
如何用Python抓取Google产品评论结果
Advanced Data Extraction Specialist
随着数字浪潮席卷全球,谷歌作为全球最大的搜索引擎之一,在其搜索结果页面 (SERP) 中隐藏着海量宝贵的數據。这些数据不仅仅是简单的信息列表,更是洞察市场动态、分析竞争对手以及理解消费者行为的关键。
然而,高效有效地抓取谷歌搜索结果并非易事。谷歌产品的页面结构复杂且多变,并且拥有强大的反爬虫机制,使得传统的數據抓取方法往往难以奏效。为了应对这些挑战,一个强大、可扩展且灵活的数据管道,能够适应谷歌结构的变化,显得尤为重要。无论您计划构建自己的大型语言模型 (LLM) ,还是想从市场获得第一手的消费者洞察,一个可靠的谷歌搜索爬虫都是必不可少的。
在本文中,我们将重点介绍如何使用 Python 和 BeautifulSoup 库从零开始构建一个谷歌产品评论结果爬虫。借助此工具,您将能够自动提取宝贵的数据,并从搜索引擎的数据海洋中挖掘出可直接用于决策的洞察。
抓取谷歌产品结果的用例
抓取谷歌产品结果已成为企业和研究人员获取市场洞察的重要手段。通过分析这些数据,企业可以了解市场趋势、消费者偏好和竞争对手动态,从而制定更有效的业务战略。以下是一些常见的用例:
- 市场研究和趋势分析
- 竞争对手分析
- 产品开发和优化
- 消费者行为洞察
- 价格监控和调整
- 品牌保护和声誉管理
- 电子商务和在线零售优化
- 学术研究和数据分析
- 公共政策制定和监督
抓取谷歌产品评论的难点
提取谷歌产品评论面临着一些挑战,包括:
反爬虫措施
- 谷歌使用 CAPTCHA 和 IP 封锁来防止机器人访问。
- 需要代理和用户代理轮换来绕过。
动态和 JavaScript 渲染的内容
- 评论通过 JavaScript 动态加载。
- 需要使用 Puppeteer 或 Selenium 等工具来提取数据。
频繁的 DOM 结构变化
- 谷歌定期更新其 HTML 结构。
- 爬虫需要不断维护。
方法一:使用 Scrapeless 抓取谷歌产品评论结果
使用 Python 抓取谷歌产品评论需要处理动态内容加载和反爬虫机制等挑战。本节将探讨有效的方法和工具,以高效地提取评论数据。
步骤一:构建谷歌产品数据抓取环境
首先,我们需要构建一个数据抓取环境,并准备以下工具:
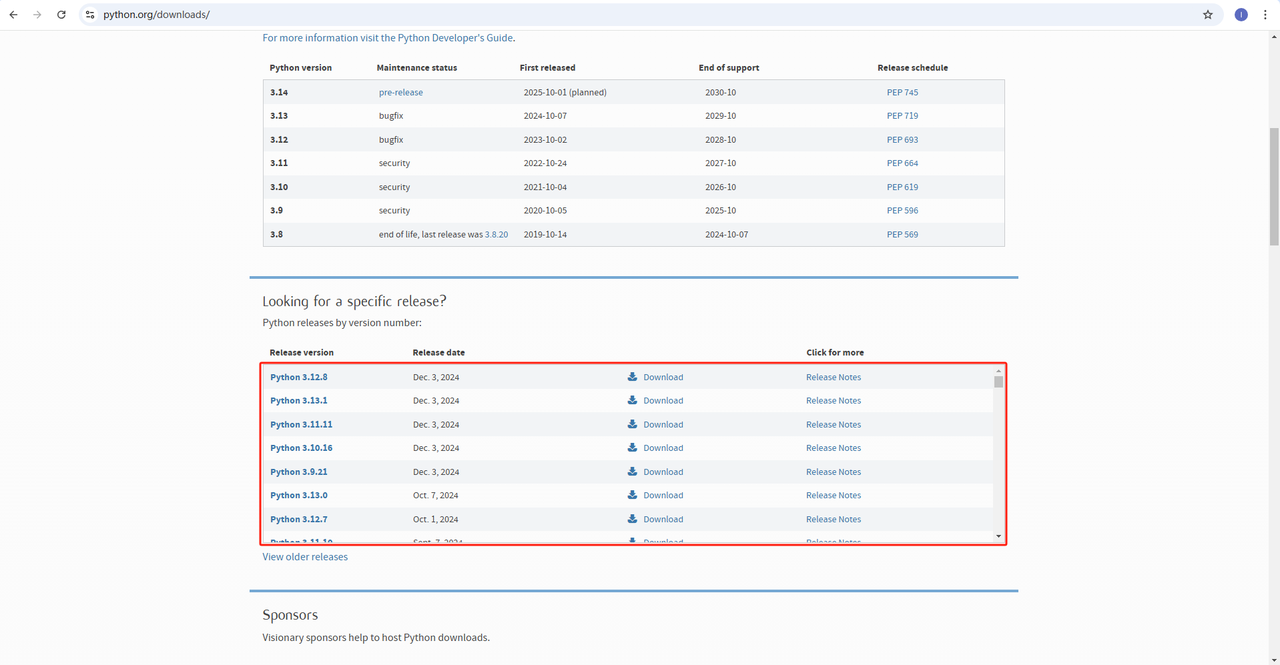
1. Python: 这是运行 Python 的核心软件。您可以从官方网站链接下载所需版本,如下图所示,但建议不要下载最新版本。您可以下载最新版本之前的 1-2 个版本。
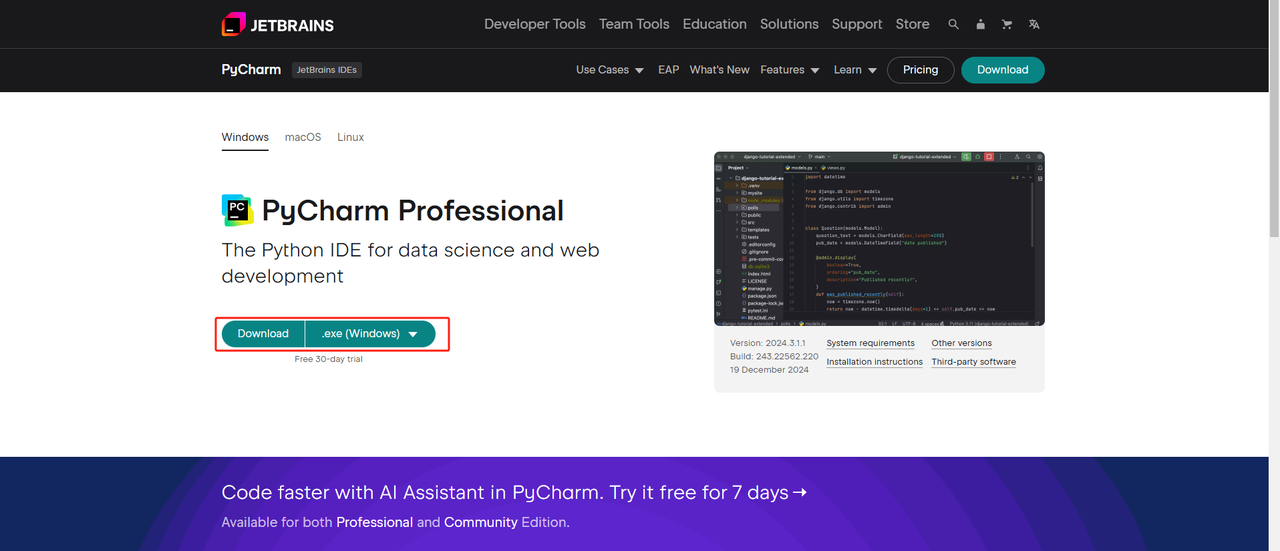
**2. Python IDE:**任何支持 Python 的 IDE 都可以,但我们推荐 PyCharm,它是一款专门为 Python 设计的 IDE 开发工具软件。关于 PyCharm 版本,我们推荐免费的 PyCharm 社区版。
**3. Pip:**您可以使用 Python 包索引,通过单个命令安装运行程序所需的库。
**注意:**如果您是 Windows 用户,请不要忘记在安装向导中选中“将 python.exe 添加到 PATH”选项。这将允许 Windows 在终端中使用 Python 和命令。由于 Python 3.4 或更高版本默认包含它,因此您无需手动安装它。
通过以上步骤,谷歌产品数据抓取的环境就搭建好了。接下来,您可以使用下载的 PyCharm 结合 Scraperless 来抓取谷歌产品数据。
步骤二:使用 PyCharm 和 Scrapeless 抓取谷歌产品数据
-
启动 PyCharm 并从菜单栏中选择文件>新建项目…
-
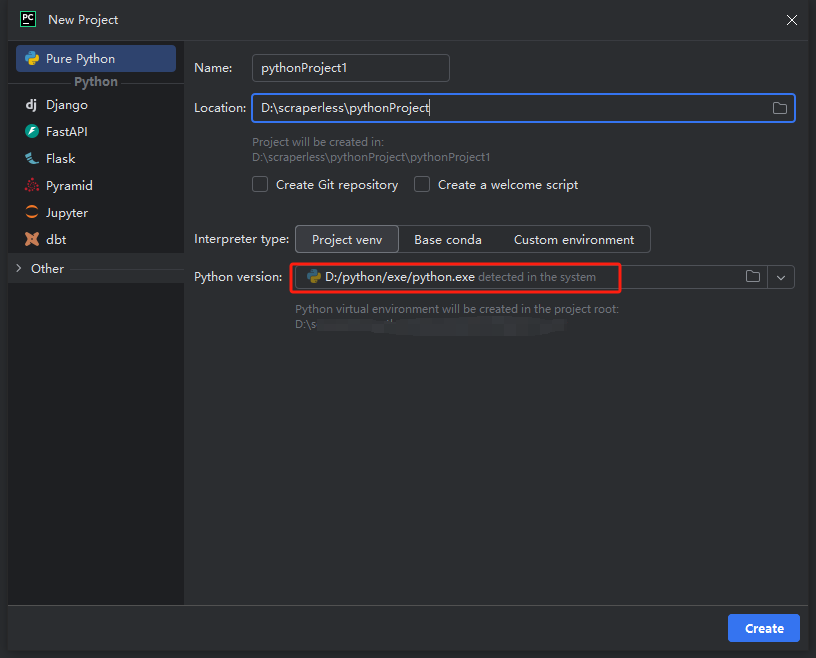
然后,在弹出的窗口中,从左侧菜单中选择纯 Python 并按照如下设置您的项目:
**注意:**在下面的红色方框中,选择在环境配置第一步中下载的 Python 安装路径
- 您可以创建一个名为 python-scraper 的项目,选中“在文件夹中创建 main.py 欢迎脚本选项”,然后点击“创建”按钮。PyCharm 设置项目一段时间后,您应该看到如下内容:
-
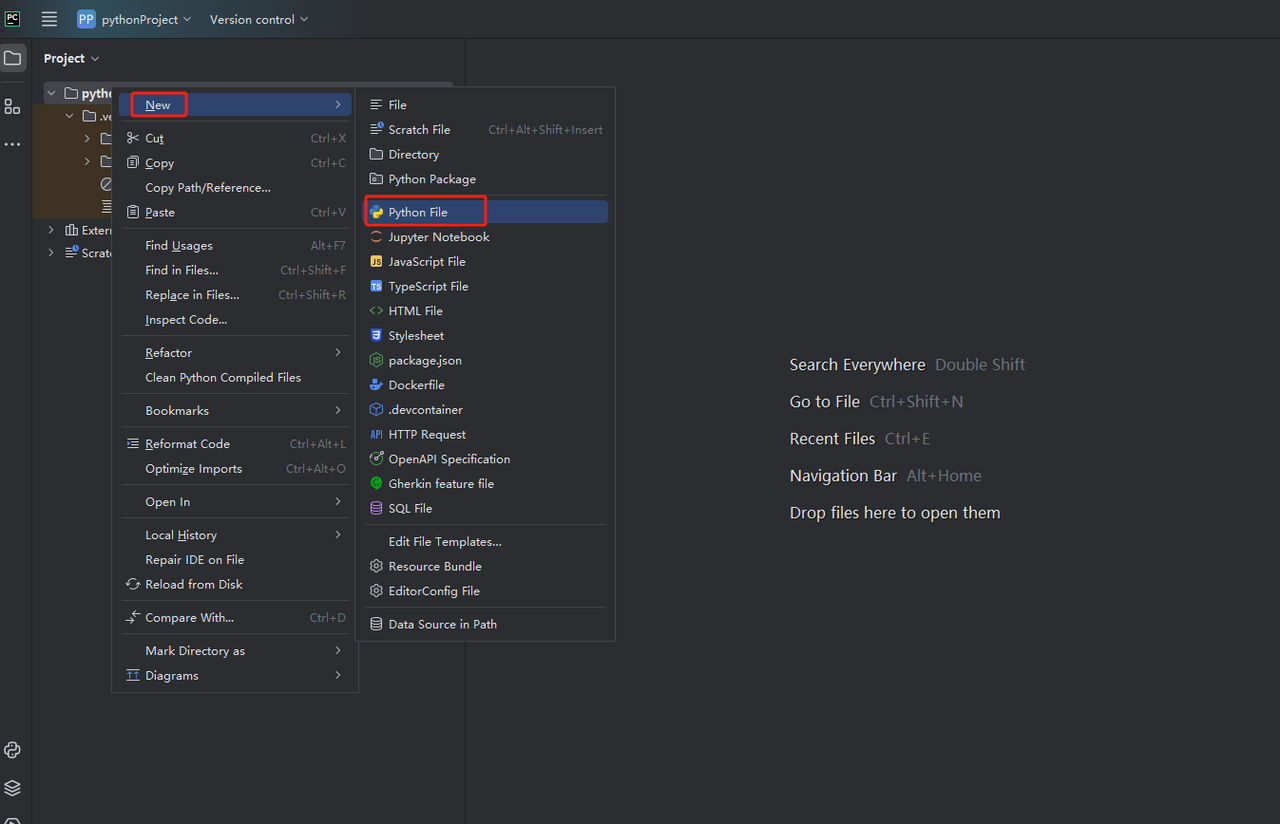
然后,右键单击以创建新的 Python 文件。
-
为验证一切正常,打开屏幕底部的终端选项卡并键入:python main.py。启动此命令后,您应该会得到:Hi, PyCharm。
步骤三:获取 Scrapeless API 密钥
现在您可以直接将 Scrapeless 代码复制到 PyCharm 中并运行它,这样您就可以获得 Google Job 的 JSON 格式数据。但是,您首先需要获取 Scrapeless API 密钥。步骤如下:
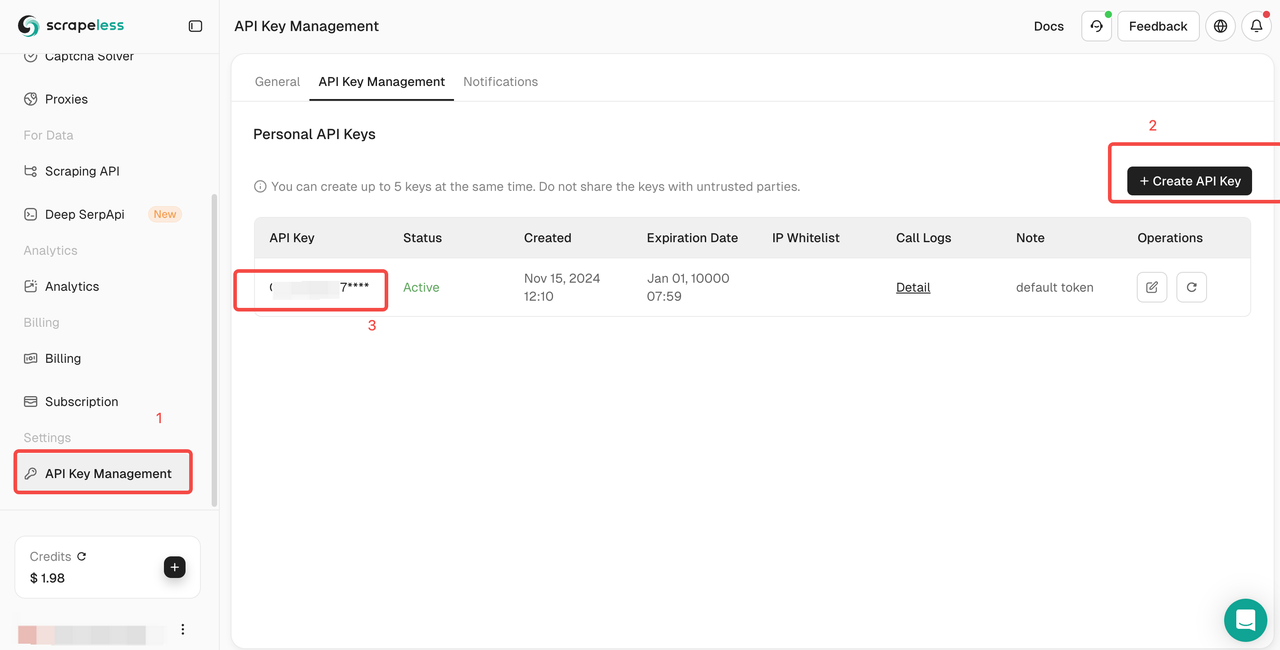
- 如果您还没有帐户,请注册 Scrapeless。注册后,登录您的仪表板。
- 在您的 Scrapeless 仪表板中,导航到 API 密钥管理并点击创建 API 密钥。您将获得您的 API 密钥。只需将鼠标放在上面并单击即可复制它。此密钥将在调用 Scrapeless API 时用于验证您的请求。
我们坚决保护网站的隐私。本博客中的所有数据都是公开的,仅用作抓取过程的演示。我们不会保存任何信息和数据。
加入 Scrapeless 并获得 20,000 次免费查询!
立即注册 Scrapeless 并享受我们提供的 20,000 次免费查询!轻松开始抓取谷歌产品评论并解锁有价值的见解。不要错过——立即注册并免费体验 Scrapeless 的强大功能!
步骤四:如何将 Scrapeless API 集成到您的抓取工具中
获得 API 密钥后,您可以开始将 Scrapeless API 集成到您自己的抓取工具中。以下是如何使用 Python 和 requests 调用 Scrapeless API 并检索数据的示例。
使用 Scrapeless API 抓取 Google 产品信息的示例代码:
python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_product",
"product_id": "4172129135583325756",
"gl": "us",
"hl": "en",
}
payload = Payload("scraper.google.product", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()根据此代码的输出,您可以找到所有关于谷歌产品评论的信息。
您还可以参考官方 Scrapeless API 参数文档
以下是部分结果列表,其中包括用户评论信息。
json
body {"product_results":{"product_id":"4172129135583325756","title":"Apple iPhone 12 Pro - 128 GB - Silver - AT\u0026T","price":["$314.84","$298.00","$325.33"],"reviews":14303,"rating":4.4,"extensions":["Smartphone","Dual SIM","5G","With Wireless Charging","With Fast Charging","AT\u0026T","Dual Lens","iOS","GSM","CDMA"],"description":"5G goes Pro. A14 Bionic rockets past every other smartphone chip. The iPhone 12 Pro features a 6.1” Super Retina XDR display, LiDAR scanner for ultrafast and accurate depth maps of whatever space you're in and MagSafe wireless charging. The Pro camera system takes low-light ...More5G goes Pro. A14 Bionic rockets past every other smartphone chip. The iPhone 12 Pro features a 6.1” Super Retina XDR display, LiDAR scanner for ultrafast and accurate depth maps of whatever space you're in and MagSafe wireless charging. The Pro camera system takes low-light photography to the next level with Night mode available in both the Wide and Ultra Wide cameras, so it’s better than ever at capturing incredible low-light shots. And Ceramic Shield delivers four times better drop performance.Less","media":[{"type":"image","link":"https://encrypted-tbn0.gstatic.com/shopping?q=tbn:ANd9GcStw-jdTZtGmdXcVKCqweq6wxzU5tpRTTbl6stPV97GpGVR6XY\u0026usqp=CAY"},{"type":"image","link":"https://encrypted-tbn1.gstatic.com/shopping?q=tbn:ANd9GcR0wJ1fsUOPAGDMtjdtx1zsd5ZWUXwnNe70fmZszERkEihkYCKnZoGJ3Y4lqSQTyR4soiTVWFVzllzYTHJBTRXegTR7Pj83RA\u0026usqp=CAY"},{"type":"image","link":"https://encrypted-tbn1.gstatic.com/shopping?q=tbn:ANd9GcR4L66Gss9O5HSL00NLxaHu0pl5huMUojbC9tO9FKCRpCQObUqdHWsSPYZJ4lU8eETn-MlJx4Hni_oc_l5mxIs_l-Z2htBiaA\u0026usqp=CAY"},{"type":"image","link":"https://encrypted-tbn0.gstatic.com/shopping?q=tbn:ANd9GcQLv5xOi-9b-Mka7jfFnQzlXkTrEAsjPAzumbUB2D6Ddgl3FHGZOQXAUGQAv6WkUeZsbsdvKA2NRF1-h8EOBSQPLmuPMLPQ2Q\u0026usqp=CAY"}],"sizes":{"128 GB":{"link":"https://www.google.com/shopping/product/4172129135583325756?gl=us\u0026hl=en\u0026sourceid=chrome\u0026ie=UTF-8","product_id":"4172129135583325756"},"256 GB":{"link":"https://www.google.com/shopping/product/1700752269234454309?gl=us\u0026hl=en\u0026sourceid=chrome\u0026ie=UTF-8\u0026prds=opd:11579479524734831751,rsk:PC_14243855303706753583\u0026sa=X\u0026ved=0ahUKEwjxhNXT2ZeMAxVcK7kGHUh1ErMQlIUHCEQoAQ","product_id":"1700752269234454309"},"512 GB":{"link":"https://www.google.com/shopping/product/14752474427020499512?gl=us\u0026hl=en\u0026sourceid=chrome\u0026ie=UTF-8\u0026prds=opd:11579479524734831751,rsk:PC_14243855303706753583\u0026sa=X\u0026ved=0ahUKEwjxhNXT2ZeMAxVcK7kGHUh1ErMQlIUHCEUoAg","product_id":"14752474427020499512"}},"highlight":["5G transforms iPhone with accelerated wireless speeds and better performance on congested networks","A14 Bionic: generations ahead of any other smartphone chip","Night mode comes to both the Wide and Ultra Wide cameras, and it's better than ever at capturing incredible low-light shots",为什么使用 Scrapeless 抓取谷歌产品评论
- **价格实惠:**Scrapeless 每 1,000 次查询仅需 0.1 美元,为需要扩展数据收集而又不超出预算的企业提供了非常经济高效的解决方案。
- **快速可靠:**Scrapeless 的响应时间不到 3 秒,可提供实时结果,确保您快速高效地获取所需数据——这对于快节奏的商业环境至关重要。
- **易于使用:**Scrapeless 具有直观的界面,允许技术专业知识有限的团队以最少的设置开始使用,从而减少了对大量培训的需求。
- **可扩展的数据收集:**无论您是为小型项目还是企业级分析收集数据,Scrapeless 都能随着您的业务需求而扩展,使您能够轻松处理大量查询。
- **可定制的抓取:**Scrapeless 允许您根据特定需求定制数据提取——无论您是针对特定产品、地区还是评论类型,它都能为您提供灵活地收集最相关见解的能力。
- **增强决策:**Scrapeless 帮助企业从谷歌产品评论中获得宝贵的见解,有助于客户情绪分析和产品改进决策。这对于希望保持竞争力的企业尤其重要。
- **无缝集成:**通过将 Scrapeless 与其他业务工具集成的选项,您的团队可以在现有系统中直接分析收集到的数据,从而更容易快速根据见解采取行动。
加入我们的 Discord 社区并与 TOB 客户联系!
加入我们的 Discord 社区 以与其他 TOB 客户建立联系,分享见解并讨论策略。此外,还可以直接访问我们的团队以获得个性化支持——无论您需要自定义解决方案、数据测试还是指导。不要错过这个机会来增强您的 Scrapeless 体验!
方法二:使用 Python 和 Selenium 抓取谷歌产品评论
先决条件
在开始之前,请确保您拥有以下内容:
- 已安装 Python(推荐 3.x)
- Google Chrome 和 ChromeDriver
- 必需的 Python 库:
bash
pip install selenium beautifulsoup4 pandas步骤一:设置 Selenium WebDriver
Selenium 允许我们自动化 Web 交互。首先,我们需要初始化 Chrome WebDriver:
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
service = Service('path/to/chromedriver') # 更新为正确的路径
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 在无头模式下运行
driver = webdriver.Chrome(service=service, options=options)
driver.get('https://www.google.com/shopping/product/1234567890/reviews') # 示例 URL步骤二:提取评论数据
我们使用 BeautifulSoup 解析页面源代码并提取评论详细信息。
python
from bs4 import BeautifulSoup
def extract_reviews(driver):
soup = BeautifulSoup(driver.page_source, 'html.parser')
reviews = []
for review in soup.find_all('div', class_='sh-dgr__content'):
rating = review.find('div', class_='sh-dgr__rating')
text = review.find('div', class_='sh-dgr__review-text')
if rating and text:
reviews.append({
'rating': rating.text.strip(),
'review': text.text.strip()
})
return reviews
data = extract_reviews(driver)
print(data)步骤三:自动化分页
如果有多个评论页面,我们需要自动化分页。
python
def scrape_multiple_pages(driver):
all_reviews = []
while True:
all_reviews.extend(extract_reviews(driver))
try:
next_button = driver.find_element(By.XPATH, '//a[@aria-label="Next page"]')
next_button.click()
time.sleep(2) # 等待新页面加载
except:
break
return all_reviews
data = scrape_multiple_pages(driver)
print(f'Total Reviews Scraped: {len(data)}')步骤四:将数据保存到 CSV
收集数据后,我们可以将其保存以进行进一步分析。
python
import pandas as pd
df = pd.DataFrame(data)
df.to_csv('google_reviews.csv', index=False)
print('Reviews saved to google_reviews.csv')比较:Scrapeless 与 Selenium + BeautifulSoup 抓取谷歌产品评论
下表比较了为什么 Scrapeless 是抓取谷歌产品评论的更好选择:
| 方面 | Scrapeless 🚀(推荐) | Selenium + BeautifulSoup ⚙️(传统方法) |
|---|---|---|
| 易用性 | 无需编码,只需 API 调用 | 需要编写和维护 Python 代码 |
| 反爬虫措施 | 内置绕过机制 | 易于被 Google 检测到,可能会被阻止 |
| 速度 | 基于云,更快的抓取 | 本地运行,由于页面加载而速度较慢 |
| 维护成本 | 无需维护,Scrapeless 处理网站更新 | 需要频繁更新代码以适应页面更改 |
| 数据质量 | 结构化数据,JSON/CSV 输出 | 需要手动 HTML 解析,可能不一致 |
| 多页抓取 | 自动处理分页 | 需要手动编写分页代码 |
| 环境设置 | 无需其他软件,基于 API | 需要 ChromeDriver 和复杂的设置 |
结论
Scrapeless、Selenium 和 Scrapy 都是抓取谷歌产品评论数据的可行方案,但各有优缺点:
- Scrapeless 是最简单、最有效的选项,尤其是在您需要快速获取结构化数据的情况下。它可以自动处理反爬虫机制和动态内容加载。
- Selenium 提供强大的动态内容处理能力,但性能低,维护成本高,并且易于被检测到。
- Scrapy 是一个高效的爬虫框架,适用于大规模数据抓取,但它难以处理动态内容并且学习曲线陡峭。
总而言之,如果您想快速、高效且稳定地获取谷歌产品评论数据,Scrapeless 是最佳选择。它不仅简化了抓取过程,而且避免了复杂的开发和维护工作。使用任何工具时,请务必遵守谷歌的服务条款,以免造成不必要的法律风险。
准备好将您的数据抓取提升到一个新的水平了吗?
不要让您的业务落后!立即注册 Scrapeless 并开始轻松抓取谷歌产品评论。只需几个简单的 API 调用,您就可以访问宝贵的见解,以改进您的产品开发和客户参与度。此外,Scrapeless 不仅限于评论——您可以使用它来收集各种平台的数据,分析竞争对手,跟踪趋势等等!
立即加入并获得20,000 次免费查询,探索 Scrapeless 提供的所有强大功能。无论您从事电子商务、市场营销还是研究,Scrapeless 都是您进行高效、可扩展和可定制数据提取的首选工具。
立即注册 并查看它对您的业务产生的影响!
更多资源
您可能也对以下数据捕获感兴趣,欢迎与我们讨论。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


