
Python网络爬虫:2025年分步指南
Advanced Data Extraction Specialist
随着数据量的剧增,网络爬虫已成为数据科学、市场调研和竞争分析等领域的重要工具。在众多编程语言中,Python凭借其简洁的语法和强大的库支持,成为开发网络爬虫(Python网络爬虫)的首选语言。无论是从电商平台提取数据,还是收集新闻网站的最新文章,Python网络爬虫都能高效完成任务。本文将提供一个2025版本的循序渐进指南,帮助你掌握如何使用Python构建功能强大的网络爬虫,从基础知识到高级技巧,全面提升你的网络爬虫能力。
Python网络爬虫及其在数据提取中的重要性
网络爬虫是一个自动化程序,它根据特定规则从互联网上抓取信息。它通过模拟浏览器访问网页,提取所需数据并将其存储在本地。这个过程通常包括选择初始URL、下载网页内容、解析HTML、跟踪链接以及重复此过程以获取更多数据。网络爬虫在数据提取中起着至关重要的作用,因为它可以高效地从大量网页中收集信息,并支持搜索引擎索引构建和数据分析任务。
Python网络爬虫的优势
使用Python编写网络爬虫有很多优势,尤其是在灵活性和易用性方面。首先,Python的语法简洁易学,允许开发人员快速入门并实现复杂的爬取逻辑。其次,Python拥有丰富的库和框架,例如Scrapy和BeautifulSoup,它们极大地简化了网页解析和数据提取的过程。此外,Python的跨平台特性允许爬虫在不同的操作系统上运行,从而提高了开发和部署的灵活性。
💡 相关阅读:2025年使用Python进行网络抓取
Python网络爬虫的高级技巧
在开发Python网络爬虫时,有几种高级技巧可以增强你的网络抓取能力,尤其是在处理动态内容和反爬措施时。这些策略对于克服构建Python网络爬虫时经常遇到的挑战至关重要,例如JavaScript渲染、CAPTCHA解决和IP封锁。以下是一些关键策略:
- 处理动态网页:
- 使用Selenium:这个库允许你自动化浏览器操作,使你能够在提取数据之前等待JavaScript内容加载。
- 执行Ajax请求:在浏览器的开发者工具中分析网络请求以识别API端点。使用Python中的requests库向这些端点发送直接请求,以更有效地检索数据。
- 绕过反爬措施:
- 使用代理:实现轮换代理IP以将请求分布在多个IP地址上,使网站更难以检测和阻止你的抓取活动。
- 模拟User-Agent:修改请求头中的User-Agent字符串以模拟流行的浏览器。这有助于降低被标记为机器人的可能性。
- 提高效率:
- 实现异步编程:使用asyncio和aiohttp等库进行并发请求,显著加快数据提取过程。
- 利用XPath或CSS选择器:这些工具允许精确地定位HTML元素,提高数据提取的准确性和效率。
设置你的Python网络爬虫环境
在开始设置你的网络爬虫环境之前,你需要准备一些基本环境:
- Python 3+:下载安装程序,双击它,然后按照安装向导进行操作。
- Python IDE:Visual Studio Code或PyCharm以及Python扩展。
然后,在终端中输入以下命令来初始化一个名为python-crawler的项目:
mkdir python-crawler
cd python-crawler
python -m venv env在进行网络爬虫时,我们需要使用两个库来进行HTTP请求和HTML解析。Python中最流行的两个库是:
- requests:一个强大的HTTP客户端库,可以发送HTTP请求并处理响应。
- beautifulsoup4:一个功能全面的HTML和XML解析器。
在终端中输入以下命令来安装它们:
pip install beautifulsoup4 requests在项目文件夹中,创建crawler.py并导入项目依赖项:
import requests
from bs4 import BeautifulSoup项目已构建完成,让我们开始爬取网页。
如何使用Python抓取亚马逊数据
抓取亚马逊的数据可以获得有关产品信息、评论和趋势的内容。但是,亚马逊的反爬措施,例如CAPTCHA和IP速率限制,使这个过程具有挑战性。在本指南中,我们将逐步指导你如何使用Python抓取亚马逊数据。
如何在Python中构建简单的网络爬虫
按照上述步骤设置网站爬取环境后,你需要按照以下步骤在Python中创建一个简单的网络爬虫。
**步骤1:**使用Requests和BeautifulSoup的基本网络爬虫
代码示例
import requests
from bs4 import BeautifulSoup
class SimpleWebCrawler:
def __init__(self, start_url):
self.start_url = start_url
self.visited_urls = set()
self.urls_to_visit = [start_url]
def crawl(self):
while self.urls_to_visit:
current_url = self.urls_to_visit.pop(0)
if current_url in self.visited_urls:
continue
print(f"Crawling: {current_url}")
response = requests.get(current_url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
self.visited_urls.add(current_url)
self.extract_links(soup)
def extract_links(self, soup):
for link in soup.find_all('a', href=True):
absolute_link = link['href']
if absolute_link not in self.visited_urls and absolute_link not in self.urls_to_visit:
self.urls_to_visit.append(absolute_link)
if __name__ == "__main__":
crawler = SimpleWebCrawler("https://example.com")
crawler.crawl()解释
- 初始化:SimpleWebCrawler类使用起始URL进行初始化,并设置跟踪已访问的URL和要访问的URL。
- 爬取逻辑:crawl方法处理urls_to_visit列表中的URL,获取每个页面的内容。
- 链接提取:extract_links方法查找页面上的所有超链接,如果它们尚未被访问,则将它们添加到要访问的URL列表中。
**步骤2:**使用Scrapy进行更复杂的爬取
如果你的项目需要更高级的功能,例如同时处理多个请求或高效地抓取大型网站,请考虑使用Scrapy。
基本的Scrapy示例
import scrapy
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = ['https://example.com']
def parse(self, response):
for link in response.css('a::attr(href)').getall():
yield response.follow(link, self.parse)运行Scrapy
你可以使用命令行运行你的Scrapy爬虫:
scrapy crawl my_spider如何使用Python抓取亚马逊数据
接下来,本节将详细介绍如何使用Python抓取亚马逊数据。
步骤1. 首先,我们需要获取产品页面并使用get方法发出请求:
url = "https://www.amazon.com/Breathable-Athletic-Sneakers-Comfortable-Lightweight/dp/B0CMTJ7JS7/?_encoding=UTF8&pd_rd_w=XsBL5&content-id=amzn1.sym.61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_p=61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_r=8M3TP83H0CZQD08XHGBR&pd_rd_wg=6d3lc&pd_rd_r=a6a366f4-4ec7-491f-87ec-67672fe48a55&ref_=pd_hp_d_btf_cr_simh&th=1"
response = requests.get(url)response.content包含服务器生成的HTML文档。这将被馈送到BeautifulSoup,并且html.parser选项允许你指定库将使用的解析器:
soup = BeautifulSoup(response.content, "html.parser")**步骤2.**接下来,我们需要获取我们想要抓取的数据。我们可以使用CSS选择器来获取相应的元素。
BeautifulSoup提供了两种方法,select和select_one,它们都支持CSS选择器策略。
在编写代码之前,你可以打开开发者工具来查看元素的CSS。
- 获取产品标题:
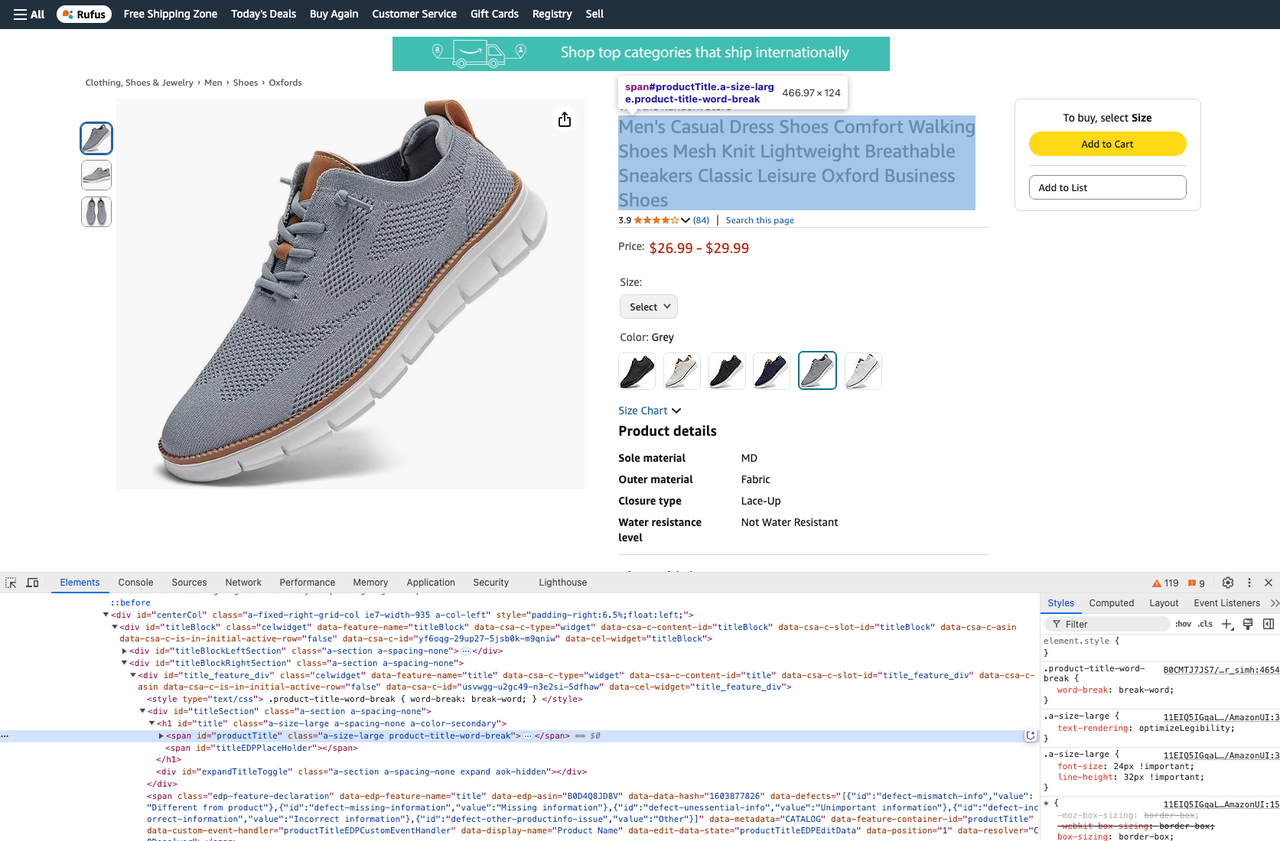
product_title = soup.select_one("#productTitle").text- 获取产品描述:
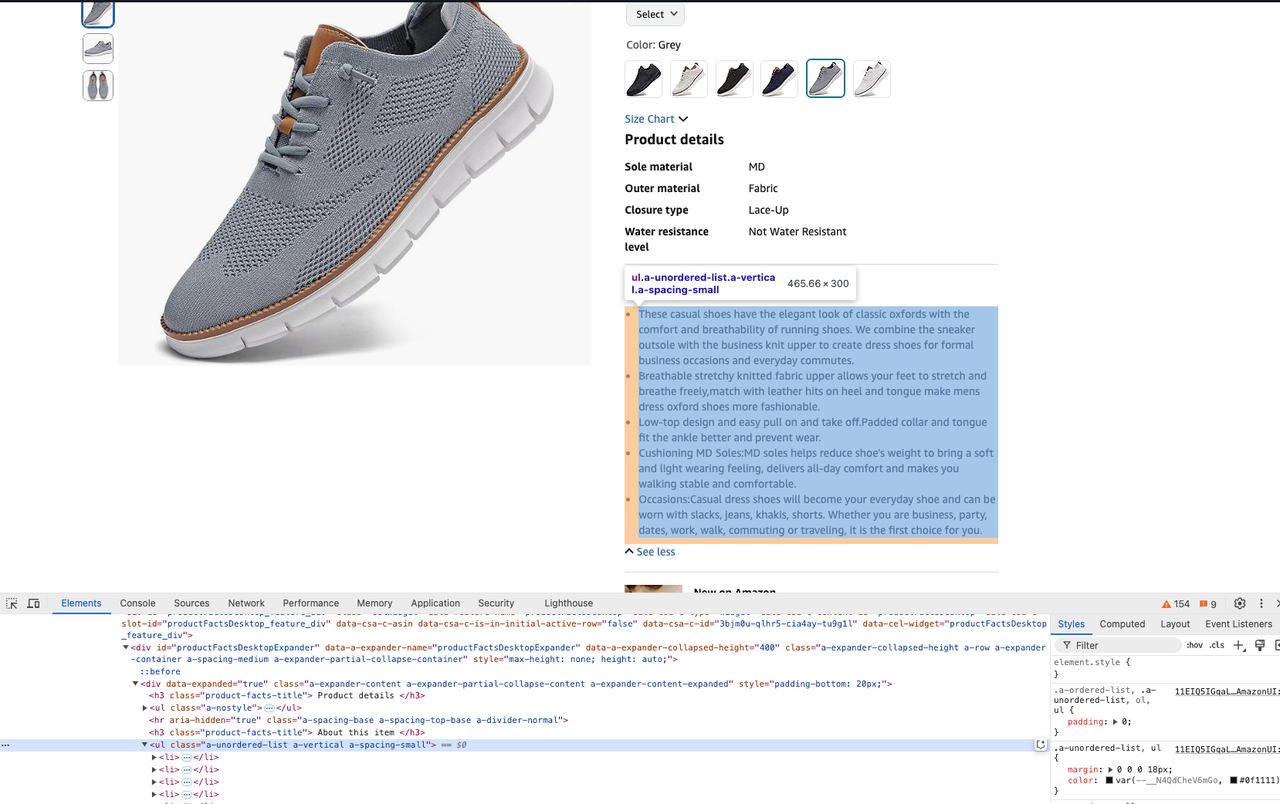
description = soup.select_one("#productFactsDesktopExpander ul.a-unordered-list").text- 获取产品的价格:
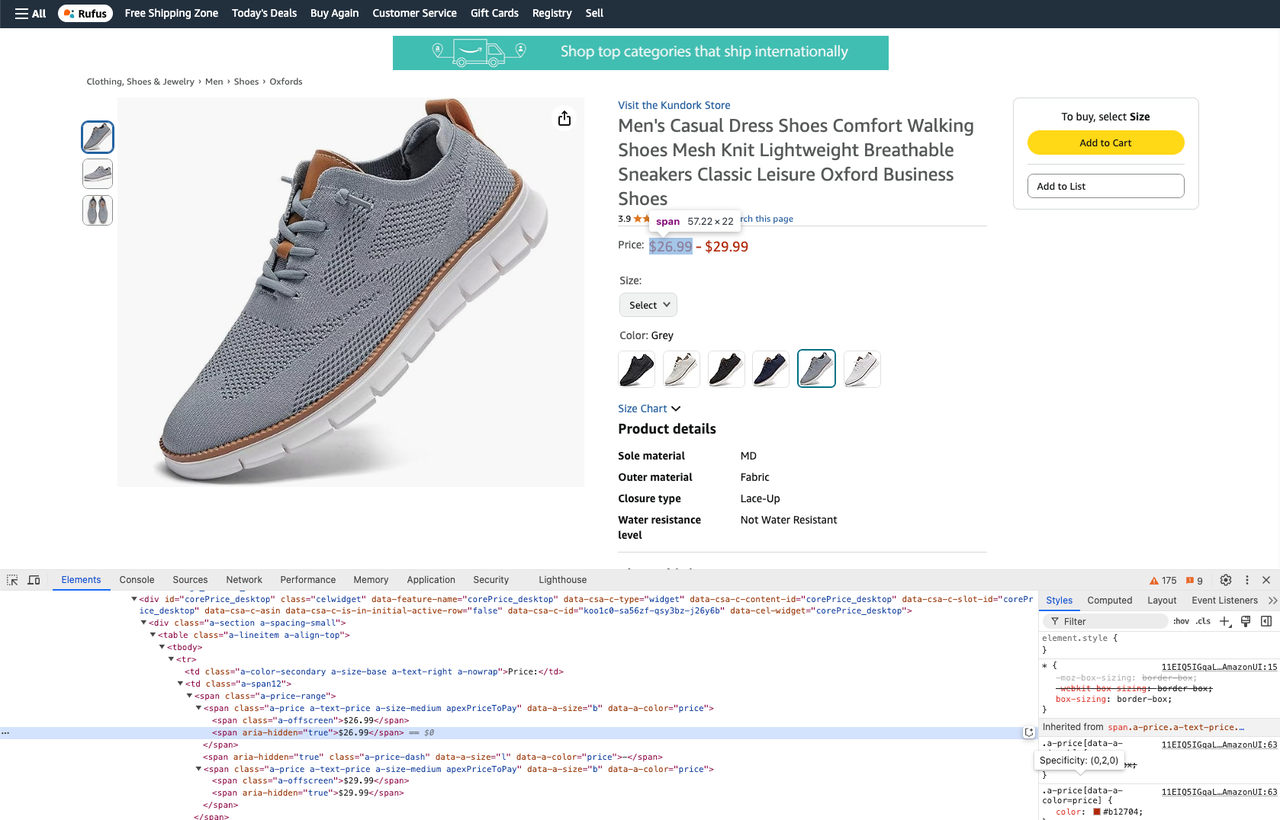
prices = soup.select_one(".a-price-range")
real_price = prices.select(".a-offscreen")
min_price = real_price[0].text
max_price = real_price[1].text- 获取产品评论:
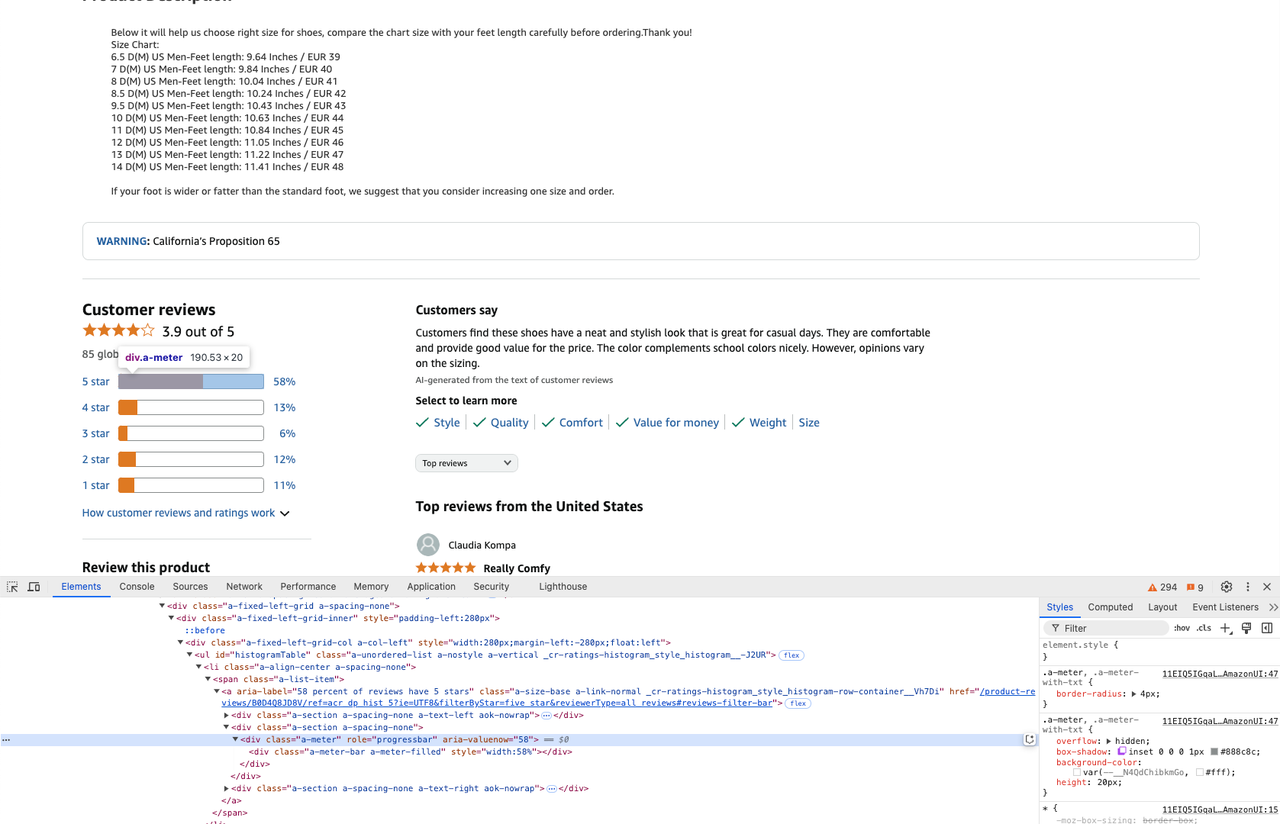
star_info = soup.select('.a-meter[role=progressbar]')
five_star = star_info[0].attrs['aria-valuenow'] + '%'
four_star = star_info[1].attrs['aria-valuenow'] + '%'**步骤3.**现在我们已经爬取了网站并获得了我们想要的数据,我们可以将爬取的信息提取到csv文件中。
为此,请将以下内容添加到文件的顶部:
import csv将爬取的数据写入csv文件:
with open("product.csv", "w") as csv_file:
writer = csv.writer(csv_file)
writer.writerow([
"product_title",
"description",
"min_price",
"max_price",
"five_star",
"four_star"
])
writer.writerow([
product_title,
description,
min_price,
max_price,
five_star,
four_star
])在终端中运行以下命令来执行爬取命令:
python crawler.py**步骤4.**执行完成后,我们可以看到product.csv文件出现在你的文件夹中。打开此文件,我们可以看到我们爬取的数据结果:

完整的代码如下:
import csv
import requests
from bs4 import BeautifulSoup
url = "https://www.amazon.com/Breathable-Athletic-Sneakers-Comfortable-Lightweight/dp/B0CMTJ7JS7/?_encoding=UTF8&pd_rd_w=XsBL5&content-id=amzn1.sym.61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_p=61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_r=8M3TP83H0CZQD08XHGBR&pd_rd_wg=6d3lc&pd_rd_r=a6a366f4-4ec7-491f-87ec-67672fe48a55&ref_=pd_hp_d_btf_cr_simh&th=1"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
product_title = soup.select_one("#productTitle").text
description = soup.select_one("#productFactsDesktopExpander ul.a-unordered-list").text
prices = soup.select_one(".a-price-range")
real_price = prices.select(".a-offscreen")
min_price = real_price[0].text
max_price = real_price[1].text
star_info = soup.select('.a-meter[role=progressbar]')
five_star = star_info[0].attrs['aria-valuenow'] + '%'
four_star = star_info[1].attrs['aria-valuenow'] + '%'
with open("product.csv", "w") as csv_file:
writer = csv.writer(csv_file)
writer.writerow([
"product_title",
"description",
"min_price",
"max_price",
"five_star",
"four_star"
])
writer.writerow([
product_title,
description,
min_price,
max_price,
five_star,
four_star
])Scrapeless的亚马逊抓取API如何简化你的网络爬虫任务
Scrapeless的亚马逊抓取API旨在自动化并简化从亚马逊提取数据的过程,使其成为开发人员和企业的宝贵工具。与使用Python网络爬虫方法不同,后者通常需要大量的代码编写和处理各种挑战,例如IP轮换或CAPTCHA绕过,Scrapeless API简化了这个过程。它提供了一系列增强效率的功能,使用户可以轻松收集数据,例如产品价格、评论和描述,而无需复杂的Python脚本。
除了亚马逊抓取API,Scrapeless还包括Shopee抓取API,Lazada抓取API,谷歌趋势抓取API,谷歌航班抓取API,谷歌搜索抓取API,Airbnb抓取API等等,为网络数据提取提供了一个全面的解决方案。
准备好轻松开始抓取了吗?
立即注册Scrapeless并获得免费试用,体验我们API的强大功能。解锁从亚马逊、Shopee等顶级电商平台无缝提取数据的便捷性。不要错过——立即开始吧!
与手动Python网络爬虫相比的优势
1. 自动化和效率
亚马逊抓取API自动化了整个数据提取过程,确保用户可以快速准确地收集大量数据。这消除了通常需要用于手动Python网络爬虫的复杂编码,后者通常涉及处理各种挑战,例如动态内容和反爬措施。
2. 内置基础设施
使用Scrapeless的API,用户可以受益于强大的基础设施,该基础设施自动处理代理管理、IP轮换和CAPTCHA解决。相比之下,手动Python网络爬虫需要开发人员自己实现这些功能,这既费时又容易出错。
3. 无代码接口
API提供了一个无代码接口,允许用户通过简单的API调用启动抓取任务。这比编写和调试Python网络爬虫的代码要容易得多,因此不同技能水平的用户都可以使用它。
通过API高效提取亚马逊数据
使用Scrapeless的亚马逊抓取API,用户可以通过以下步骤轻松提取结构化数据:
-
API密钥生成:注册Scrapeless并生成你的唯一API密钥。
-
点击抓取API并选择亚马逊。
-
定义你的需求:指定你想要抓取的数据类型(例如,产品详细信息、评论)。
-
点击开始抓取:使用简单的API调用从亚马逊请求数据。
-
接收结构化数据:Scrapeless API以各种格式(例如,JSON)提供收集的数据,以便进行分析或集成到你的系统中。
通过利用Scrapeless的亚马逊抓取API,用户可以大大简化他们的网络抓取任务,使他们能够专注于分析见解,而不是管理网络抓取的复杂性。这个强大的工具不仅提高了生产力,而且确保遵守数据保护法规,使其成为希望在市场研究工作中获得竞争优势的企业的理想选择。
如果你需要将Scrapeless集成到自己的项目中,可以参考我们的示例代码。你也可以点击此处查看完整文档。
请求示例 - 产品
import requests
import json
url = "https://api.scrapeless.com/api/v1/scraper/request"
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)请求示例 - 卖家
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "",
"action": "seller"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))请求示例 - 关键词
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"action": "keywords",
"keywords": "iPhone 12",
"page": "5",
"domain": "com"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))立即加入Scrapeless Discord社区!
关注每周新闻,独家更新,并参与激动人心的活动,有机会赢取积分。不要错过乐趣——立即参与行动!
关于Python网络爬虫的常见问题
常见问题#1:Python中网络爬虫和网络抓取器有什么区别?
网络爬虫和网络抓取器在数据提取领域有不同的用途。网络爬虫主要关注发现;它浏览网站以查找和索引URL,基本上是创建互联网或特定网站的地图。网络爬虫的输出通常是一个URL列表。相比之下,网络抓取器从这些URL中提取特定数据,例如产品详细信息或价格信息。虽然这两个过程都涉及下载HTML内容,但爬虫的目标是收集链接,而抓取器的目标是从这些页面中过滤和提取相关数据点。
常见问题#2:使用Python构建网络爬虫时如何处理CAPTCHA?
处理CAPTCHA是使用Python构建网络爬虫最具挑战性的方面之一,因为它专门设计用于防止自动化访问。以下是处理CAPTCHA的一些有效策略:
- 使用无头浏览器:无头浏览器结合Puppeteer或Playwright等工具可以帮助绕过CAPTCHA,方法是模拟真实的浏览器行为。
- 避免触发CAPTCHA:
2.2 随机化请求头(例如,用户代理)并在请求之间引入延迟以模拟人类活动。
虽然这些方法可以帮助绕过CAPTCHA,但始终确保你的行为符合网站的服务条款和法律要求。
常见问题#3:使用Python从亚马逊等网站抓取数据是否合法?
网络抓取的合法性取决于多种因素,尤其是在针对亚马逊等电商平台时。以下是一些关键注意事项:
- robots.txt合规性:网站通常包含一个文件,该文件概述了可以抓取网站的哪些部分。虽然忽略它本身并不违法,但这可能被认为是不道德的或违反最佳实践的。
- 公平使用和公共数据:如果数据是公开可访问的,并且用于非商业目的(例如学术研究),则它可能属于某些司法管辖区内的“公平使用”。但是,这并非一定如此。
为避免法律问题:
- 在抓取数据之前,始终检查网站的服务条款。
- 如果可能,请征求许可。
- 使用合法的网站抓取API,例如Scrapeless。
结论
在本文中,我们探讨了Python网络爬虫的重要性,特别是它在电商数据爬取中的广泛应用。作为一种灵活而强大的编程语言,Python提供了丰富的库和工具,可以帮助开发人员高效地从电商平台爬取数据,并获得关键数据,例如产品信息、价格和评论。但是,手动编写和维护网络爬虫通常需要花费大量的时间和精力,尤其是在遇到复杂的反爬机制时。
在此背景下,Scrapeless的亚马逊抓取API提供了一种高效的替代方案。对于需要爬取大规模电商数据的用户,Scrapeless API不仅简化了爬取过程,而且还自动处理各种复杂的问题,帮助用户节省时间和精力,轻松获取所需亚马逊数据。无论是小型企业还是大规模数据需求,Scrapeless都是理想的选择。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


