
如何用Python爬取Google Play商店应用
Advanced Data Extraction Specialist
Google Play 商店包含海量应用数据,包括应用名称、开发者信息、评分、下载次数和用户评论。这些数据对于市场分析、竞争对手研究、应用商店优化 (ASO) 和自动化数据监控至关重要。例如,开发者可以抓取 Google Play 商店数据来分析竞争对手的更新频率、趋势关键词和用户反馈,从而优化其产品策略。
此外,市场研究人员可以通过收集和分析 Play 商店数据来追踪特定应用类别的增长趋势。
但是,由于以下几个挑战,抓取 Google Play 商店并非易事:
- 动态内容加载: 大多数应用信息都是使用 JavaScript 渲染的,这使得无法使用传统的请求 + BeautifulSoup 方法提取完整数据。
- 反抓取机制: Google 会检测异常访问模式,并使用 CAPTCHA、IP 限制和其他对策来阻止抓取器。
- 复杂的 HTML 结构: Google Play 商店页面的结构经常发生变化,要求抓取器不断更新。
在本文中,我们将探讨几种基于 Python 的常用抓取方法,包括 Requests + BeautifulSoup,同时分析它们的优缺点。最后,我们将介绍一个更高效、更可靠的解决方案——Scrapeless——它允许您轻松提取 Google Play 商店数据,无需编写复杂的抓取脚本。
了解 Google Play 商店抓取的挑战
抓取 Google Play 商店具有挑战性,因为有一些内置的保护措施可以防止自动化数据提取。在深入了解如何抓取 Google Play 商店之前,务必了解抓取器面临的关键障碍。
1. 动态内容加载
Google Play 商店的许多部分,包括应用描述、评论和评分,都是使用 JavaScript 动态加载的。这意味着简单的 requests + BeautifulSoup 方法不起作用,因为原始 HTML 响应不包含完整的应用详细信息。相反,Google Play 抓取器需要渲染 JavaScript 以提取完整数据,这通常需要 Selenium 或 Puppeteer 等工具。
2. 反抓取机制
Google Play 商店已实施多种反抓取机制来检测和阻止自动化请求。其中一些包括:
- CAPTCHA:来自单个 IP 的请求过多后,Google Play 商店会提示进行 CAPTCHA 验证,使抓取器难以继续。
- IP 速率限制:Google 会跟踪异常流量模式,并可能暂时或永久阻止发送过多请求的 IP 地址。
- 用户代理检测:发送没有正确标头(如浏览器用户代理)的请求可能会很快导致阻止。
Google Play 商店抓取器必须使用轮换代理、CAPTCHA 解决技术和真实的浏览器标头来绕过这些限制。
3. 持续的 HTML 结构变化
Google 经常更新其 Play 商店页面的布局和结构。这意味着今天构建的 Google Play 抓取器可能会在几个月后失效,除非定期更新。对于依赖网络抓取进行数据提取的开发者来说,这是一个常见的挑战。
4. API 限制
Google 没有提供用于抓取 Google Play 商店数据的免费官方 API。虽然存在一些第三方 API,但它们通常有速率限制、需要订阅或缺乏数据提取的灵活性。
方法 1:使用 Requests & BeautifulSoup 抓取 Google Play 商店
抓取 Google Play 商店最简单的方法之一是使用 Python 的 requests 库来获取 HTML,并使用 BeautifulSoup 来解析页面。这种方法很简单,但有一些限制,我们将在下面讨论。
注意: 我们坚决保护网站的隐私。本博客中的所有数据都是公开的,仅用于演示爬取过程。我们不会保存任何信息和数据。
如何使用 Requests & BeautifulSoup 抓取 Google Play 商店
以下是如何使用 requests 和 BeautifulSoup 从 Google Play 商店提取应用详细信息的简单示例:
import requests
from bs4 import BeautifulSoup
# 定义应用页面的 URL
app_url = "https://play.google.com/store/apps/details?id=com.whatsapp"
# 设置标头以模拟真实的浏览器请求
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
# 发送请求
response = requests.get(app_url, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# 提取应用名称
app_name = soup.find("h1", class_="Fd93Bb F5UCq").text if soup.find("h1", class_="Fd93Bb F5UCq") else "Not Found"
# 提取应用描述
app_description = soup.find("div", class_="bARER").text if soup.find("div", class_="bARER") else "Not Found"
print(f"App Name: {app_name}")
print(f"Description: {app_description}")
else:
print(f"Failed to fetch the page, status code: {response.status_code}")一些抓取结果如下所示:
Description: WhatsApp from Meta is a FREE messaging and video calling app. It’s used by over 2B people in more than 180 countries. It’s simple, reliable, and private, so you can easily keep in touch with your friends and family. WhatsApp works across mobile and desktop even on slow connections, with no subscription fees*.Private messaging across the worldYour personal messages and calls to friends and family are end-to-end encrypted. No one outside of your chats, not even WhatsApp, can read or listen to them.Simple and secure connections, right awayAll you need is your phone number, no user names or logins. You can quickly view your contacts who are on WhatsApp and start messaging.High quality voice and video callsMake secure video and voice calls with up to 8 people for free*. Your calls work across mobile devices using your phone’s Internet service, even on slow connections.Group chats to keep you
.....使用 Requests & BeautifulSoup 抓取 Google Play 商店的局限性
虽然 requests 和 BeautifulSoup 提供了一种简单的抓取 Google Play 商店的方法,但这种方法有一些缺点:
❌ 无法处理动态内容
- Google Play 商店通过 JavaScript 动态加载许多元素,例如评论和评分。由于 requests 只获取原始 HTML,因此动态加载的数据将丢失。
- 许多应用详细信息(如开发者信息和用户评论)需要执行 JavaScript,requests 无法处理。
❌ 易被 Google 阻止
- Google Play 具有严格的反抓取机制,可以检测异常流量模式。如果您从同一 IP 发送多个请求,Google 可能会阻止访问或显示 CAPTCHA。
- 使用静态标头可以暂时有所帮助,但最终您的抓取器会被标记。
❌ 使用案例有限
- 由于此方法无法渲染 JavaScript,因此它仅适用于抓取不需要执行 JavaScript 的静态内容。
- 如果您需要详细信息,例如用户评论、更新历史记录或应用屏幕截图,则此方法不起作用。
何时使用 Requests & BeautifulSoup 抓取 Google Play 商店?
尽管有其局限性,但此方法对于不需要执行 JavaScript 的小型抓取任务仍然有用,例如:
✅ 提取应用名称和基本描述
✅ 获取应用包 ID 以进行快速查找
✅ 抓取类别、排名或静态元数据
方法 2:使用 Scrapeless 抓取 Google Play 商店(B2B 需求的更好性能)
对于依赖 Google Play 商店抓取器解决方案进行市场情报、广告跟踪或竞争对手研究的企业来说,传统的网络抓取方法(如 Selenium 或 Scrapy)可能速度慢、不可靠且需要高维护成本。另一方面,Scrapeless 提供了一个可扩展的基于 API 的解决方案,可以高效地抓取 Google Play 商店,而无需基础设施管理或处理 Google 的反抓取保护。
为什么 Scrapeless 是 B2B Google Play 抓取的最佳选择?
🚀 消除抓取挑战 – Scrapeless 提供了一个完全托管的 Google Play 抓取器,绕过 Google 的反抓取机制,无需代理或浏览器自动化。
💰 降低运营成本 – 维持您自己的 Google Play 商店抓取器需要不断更新、代理轮换和 CAPTCHA 处理。Scrapeless 消除了这些成本,API 定价低至每 1K 个请求 0.1 美元,使其成为 B2B 数据需求的经济高效的选择。
📊 可操作的结构化数据 – API 提供清洗的结构化 JSON 数据,使企业能够轻松监控应用趋势、跟踪竞争对手或为机器学习模型提供动力,而无需处理数据解析和清洗。
如何使用 Scrapeless 作为 Google Play 商店抓取器(Python API 示例)
对于需要大规模 Google Play 抓取的 B2B 公司,以下是如何在 Python 中使用 Scrapeless 获取应用数据:
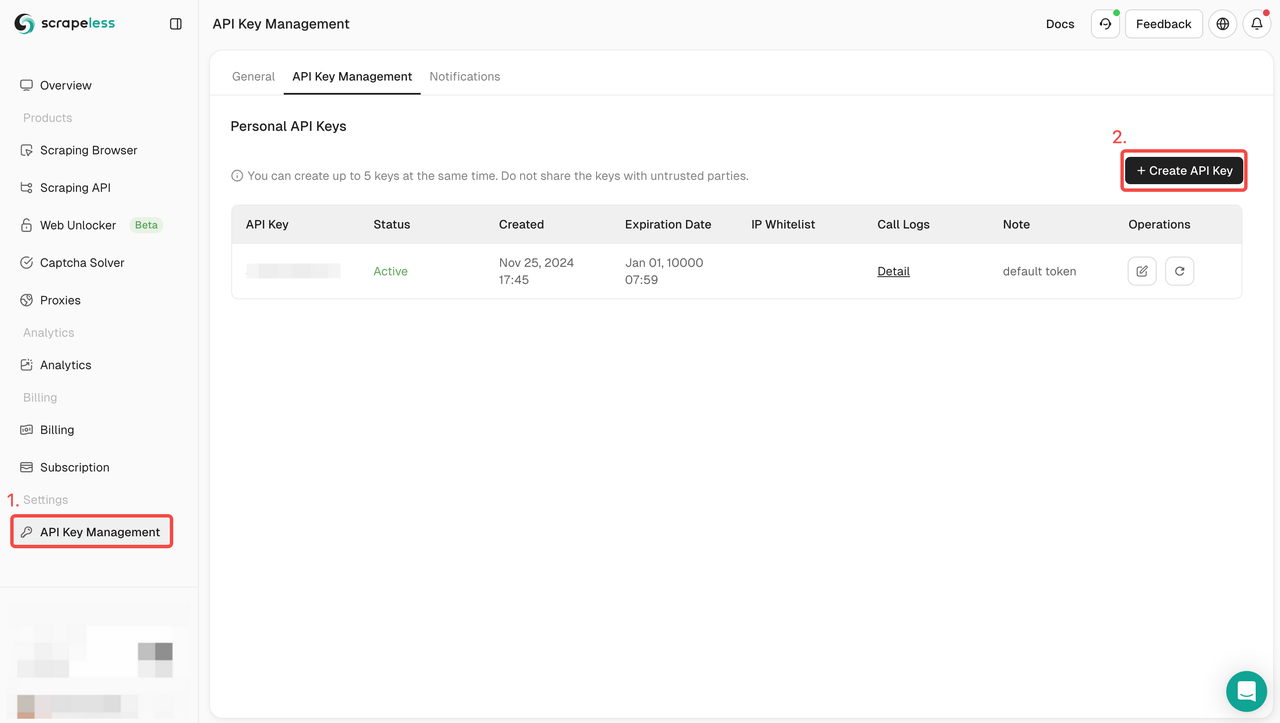
步骤 1:创建您的 Google Play 商店 API 令牌
要开始使用,您需要从 Scrapeless 仪表板获取 API 密钥:
- 登录到 Scrapeless 仪表板。
- 导航到API 密钥管理。
- 点击创建以生成您的唯一 API 密钥。
- 创建后,只需点击 API 密钥即可复制它。
Scrapeless 的价格仅为每 1000 次请求 0.1 美元,并提供免费试用,让您体验高效的 Google Play 商店数据抓取服务。
步骤 2:编写 Python 脚本来集成 Scrapeless API
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"apps_category": "BEAUTY",
}
payload = Payload("scraper.google.play", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()有关更高级的参数信息,您可以查看 Scrapeless 的**官方 API 文档**
还要将“your_token”替换为您的 Scrapeless API 密钥
Scrapeless 作为 Google Play 商店抓取器的主要业务用例
-
竞争对手情报 – 监控竞争对手应用的更新、价格变化和客户情绪分析。
-
市场研究和趋势分析 – 提取历史和实时应用数据,以获得更深入的行业洞察。
-
广告情报和 ASO 优化 – 追踪关键词趋势、应用排名和开发者活动,以制定更有效的营销策略。
-
与企业系统的数据集成 – 将 Scrapeless API 轻松连接到内部分析、CRM 或自动化平台。
为什么选择 Scrapeless 而非传统的 Google Play 抓取方法?
| 方法 | 速度 | 绕过反抓取 | 处理 JavaScript | 需要维护 | 最适合 |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | ⚡⚡ | ❌ 否 | ❌ 否 | ✅ 是 | 小规模抓取 |
| Selenium | ⚡ | ❌ 否 | ✅ 是 | ✅ 是 | JavaScript 密集型页面 |
| Scrapeless | ⚡⚡⚡⚡ | ✅ 是 | ✅ 是 | ❌ 否 | 大规模 B2B 数据提取 |
与传统的 Google Play 商店抓取器设置不同,Scrapeless 提供了一个完全托管的可扩展解决方案,使其成为需要可靠、结构化且经济高效的数据提取的企业的最佳选择。
免费试用 Scrapeless 并体验我们的 API 如何简化您的 Google Play 商店抓取过程。在此处开始您的免费试用!
加入我们的 Discord 社区 以获得支持、分享见解并随时了解最新功能。点击此处加入!
关于抓取 Google Play 商店的常见问题
Q1:如何处理 Google Play 商店的反抓取机制?
Google Play 商店有严格的反抓取措施,例如 CAPTCHA 和 IP 阻止。使用轮换代理、无头浏览器或像 Scrapeless 这样的专用 Google Play 抓取器可以帮助绕过这些限制。
Q2:我可以使用 Scrapy 或 Selenium 进行大规模抓取吗?
虽然 Scrapy 和 Selenium 可以抓取 Google Play 商店,但由于 IP 阻止风险高且性能慢,它们并不适合大规模抓取。像 Scrapeless 这样的基于云的 Google Play 商店抓取器提供了更好的效率。
Q3:抓取 Google Play 商店的最佳工具是什么?
最佳选择取决于您的需求。如果您想要一个可扩展且轻松的解决方案,Scrapeless 是一个强大的 Google Play 抓取器,具有快速可靠的数据提取功能。
结论
在本文中,我们探讨了几种抓取 Google Play 商店的方法,每种方法都有其自身的优缺点。使用 Requests + BS4 对于简单的小规模抓取是一个不错的选择,但在处理动态内容时它有局限性。Scrapeless 为大规模的企业级数据收集提供了最佳性能。它消除了维护复杂抓取器的需求,比传统方法更快,并提供经济高效的定价模式。
对于希望节省时间和开发成本同时获取高质量数据的企业来说,Scrapeless 是最佳解决方案。我们鼓励您免费试用 Scrapeless 并体验其 API 如何简化您的 Google Play 商店抓取过程。点击此处开始您的免费试用!
更多资源
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


