
如何用Python爬取Google新闻
Advanced Data Extraction Specialist
什么是Google新闻?
Google新闻是Google推出的一项新闻聚合服务。它收集、整理和展示来自全球主要新闻网站的最新新闻报道。用户可以按关键词、主题、地区、发布来源等进行筛选,Google新闻算法会根据用户的兴趣和浏览习惯推荐个性化的新闻内容。
Google新闻数据主要来自权威新闻机构、博客、政府公告等,因此它是获取全球实时信息的重要来源。
你可以从Google新闻中获取哪些数据?
-
新闻标题 (title) – 文章的核心内容
-
新闻链接 (link) – 文章的原始来源URL
-
发布日期 (date) – 文章发布时间(几分钟前、几小时前或具体时间)
-
新闻摘要 (snippet) – 文章内容的简短预览
-
新闻来源 (source) – 文章发布的媒体机构,例如CNN、BBC、NYTimes
-
新闻类别 (category) – 文章所属的类别,例如科技、体育、财经、健康等
-
图片链接 (thumbnail) – 文章 accompanying 图片的链接
-
相关新闻 (related news) – 类似或相关报道的链接
-
视频内容 (video) – 包含的视频新闻
....
为什么抓取Google新闻数据?
抓取Google新闻数据有很多实际应用场景。以下是其中一些最常见的用途:
- 市场分析和商业情报
- 金融和投资分析
- SEO和内容营销
- 机器学习和AI研究
- 媒体和新闻聚合应用
如何使用Python抓取Google新闻数据
步骤1:构建Google新闻数据抓取环境
首先,我们需要构建一个数据抓取环境并准备以下工具:
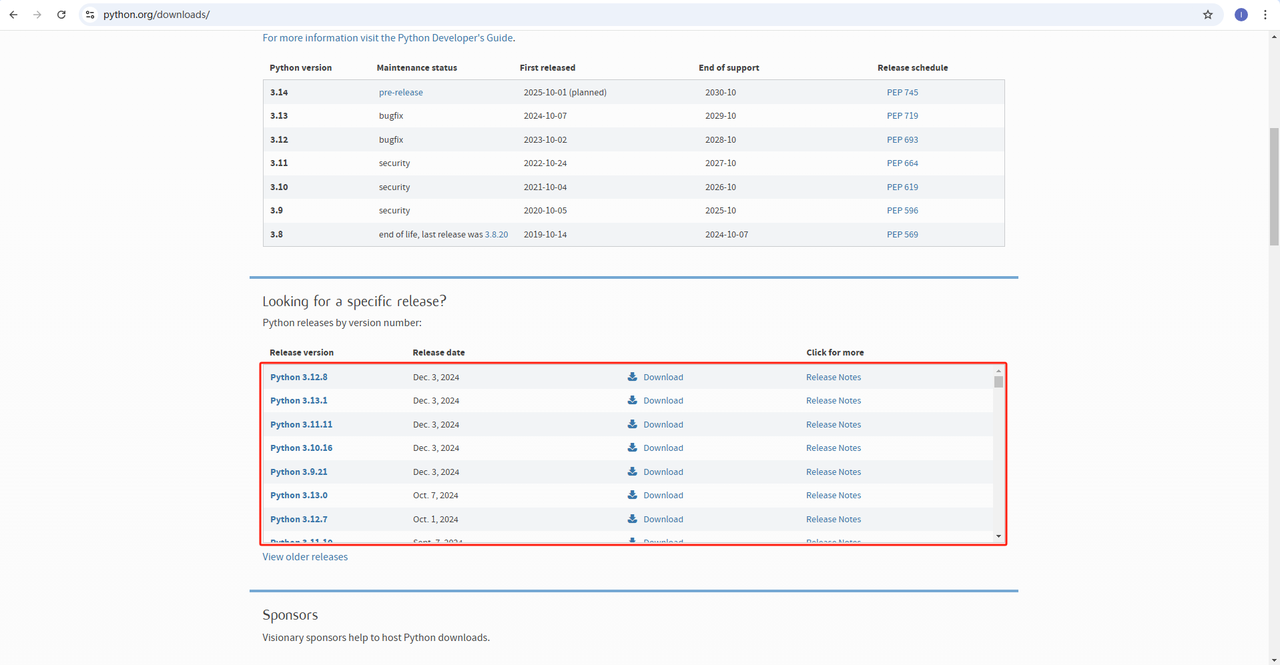
- Python: https://www.python.org/downloads/ 这是运行Python的核心软件。您可以从官方网站链接下载我们需要的版本,如下图所示,但建议不要下载最新版本。您可以下载最新版本之前的1-2个版本。
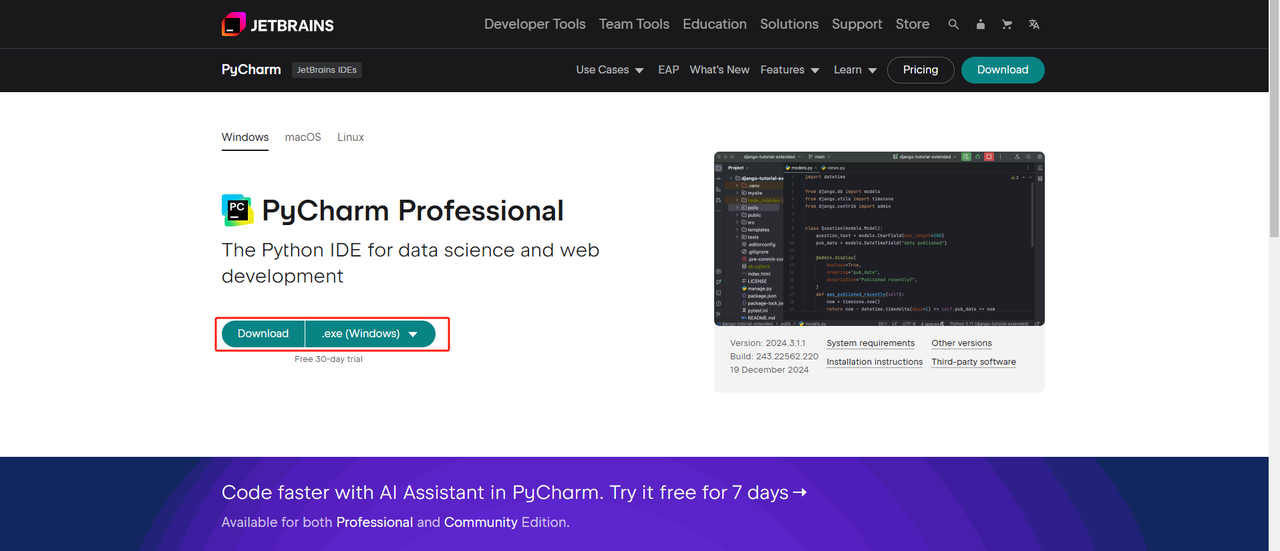
- Python IDE:任何支持Python的IDE都可以,但我们推荐PyCharm,它是一款专门为Python设计的IDE开发工具软件。关于PyCharm版本,我们推荐免费的PyCharm社区版。
- Pip:您可以使用Python包索引,通过单个命令安装运行程序所需的库。
注意:如果您是Windows用户,请不要忘记在安装向导中选中“将python.exe添加到PATH”选项。这将允许Windows在终端中使用Python和命令。由于Python 3.4或更高版本默认包含它,因此您无需手动安装它。
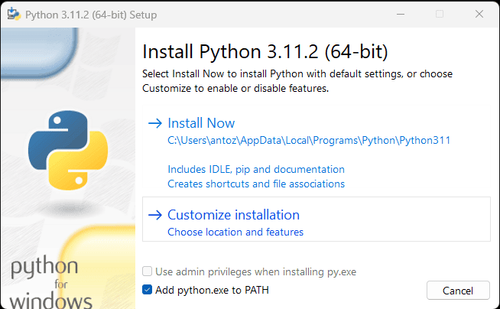
通过以上步骤,就设置好了抓取Google新闻数据的环境。接下来,您可以使用下载的PyCharm结合Scrapeless来抓取Google新闻数据。
步骤2:使用PyCharm和Scrapeless抓取Google新闻数据
- 启动PyCharm并从菜单栏中选择文件>新建项目…
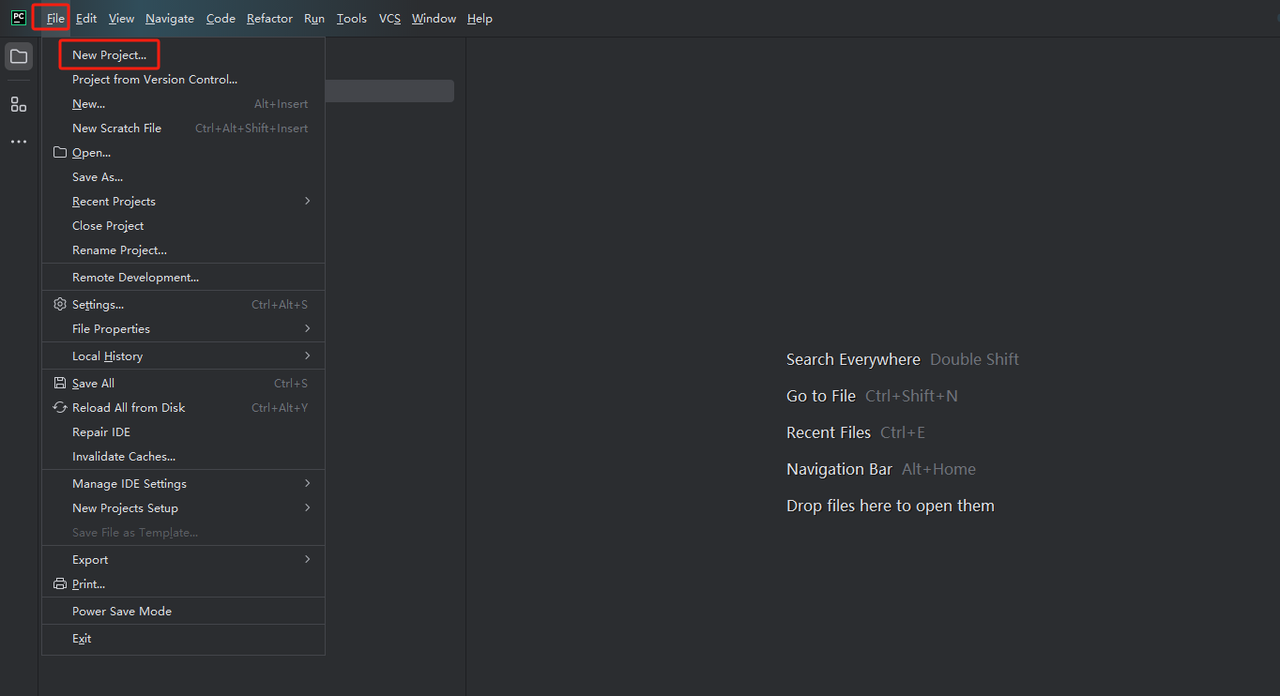
- 然后,在弹出的窗口中,从左侧菜单中选择纯Python,并按如下方式设置您的项目:
注意:在下面的红色方框中,选择在环境配置第一步下载的Python安装路径
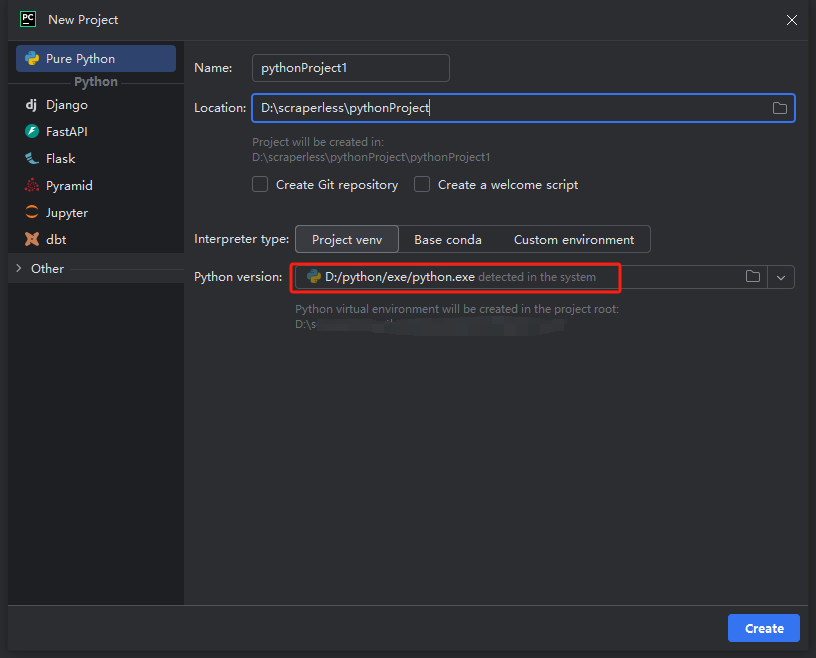
- 您可以创建一个名为python-scraper的项目,选中“在文件夹中创建main.py欢迎脚本选项”,然后单击“创建”按钮。PyCharm设置项目一段时间后,您应该看到以下内容:
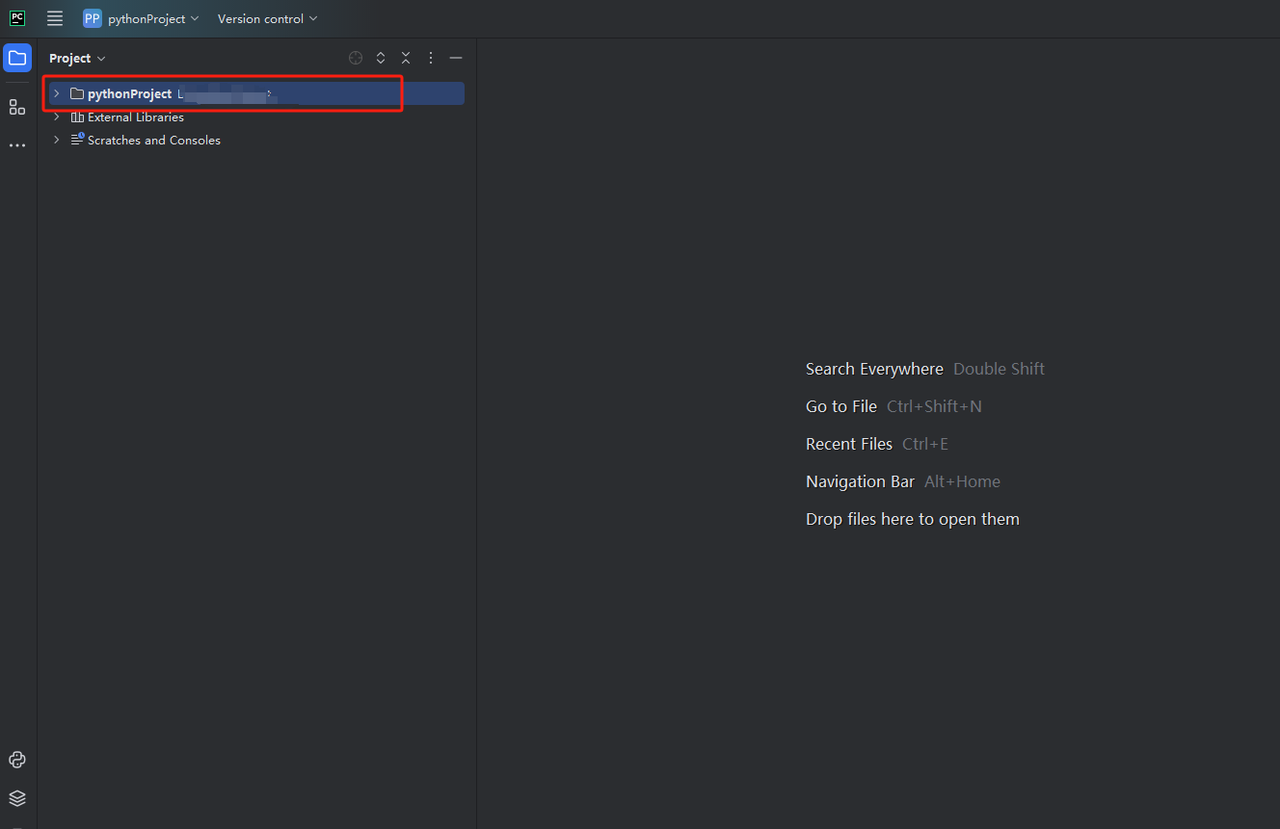
- 然后,右键单击以创建一个新的Python文件。
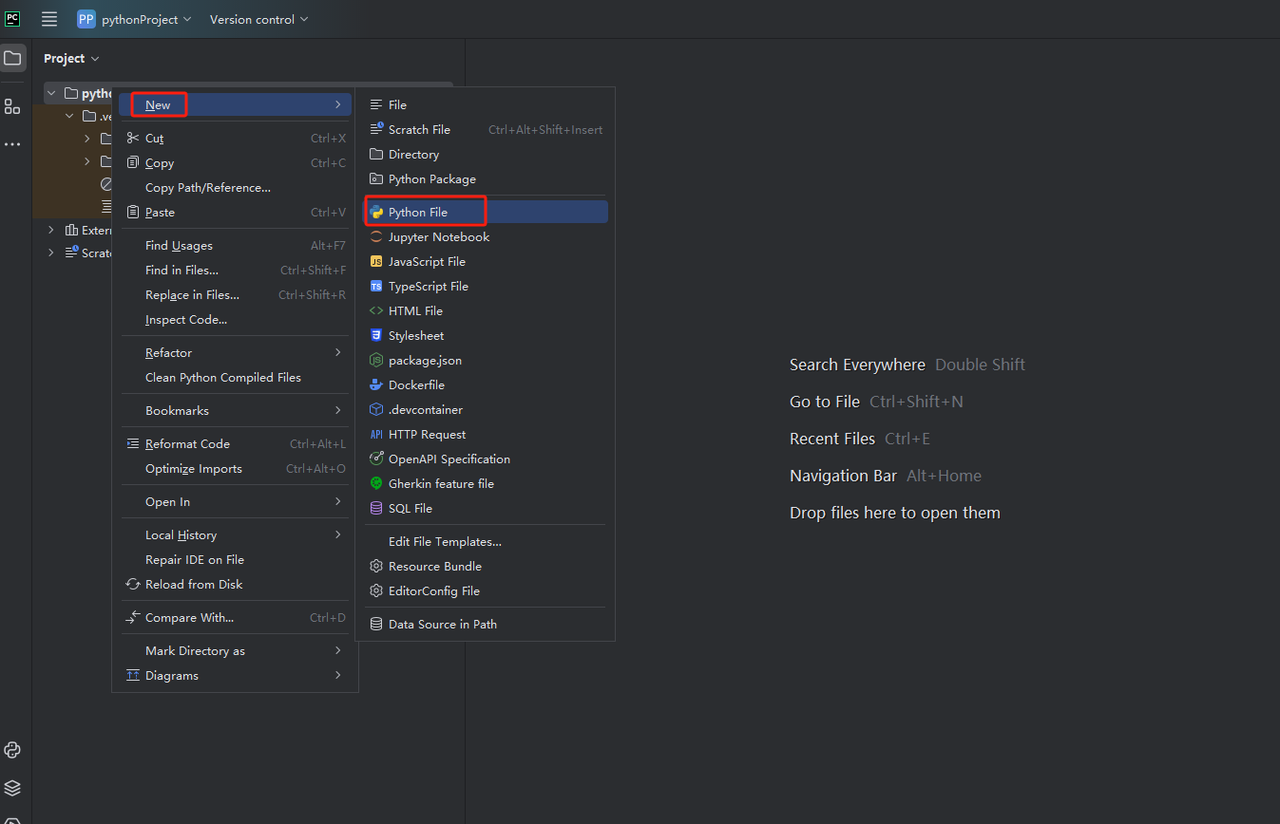
- 要验证一切是否正常工作,请打开屏幕底部的“终端”选项卡并键入:python main.py。启动此命令后,您应该会得到:Hi, PyCharm。
步骤3:获取Scrapeless API密钥
现在您可以直接将Scrapeless代码复制到PyCharm中并运行它,这样您就可以获取Google新闻的JSON格式数据。但是,您需要先获取Scrapeless API密钥。步骤如下:
如果您还没有帐户,请注册Scrapeless。注册后,登录您的控制面板。
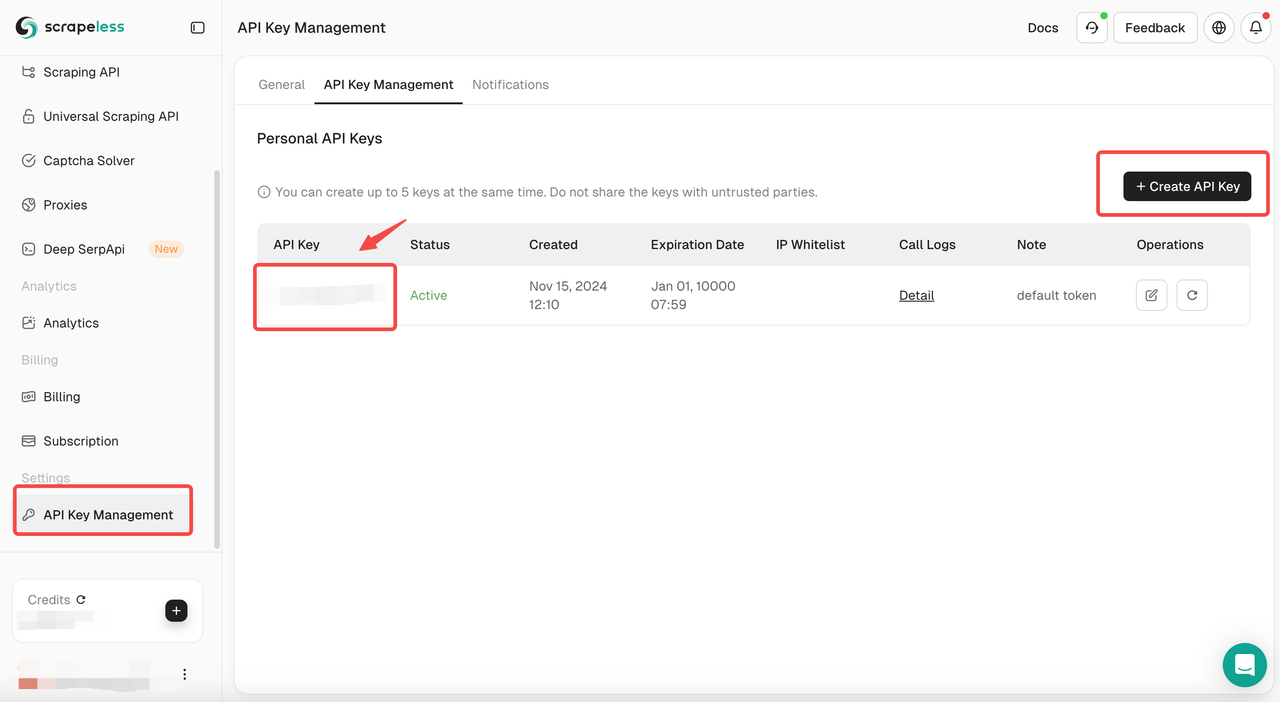
在您的Scrapeless控制面板中,导航到API密钥管理,然后单击创建API密钥。您将获得您的API密钥。只需将鼠标放在上面并单击即可复制它。在调用Scrapeless API时,此密钥将用于验证您的请求。
步骤4:如何将Scrapeless API集成到您的抓取工具中
获得API密钥后,您可以开始将Scrapeless API集成到您自己的抓取工具中。以下是如何使用Python和requests调用Scrapeless API并检索数据的示例。
使用Scrapeless API抓取Google新闻信息的示例代码:
python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_news",
"q": "pizza",
"gl": "us",
"hl": "en",
}
payload = Payload("scraper.google.news", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()受够了处理IP封锁、CAPTCHA和不断变化的HTML结构?
使用Scrapeless Google新闻API,您可以绕过限制,提取实时新闻数据,并节省数小时的开发时间——所有这些只需一个简单的API调用!
为什么选择Scrapeless而不是自己抓取?
✅ 超低价格,每1000次查询仅需$0.1
与构建您自己的爬虫、维护代理IP和绕过反爬虫机制相比,SerpApi的价格非常具有竞争力,每1000次查询仅需$0.1,大大降低了数据获取成本。
✅ 超快速响应,3秒内返回数据
Scrapeless具有超快的爬取数据能力,可以在请求后3秒内返回结构化的JSON数据,这比传统爬虫的处理速度快得多。
✅ 免维护,无需担心IP封锁和反爬虫机制
Google会检测异常流量并封锁IP,甚至需要验证码验证。Scrapeless处理所有反爬虫问题,以确保API请求始终可用,并且不会触发CAPTCHA或IP封禁。
✅ 精确搜索,按需筛选新闻数据
您可以按关键词、发布时间、新闻来源等条件筛选新闻,获取最相关的资料,避免无用信息的干扰。
Scrapeless Google新闻API
🔹 超低价格 – 每1000次查询仅需$0.1
🔹 超快速度 – 3秒内返回数据
🔹 稳定高效 – 无IP封锁,无需维护
👉 立即试用Scrapeless轻松抓取Google新闻数据!
Scrapeless Deep SerpAPI:更快更广泛的数据抓取方案

如果您需要更全面、更高效的数据采集方案,Scrapeless Deep SerpAPI绝对值得一试!
✅ 更广泛的数据覆盖 – 20多个Google搜索API场景接口
✅ 实时数据更新 – 随时获取过去24小时的数据
✅ 超低成本 – 每1000次查询仅需$0.10
✅ 超快速响应 – 数据在1-2秒内返回,远超传统API
👉 立即试用Scrapeless Deep SerpAPI轻松抓取Google搜索数据!
免费开发者支持:
将Scrapeless Deep SerpApi集成到您的AI工具、应用程序或项目中(我们已经支持Dify,并将支持Langchain、Langflow、FlowiseAI和其他框架)。
在社交媒体上分享您的集成结果,您将获得1到12个月的免费开发者支持,每月最多可使用500K次。
抓住这次机会,改进您的项目并享受更多开发支持!
结论
在本文中,我们探讨了如何使用Python抓取Google新闻。需要注意的是,在抓取内容时,必须遵守Google的使用策略和限制,以确保合法合规。
相关资源
如何从Kayak抓取航班数据
如何将Selenium与PowerShell一起使用
使用Scrapeless抓取Google职位以轻松创建职位列表
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


