
无痕云浏览器的行动:为自动化、指纹识别和验证码处理调整Puppeteer
Expert Network Defense Engineer
在网页自动化和数据爬取场景中,开发人员常常面临三个核心技术挑战:
- 环境隔离:
当同时运行数十个甚至数百个独立的浏览器会话时,传统的本地部署方案会遭遇高资源消耗、管理复杂和配置繁琐的问题。
- 指纹检测风险:
使用相同浏览器指纹的重复访问很容易触发目标网站的反机器人和指纹检测机制。
- 验证码中断:
一旦被触发,像reCAPTCHA或Cloudflare Turnstile这样的验证会中断自动化脚本。集成第三方验证码解决服务不仅增加了开发成本和复杂性,还会降低执行效率。
这些问题往往需要开发人员花费大量时间来设置本地环境或集成外部服务,导致时间和运营成本的增加。
本质上,需要的是一个能够做到以下几点的工具:
- 大规模隔离环境:
通过API生成独立的浏览器配置文件,每个配置文件代表一个完全隔离的浏览器实例。
- 自动指纹随机化:
随机化关键参数,如User-Agent、时区、语言和屏幕分辨率,同时与真实浏览器环境保持完全一致。
- 内置验证码处理:
自动识别并解决常见验证码挑战无需人工干预或第三方集成。
那么,指纹浏览器怎么样?
在国内企业自动化中,本地部署的指纹浏览器被广泛使用。然而,它们通常消耗大量系统资源,难以在各实例间保持一致,并且仍然需要第三方验证码服务进行验证处理。
相比之下,现代的基于云的无头浏览器如Scrapeless.com则提供了更可扩展和高效的替代方案。它们允许开发人员:
- 通过API创建隔离的浏览器配置文件,
- 本地随机化指纹,以及
- 自动处理验证码挑战,
所有这些都在云端进行——大大降低了开发和维护成本,同时支持高并发工作负载。
在接下来的部分中,我们将探讨几个基准场景,以评估基于云的无头浏览器在指纹隔离、并发和验证码处理方面的性能。
⚠️ 免责声明:
使用任何浏览器自动化解决方案时,始终遵守目标网站的服务条款、robots.txt规则以及相关法律法规。
为未授权或非法目的进行数据爬取,或侵犯他人权利,是严格禁止的。
我们对因滥用而造成的任何法律后果或损失不承担任何责任。
环境设置
首先,安装Scrapeless Node SDK。如果您尚未安装Node,请提前安装Node。
bash
npm install @scrapeless-ai/sdk puppeteer-core基本连接测试
js
// 设置您的API密钥
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer } from "@scrapeless-ai/sdk";
const browser = await Puppeteer.connect({
sessionName: "sdk_test",
sessionTTL: 180,
proxyCountry: "ANY",
sessionRecording: true,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto("https://www.scrapeless.com");
console.log(await page.title());
await browser.close();如果页面标题被打印,则环境配置成功。
准备好提升您的网页自动化能力吗?今天尝试Scrapeless云浏览器,体验无缝的配置文件管理、独立指纹和自动验证码处理——全部在云端!
案例 1:随机浏览器指纹验证
目标: 验证每个配置文件生成的浏览器指纹确实是独立的。
这个示例:
- 创建多个独立配置文件
- 访问指纹测试网站:https://xfreetool.com/zh/fingerprint-checker
- 提取并比较每个配置文件的浏览器指纹ID
- 验证指纹的独立性和随机性
网站https://xfreetool.com/zh/fingerprint-checker是一个检查浏览器指纹的网站,能够自动捕捉访问浏览器的指纹信息。
示例代码:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import {Puppeteer, randomString, ScrapelessClient} from "@scrapeless-ai/sdk";
// 配置常量
const MAX_PROFILES = 3; // 最大需要的profile数量
// 初始化客户端
const client = new ScrapelessClient();
/**
* 从creepjs站点页面获取浏览器指纹ID
* @param {Object} page - Puppeteer页面对象
* @returns {Promise<string>} 浏览器指纹ID
*/
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', {timeout: 15000});
return await page.evaluate(() => {
const fpContainer = document.querySelector(
'#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div'
);
return fpContainer.textContent;
});
};
/**
* 运行单个任务
* @param {string} profileId - Profile ID
* @param {number} taskId - 任务ID
* @returns {Promise<string>} 浏览器指纹ID
*/
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'My Browser',
sessionTTL: 45000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
const page = await browser.newPage();
page.setDefaultTimeout(45000);
await page.goto('https://xfreetool.com/zh/fingerprint-checker', {
waitUntil: 'networkidle0'
});
// 获取并打印cookie信息
const cookies = await page.cookies();
console.log(`[${taskId}] Cookies:`);
cookies.forEach(cookie => {
// console.log(` Name: ${cookie.name}, Value: ${cookie.value}, Domain: ${cookie.domain}`);
});
const fpId = await getFPId(page);
console.log(`[${taskId}] ✓ 浏览器指纹id= ${fpId}`);
return fpId;
} finally {
await browser.close();
}
};
/**
* 创建新的profile
* @returns {Promise<string>} 新创建的profile ID
*/
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('My Profile' + randomString());
console.log('Profile created:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('Failed to create profile:', error);
throw error;
}
};
/**
* 获取或创建所需的profile列表
* @param {number} count - 需要的profile数量
* @returns {Promise<string[]>} Profile ID列表
*/
const getProfiles = async (count) => {
try {
// 获取现有的profile列表
const response = await client.profiles.list({
page: 1,
pageSize: count
});
const profiles = response?.docs || [];
// 如果现有profile不足,创建新的
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate)
.fill(0)
.map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [
...profiles.map(p => p.profileId),
...newProfiles
];
}
// 如果已有足够profile,返回前count个
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('Failed to get profiles:', error);
throw error;
}
};
/**
* 并发运行任务
*/
const runTasks = async () => {
try {
// 获取或创建所需的profile
const profileIds = await getProfiles(MAX_PROFILES);
// 为每个profile创建任务
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
await Promise.all(tasks);
console.log('All tasks completed successfully');
} catch (error) {
console.error('Error running tasks:', error);
}
};
// 执行任务
await runTasks();测试结果:
- 3个个人资料同时运行,每个环境完全独立。
- 每个个人资料的浏览器指纹ID完全不同。
结果解释:
-
指纹唯一性
3个个人资料返回不同的指纹ID。每次创建个人资料时,浏览器指纹都是随机生成的,避免因重复指纹而被检测。
-
环境隔离验证
每个个人资料的Cookie完全独立:- 个人资料1的Cookie不会出现在个人资料2或3中
- 多个个人资料可以同时登录不同账户而不相互影响
案例2:高并发与环境隔离测试
目标: 验证高并发场景下个人资料的环境隔离,并测试批量创建和管理个人资料的能力。
在许多情况下,为了加速数据抓取或登录多个账户,工具需要支持高并发和环境隔离——相当于同时拥有数十或数百个独立的浏览器实例。Scrapeless 支持手动添加配置文件或通过 API 操作配置文件。
这个例子:
- 通过 API 创建 10 个独立配置文件
- 每个配置文件首先访问 https://abrahamjuliot.github.io/creepjs/ 获取浏览器指纹 ID
- 然后访问 https://minecraftpocket-servers.com/login/ 并拍摄屏幕截图
- 验证指纹独立性和环境隔离
示例代码:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import {Puppeteer, randomString, ScrapelessClient} from '@scrapeless-ai/sdk';
// 配置常量
const MAX_PROFILES = 5; // 最大需要的profile数量
// 初始化客户端
const client = new ScrapelessClient({});
/**
* 从creepjs站点页面获取浏览器指纹ID
* @param {Object} page - Puppeteer页面对象
* @returns {Promise<string>} 浏览器指纹ID
*/
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', {timeout: 15000});
return await page.evaluate(() => {
const fpContainer = document.querySelector(
'#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div'
);
return fpContainer.textContent;
});
};
/**
* 运行单个任务
* @param {string} profileId - Profile ID
* @param {number} taskId - 任务ID
* @returns {Promise<string>} 浏览器指纹ID
*/
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'My Browser',
sessionTTL: 30000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
// 第一步:获取浏览器指纹
let page = await browser.newPage();
page.setDefaultTimeout(30000);
await page.goto('https://abrahamjuliot.github.io/creepjs/', {
waitUntil: 'networkidle0'
});
const fpId = await getFPId(page);
await page.close(); // 关闭第一个页面
// 第二步:使用新页面进行截图
page = await browser.newPage();
const screenshotPath = `fp_${taskId}_${fpId}.png`;
await page.goto('https://minecraftpocket-servers.com/login/', {
waitUntil: 'networkidle0'
});
await page.screenshot({
fullPage: true,
path: screenshotPath
});
console.log(`[${taskId}] ✓ 指纹ID: ${fpId}, 截图保存至: ${screenshotPath}`);
return fpId;
} finally {
await browser.close();
}
};
/**
* 创建新的profile
* @returns {Promise<string>} 新创建的profile ID
*/
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('My Profile' + randomString());
console.log('Profile created:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('Failed to create profile:', error);
throw error;
}
};
/**
* 获取或创建所需的profile列表
* @param {number} count - 需要的profile数量
* @returns {Promise<string[]>} Profile ID列表
*/
const getProfiles = async (count) => {
try {
// 获取现有的profile列表
const response = await client.profiles.list({
page: 1,
pageSize: count
});
// 调试信息(可选)
// console.log('API Response:', response);
const profiles = response?.docs || [];
// 如果现有profile不足,创建新的
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate)
.fill(0)
.map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [
...profiles.map(p => p.profileId),
...newProfiles
];
}
// 如果已有足够profile,返回前count个
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('Failed to get profiles:', error);
throw error;
}
};
/**
* 并发运行任务
*/
const runTasks = async () => {
try {
console.log(`开始运行任务,需要 ${MAX_PROFILES} 个profiles`);
// 获取或创建所需的profile
const profileIds = await getProfiles(MAX_PROFILES);
console.log(`获取到 ${profileIds.length} 个profiles`);
// 为每个profile创建任务
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
const results = await Promise.all(tasks);
console.log('所有任务完成成功!');
console.log('指纹ID列表:', results);
} catch (error) {
console.error('运行任务时出错:', error);
}
};
// 执行任务
await runTasks();测试结果:
- 指纹独立性: 指纹和环境参数是随机生成的,相互独立。
- 环境隔离: 每个任务在独立的配置文件中运行;浏览器数据(Cookie、LocalStorage、Session等)不共享。
- 并发稳定性: 成功创建并发执行10个配置文件。
示例结果说明:
- 配置文件创建和连接过程
输出显示了完整的配置文件创建和浏览器连接过程:
配置文件创建成功: a27cd6f9-7937-4af0-a0fc-51b2d5c70308
配置文件创建成功: d92b0cb1-5608-4753-92b0-b7125fb18775
...
info Puppeteer: 成功连接到Scrapeless浏览器 {}
...
所有任务成功完成所有10个配置文件几乎同时创建并连接到Scrapeless云浏览器,展示了高并发下的稳定性。
-
指纹独立性验证
每个配置文件返回一个完全不同的指纹ID。这10个独特的指纹证明每个配置文件的浏览器指纹是独立和随机生成的,没有重复。
-
高并发执行稳定性
所有10个任务同时运行,成功完成,没有错误或冲突。 -
创建配置文件的多种方式
Scrapeless提供多种方法来创建和管理配置文件:
- 仪表板手动创建: 直接从仪表板创建配置文件,以便快速启动和单独操作。
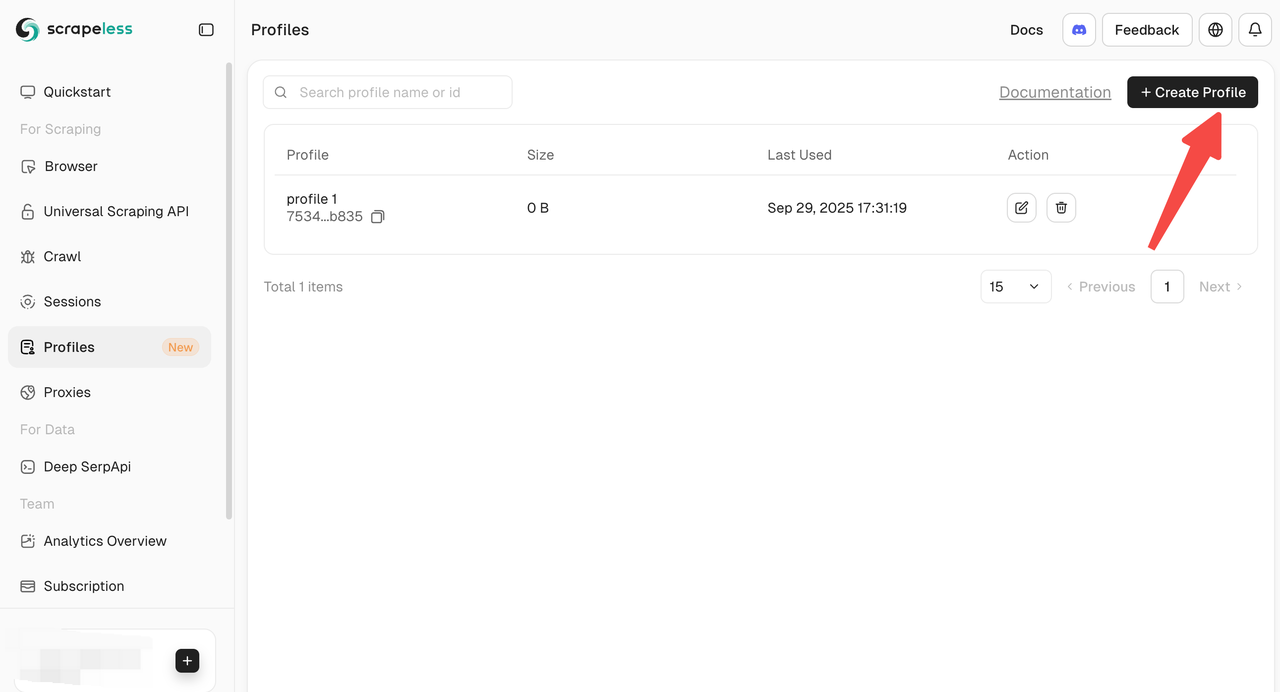
- API创建: 通过创建配置文件API以编程方式批量创建配置文件。
- SDK创建: 使用官方SDK创建配置文件,适合高并发或自定义自动化工作流程。
案例3:Cloudflare挑战 + Google reCAPTCHA – 完全自动化的CAPTCHA绕过,无需人工干预
目标: 测试Scrapeless云浏览器在访问网站时是否能自动检测并通过reCAPTCHA或Cloudflare挑战,并记录可重现的验证过程和结果。
此示例:
- 访问亚马逊搜索页面https://www.amazon.com/s?k=toy(高概率触发reCAPTCHA)
- 自动处理CAPTCHA并提取产品数据
- 验证自动处理CAPTCHA的能力
示例代码:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import {Puppeteer, randomString, ScrapelessClient} from '@scrapeless-ai/sdk';
const client = new ScrapelessClient();
const MAX_PROFILES = 1; // 最大需要的profile数量
// 从creepjs站点页面获取浏览器指纹ID
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', {timeout: 15000});
return await page.evaluate(() => {
const fpContainer = document.querySelector('#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div');
return fpContainer.textContent;
});
};
const runTask = async (profileId, taskId) => {
const browserendpoint = client.browser.create({
sessionName: 'My Browser',
sessionTTL: 45000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserendpoint,
defaultViewport: null,
timeout: 15000
});
try {
let page = await browser.newPage();
page.setDefaultTimeout(45000);
await page.goto('https://www.amazon.com/s?k=toy&crid=37T7KZIWF16VC&sprefix=to%2Caps%2C351&ref=nb_sb_noss_2');
await page.waitForSelector('[role="listitem"]', {timeout: 15000});
console.log('成功打开页面...');
const products = await page.evaluate(() => {
const items = [];
const productElements = document.querySelectorAll('[role="listitem"]');
productElements.forEach((product) => {
const titleElement = product.querySelector('[data-cy="title-recipe"] a h2 span');
const title = titleElement ? titleElement.textContent.trim() : 'N/A';
console.log(title);
const priceWhole = product.querySelector('.a-price-whole');
const priceFraction = product.querySelector('.a-price-fraction');
const price = priceWhole && priceFraction
? `$${priceWhole.textContent}${priceFraction.textContent}`
: 'N/A';
const ratingElement = product.querySelector('.a-icon-alt');
const rating = ratingElement ? ratingElement.textContent.split(' ')[0] : 'N/A';
const imageElement = product.querySelector('.s-image');
const imageUrl = imageElement ? imageElement.src : 'N/A';
const asin = product.getAttribute('data-asin') || 'N/A';
items.push({
title,
price,
rating,
imageUrl,
asin
});
});
return items;
});
console.log(JSON.stringify(products, null, 2));
return products;
} finally {
await browser.close();
}
};
// 创建新的profile
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('My Profile' + randomString());
console.log('Profile created:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('Failed to create profile:', error);
throw error;
}
};
// 获取或创建所需的profile列表
const getProfiles = async (count) => {
try {
// 获取现有的profile列表
const response = await client.profiles.list({page: 1, pageSize: count});
//console.log('API Response:', response); // 添加这行来调试API返回的数据结构
const profiles = response?.docs;
//console.log('Profiles:', profiles); // 查看解析后的profiles
// 如果现有profile不足,创建新的
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate).fill(0).map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [...profiles.map(p => p.profileId), ...newProfiles];
}
// 如果已有足够profile,返回前count个
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('Failed to get profiles:', error);
throw error;
}
};
// 并发运行任务
const runTasks = async () => {
try {
// 获取或创建所需的profile
const profileIds = await getProfiles(MAX_PROFILES);
// 为每个profile创建任务
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
await Promise.all(tasks);
console.log('All tasks completed successfully');
} catch (error) {
console.error('Error running tasks:', error);
}
};
// 执行任务
await runTasks();测试结果:
- 亚马逊搜索页面自动处理了触发的reCAPTCHA
- 成功提取了产品标题、价格、评分、图片、ASIN及其他数据
- 整个过程无需人工干预;CAPTCHA自动检测并通过
结果示例解释:
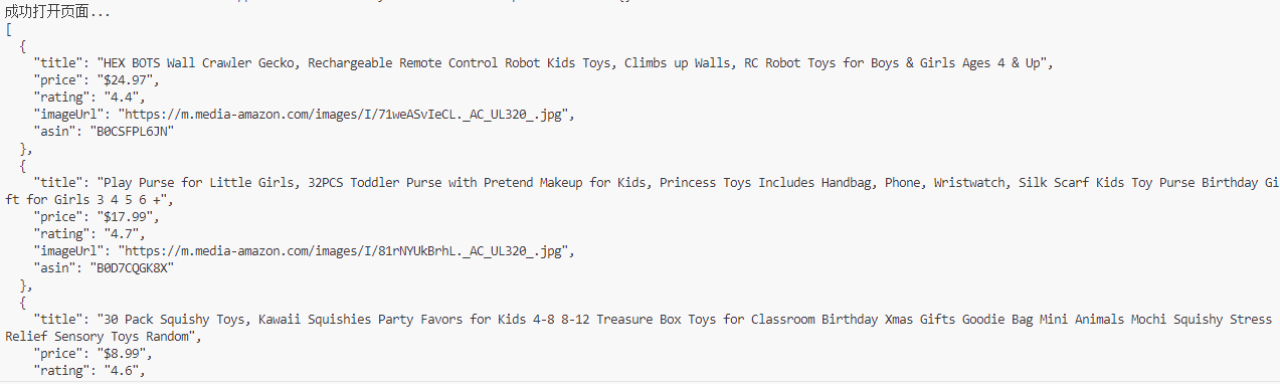
- 成功绕过CAPTCHA和数据提取:
页面成功加载,并提取了产品数据:
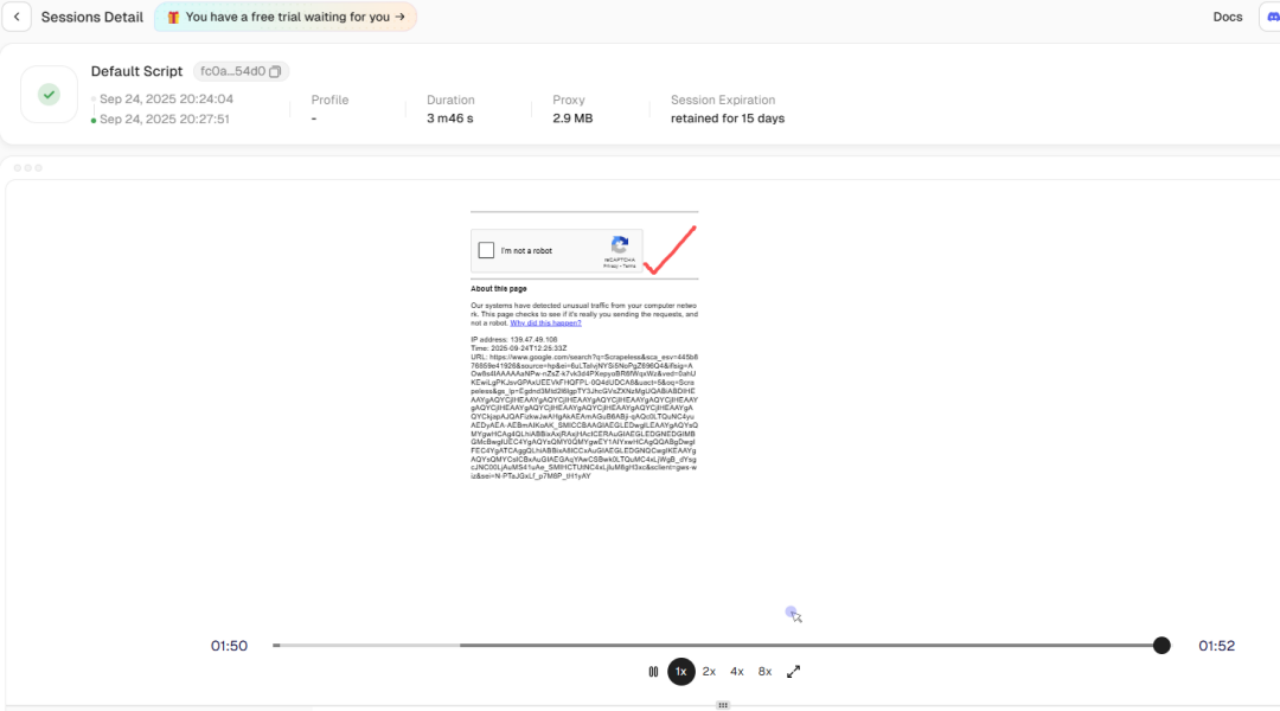
- 自动化CAPTCHA处理:
使用会话历史回放功能,可以看到数据抓取时触发了风险验证,但Scrapeless内部自动绕过了reCAPTCHA。这解决了在后台被阻止的数据抓取问题。
通常,访问亚马逊搜索页面可能会触发需要手动交互的reCAPTCHA。通过Scrapeless Cloud Browser:
- 自动检测reCAPTCHA
- 内置API自动完成验证流程
- 脚本继续执行并提取产品数据
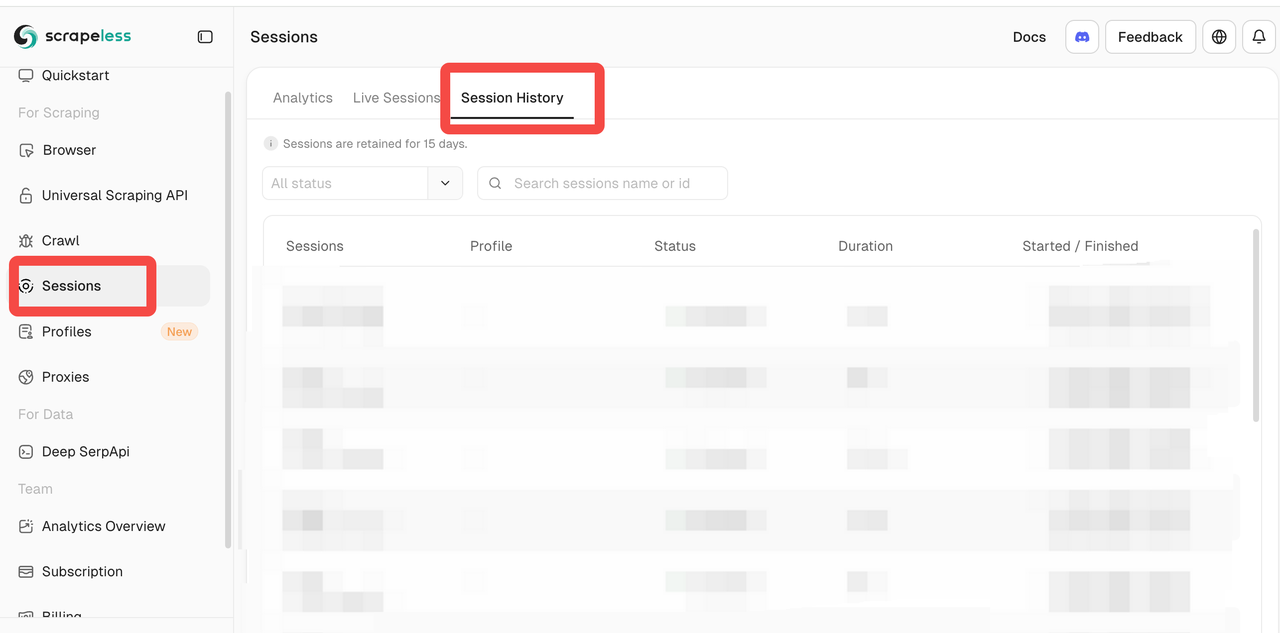
- 云观察能力:
Scrapeless面板提供:
- 实时会话: 实时监控浏览器实例以观察脚本执行
- 会话历史: 播放过去的会话以调试和审查CAPTCHA处理
尽管浏览器在云端运行,但提供的体验与本地调试非常相似,极大地降低了云浏览器调试的难度。
总结
从这三个实际场景中,我们可以总结出Scrapeless Cloud Browser在关键维度上的表现:
- 并发与环境隔离
- 支持批量创建和管理配置文件
- 每个配置文件的指纹、Cookies、缓存和浏览器数据完全隔离
- 支持在示例中同时执行10多个并发任务,无冲突或资源争用;可以扩展到成千上万的并发任务
- 相当于同时拥有数百或数千个独立的浏览器实例
- 随机浏览器指纹
- 每个配置文件的创建随机生成核心参数,如用户代理、时区、语言和屏幕分辨率
- 指纹密切模仿真实浏览器环境
- 降低被检测为自动化访问的可能性
- 内置CAPTCHA自动化
- 支持自动识别reCAPTCHA、Cloudflare Turnstile/Challenge和其他类型的CAPTCHA
- 自动完成验证,无需人工干预
- 云浏览器可观察性
* **实时会话:** 实时监控浏览器执行
* **会话历史:** 重放过去的会话以进行调试和验证
对于需要多环境隔离、高并发和验证码绕过的自动化场景,Scrapeless Cloud Browser 是一个强有力的选择。
> 准备好为您的网络自动化加速了吗?今天就[试试 Scrapeless](https://app.scrapeless.com/passport/login?utm_source=wechat&utm_medium=official_account&utm_campaign=bee) Cloud Browser,体验无缝的资料管理、独立的指纹和自动化处理验证码——一切都在云端完成!
---
**免责声明:** 任何自动化工具的使用应遵守目标网站的服务条款和相关法律。本文仅用于技术研究和验证目的。在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


