
如何使用Python爬取Google购物在线卖家
Advanced Data Extraction Specialist
介绍
在当今竞争激烈的电子商务环境中,监控产品列表并分析谷歌等平台上在线卖家的表现可以提供宝贵的见解。抓取谷歌产品列表允许企业收集实时数据,以比较价格、追踪趋势和分析竞争对手。在本文中,我们将向您展示如何使用 Python 和多种方法抓取谷歌在线卖家产品信息。我们还将解释为什么 Scrapeless 是寻求可靠、可扩展和合法解决方案的企业的最佳选择。
了解抓取谷歌在线卖家产品的挑战
在尝试抓取谷歌在线卖家产品信息时,可能会出现一些关键挑战:
- 反抓取措施:网站实施 CAPTCHA 和 IP 封锁以防止自动化抓取,从而使数据提取变得困难。
- 动态内容:谷歌产品页面经常使用 JavaScript 加载数据,而传统的抓取方法(如 Requests & BeautifulSoup 或 Selenium)可能会错过这些数据。
- 速率限制:在短时间内发出过多的请求会导致访问受限,从而导致抓取过程延迟和中断。
隐私声明:我们坚决保护网站的隐私。本博客中的所有数据均为公开数据,仅用于演示抓取过程。我们不会保存任何信息和数据。
方法 1:使用 Scrapeless API 抓取谷歌在线卖家产品信息(推荐方案)
为什么 Scrapeless 是一个很棒的工具:
- 高效的数据提取:Scrapeless 可以绕过 CAPTCHA 和反机器人措施,实现流畅、不间断的数据抓取。
- 经济实惠的价格:Scrapeless 每 1000 次查询仅需 0.1 美元,为谷歌抓取提供了最经济实惠的解决方案之一。
- 多源抓取:除了抓取谷歌在线卖家产品信息外,Scrapeless 还允许您从谷歌地图、谷歌酒店、谷歌航班、谷歌新闻等收集数据。
- 速度和可扩展性:快速处理大规模抓取任务,而不会减慢速度,使其成为小型和企业级项目的理想选择。
- 结构化数据:该工具提供结构化、干净的数据,可用于您的分析、报告或集成到您的系统中。
- 易于使用:无需复杂的设置——只需集成您的 API 密钥,即可在几分钟内开始抓取数据。
如何使用 Scrapeless API:
- 注册:在 Scrapeless 上注册并获取您的 API 密钥。同时,您也可以在仪表板顶部获得免费试用。
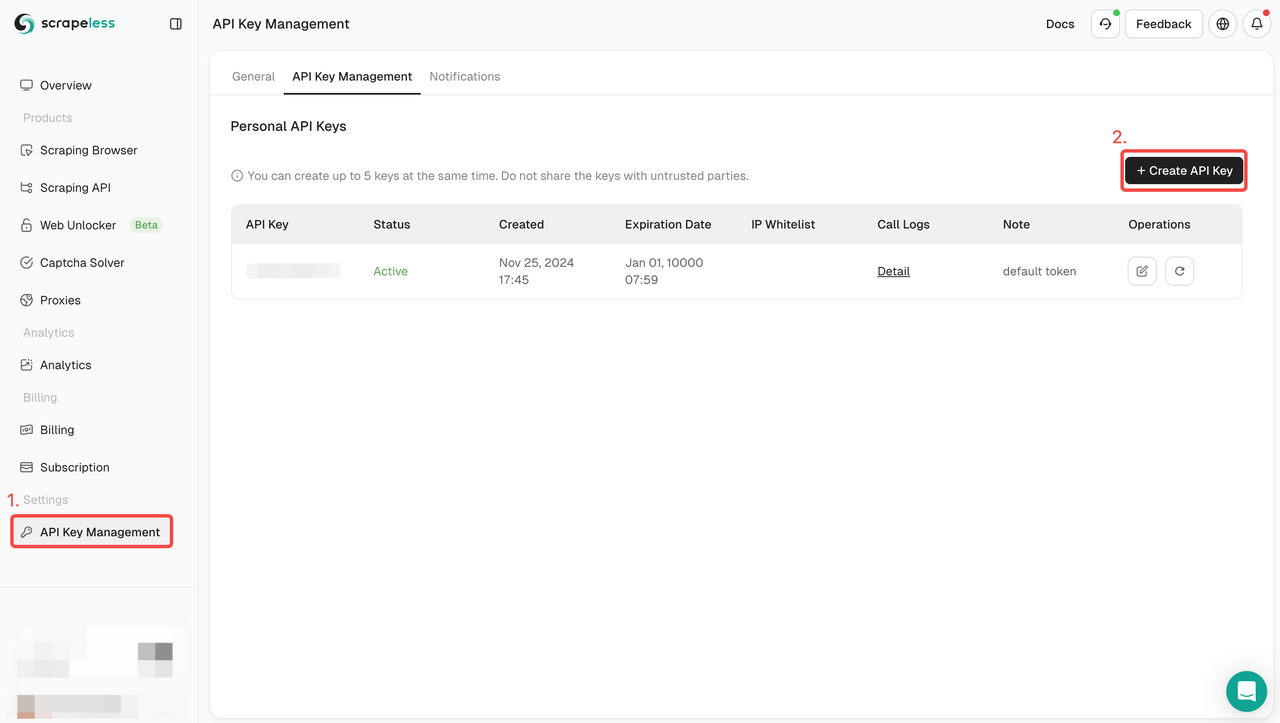
- 集成 API:在您的代码中包含 API 密钥以启动对服务的请求。
- 开始抓取:您现在可以使用产品 URL 或搜索查询发送 GET 请求,Scrapeless 将返回结构化数据,包括产品名称、价格、评论等。
- 使用数据:利用检索到的数据进行竞争对手分析、趋势追踪或任何其他需要谷歌数据洞察的项目。
完整的代码示例:
python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_product",
"product_id": "4172129135583325756",
"gl": "us",
"hl": "en",
}
payload = Payload("scraper.google.product", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()免费试用 Scrapeless 并体验我们的 API 如何简化您的谷歌在线卖家产品信息抓取过程。在此开始您的免费试用。
加入我们的 Discord 社区 以获得支持、分享见解并了解最新功能。点击此处加入!
方法 2:使用 Requests & BeautifulSoup 抓取谷歌产品列表
在这种方法中,我们将深入探讨如何使用两个强大的 Python 库:Requests 和 BeautifulSoup 来抓取谷歌产品列表。这些库允许我们向谷歌产品页面发出 HTTP 请求,并解析 HTML 结构以提取有价值的信息。
步骤 1. 设置环境
首先,确保您的系统上安装了 Python。并创建一个新目录来存储此项目的代码。接下来,您需要安装 beautifulsoup4 和 requests。您可以通过 PIP 执行此操作:
language
$ pip install requests beautifulsoup4步骤 2. 使用 requests 发出简单的请求
现在,我们需要抓取谷歌产品的相关数据。让我们以 product_id 为 4172129135583325756 的产品为例,抓取一些 OnlineSeller 的数据。
让我们首先简单地使用 requests 发送 GET 请求:
def google_product():
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/jpeg,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Priority": "u=0, i",
"Sec-Ch-Ua": '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
}
response = requests.get('https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8', headers=headers)正如预期的那样,请求返回了一个完整的 HTML 页面。现在我们需要从以下页面提取一些数据:
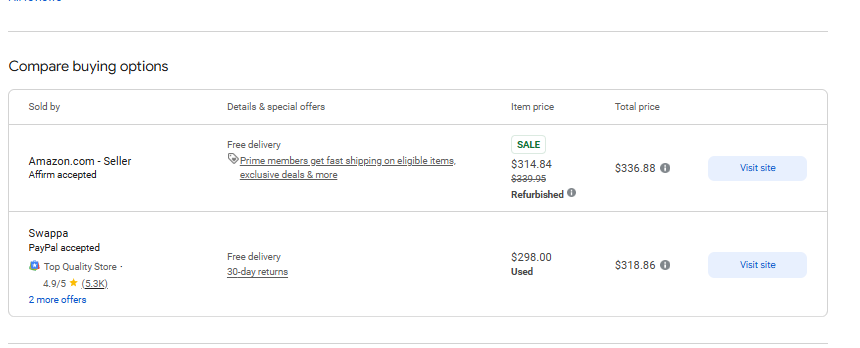
步骤 3. 获取特定数据
如图所示,我们需要的数据在 tr[jscontroller='d5bMlb'] 下:
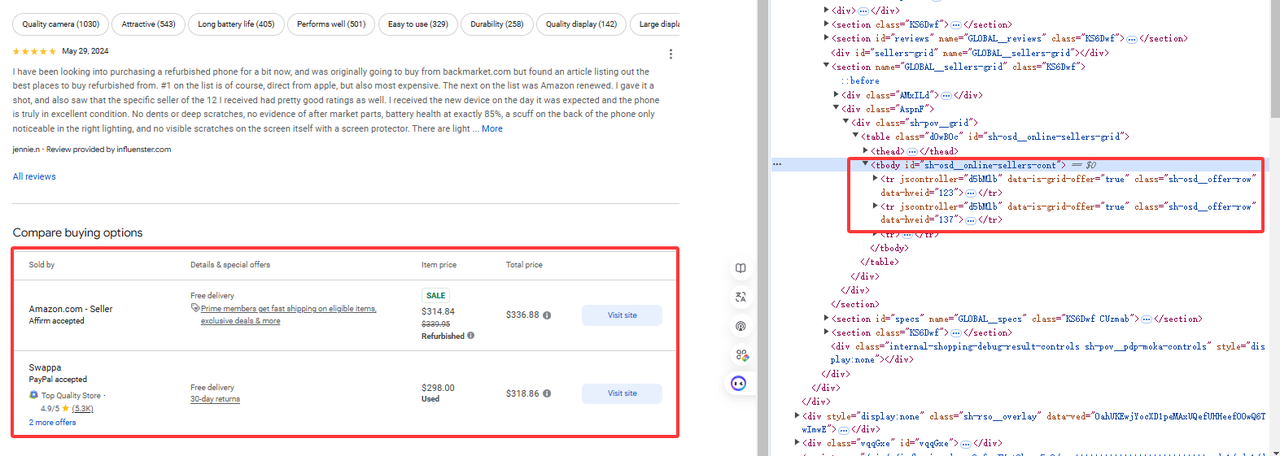
online_sellers = []
soup = BeautifulSoup(response.content, 'html.parser')
for i, row in enumerate(soup.find_all("tr", {"jscontroller": "d5bMlb"})):
name = row.find("a").get_text(strip=True)
payment_methods = row.find_all("div")[1].get_text(strip=True)
link = row.find("a")['href']
details_and_offers_text = row.find_all("td")[1].get_text(strip=True)
base_price = row.find("span", class_="g9WBQb fObmGc").get_text(strip=True)
badge = row.find("span", class_="XhDkmd").get_text(strip=True) if row.find("span", class_="XhDkmd") else ""
link = f"https://www.google.com/{link}"
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_sellers.append({
'name' : name,
'payment_methods' : payment_methods,
'link' : link,
'direct_link' : direct_link,
'details_and_offers' : [{"text": details_and_offers_text}],
'base_price' : base_price,
'badge' : badge
})然后使用 BeautifulSoup 解析 HTML 页面并获取相关的元素:
完整代码
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
class AdditionalPrice:
def __init__(self, shipping, tax):
self.shipping = shipping
self.tax = tax
class OnlineSeller:
def __init__(self, position, name, payment_methods, link, direct_link, details_and_offers, base_price,
additional_price, badge, total_price):
self.position = position
self.name = name
self.payment_methods = payment_methods
self.link = link
self.direct_link = direct_link
self.details_and_offers = details_and_offers
self.base_price = base_price
self.additional_price = additional_price
self.badge = badge
self.total_price = total_price
def sellers_results(url):
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/jpeg,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Priority": "u=0, i",
"Sec-Ch-Ua": '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
online_sellers = []
for i, row in enumerate(soup.find_all("tr", {"jscontroller": "d5bMlb"})):
name = row.find("a").get_text(strip=True)
payment_methods = row.find_all("div")[1].get_text(strip=True)
link = row.find("a")['href']
details_and_offers_text = row.find_all("td")[1].get_text(strip=True)
base_price = row.find("span", class_="g9WBQb fObmGc").get_text(strip=True)
badge = row.find("span", class_="XhDkmd").get_text(strip=True) if row.find("span", class_="XhDkmd") else ""
link = f"https://www.google.com/{link}"
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_sellers.append({
'name' : name,
'payment_methods' : payment_methods,
'link' : link,
'direct_link' : direct_link,
'details_and_offers' : [{"text": details_and_offers_text}],
'base_price' : base_price,
'badge' : badge
})
return online_sellers
url = 'https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8'
sellers = sellers_results(url)
for seller in sellers:
print(seller)控制台打印结果如下:

限制
当然,我们可以使用上面获取部分数据的示例来获取数据,但是存在IP被封的风险。我们不能进行大量的请求,这会触发谷歌的产品风险控制。
方法 3:使用 Selenium 抓取谷歌在线卖家产品信息
在这种方法中,我们将探讨如何使用 Selenium(一个强大的 Web 自动化工具)从在线卖家处抓取谷歌产品列表。与 Requests 和 BeautifulSoup 不同,Selenium 允许我们与需要 JavaScript 执行的动态页面进行交互,这使其非常适合抓取动态加载内容的谷歌产品列表。
步骤 1:设置环境
首先,确保您的系统上安装了 Python。并创建一个新目录来存储此项目的代码。接下来,您需要安装 selenium 和 webdriver_manager。您可以通过 PIP 执行此操作:
pip install selenium
pip install webdriver_manager步骤 2:初始化 selenium 环境
现在,我们需要添加一些 selenium 的配置项并初始化环境。
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)步骤 3:获取特定数据
我们使用 selenium 获取 product_id 为 4172129135583325756 的产品,并抓取一些 OnlineSeller 的数据
driver.get(url)
time.sleep(5) #wait page
online_sellers = []
rows = driver.find_elements(By.CSS_SELECTOR, "tr[jscontroller='d5bMlb']")
for i, row in enumerate(rows):
name = row.find_element(By.TAG_NAME, "a").text.strip()
payment_methods = row.find_elements(By.TAG_NAME, "div")[1].text.strip()
link = row.find_element(By.TAG_NAME, "a").get_attribute('href')
details_and_offers_text = row.find_elements(By.TAG_NAME, "td")[1].text.strip()
base_price = row.find_element(By.CSS_SELECTOR, "span.g9WBQb.fObmGc").text.strip()
badge = row.find_element(By.CSS_SELECTOR, "span.XhDkmd").text.strip() if row.find_elements(By.CSS_SELECTOR, "span.XhDkmd") else ""完整代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
from urllib.parse import urlparse, parse_qs
class AdditionalPrice:
def __init__(self, shipping, tax):
self.shipping = shipping
self.tax = tax
class OnlineSeller:
def __init__(self, position, name, payment_methods, link, direct_link, details_and_offers, base_price, additional_price, badge, total_price):
self.position = position
self.name = name
self.payment_methods = payment_methods
self.link = link
self.direct_link = direct_link
self.details_and_offers = details_and_offers
self.base_price = base_price
self.additional_price = additional_price
self.badge = badge
self.total_price = total_price
def sellers_results(url):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
try:
driver.get(url)
time.sleep(5)
online_sellers = []
rows = driver.find_elements(By.CSS_SELECTOR, "tr[jscontroller='d5bMlb']")
for i, row in enumerate(rows):
name = row.find_element(By.TAG_NAME, "a").text.strip()
payment_methods = row.find_elements(By.TAG_NAME, "div")[1].text.strip()
link = row.find_element(By.TAG_NAME, "a").get_attribute('href')
details_and_offers_text = row.find_elements(By.TAG_NAME, "td")[1].text.strip()
base_price = row.find_element(By.CSS_SELECTOR, "span.g9WBQb.fObmGc").text.strip()
badge = row.find_element(By.CSS_SELECTOR, "span.XhDkmd").text.strip() if row.find_elements(By.CSS_SELECTOR, "span.XhDkmd") else ""
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_seller = {
'name': name,
'payment_methods': payment_methods,
'link': link,
'direct_link': direct_link,
'details_and_offers': [{"text": details_and_offers_text}],
'base_price': base_price,
'badge': badge
}
online_sellers.append(online_seller)
return online_sellers
finally:
driver.quit()
url = 'https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8'
sellers = sellers_results(url)
for seller in sellers:
print(seller)控制台打印结果如下:

限制
Selenium 是一个强大的 Web 浏览器操作自动化工具,广泛用于自动化测试和 Web 数据抓取。但是,它需要等待页面加载,因此在数据抓取过程中相对较慢。
常见问题
大规模抓取谷歌产品列表的最佳方法是什么?
大规模抓取谷歌产品信息最有效的方法是使用 Scrapeless。它提供快速且可扩展的 API,有效地处理动态内容、IP 封锁和 CAPTCHA,使其成为企业的理想选择。
如何绕过谷歌的反抓取措施来抓取产品列表?
谷歌采用了几种反抓取措施,包括 CAPTCHA 和 IP 封锁。Scrapeless 提供了一个可以绕过这些措施并确保流畅、不间断数据提取的 API。
我可以使用 BeautifulSoup 或 Selenium 等 Python 库来抓取谷歌产品列表吗?
虽然 BeautifulSoup 和 Selenium 可用于抓取谷歌产品列表,但它们有一些局限性,例如性能缓慢、检测风险以及无法扩展。Scrapeless 提供了一个更有效的解决方案,可以处理所有这些问题。
结论
在本文中,我们讨论了三种抓取谷歌在线卖家产品信息的方法:Requests & BeautifulSoup、Selenium 和 Scrapeless。每种方法都有其独特的优势,但是当涉及到大规模抓取时,Scrapeless 无疑是企业最佳的选择。
- Requests & BeautifulSoup 适用于小型抓取任务,但在处理动态内容或扩展时存在局限性。这些工具还存在被反抓取措施阻止的风险。
- Selenium 对于 JavaScript 渲染的页面有效,但它资源密集型且速度比其他选项慢,因此不太适合大规模抓取谷歌产品列表。
另一方面,Scrapeless解决了与传统抓取方法相关的所有挑战。它快速、可靠且合法,确保您可以高效地大规模抓取谷歌在线卖家产品信息,而无需担心被阻止或遇到其他障碍。
对于寻求简化、可扩展解决方案的企业来说,Scrapeless 是首选工具。它绕过了传统方法的所有障碍,并为收集谷歌产品数据提供了流畅、无障碍的体验。
立即免费试用 Scrapeless,了解扩展谷歌产品抓取任务是多么容易。立即开始免费试用。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


