如何使用 Playwright 绕过验证码
Advanced Bot Mitigation Engineer
是否有 CAPTCHA 阻止您进行网络抓取?这些困难可能会在自动化数据收集时造成麻烦。幸运的是,有两种方法可以使用 Playwright 来绕过 CAPTCHA,我们将在本文中介绍。
Playwright 能解决 CAPTCHA 吗?
CAPTCHA 的设计目的是对机器来说很难,但对人来说很简单,但我们也将探讨如何使用 Playwright 与其他有用工具结合起来来消除它们。
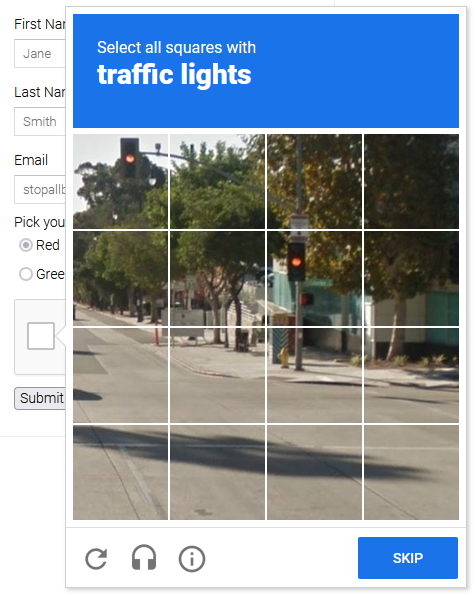
一个重要的教训是,您可以:A) 在出现验证码时立即完成验证;或 B) 彻底避免它,并在出现时再次尝试。
在第一种情况下,需要使用 Playwright CAPTCHA 解决方案,这在大量使用时可能会很昂贵。为了在第二种情况下避免被检测到,您的抓取器必须更好地模仿人类的行为。两种策略都将展示,但作为起点,第二种策略是最好的。
现在让我们看看如何将这些付诸实践!
方法 1:使用基础 Playwright 和 CAPTCHA 解决方案来绕过 CAPTCHA。
我们将讨论的第一种方法是使用 Playwright 与 Scrapeless,这项服务通过雇用人工来解决 CAPTCHA。
厌倦了不断被CAPTCHA阻碍你的网页抓取工作?
向您强烈推荐 Scrapeless - 性能强大的一体化网页抓取解决方案。
Scrapeless:目前最好的一体化在线抓取解决方案!
借助我们强大的工具套件,可以轻松发挥数据抓取的全部潜力:
最佳 CAPTCHA 解码器
自动解决复杂的 CAPTCHA 问题,确保持续而丝滑地抓取网页数据。
免费试用开启中!
方法 2:在 Playwright 中使用 Stealth 插件
如果您需要从使用更复杂 CAPTCHA 障碍的网站抓取数据,之前的 Playwright 设置将无法正常工作,但 Stealth 插件是一个有用的变通方案。这个开源项目为 Playwright 添加了元素,使其更像真实的网络流量:
- 您的用户代理被隐藏。
- 为了避免 IP 地址识别,WebRTC 被禁用。它通过隐藏浏览历史记录来保护隐私,即使它没有专门禁止跟踪脚本。
- 为了使您的请求看起来更自然,它使用额外的组件增强了您的无头浏览器。
- 为了增加我们示例的活力,让我们尝试一下 Astra,这是一个具有最低 Cloudflare 安全性的网站。
在开始之前,请通过在您的项目文件夹中执行以下命令安装必要的依赖项:
language
npm install playwright playwright-extra需要注意的是,playwright-extra 框架包含 Stealth 插件。
要增强 Playwright,请使用 playwright-extra 启动无头 Chrome 浏览器,并使用 chromium.use(pluginStealth) 启用 puppeteer-extra-plugin-stealth。这组技术提供了进一步的保障措施,使网站更难识别您的网络抓取工具。
language
const { chromium } = require('playwright-extra')
// 加载隐身插件并使用默认值(所有隐藏 playwright 使用的技巧)
const pluginStealth = require("puppeteer-extra-plugin-stealth");
// 使用隐身
chromium.use(pluginStealth)
// 就这些,其余的就像平常一样使用 playwright 😊
chromium.launch({ headless: true }).then(async browser => {
// 创建一个新页面
const page = await browser.newPage()
// 访问网站
await page.goto('https://www.scrapeless.com/')
// 等待页面下载
await page.waitForTimeout(1000);
// 截取屏幕截图
await page.screenshot({ path: 'screen.png'})
// 关闭浏览器
console.log('全部完成,查看屏幕截图。 ✨')
await browser.close()
})我们的网站在使用 browser.newPage() 加载新页面并调用 page.goto() 方法后,已准备好进行抓取。
结论
使用 Playwright 绕过 CAPTCHA 可能很困难,因为这种众所周知的障碍旨在阻止对网站的自动访问。 尽管如此,如果你拥有合适的工具和库,你将能够抓取所需的数据。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


