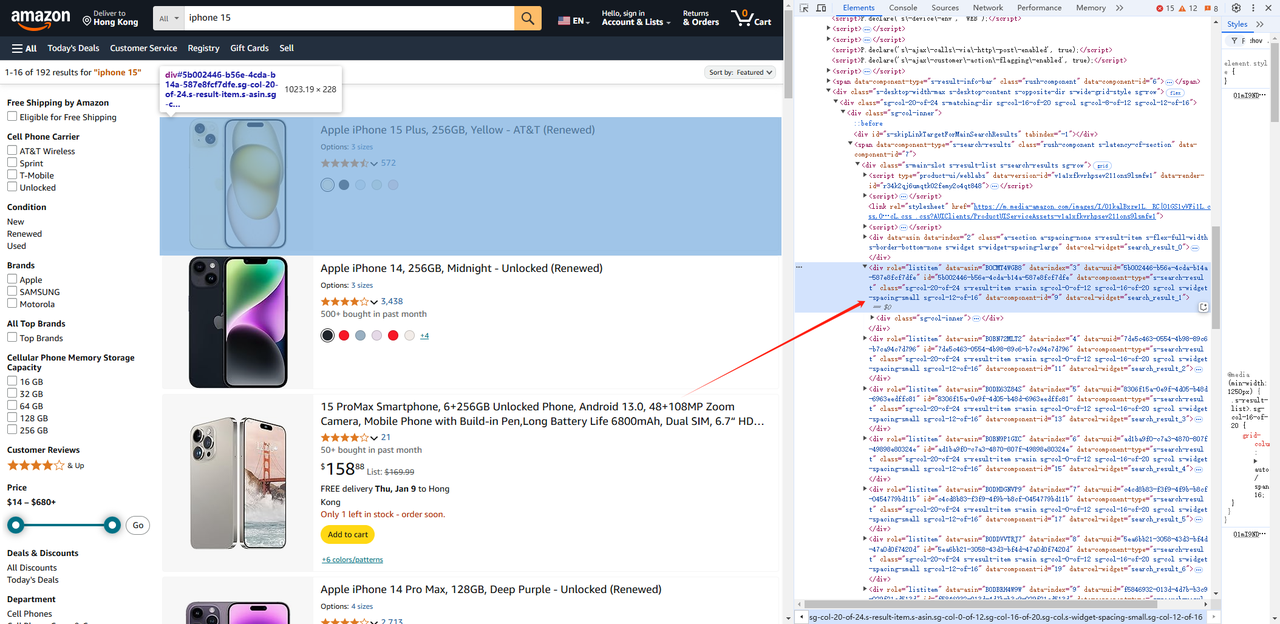
await page.waitForSelector('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]') // 您需要等待元素呈现后再获取它
const list = await page.$$('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')- 同样,我们可以为每个元素获取产品信息,例如图片、标题、链接等。
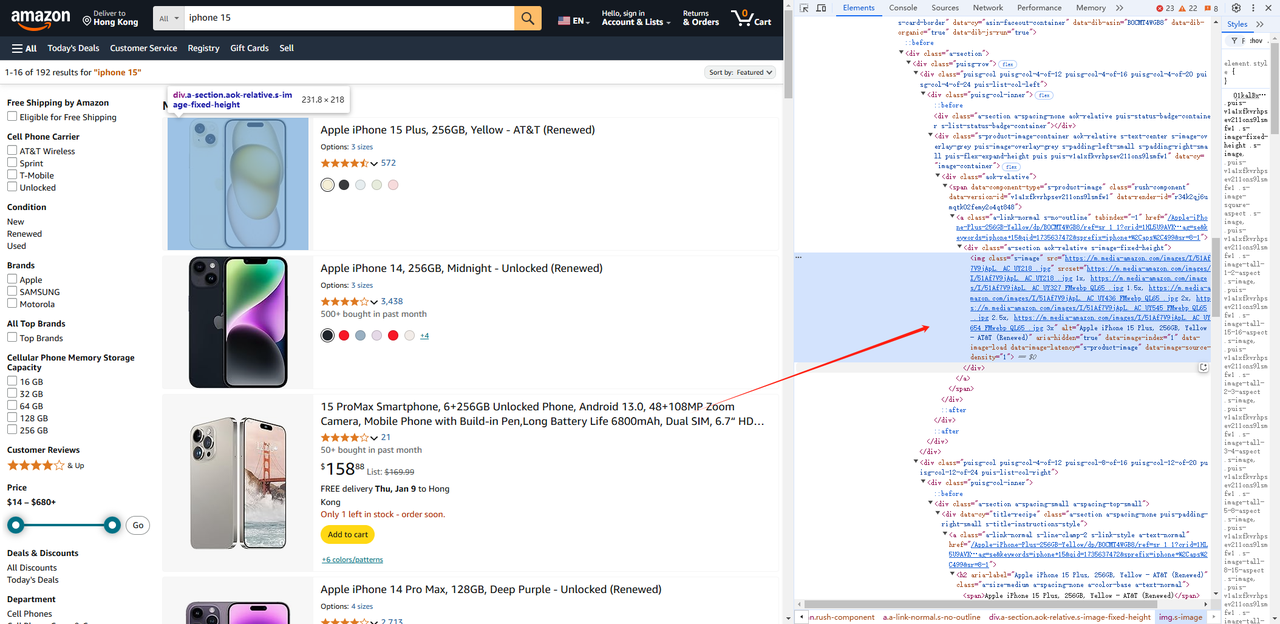
const renderList = []
for (const item of list) {
const img = await item.$('img').then((ele) => {
return ele.evaluate((ele) => {
const img = ele.getAttribute("src")
const title = ele.getAttribute("alt")
return { img, title }
})
})
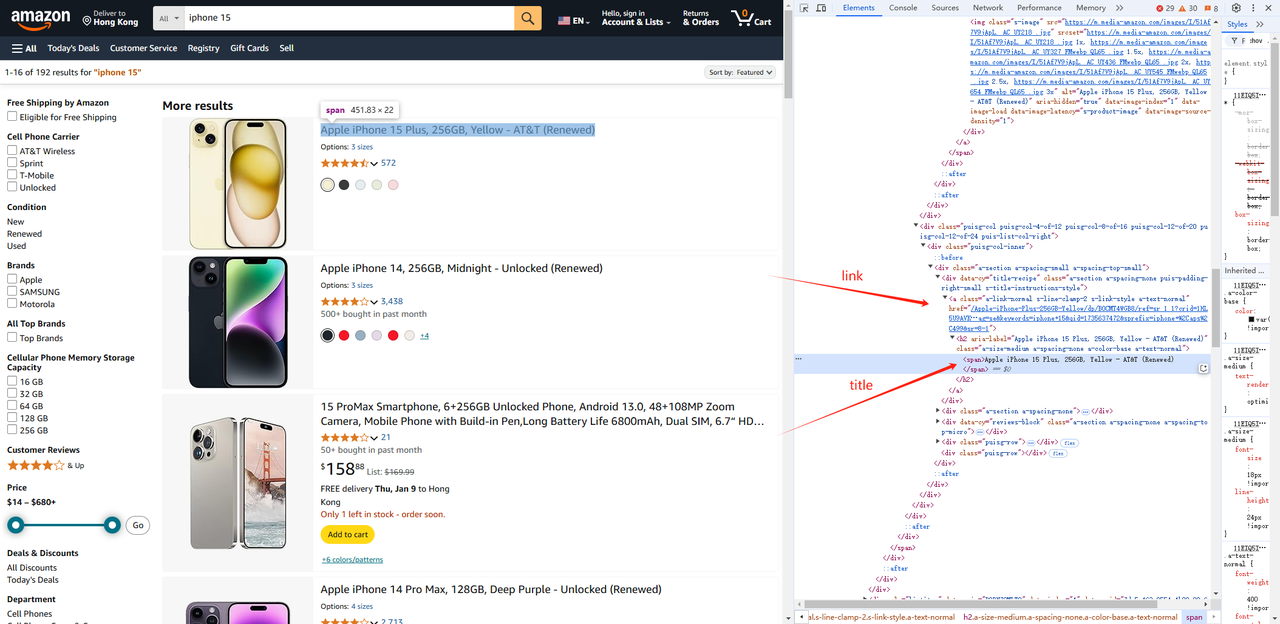
const link = await item.$('.a-link-normal.s-line-clamp-2.s-link-style.a-text-normal').then((ele) => {
return ele.evaluate((ele) => {
return `https://www.amazon.com${ele.getAttribute("href")}`
})
})
img.link = link
renderList.push(img)
}运行以下完整代码以获取已抓取的内容:
import puppeteer from 'puppeteer-core';
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOU_TOKEN&session_ttl=180&proxy_country=ANY';
(async () => {
try {
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL
});
const page = await browser.newPage();
await page.goto('https://www.amazon.com/');
await page.waitForSelector('#twotabsearchtextbox')
await page.type('#twotabsearchtextbox', 'iphone 15', { delay: 100 })
await page.click('#nav-search-submit-button')
await page.waitForSelector('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')
const list = await page.$$('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')
const renderList = []
for (const item of list) {
const img = await item.$('img').then((ele) => {
return ele.evaluate((ele) => {
const img = ele.getAttribute("src")
const title = ele.getAttribute("alt")
return { img, title }
})
})
const link = await item.$('.a-link-normal.s-line-clamp-2.s-link-style.a-text-normal').then((ele) => {
return ele.evaluate((ele) => {
return `https://www.amazon.com${ele.getAttribute("href")}`
})
})
img.link = link
renderList.push(img)
}
console.log(JSON.stringify(renderList))
} catch (e) {
console.error(e)
}
})();[
{
"img": "https://m.media-amazon.com/images/I/61WUSYIQdKL._AC_UY218_.jpg",
"title": "Apple iPhone 14, 256GB, Midnight - Unlocked (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-14-256GB-Midnight/dp/B0BN72MLT2/ref=sr_1_1?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-1"
},
{
"img": "https://m.media-amazon.com/images/I/51Af7V9jApL._AC_UY218_.jpg",
"title": "Apple iPhone 15 Plus, 256GB, Yellow - AT&T (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-Plus-256GB-Yellow/dp/B0CMT4WGB8/ref=sr_1_2?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-2"
},
{
"img": "https://m.media-amazon.com/images/I/71wtsuGLA4L._AC_UY218_.jpg",
"title": "15 ProMax Smartphone, 6+256GB Unlocked Phone, Android 13.0, 48+108MP Zoom Camera, Mobile Phone with Build-in Pen,Long Batt...",
"link": "https://www.amazon.com/15-ProMax-Smartphone-Unlocked-Titanium/dp/B0DK63Z84S/ref=sr_1_3?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-3"
},
{
"img": "https://m.media-amazon.com/images/I/71Xu6GSGm1L._AC_UY218_.jpg",
"title": "Apple iPhone 15 Pro, 128GB, Natural Titanium - Boost Mobile (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-128GB-Natural-Titanium/dp/B0DK7BCPH5/ref=sr_1_4?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-4"
},
{
"img": "https://m.media-amazon.com/images/I/61j3-75mrLL._AC_UY218_.jpg",
"title": "SZV 15 ProMAX 12+512GB Unlocked Cell Phone,Smartphone 6.85\" HD Screen Unlocked Phones,Battery 7000mAh Android 13,5G/Face I...",
"link": "https://www.amazon.com/SZV-Unlocked-Smartphone-Battery-Fingerprint/dp/B0DHDGNVP9/ref=sr_1_5?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-5"
}
]高级用户的高级功能
在进行大规模或复杂的网页抓取操作时,高级功能对于保持效率、克服障碍和扩展抓取任务至关重要。Scrapeless抓取浏览器提供了一系列强大的功能,以满足那些只需要基本抓取功能以外的专业用户的需求,还提供一些高级功能:
- 为特定用例自定义抓取参数
网页抓取的主要挑战之一是调整工具以精确提取所需内容,而不会生成冗余数据或错过机会。Scrapeless提供高级自定义选项,允许用户设置特定的抓取参数以适应其确切的用例。
- 处理CAPTCHA和反抓取保护
网站通常会部署CAPTCHA挑战和复杂的反抓取机制来阻止自动机器人。Scrapeless抓取浏览器是一个基于云的指纹浏览器,具有CAPTCHA解锁功能。这些高级解决方案不仅提高了数据收集速度,而且还降低了被具有强大反机器人措施的网站检测或阻止的可能性。
- 使用代理和轮换来提高可扩展性并避免IP封禁
扩展抓取操作通常会导致网站封禁IP并限制速率,从而中断数据收集。为了缓解这个问题,Scrapeless提供了一个强大的代理网络,包括IP轮换和代理池,以帮助您保持持续的大规模抓取而不会中断。Scrapeless提供了访问超过8000万个IP的庞大代理网络,这些IP来自200多个国家/地区,确保用户可以分发请求并避免IP封禁。
有效网页抓取的最佳实践
网页抓取是企业寻求从网络收集有价值数据的强大工具。但是,为了有效地提取数据并避免常见的陷阱,务必遵循最佳实践。通过利用Scrapeless等AI驱动的解决方案,企业可以增强其抓取策略,以确保准确性、合规性和可扩展性。以下是网页抓取最佳实践的细分,包括Scrapeless如何为您优化这些流程。
确保数据准确性和完整性
网页抓取的主要挑战之一是确保收集的数据准确无误。当从各种来源提取大型数据集时,很容易遇到数据丢失或不一致等问题。为了解决这个问题,Scrapeless中的AI算法可以自动分析网页结构并调整抓取方法以适应内容。
遵守法律和道德标准
随着对网页抓取的审查越来越严格,在法律和道德界限内运作至关重要。抓取工具必须了解隐私法、网站服务条款和GDPR等法规。Scrapeless通过集成智能robot.txt检测来帮助保持合规性,以确保抓取符合网站所有者设置的规则。
此外,AI可用于分析网页内容并过滤敏感或受保护的数据,确保企业避免不道德的行为。Scrapeless的AI算法旨在帮助用户遵守法律要求,帮助他们避免知识产权侵犯或隐私侵犯等风险。
避免被网站阻止
网站通常会部署反抓取措施来检测和阻止自动抓取工具。Scrapeless中的AI技术通过模拟人类浏览行为来帮助避免检测,使抓取请求看起来更自然。AI算法会调整请求频率、时间和标题以模仿真实用户的活动,从而大大降低被阻止的可能性。
此外,Scrapeless使用代理轮换,这是一个AI驱动的系统,可以自动在多个IP地址之间切换以分发请求。这有助于绕过速率限制并防止网站阻止单个IP地址发送过多请求。通过智能地使用基于AI的代理轮换,Scrapeless确保不间断的数据提取。
优化Scrapeless技术以进行大规模数据收集
对于从事大规模数据收集的企业而言,抓取效率和可扩展性至关重要。Scrapeless的AI功能会自动调整抓取策略,以确保最佳性能,即使是从复杂或大型网站提取数据也是如此。例如,Scrapeless的AI驱动爬虫可以处理动态内容,例如JavaScript密集型网站,使企业能够抓取传统工具可能难以处理的更广泛的内容。
此外,AI算法有助于优先处理最重要的数据,确保在处理大量信息时有效分配资源。这使得能够进行无缝的大量抓取,以满足业务需求,同时保持速度和性能。
遵循网页抓取最佳实践是最大化收集数据价值的关键。通过利用Scrapeless的AI驱动爬虫技术,企业可以提高数据准确性,确保法律合规性,避免被网站阻止,并优化大规模数据收集的爬取操作。借助Scrapeless,公司可以快速、高效且合乎道德地访问所需的数据,帮助他们在竞争激烈的、数据驱动的领域中保持领先地位。
常见网页抓取问题的故障排除
- 网站结构更改
- 问题:网站经常更新其布局或HTML结构,导致依赖于特定标签的抓取工具中断。
- 解决方案:使用动态技术构建灵活的抓取工具,或实施可以适应细微变化的错误处理。Scrapeless提供了一个智能的、AI驱动的抓取工具,可以检测更改并相应地进行调整。
- IP封锁
- 问题:网站限制来自单个IP地址的请求数量,在尝试过多次数后会阻止抓取工具。
- 解决方案:使用带有IP轮换的Scrapeless代理来跨多个IP分发请求,使网站更难以检测抓取模式并阻止访问。
- CAPTCHA和反抓取机制
- 问题:CAPTCHA和其他反机器人措施(如JavaScript挑战)可能会阻止您的抓取工具。
- 解决方案:利用Scrapeless Captcha求解器来自动解决CAPTCHA。对于JavaScript密集型页面,请使用Scrapeless抓取浏览器,它可以有效地处理动态内容。
- 速率限制
- 问题:网站限制特定时间段内的请求数量以防止服务器超载,导致抓取工具失败。
- 解决方案:使用代理和轮换以及速率限制控制设置您的抓取工具,以模拟人类行为并避免达到速率限制。
- 数据不准确或信息缺失
- 问题:由于抓取逻辑错误或数据解析不当,抓取会导致数据不完整或不准确。
- 解决方案:实施检查以验证抓取的数据并确保抓取工具已正确配置。Scrapeless使用AI驱动的算法来确保数据的完整性和一致性。
- 法律和道德问题
- 问题:抓取某些网站可能会违反服务条款或当地法律,从而导致法律后果。
- 解决方案:始终确保您遵守法律和道德标准。Scrapeless提供了一个内置框架,以帮助确保您的抓取活动保持在法律界限内。
有关网页抓取中更常见的挑战以及如何解决这些挑战,请阅读:如何解决网页抓取挑战 - 2025年完整指南
关于抓取网页的常见问题
1. 如何抓取网页?
最简单的方法是手动直接从网页复制所需数据并将其粘贴到文档中。
您还可以使用浏览器的开发者工具(例如Chrome的“检查”功能)来查看网页的HTML结构并从中提取数据。最简单的是使用Scrapeless之类的无代码工具,这些工具允许用户通过图形界面轻松设置抓取任务,而无需编写代码。
使用这些方法,您可以有效地抓取网页并提取所需数据。
2. 从网站抓取数据可以吗?
只要您遵守网站的服务条款、数据使用策略和当地法律,网页抓取就是合法的。在抓取之前,始终检查网站的robots.txt文件和服务条款。最好遵循速率限制并避免抓取个人或受版权保护的数据。
3. 如何从网站提取所有页面?
您可以使用网络爬虫来抓取网站的所有页面。这涉及从主页或其他关键页面递归访问所有链接。Scrapeless抓取浏览器或Scrapeless API之类的工具可以自动化此过程,根据网站的结构从每个页面提取数据。
4. 使用什么工具进行网页抓取?
常见的网页抓取工具包括Scrapeless、BeautifulSoup、Selenium、Octoparse和Scrapy。这些工具允许用户通过发送请求、解析HTML内容并以CSV、JSON或Excel等结构化格式提供数据来自动化从网站提取数据的过程。
5. 你可以通过网页抓取赚钱吗?
是的,您可以通过为企业提供数据提取服务 、进行市场调查或为客户抓取公开数据来通过网页抓取赚钱。网页抓取还可以用于收集数据以进行竞争分析、潜在客户开发或构建对电子商务、房地产和金融等行业有价值的专业数据库。
结论:为什么Scrapeless是网页抓取的未来
Scrapeless提供了一个强大的AI驱动解决方案,以简化网页抓取任务,为开发人员和企业带来巨大的好处。凭借其尖端功能,Scrapeless确保您的数据收集高效、准确且可扩展:
- AI抓取:利用AI来提高抓取效率并处理复杂、动态的内容。
- 快10倍:优化的浏览器操作使其比传统的抓取方法快10倍。
- 绕过CAPTCHA和反抓取:自动绕过CAPTCHA和其他反机器人保护。
- 可自定义的抓取:自定义抓取参数以满足特定需求和用例。
- 自动化工作流程:AI驱动的自动化减少了人工干预并简化了数据收集。
无论您是寻求提高抓取效率的开发人员,还是寻求大规模收集结构化数据的企业,Scrapeless都能提供全面的解决方案来满足您的需求。不要让网页抓取的复杂性拖慢您的速度 - 从今天开始使用Scrapeless,释放无缝、AI驱动的网页数据提取的潜力。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


