
2025年五大抓取浏览器 | 错过了只能哭了!
Expert Network Defense Engineer
什么是网页抓取以及它的用途?
网页抓取是一种从互联网提取数据的技术,通常通过自动爬取和构建网站上的信息来实现。抓取通常涉及通过发送HTTP请求访问网页,获取页面内容,然后解析并提取所需数据,例如文本、图像、链接、表格数据等。
抓取是大规模数据收集的核心技术之一,广泛应用于许多领域,例如价格监控、市场调研、竞争分析、新闻聚合和学术研究。由于许多网站的数据以HTML页面的形式呈现,网页抓取可以将这些内容转换为结构化数据,以便后续分析和使用。
网页抓取是如何工作的?
步骤1. 发送请求: 您的网页抓取工具首先向目标网站发送HTTP请求,模拟真实用户的浏览行为。
步骤2. 获取网页内容: 网站将返回HTML页面内容,抓取工具对其进行解析。
步骤3. 数据解析: 它使用HTML解析工具(例如BeautifulSoup、lxml等)提取页面上的特定数据。
步骤4. 数据存储: 提取的数据可以存储为CSV、JSON或数据库等格式,以便后续处理和分析。
抓取浏览器通常会自动执行这些步骤,提供更高效、更可靠的抓取流程。
如何选择网页抓取工具
访问网络数据的方法有很多。即使你已经缩小到网页抓取工具,搜索结果中出现的各种令人困惑功能的工具仍然可能让你难以做出决定。
在选择网页抓取工具之前,您可以考虑以下几个方面:
- 设备: 如果你使用的是Mac或Linux系统,你应该确保该工具支持你的系统,因为大多数网页抓取工具只适用于Windows。
- 云服务: 如果你想随时随地跨设备访问数据,云服务非常重要。
- API访问和IP代理: 网页抓取有其自身的挑战和反抓取技术。IP轮换和API访问将帮助你避免被封禁。
- 集成: 你以后如何使用这些数据?集成选项可以更好地自动化整个数据处理过程。
- 培训: 如果你不擅长编程,最好确保有指南和支持来帮助你完成整个数据抓取过程。
- 价格: 网页抓取工具的成本始终是一个需要考虑的因素,并且它在不同供应商之间差异很大。
五大抓取浏览器
1. Scrapeless
Scrapeless 抓取浏览器 提供了一个高性能的无服务器平台,旨在简化从动态网站提取数据的过程。通过与 Puppeteer 的无缝集成,开发人员可以运行、管理和监控无头浏览器,而无需专用服务器,从而实现高效的 Web 自动化和数据收集。
Scrapeless 抓取浏览器拥有覆盖 195 个国家/地区和 7000 多万个住宅 IP 的全球网络,提供 99.9% 的正常运行时间和高成功率。它绕过了诸如 IP 封锁和 CAPTCHA 等常见障碍,使其成为复杂 Web 自动化和 AI 驱动的数据收集的理想选择。非常适合需要可靠、可扩展的网页抓取解决方案的用户。
如何将此网页抓取工具集成到您的项目中?立即按照我的步骤操作!
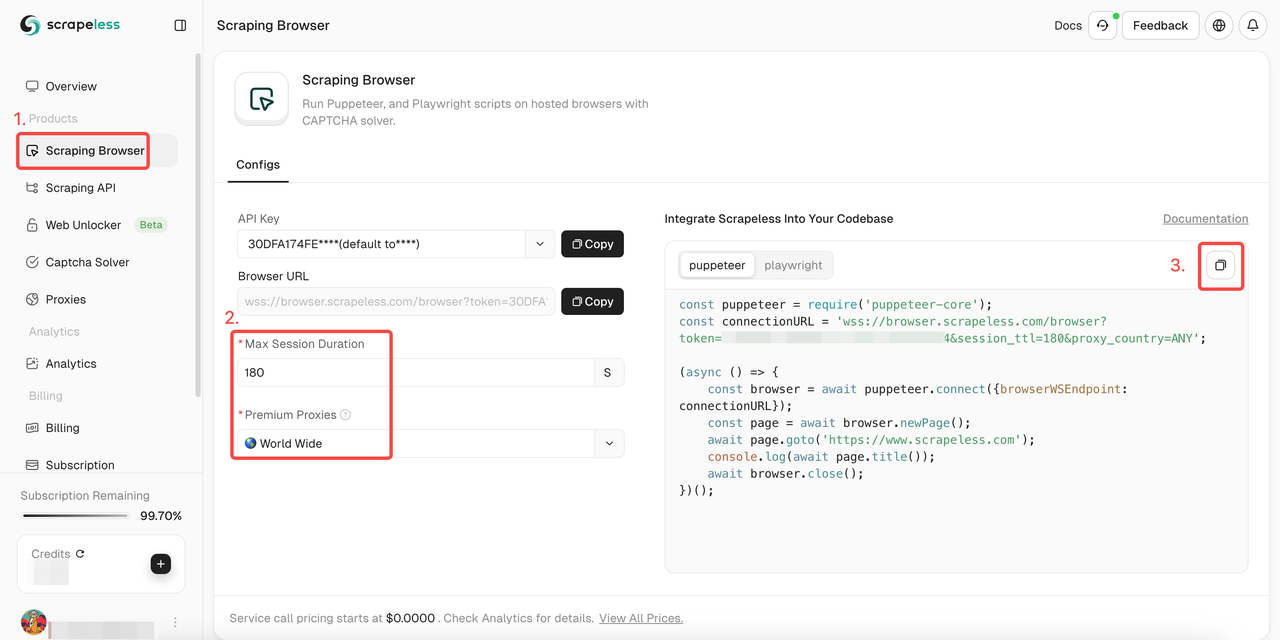
- 登录 Scrapeless
- 进入“Scraping Browser”
- 根据您的需求设置参数
- 复制集成到您的项目的示例代码
- 示例代码:
- Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input your token
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();- Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input your token
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();- 想要了解更多详情?我们的文档 将会极大地帮助你!
2. ParseHub
Parsehub 是一款常用的网页抓取工具,它使用 JavaScript、AJAX 技术、Cookie 等从网站收集数据。它支持 Windows、Mac OS X 和 Linux 系统。
Parsehub 使用机器学习技术来读取、分析网页文档并将其转换为相关数据。但它并非完全免费,你只能免费设置最多五个抓取任务。
3. Import
Import.io 是一款独特的 SaaS 网页数据集成软件。它为最终用户提供了一个可视化环境来设计和定制数据收集工作流程。
它在一个平台上涵盖了从数据提取到分析的整个网页提取生命周期。你还可以轻松地将其集成到其他系统中。
除了完全托管的抓取浏览器外,我们还可以使用强大的插件或扩展:
4. Webscraper
Web Scraper 具有 Chrome 扩展程序和云扩展程序。
对于 Chrome 扩展程序版本,您可以创建一个网站地图(计划),说明如何浏览网站以及应该抓取哪些数据。
云扩展程序可以抓取大量数据并同时运行多个抓取任务。您可以将数据导出到 CSV 或将数据存储在 Couch DB 中。
5. Dexi
Dexi.io 更适合具有熟练编程技能的高级用户。它有三种类型的程序供您创建抓取任务 - 提取器、爬虫和管道。它提供各种工具,允许您更精确地提取数据。凭借其现代功能,您将能够处理任何网站上的详细信息。
但是,如果您没有编程技能,您可能需要花费一些时间来习惯它,然后才能创建一个网页抓取机器人。
为什么抓取浏览器可以增强您的工作?
抓取浏览器(例如 Puppeteer、Playwright 等)可以显著提高网页爬取效率,原因如下:
- 支持动态内容: 抓取浏览器通过提供完整的浏览器渲染能力,可以处理使用 JavaScript 动态生成的页面内容,爬取更有效的数据。
- 模拟真实用户行为: 抓取浏览器可以模拟真实用户行为,例如点击、滚动、输入数据等,以避免被反爬虫机制检测到。
- 提高稳定性: 抓取浏览器通过集成代理管理、自动化验证码解决方案等功能,可以提高爬取的成功率和稳定性。
- 跨平台支持: 许多抓取浏览器支持跨平台操作,可以在不同的操作系统(Windows、Linux、MacOS 等)上运行,提供更大的灵活性。
- 高并发支持: 一些抓取浏览器(例如 Browserless)还提供云服务,支持高并发爬取和大规模数据收集,适用于需要处理大量数据的场景。
最后的想法
哪种网页抓取工具最适合您,抓取浏览器还是抓取扩展程序?您肯定希望使用最方便、最高效的工具来快速进行网页抓取。立即试用 Scrapeless!
Scrapeless 抓取浏览器 使网页抓取变得简单高效。通过绕过 CAPTCHA 和智能 IP 轮换,您可以避免网站封锁并轻松实现数据抓取。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


