
如何快速抓取Instagram个人资料数据?
Specialist in Anti-Bot Strategies
Instagram是全球数百万用户使用的最受欢迎的社交媒体平台之一。抓取Instagram个人资料有助于企业、开发者、数据分析专家进行营销分析、竞争研究或个人数据管理。
本文将深入讲解抓取Instagram个人资料的过程。我们将解释如何创建一个Instagram抓取工具来提取Instagram个人资料和帖子页面中的数据。
现在就学习如何使用便捷的Scraping API快速抓取Ins数据。
- #方法一。构建您的Python Instagram个人资料抓取工具
- #方法二。使用Scraping API轻松收集数据
为什么抓取Instagram个人资料?
Instagram的公共数据量巨大,可以提供各种见解。抓取个人资料数据可以为您提供有关全球热门用户的宝贵信息,帮助您预测趋势、追踪品牌知名度、了解如何改进您的Instagram表现,或帮助企业通过与具有相似兴趣的热门Instagram个人资料联系来寻找潜在客户并接触新客户。
此外,抓取的Instagram数据是情感分析研究的可行资源。这些数据可以在帖子和评论中找到,并可用于收集公众对特定趋势和新闻的意见。
方法一. Python Instagram个人资料抓取工具
让我们从抓取Instagram用户个人资料开始!接下来,我们将深入解释如何抓取Instagram用户ladygaga的个人资料信息。我们可以按照以下步骤进行:
我们坚决保护网站的隐私。本博客中的所有数据都是公开的,仅用于演示抓取过程。我们不会保存任何信息和数据。
步骤一. 分析目标页面
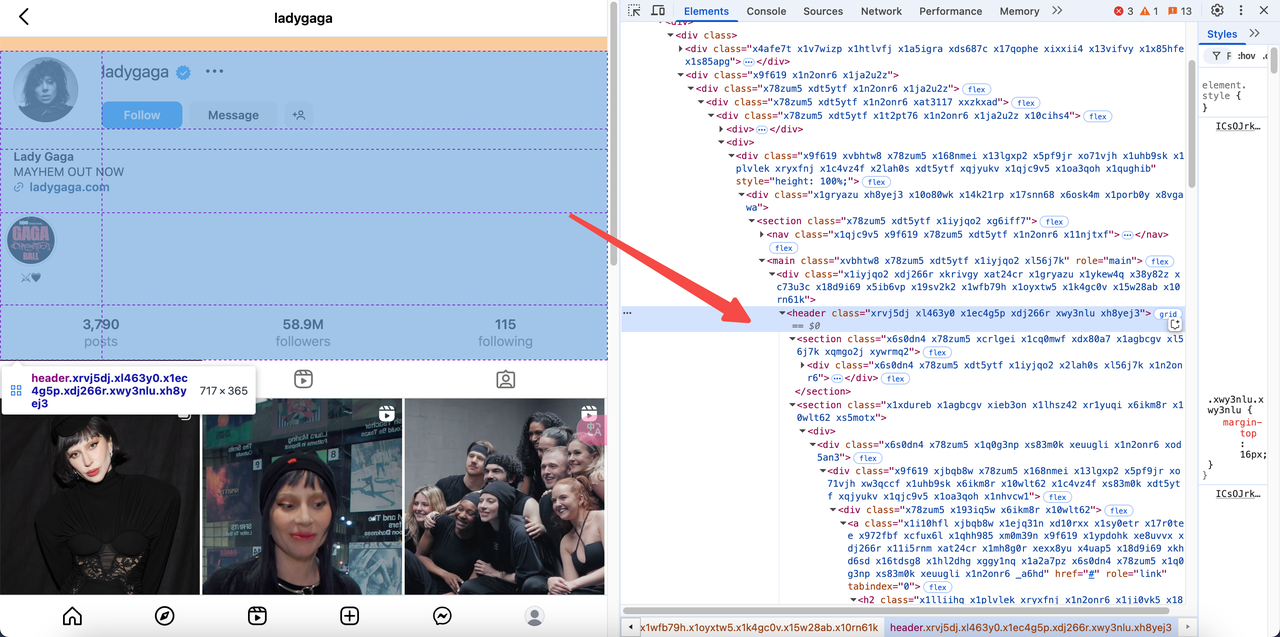
- 访问目标URL:https://www.instagram.com/ladygaga/。
- 检查页面源代码以找到嵌入的JSON数据:
- Instagram将用户信息嵌入到格式为
window._sharedData的<script>标签中。 - 我们可以通过解析HTML来提取这些数据。
步骤二. 安装所需的库
确保安装了以下Python库:
pip install requests beautifulsoup4
步骤三. 设置请求头
为了模拟浏览器访问,请设置User-Agent和Referer头,以避免被反抓取机制阻止。
Python
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://www.instagram.com/"
}步骤四. 解析JSON数据
我们需要从HTML中的<script>标签中提取window._sharedData内容并将其转换为Python字典。
Python
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", type="application/ld+json")
if not script_tag:
print("Error: JSON数据未在页面中找到。")
return None
# 解析JSON数据
try:
data = json.loads(script_tag.string)
except json.JSONDecodeError:
print("Error: 无法解析JSON数据。")
return None步骤五. 提取所需字段
从解析的JSON数据中检索用户名、个人简介、关注者数量、帖子数量和其他相关信息。
完整代码
以下是完整的Python代码,您可以直接使用它来抓取Lady Gaga的个人资料信息:
Python
import requests
from bs4 import BeautifulSoup
import json
def scrape_instagram_profile(username):
url = f"https://www.instagram.com/ladygaga/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://www.instagram.com/"
}
response = requests.get(url, headers=headers)
if response.status_code != 200:
print(f"Error: 无法获取{username}的数据。状态码:{response.status_code}")
return None
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", type="application/ld+json")
if not script_tag:
print("Error: JSON数据未在页面中找到。")
return None
# 解析JSON数据
try:
data = json.loads(script_tag.string)
except json.JSONDecodeError:
print("Error: 无法解析JSON数据。")
return None
profile = {
"username": data["author"]["name"],
"bio": data["description"],
"follower_count": data["author"]["interactionStatistic"][0]["userInteractionCount"],
"post_count": data["author"]["interactionStatistic"][1]["userInteractionCount"]
}
return profile
# 示例用法
if __name__ == "__main__":
username = "ladygaga"
profile_data = scrape_instagram_profile(username)
if profile_data:
print("Instagram个人资料数据:")
print(json.dumps(profile_data, indent=4, ensure_ascii=False))抓取结果
运行代码后,profile_data输出将包含以下字段:
JSON
{
"username": "ladygaga",
"bio": "Lady Gaga MAYHEM OUT NOW",
"follower_count": "58.9M",
"post_count": "3,790"
}方法二. Scrapeless Scraping API (推荐)
抓取Instagram非常容易。但是,Instagram对其公共数据的访问权限非常严格。它仅允许未登录用户每天发出少量请求,超过此数量后,它会将请求重定向到登录页面。
如何避免阻止Instagram抓取工具?Scrapeless是您的理想抓取工具!
Scrapeless提供用于大规模数据收集的网页抓取、网页解锁和数据提取API。
- 反机器人保护绕过: 避免在抓取网页时被阻止!
- 轮换住宅代理: 防止IP封禁和地理位置封锁。
- JavaScript渲染: 通过云浏览器抓取动态网页。
- Python和Typescript SDK,以及Scrapy集成。
这个Instagram Scraping API是免费的吗?
是的。Scrapeless为您提供2美元的免费积分。您可以直接注册以领取免费积分。使用Instagram个人资料抓取工具,您可以轻松免费收集用户信息!
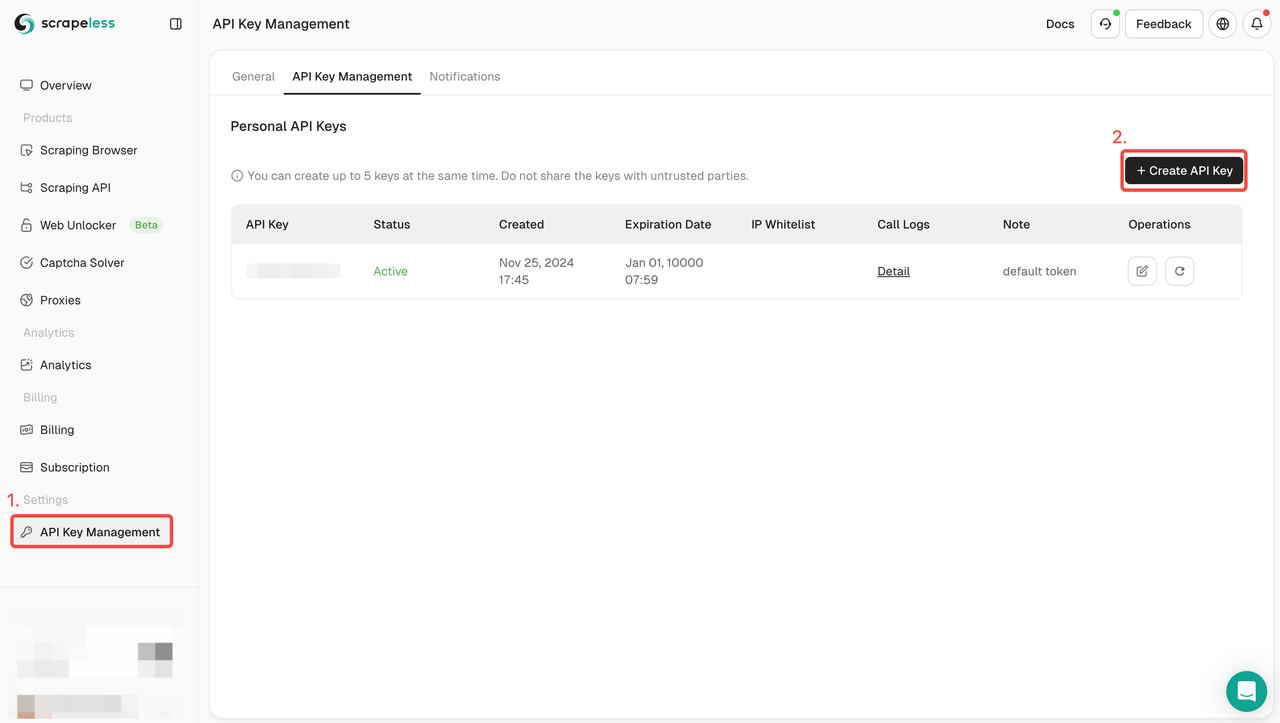
步骤一. 创建您的API令牌
首先,您需要从Scrapeless Dashboard获取您的API密钥:
- 登录到Scrapeless Dashboard。
- 导航到API密钥管理。
- 点击创建以生成您的唯一API密钥。
- 创建后,只需点击API密钥即可复制它。
总结
在本教程中,我们介绍了两种有效的获取Instagram个人资料数据的方法。我们展示了如何处理身份验证、发出请求、处理响应以及集成代理IP以提高稳定性和安全性。
按照本指南,您可以轻松开始提取Instagram个人资料数据以用于个人或商业用途,同时保持隐私并避免速率限制等问题。
为了提高数据收集效率,我们建议您使用高级抓取API,它只需要简单的配置参数即可完成数据提取!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


