
Scrapeless 现在在 Pipedream 上可用!
Senior Web Scraping Engineer
我们很高兴地宣布,Scrapeless现在正式在Pipedream上线! 🎉
这意味着您现在可以无缝利用Scrapeless强大的抓取能力,在这个强大的无服务器集成平台上构建自动化数据提取工作流程——不再需要麻烦的抓取器配置或反机器人困扰。
为什么选择Pipedream?
Pipedream是一个高度灵活和高效的自动化平台,支持事件驱动架构,并允许您集成数百种服务,如Slack、Notion、GitHub、Google Sheets等。您可以用JavaScript、Python和其他语言编写自定义逻辑——无需管理服务器或基础设施。
这是构建网络钩子、同步数据、创建实时通知和自动化任何所需操作的完美环境——简化开发并节省时间。
在Pipedream中构建您的第一个Scrapeless工作流程!
前提条件
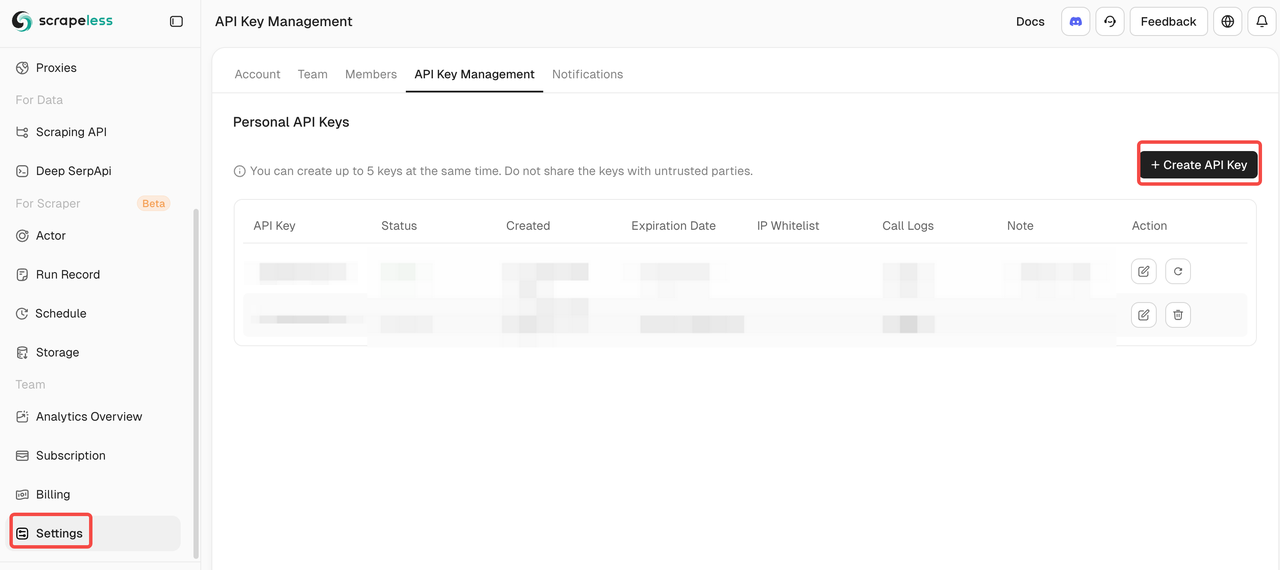
步骤1. 获取您的Scrapeless API密钥。 在Pipedream上使用Scrapeless之前,请确保您已经拥有API密钥:
- 登录到Scrapeless
- 转到API管理并生成您的密钥
步骤2. 创建Pipedream帐户。 如果您还没有, 请在Pipedream上注册。
在Pipedream中设置您的Scrapeless API密钥
准备好后,前往Pipedream的“帐户”标签并添加您的Scrapeless API密钥:
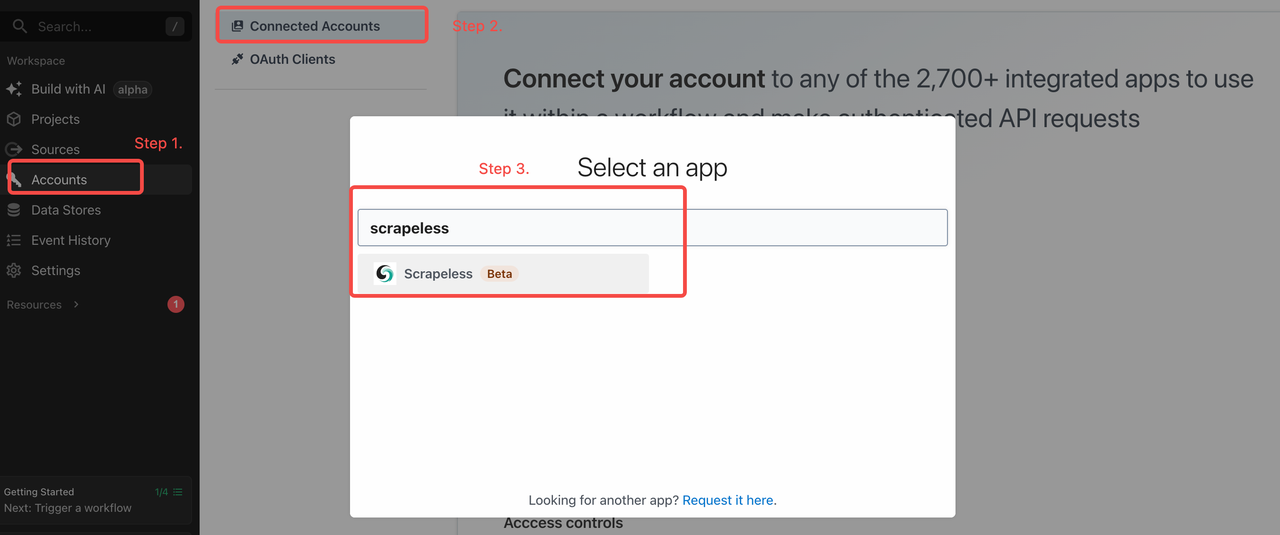
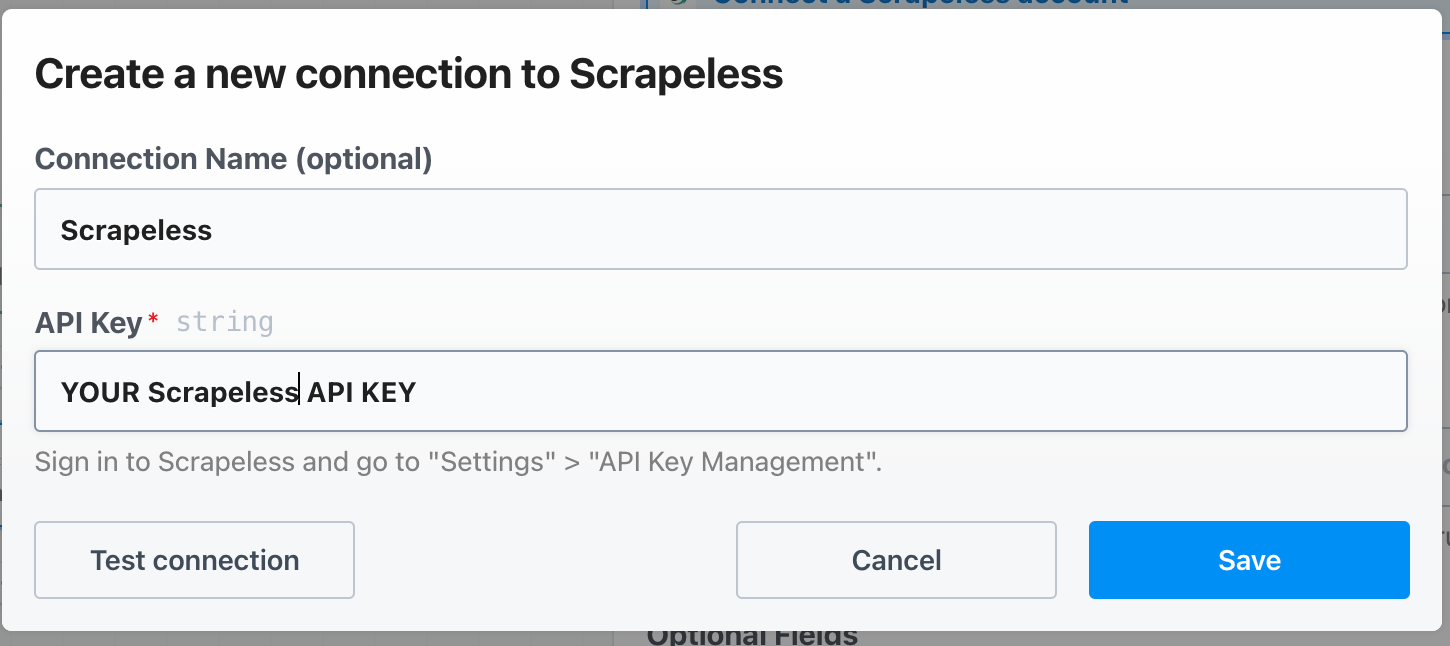
在Pipedream中设置Scrapeless API密钥如下:
Scrapeless提供三个强大的模块,帮助您在几分钟内构建数据提取工作流程:
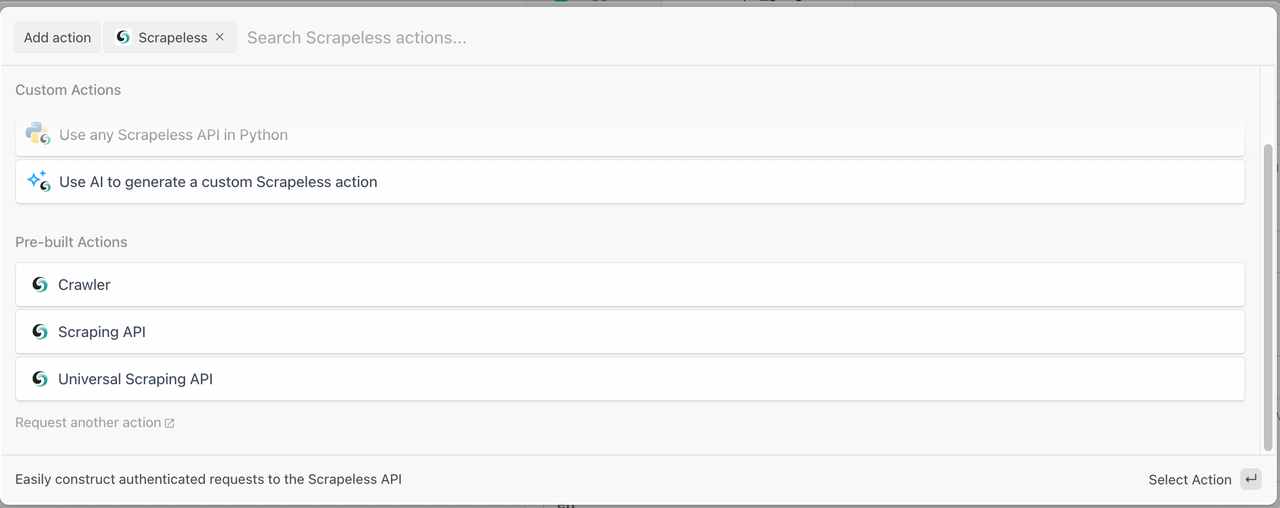
1. 爬虫模块
- 爬虫抓取:抓取整个网站,递归访问页面中的链接,并获取完整的数据集。
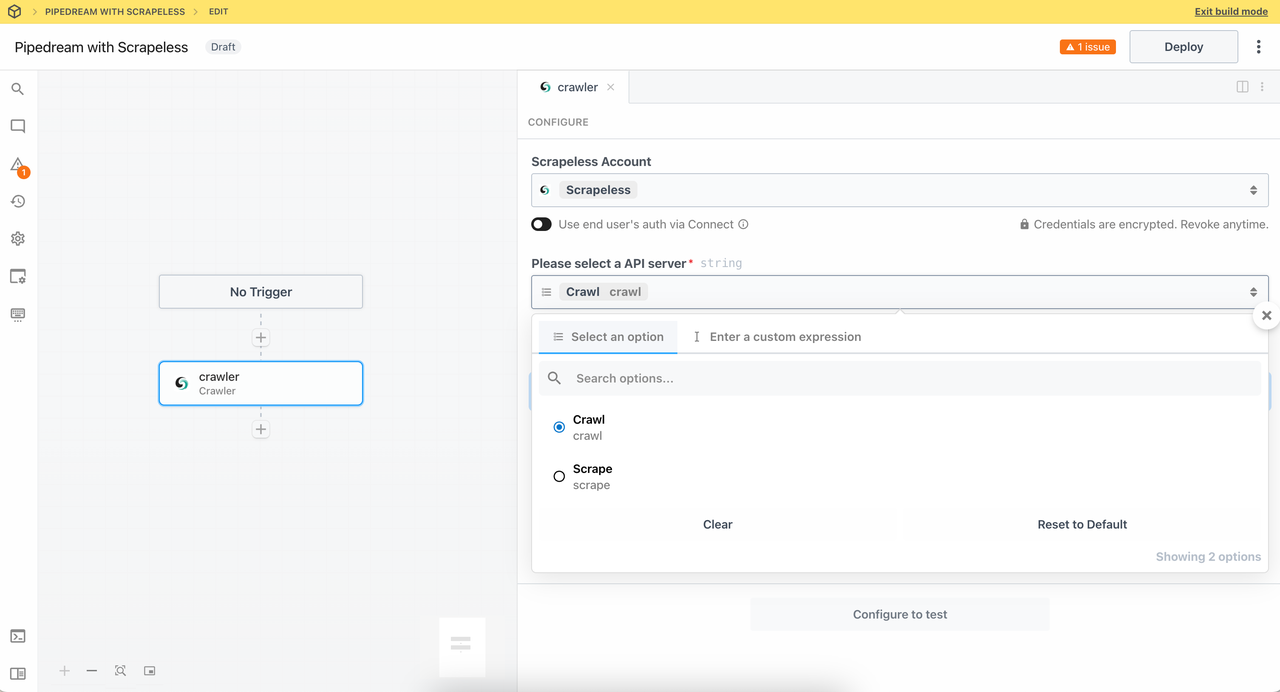
此节点使用Crawl中的爬虫功能。Scrapeless提供智能递归抓取,以充分捕获所有链接页面。
设置子页面计数,以收集所需的页面数据量。现在,我们尝试抓取 https://www.scrapeless.com/en:
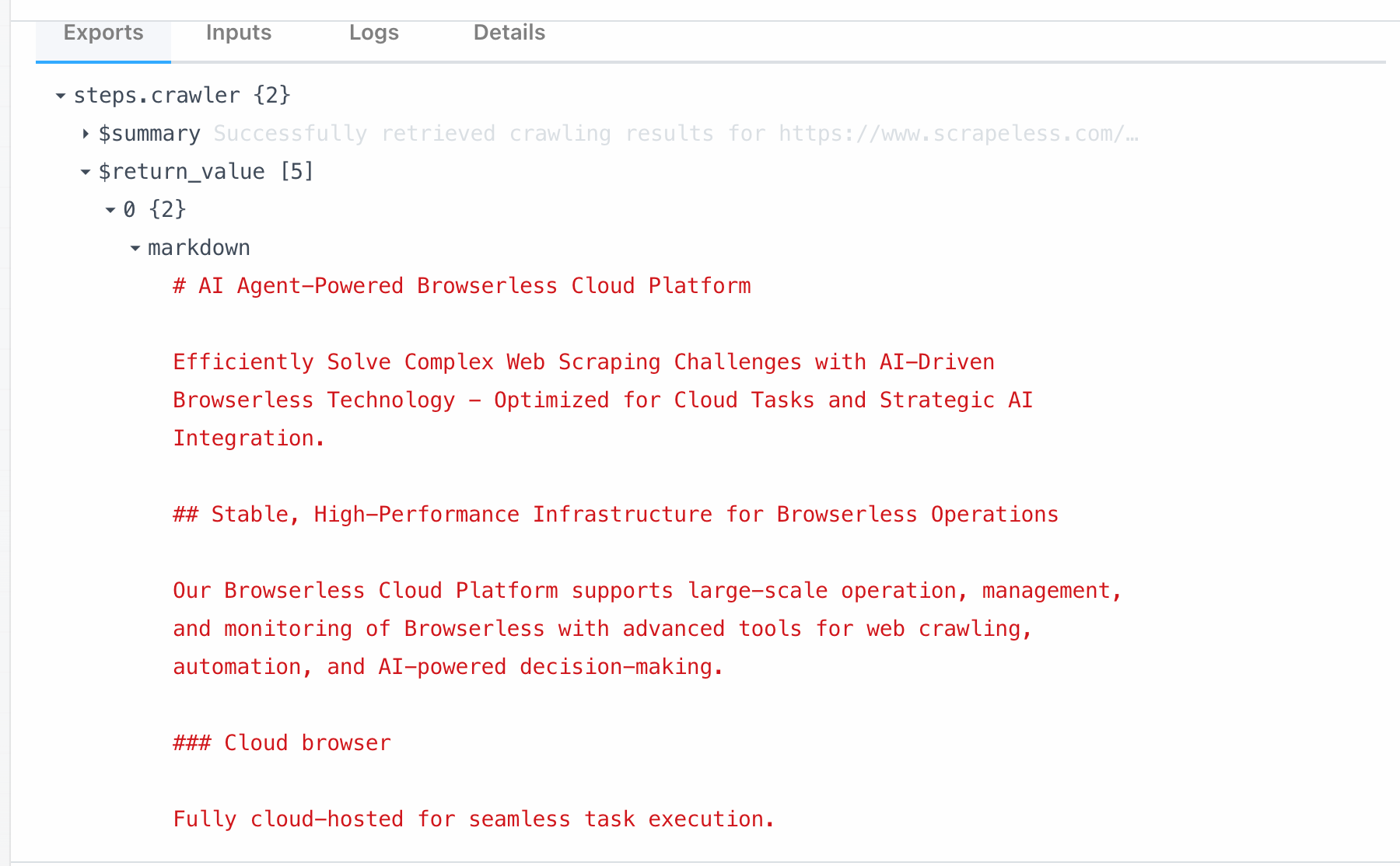
- 爬虫抓取:用于抓取单个网页的内容并提取结构化数据。
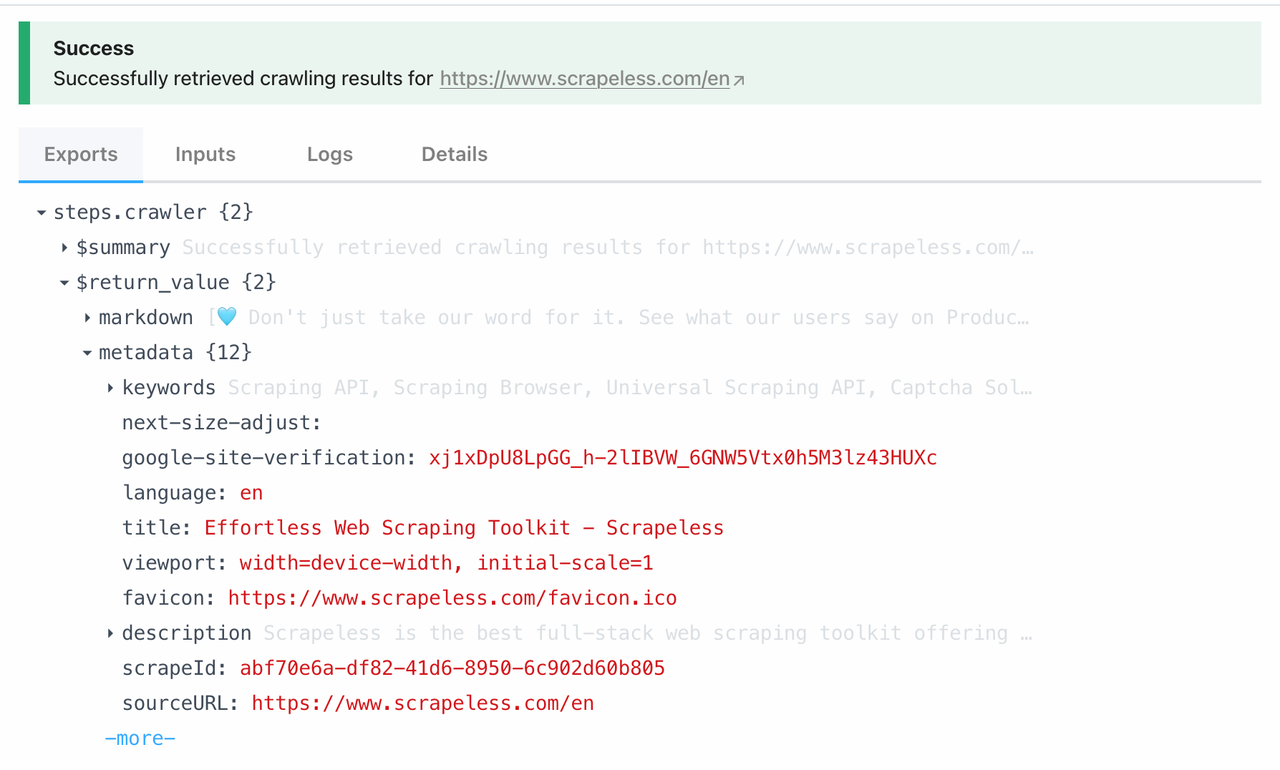
抓取节点直接连接到Scrapeless抓取下的抓取功能。通过调用此模块,您可以一键抓取单个页面的所有数据。这里是我们从 https://www.scrapeless.com/en抓取的内容:
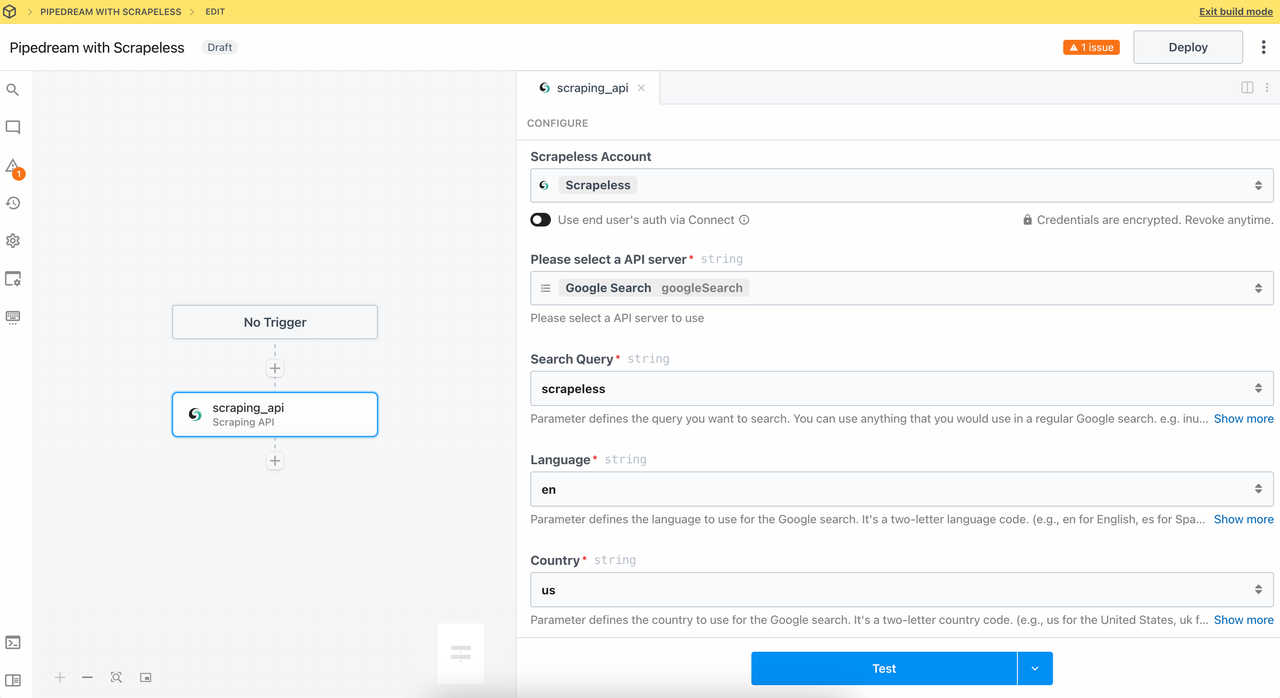
2. 抓取API模块
调用抓取API模块可以一次性访问Google搜索和Google趋势等数据源,轻松获取搜索结果和趋势数据,而无需编写复杂请求或自己处理响应。
我们来设置:
- 查询:
Scrapeless - 语言:
en - 国家:
us
为了等待异步任务的结果,我们需要在提交查询后手动点击恢复:
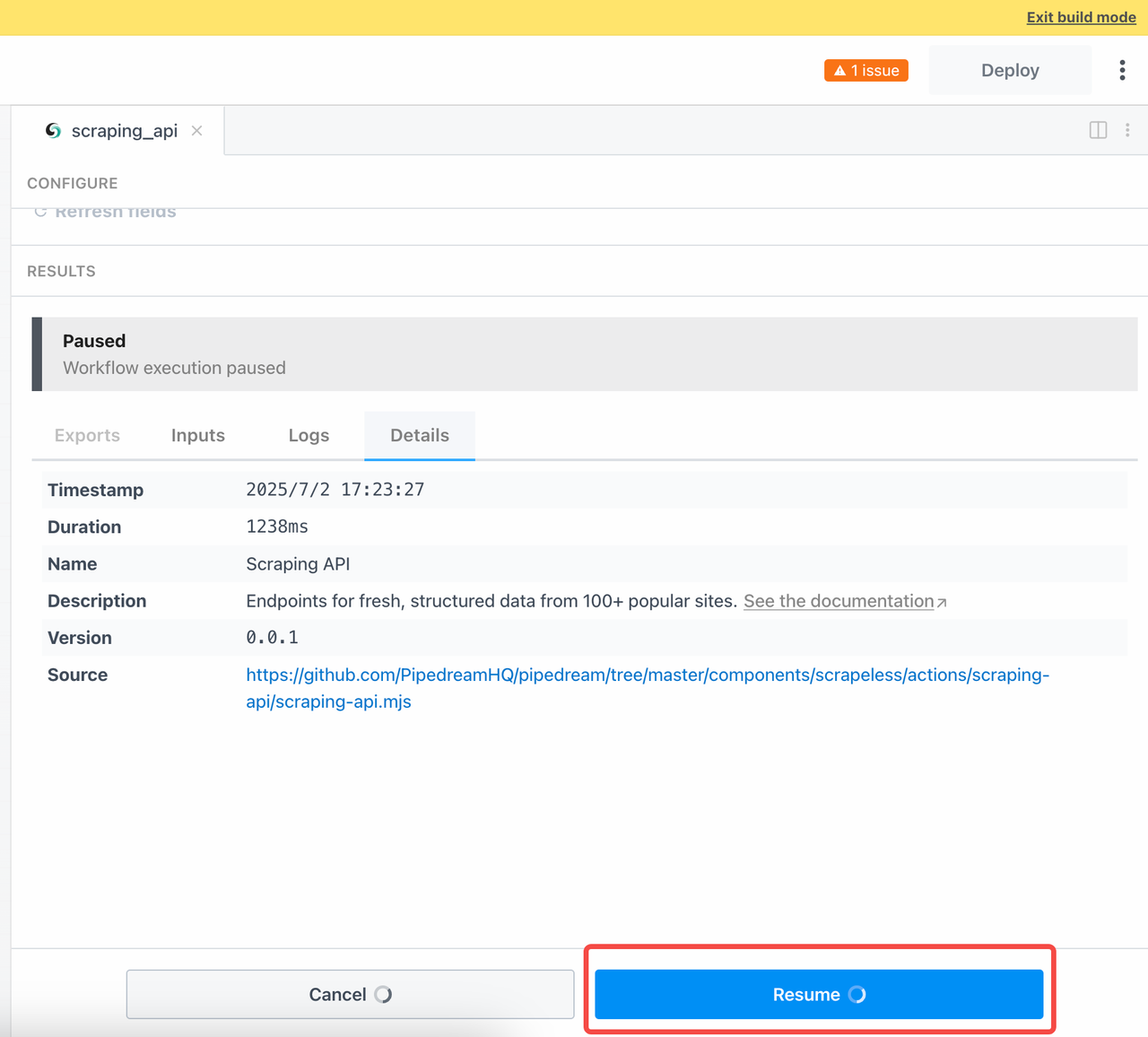
现在,让我们检查我们的抓取结果:
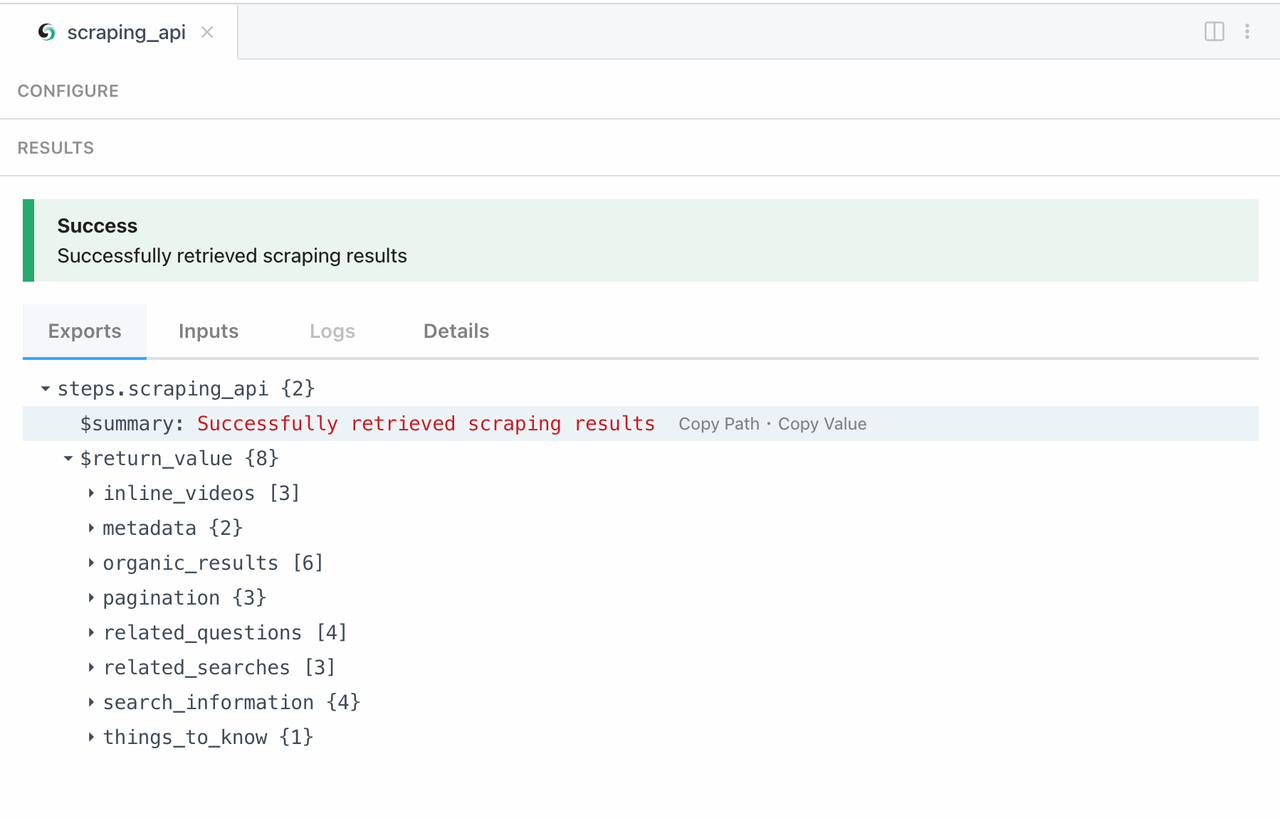
3. 通用抓取API模块
通过添加解锁网站模块,您可以成功调用Scrapeless的通用抓取API服务。面对复杂页面,如JavaScript渲染页、登录验证、反爬虫机制等,该模块可以自动处理各种障碍,像浏览器一样访问页面并提取数据。
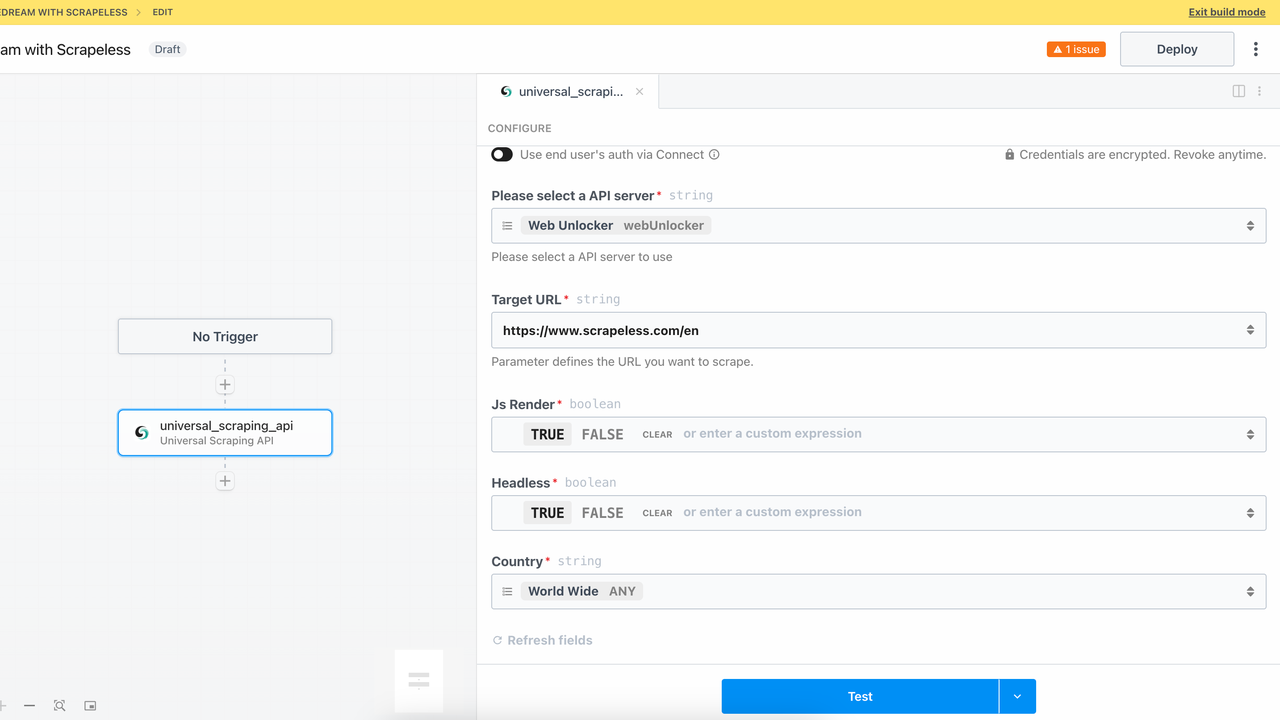
以下是返回的HTML结果:
开始使用!
无论您想抓取公共网页、提取搜索趋势,还是访问高度保护的动态页面,Scrapeless + Pipedream 允许您以最少的代码完成最复杂的数据自动化任务。
🔗 立即尝试 -> Scrapeless on Pipedream
进一步阅读
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


