
2025年五大网页数据采集工具
Senior Web Scraping Engineer
网页数据收集的目标是从最初分散且难以直接使用信息中提取信息,并将其组织成有用的数据格式,然后用于回答业务问题、增强算法以及与其他公司竞争。
如何轻松精确地从网站收集数据?
这篇博客将向您介绍5个最佳的网页数据收集工具。开始阅读,获取最佳工具!
五大网页数据收集工具
- #1. Scrapeless:一个全面的数据收集器。
- #2. Mention:一个有用的新闻监控和关键词提醒工具。
- #3. SurveyMonkey:轻松收集客户、员工和市场洞察。
- #4. Lead411:精确的销售情报平台。
- #5. Magpi:一个功能齐全的移动优先数据收集系统。
什么是网页数据收集?
网页数据收集,也称为网页抓取或数据爬取,是指通过自动化工具从互联网提取结构化或非结构化数据的过程。
网页数据收集通常使用爬虫模拟用户访问网站,并通过解析网页内容来提取所需数据。
例如,可以收集电子商务平台的产品价格、库存信息和用户评论,或者收集社交媒体上的热门话题和用户互动数据。这些数据可用于各种场景,例如市场研究、竞争分析、业务决策、SEO优化或人工智能训练模型。
企业希望通过网页数据收集实现什么?
网页数据收集使企业能够利用网上大量可用的信息,从而获得可操作的见解并推动战略决策。
通过系统地收集和分析这些数据,企业旨在实现几个关键目标:
- 市场分析和趋势预测
企业使用网页数据来监控行业趋势、消费者偏好和市场需求。这有助于他们通过适应新兴趋势并相应地调整产品或服务来领先于竞争对手。
- 竞争对手情报
通过从竞争对手网站收集数据(例如,定价、产品供应和营销策略),公司可以识别市场中的差距,优化自身的策略,并保持竞争优势。
- 客户洞察
网页数据收集使企业能够分析客户行为、评论和反馈。这有助于了解消费者的痛点、偏好和期望,最终提高客户满意度和忠诚度。
- 动态定价策略
电子商务平台和零售商使用实时网页抓取来跟踪竞争对手的定价并动态调整自身的定价,确保他们在保持竞争力的同时最大限度地提高利润率。
- 内容优化
企业收集有关热门关键词、趋势话题和受众参与指标的数据,以优化其内容的SEO并提高其在线可见性。
- 风险管理
公司使用网络数据收集来监控潜在风险,例如法规变化、声誉问题或供应链中断。这使他们能够采取主动措施并有效地减轻风险。
- AI和机器学习数据
企业收集大型数据集来训练AI模型并增强机器学习算法。例如,抓取图像、文本或语言数据有助于改进基于AI的解决方案,例如推荐系统或预测分析。
五大最佳网页数据收集工具
评估标准
提供关于排名方法的透明度。一些标准可能包括:
- 效率: 数据收集的速度和准确性。
- 反屏蔽功能: 绕过反抓取措施的能力。
- 用户体验: 易用性、直观的UI和设置时间。
- 兼容性: 支持的语言、平台和集成。
- 成本效益: 基于功能和定价的物有所值。
- 法律合规性: 遵守GDPR和CCPA等数据隐私法。
#1. Scrapeless
Scrapeless 作为最佳的网页数据收集工具脱颖而出,提供无与伦比的可靠性、经济性和易用性。Scrapeless旨在满足现代数据抓取的需求,它将尖端技术与一套集成功能相结合,使其成为任何数据收集挑战的一体化解决方案。
为什么超过两千家企业使用Scrapeless进行数据收集?
- 经济实惠的定价: Scrapeless旨在提供卓越的价值。
- 稳定性和可靠性: Scrapeless凭借其久经考验的业绩,即使在高工作负载下也能提供稳定的API响应。
- 高成功率: 向提取失败说再见,Scrapeless承诺99.99%成功访问网页数据。
- 可扩展性: 多亏了Scrapeless背后的强大基础设施,您可以轻松处理数千个查询。
Scrapeless的与众不同之处在于其令人印象深刻的稳定性和高成功率,确保平稳和不间断的运营。其经济实惠的定价使其能够为各种规模的企业所用,而其用户友好的界面即使是非技术用户也能轻松上手。此外,Scrapeless以其快速的响应时间而闻名,可在各种抓取场景中提供无缝的性能。
该平台的真正力量在于其集成功能:网页解锁器、抓取浏览器、抓取API、验证码求解器和内置代理,所有这些功能协同工作,轻松处理复杂的网页抓取任务。Scrapeless采用先进的反检测技术,避免99.99%的反机器人检测和网络限制,为用户提供可靠高效的解决方案来绕过最棘手的障碍。
#2. Mention
Mention是一个媒体监控平台,允许初创公司跟踪网络上的品牌提及和情绪。功能包括新闻监控、关键词提醒和影响者发现。
Mention使小型初创公司能够通过易于使用且经济实惠的监控解决方案来掌握有关其品牌的在线对话。洞察力有助于团队与潜在客户和影响者互动。
#3. SurveyMonkey
SurveyMonkey为初创公司提供了一个易于使用的在线调查平台,用于收集客户、员工和市场洞察。功能包括调查构建、分发、分析工具和集成。
SurveyMonkey使初创公司能够在无需广泛专业知识的情况下创建和管理反馈调查。经济实惠的计划提供强大的功能和支持。
#4. Lead411
Lead411提供了一个销售情报平台,专为希望扩大其渠道的初创公司量身定制。主要功能包括潜在客户和公司数据、电子邮件查找工具和实时提醒。
Lead411为销售团队提供了一种轻松识别潜在客户并增强外联营销活动的方法。具有竞争力的入门级定价消除了早期增长的障碍。
#5. Magpi
Magpi是一个移动优先数据收集系统,专为初创公司和小型研究团队量身定制。功能包括表单、调查、离线数据捕获、分析和数据集管理。
Magpi为组织提供了一种无需广泛内部专业知识即可在现场收集见解的方法。基本计划提供高级功能,以支持各种用例。
抓取API:最佳的网页数据收集方法
许多网站和平台提供API,允许开发人员以结构化格式访问特定数据。API可靠、高效,并且通常包括实时更新。示例包括Twitter API、Google SERP API和电子商务API。
但是,它们可能存在一些限制,例如速率限制或有限的数据访问,并且通常比网站直接提供的API更昂贵。
幸运的是,一些第三方抓取API价格实惠,并且具有高度的稳定性和成功率(例如Scrapeless)。
Scrapeless提供了一个可靠且可扩展的网页抓取平台,价格具有竞争力,为其用户确保卓越的价值:
- 抓取浏览器: 每小时0.09美元起
- 抓取API: 每1000个URL 0.80美元起
- 网页解锁器: 每1000个URL 0.20美元
- 验证码求解器: 每1000个URL 0.80美元起
- 代理: 每GB 2.80美元
通过订阅,您可以享受每项服务高达20%的折扣。您有特殊要求吗?立即联系我们,我们将根据您的需求提供更大的节省!
让我们弄清楚为什么Scrapeless抓取API对数据收集有效。请按照我的步骤抓取Google搜索数据。
步骤1. 登录Scrapeless仪表板,然后转到“Google搜索API”。
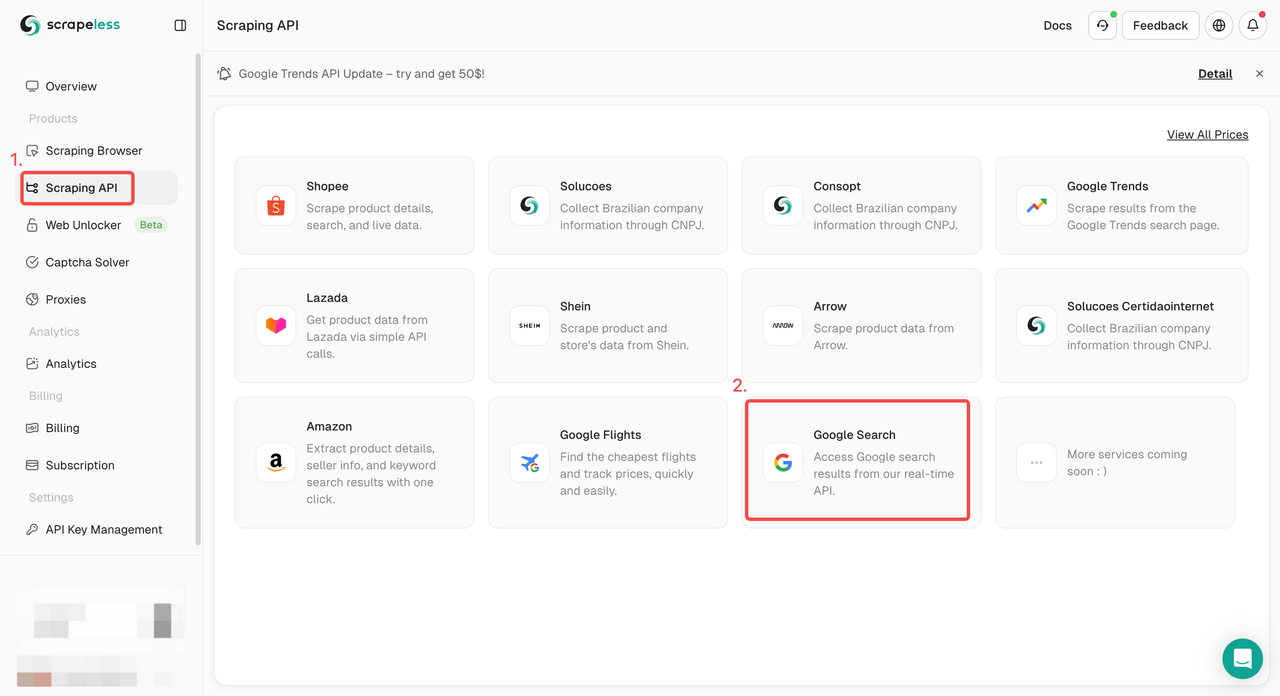
步骤2. 在左侧配置您需要的关键词、地区、语言、代理和其他信息。确保一切正常后,单击“开始抓取”。
q: 参数定义您要搜索的查询。gl: 参数定义要用于Google搜索的国家/地区。hl: 参数定义要用于Google搜索的语言。
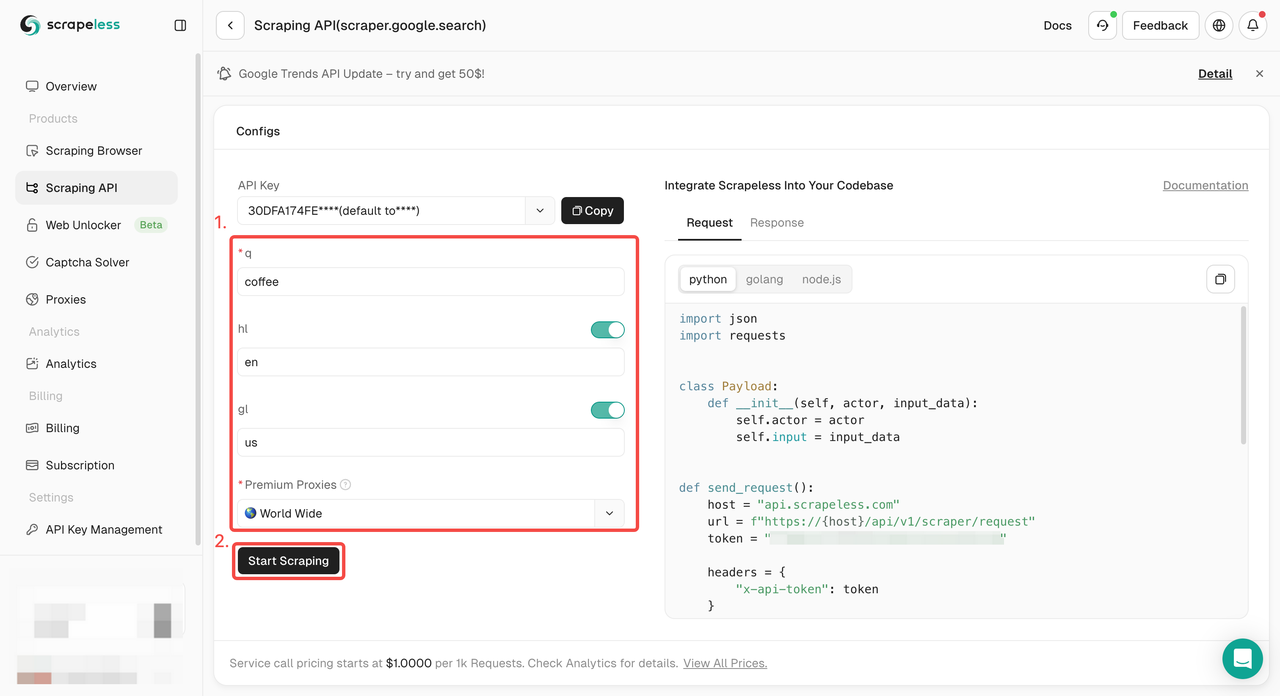
步骤3. 获取抓取结果并导出它们。
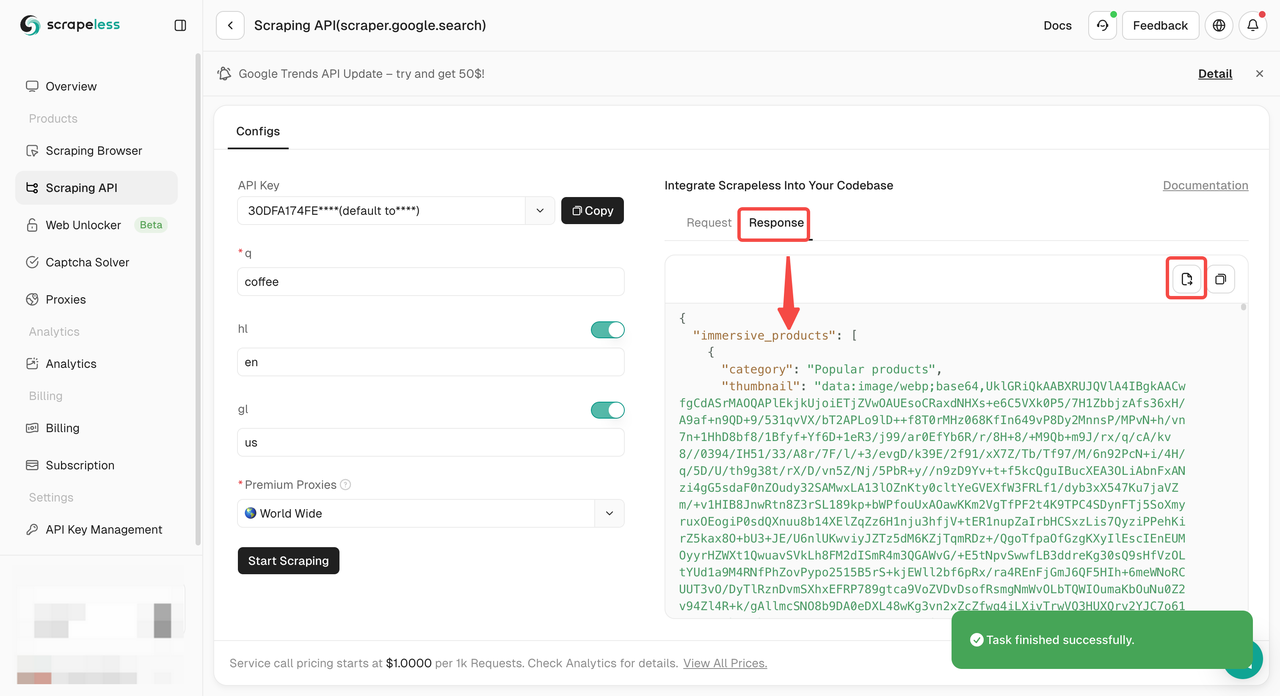
只需要集成到项目中的示例代码?我们为您准备好了!或者您可以访问我们的API文档以获取您需要的任何语言。
- Python:
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}为什么越来越多的公司使用数据收集工具?
- 提高效率和生产力: 数据为组织创造了一个至关重要的反馈循环。例如,广告技术行业的公司可以使用网页数据来自动验证广告文案、链接位置和图像,确保正确的广告到达合适的受众,从而消除人工检查并优化结果。📈
- 更快、更有效的决策: 实时网页数据收集使公司能够做出关键的、即时的决策。例如,投资公司可以收集有关股票交易量或社会情绪的数据,以做出更好的买卖决策。💡
- 更好的财务业绩: 公司可以通过分析网络流量、关键词和搜索趋势来提高盈利能力,从而更好地定位产品和品牌,并更有针对性地进行潜在客户开发。💰
- 识别和创造新的产品和服务收入: 通过数据驱动的市场研究,公司可以提高盈利能力。例如,分析竞争格局的公司可能会通过消费者评论和反馈来识别未满足的消费者需求。📊
- 改进的客户体验: 企业可以使用网页数据进行网站和用户体验测试,确保广告、内容和应用程序根据地域用户数据按预期执行。🌐
- 竞争优势: 网页数据允许公司通过比较实时定价和套餐优惠来获得竞争优势。旅游业就是一个很好的例子,在线旅行社 (OTA) 使用数据收集来创建动态定价策略,从而削弱竞争对手。🏆
找到您最好的数据收集工具!
无论是调查网站还是编制合规报告,这些网页抓取工具都可以帮助您轻松地从合适的人那里收集所需的信息。本文中的五个工具每个都有不同的应用场景。
但是,为了避免重复选择和调用,您可以直接使用Scrapeless!它是一个强大的数据收集工具包。凭借其先进的AI工具和JS渲染,您可以轻松准确地获得所需的数据。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


