
如何使用 Playwright 绕过 Cloudflare
Advanced Data Extraction Specialist
使用无头浏览器进行网页抓取时,您的抓取器是否仍然被阻止?本指南将向您展示如何通过改进 Playwright 的掩码来绕过 Cloudflare。
Cloudflare:它是什么?
Bot Management 是安全和性能优化提供商 Cloudflare 提供的一项服务,对于许多抓取器来说,它是一个噩梦。大约五分之一的网站使用 Web 应用程序防火墙 (WAF),这些防火墙通常会识别并阻止抓取器。Playwright 和 Selenium 等无头浏览器属于此类。
Cloudflare 如何运作
Cloudflare 使用多种技术来比较和分离由机器人和真实用户生成的流量:
行为分析: 它监控用户与网站交互的几个方面,包括点击、鼠标移动和页面加载时间。
IP 声誉分析: 每个请求的 IP 地址都与数据库进行比较,以确定它是否被用于抓取。
用户代理分析: 字符串用作识别发出网站请求的浏览器或设备的一种手段。Cloudflare 可以识别抓取器使用的通用或可立即识别的用户代理字符串。
CAPTCHA 测试: 系统可以选择确定向网站提交请求的用户是机器人还是人类。如果用户通过验证,则请求将被批准。否则,它将被禁止。
请求速率分析: 使用此技术,可以跟踪发送到网站的查询量,并发现自动机器人的特征趋势。例如,机器人通常会在短时间内发送大量请求。
为什么使用基本 Playwright 不足以绕过 Cloudflare
基本使用 Playwright 可能无法绕过 Cloudflare 的反机器人防御。原因?虽然可以使用此工具或其他浏览器自动化工具模拟类似人类的浏览行为来克服某些困难,但更复杂的方法(例如使用代理和自定义用户代理)可能需要额外的努力才能克服。
为了演示这一点,让我们启动一个 NodeJS Playwright 项目,看看它如何在 Cloudflare 上无法正常工作。
步骤 1:验证您的计算机上是否已安装 npm 和 Node.js。
步骤 2:导航到所需的目录后,使用此命令启动一个新项目:
language
npm init步骤 3:现在使用以下命令将 Playwright 安装为依赖项。
language
npm install playwright步骤 4:很棒的工作!现在您可以开始使用 Playwright 了。在您的项目目录中创建一个扩展名为 .js 的新文件,例如 scraper.js。在其中,构建一个脚本以访问 https://crozdesk.com 并抓取屏幕截图。
language
const playwright = require("playwright");
async function scraper() {
const browser = await playwright.chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto("https://crozdesk.com");
await page.waitForTimeout(1000);
await page.screenshot({ path: "screenshot.png", fullPage: true });
await browser.close();
}
scraper();如您在第四行中所见,我们的抓取器使用 Chromium 作为浏览器,但您可以随意使用其他浏览器。
步骤 5:使用此命令运行整个代码:
language
node scraper.js这是结果:
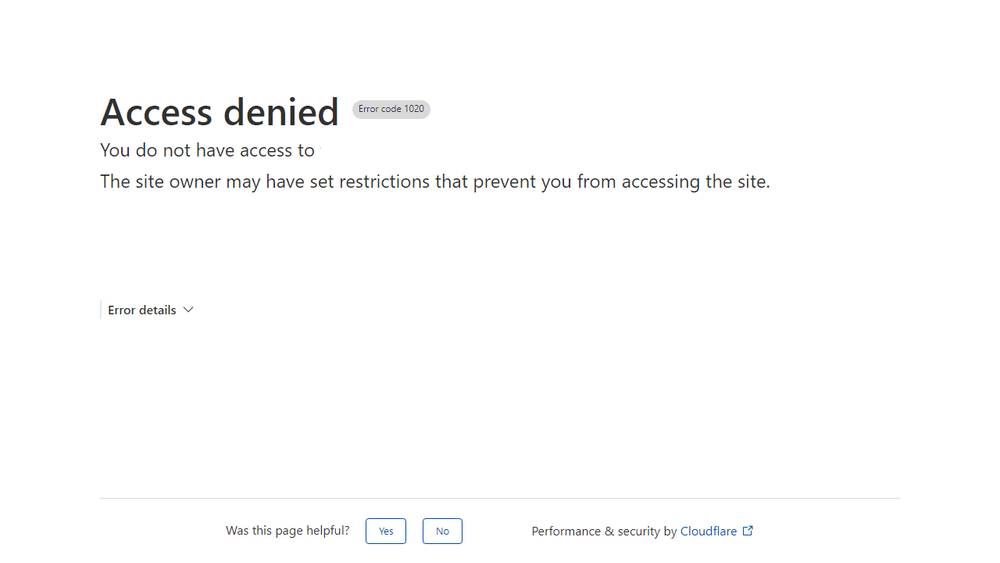
不幸的是,Playwright 的简单版本被标记为机器人,然后被阻止访问该网站。
在下一部分中,我们将介绍一些策略,这些策略将帮助您绕过 Cloudflare。继续阅读!
如何通过掩盖 Playwright 来绕过 Cloudflare
让我们看看几种处理 Cloudflare 检测技术的策略。通常,要使您的脚本起作用,可能需要组合使用这些策略。
方法 1:复制人类行为
为了使自动化浏览器看起来更像人类,您可以向我们之前 Playwright 抓取器代码中添加随机暂停、滚动和其他与网站的交互。
方法 2:使用代理
如果您在短时间内发送了太多查询,则很容易被网站抓取禁止。通过使用轮换代理使自己看起来像不同的用户,您可以避免这种情况。
方法 3:选择一个独特的用户代理
用户代理包含有关发出请求的客户端的信息,包括操作系统和浏览器。最好使用模拟流行在线浏览器的自定义用户代理,而不是 Playwright 的默认用户代理,以防止被检测到。
方法 4:使用 CAPTCHA 求解器
使用 Playwright,您可以使用各种工具(例如 Scrapeless)来解决 CAPTCHA。
对于不断出现的网页抓取阻塞和CAPTCHA感到厌烦?
介绍Scrapeless - 终极一体化网页抓取解决方案!
利用我们强大的工具套件,释放数据提取的全部潜力:
最佳网页抓取解决方案
自动解决高级CAPTCHA,保持您的抓取毫不间断。
体验不同 - 免费试用!
方法 5:添加 Playwright-extra
Playwright-extra 是一个轻量级的 Playwright 插件框架,允许添加额外的有用插件。我们将用来绕过 Cloudflare 的插件叫做 Puppeteer-extra-plugin-stealth,它使用多种策略,包括鼠标事件生成和 User-Agent 修改,来隐藏无头浏览器的使用。
总结
如您所见,您可以使用 Playwright 绕过 Cloudflare,但您可能需要使用一些可能并非每次都奏效的复杂技巧。与此同时,Scrapeless 将帮助您立即成功,并立即为您提供免费 API 密钥。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


