
Scrapeless SDK 正式推出:您的一体化网页抓取和浏览器解决方案
Expert Network Defense Engineer
我们很高兴地宣布,官方的 Scrapeless SDK 现已上线!🎉
这是您与强大的 Scrapeless 平台之间的终极桥梁——使网络数据提取和浏览器自动化变得比以往更简单。
只需几行代码,您就可以执行大规模的网页抓取和 SERP 数据提取,为 Agentic AI 系统提供稳定支持。
Scrapeless SDK 为开发者提供了所有核心服务的官方封装,包括:
- 抓取浏览器:基于 Puppeteer 和 Playwright 的自动化层,支持真实点击、表单填写和其他高级功能。
- 浏览器 API:创建和管理浏览器会话,适用于高级自动化需求。
- 抓取 API:获取网页并以多种格式提取内容。
- 深度 SERP API:轻松抓取 Google 等搜索引擎的搜索结果。
- 通用抓取 API:具备 JS 渲染、截图和元数据提取的通用网络抓取功能。
- 代理 API:即时配置代理,包括 IP 地址和地理位置。
无论您是数据工程师、爬虫开发人员,还是一家建立数据驱动产品的初创公司的一部分,Scrapeless SDK 都能帮助您更快、更可靠地获取所需数据。
从浏览器自动化到搜索引擎结果解析,从网页数据提取到自动代理管理,Scrapeless SDK 简化了您整个数据获取工作流程。
👉 查看完整代码示例
Scrapeless SDK 使用参考
前提条件
登录 Scrapeless 仪表板并获取 API 密钥
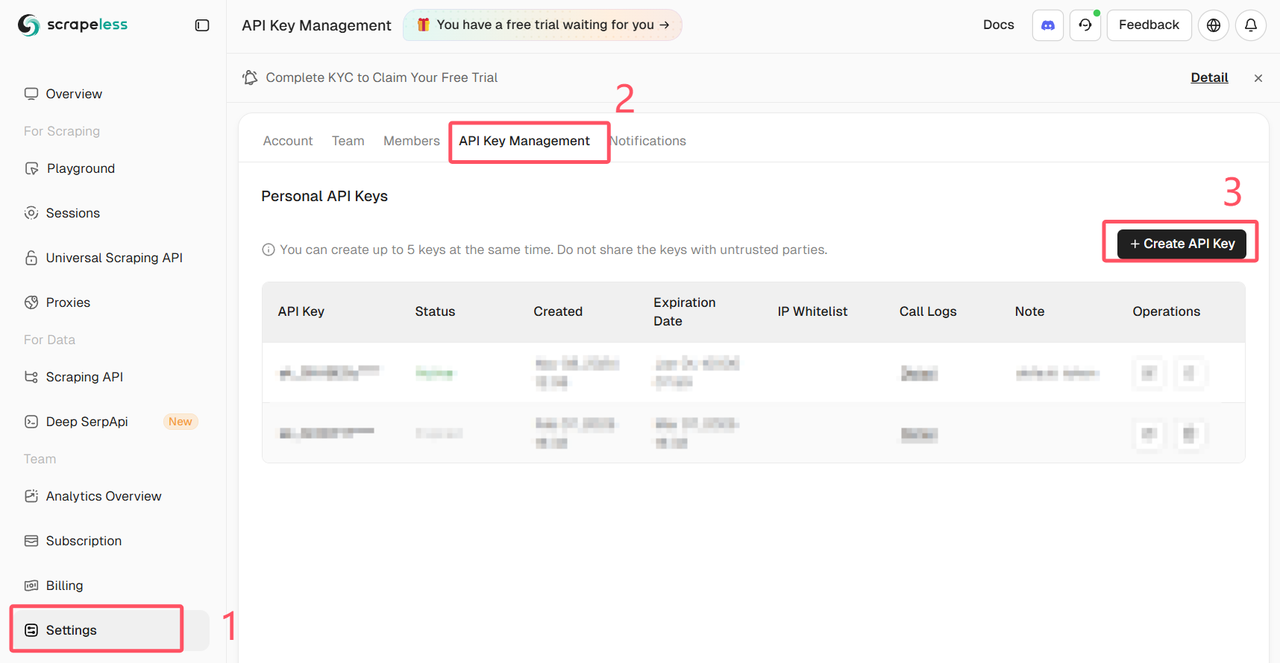
安装
- npm:
Bash
npm install @scrapeless-ai/sdk- yarn:
Bash
yarn add @scrapeless-ai/sdk- pnpm:
Bash
pnpm add @scrapeless-ai/sdk基本设置
JavaScript
import { Scrapeless } from '@scrapeless-ai/sdk';
// 初始化客户端
const client = new Scrapeless({
apiKey: 'your-api-key' // 从 https://scrapeless.com 获取您的 API 密钥
});环境变量
您还可以使用环境变量配置 SDK:
Bash
# 必需
SCRAPELESS_API_KEY=your-api-key
# 可选 - 自定义 API 端点
SCRAPELESS_BASE_API_URL=https://api.scrapeless.com
SCRAPELESS_ACTOR_API_URL=https://actor.scrapeless.com
SCRAPELESS_STORAGE_API_URL=https://storage.scrapeless.com
SCRAPELESS_BROWSER_API_URL=https://browser.scrapeless.com
SCRAPELESS_CRAWL_API_URL=https://crawl.scrapeless.com抓取浏览器(浏览器自动化封装)
抓取浏览器模块为浏览器自动化提供了一个高层次的统一 API,建立在 Scrapeless 浏览器 API 之上。它支持 Puppeteer 和 Playwright,并扩展标准页面对象,具有诸如 realClick、realFill 和 liveURL 等高级方法,以实现更类人式的自动化。
Puppeteer 示例:
Python
import { PuppeteerBrowser } from '@scrapeless-ai/sdk';
const browser = await PuppeteerBrowser.connect({
session_name: 'my-session',
session_ttl: 180,
proxy_country: 'US'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.realClick('#login-btn');
await page.realFill('#username', 'myuser');
const urlInfo = await page.liveURL();
console.log('当前页面 URL:', urlInfo.liveURL);
await browser.close();Playwright 示例:
Python
import { PlaywrightBrowser } from '@scrapeless-ai/sdk';
const browser = await PlaywrightBrowser.connect({
session_name: 'my-session',
session_ttl: 180,
proxy_country: 'US'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.realClick('#login-btn');
await page.realFill('#username', 'myuser');
const urlInfo = await page.liveURL();
console.log('当前页面 URL:', urlInfo.liveURL);
await browser.close();👉 访问我们的文档以获取更多用例
👉 通过 GitHub 一键集成
实战示例:抓取 Nike.com 上的 “Air Max” 搜索结果
假设您正在为一个鞋子比较平台构建后端系统,需要实时从 Nike 官方网站获取 “Air Max” 的搜索结果。传统上,您需要部署 Puppeteer,处理代理,规避封锁,解析页面结构……这既耗时又容易出错。
现在,通过 Scrapeless SDK,整个过程只需几行代码:
第 1 步. 安装 SDK
使用您喜欢的包管理器:
Python
npm install @scrapeless-ai/sdk第 2 步. 初始化客户端
TypeScript
import { Scrapeless } from '@scrapeless-ai/sdk';
const client = new Scrapeless({
apiKey: 'your-api-key' // 在 https://scrapeless.com 获取
});步骤 3. 一键 SERP 抓取
TypeScript
const results = await client.deepserp.scrape({
actor: 'scraper.google.search',
input: {
q: 'Air Max site:www.nike.com'
}
});
console.log(results);您无需担心代理、反机器人机制、浏览器模拟或 IP 轮换 — Scrapeless 会在幕后处理这一切。
示例输出
JSON
{
inline_images: [
{
position: 1,
thumbnail: 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQtHPNOwXmvXfYfaT_4UqM1IvNBqZDZe7rScA&s',
related_content_id: 'N2x0F2OpsGqRuM,xzJA7z__Ip2bvM',
related_content_link: 'https://www.google.com/search/about-this-image?img=H4sIAAAAAAAA_wEXAOj_ChUIx-WA-v7nv5GdARC32NG7sayq2GoyjCpjFwAAAA%3D%3D&q=https://www.nike.com/t/air-max-1-mens-shoes-2C5sX2&ctx=iv&hl=en-US',
source: 'Nike',
source_logo: '',
title: "Nike Air Max 1 男鞋",
link: 'https://www.nike.com/t/air-max-1-mens-shoes-2C5sX2',
original: 'https://static.nike.com/a/images/t_PDP_936_v1/f_auto,q_auto:eco/c5ff2a6b-579f-4271-85ea-0cd5131691fa/NIKE+AIR+MAX+1.png',
original_width: 936,
original_height: 1170,
in_stock: false,
is_product: false
},
....
}您现在可以将这些结果存储到数据库中,或者直接用于展示和排名分析。
立即安装 Scrapeless SDK
Scrapeless Node.js SDK 使网页抓取和浏览器自动化变得前所未有的简单。无论您是在构建价格监控工具、SERP 分析系统,还是模拟真实用户行为 — 一行代码即可连接到 Scrapeless 的强大基础设施。
Scrapeless SDK 在 MIT 许可下开源。欢迎开发者贡献代码、提交问题,或加入我们的 Discord 社区以获取更多创意!
✅ 提供免费试用
🔗 查看文档
💬 有问题?加入我们的 Discord 社区
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


