
如何使用Scrapeless抓取Google Lens结果
Advanced Data Extraction Specialist
什么是 Google Lens?
Google Lens 是一款基于人工智能和图像识别技术的应用程序,它可以通过摄像头或图片识别物体、文本、地标和其他内容,并提供相关信息。
从 Google Lens 抓取数据合法吗?
从 Google Lens 抓取数据本身并不违法,但需要遵守各种法律和道德准则。用户必须了解 Google 的服务条款、数据隐私法和知识产权,以确保其活动符合规定。通过遵循最佳实践并随时了解法律动态,可以最大限度地降低与网络抓取相关的法律问题的风险。
抓取 Google Lens 的挑战
- 高级反机器人技术:Google 会监控网络流量模式。来自爬虫的大量重复请求会被迅速检测到,导致 IP 被封禁,从而停止抓取过程。
推荐阅读:反机器人技术:它是什么以及如何避免它 - JavaScript 渲染内容:Google Lens 的许多数据是由 JavaScript 动态生成的,传统的爬虫无法访问这些数据,需要使用 Puppeteer 或 Selenium 等无头浏览器,但这会增加复杂性和资源消耗。
- CAPTCHA 保护:Google 使用 CAPTCHA 来验证人类用户。爬虫可能会遇到难以通过编程方式解决的 CAPTCHA 挑战。
- 网站频繁更新:Google 定期更改 Google Lens 的结构和布局。抓取代码很快就会过时,用于数据提取的 XPath 或 CSS 选择器可能会停止工作。需要持续监控和更新。
使用 Python 抓取 Google Lens 的分步指南
第 1 步:配置环境
- Python:软件是运行 Python 的核心。您可以从下面的官方网站下载所需版本。但是,不建议下载最新版本。您可以下载最新版本之前的 1.2 个版本。
- Python IDE:任何支持 Python 的 IDE 都可以使用,但我们推荐 PyCharm。它是一个专门为 Python 设计的开发工具。对于 PyCharm 版本,我们推荐免费的 PyCharm 社区版
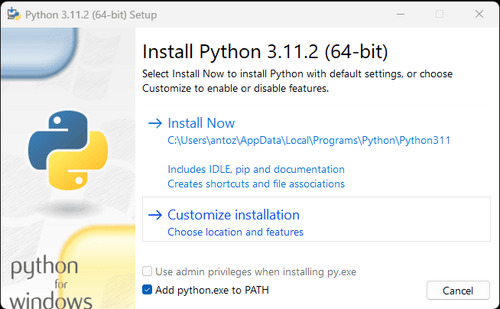
**注意:**如果您是 Windows 用户,请不要忘记在安装向导期间选中“将 python.exe 添加到 PATH”选项。这将允许 Windows 在终端中使用 Python 和命令。由于 Python 3.4 或更高版本默认包含它,因此您无需手动安装它。
现在,您可以通过打开终端或命令提示符并输入以下命令来检查是否已安装 Python:
python --version第 2 步:安装依赖项
建议创建一个虚拟环境来管理项目依赖项并避免与其他 Python 项目冲突。在终端中导航到项目目录,并执行以下命令以创建名为 google_lens 的虚拟环境:
python -m venv google_lens根据您的系统激活虚拟环境:
Windows:
google_lens_env\Scripts\activateMacOS/Linux:
source google_lens_env/bin/activate激活虚拟环境后,安装 Web 抓取所需的 Python 库。Python 中用于发送请求的库是 requests,用于抓取数据的主要库是 BeautifulSoup4。使用以下命令安装它们:
pip install requests
pip install beautifulsoup4
pip install playwright第 3 步:抓取数据
在浏览器中打开 Google Lens(https://www.google.com/?olud)并搜索“https://i.imgur.com/HBrB8p0.png”。以下是搜索结果:
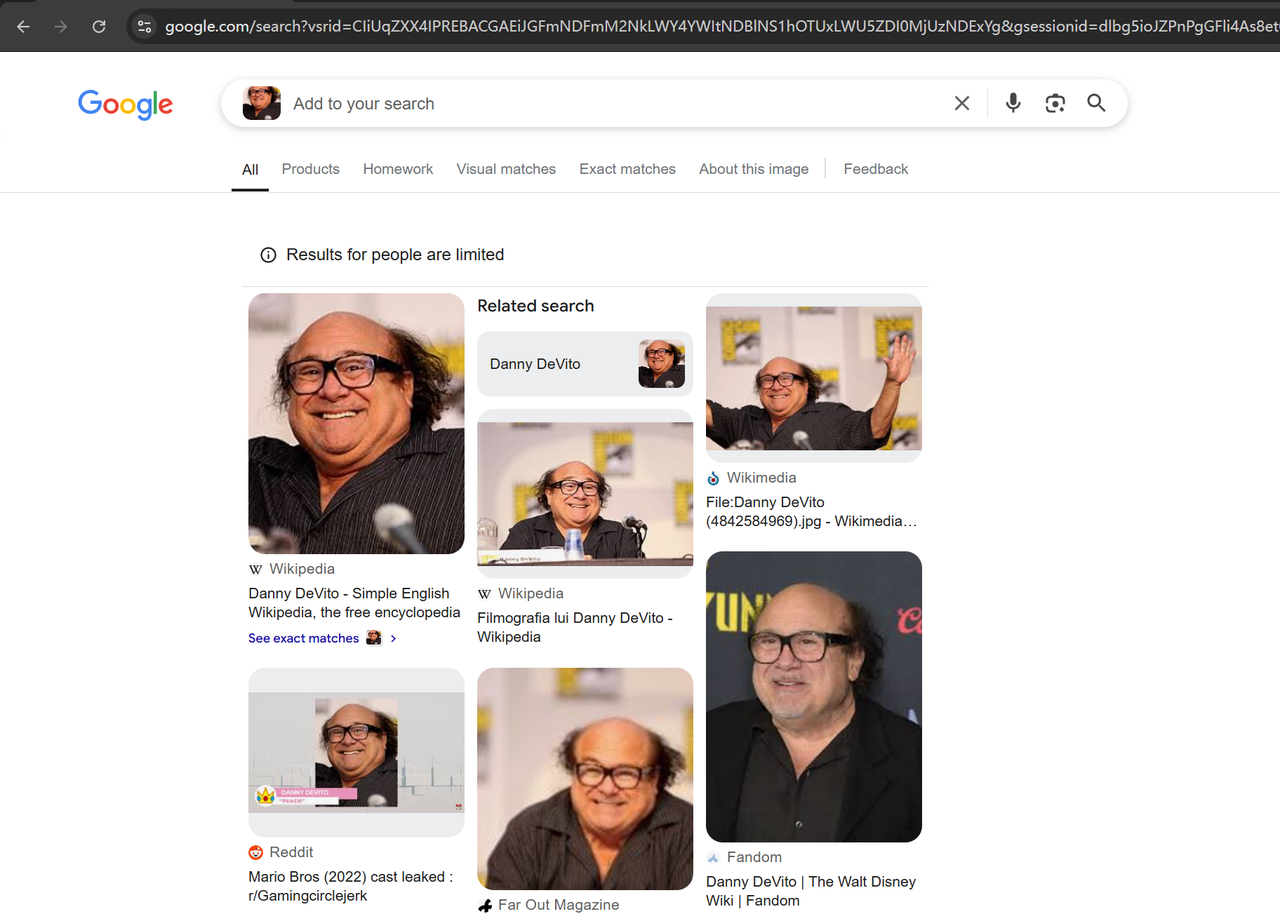
抓取标题和图像信息
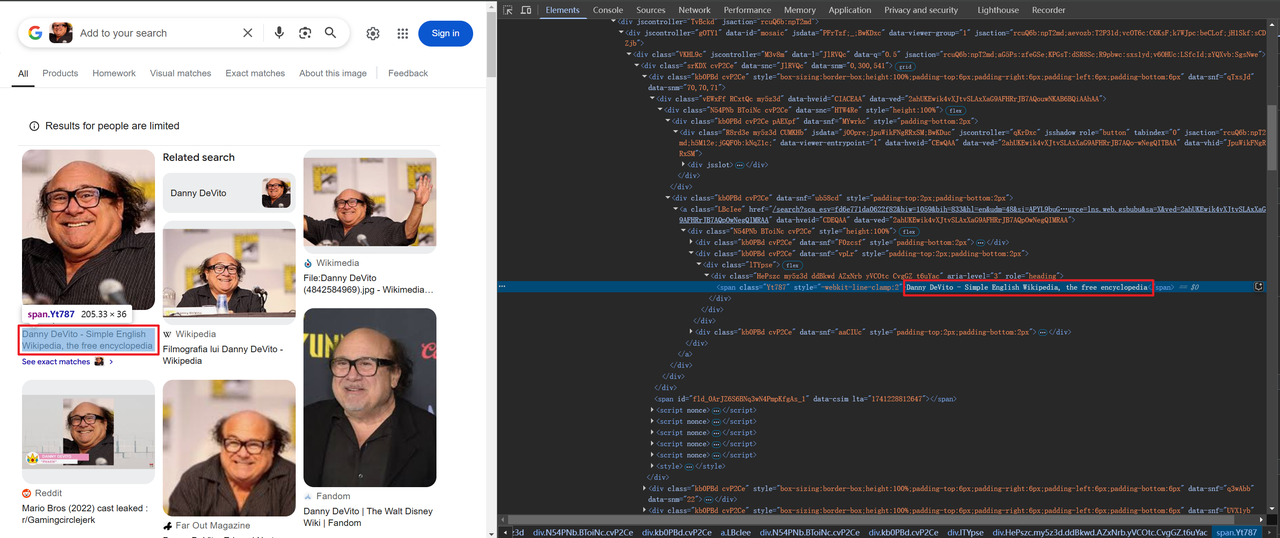
有些图像以 base64 编码,而另一些则通过 HTTP 链接,例如:
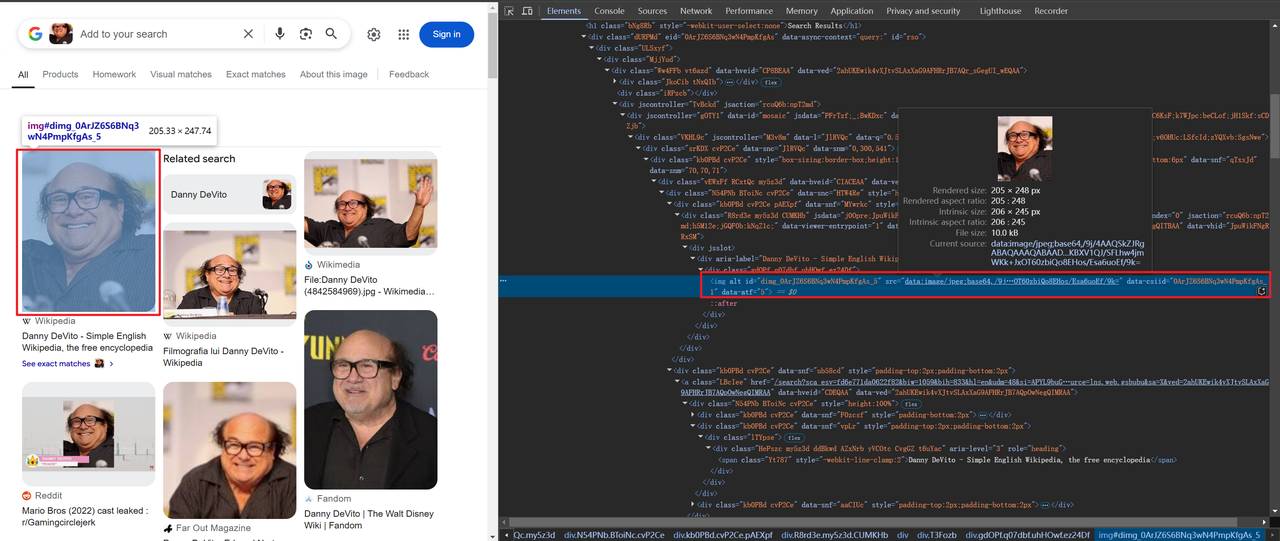
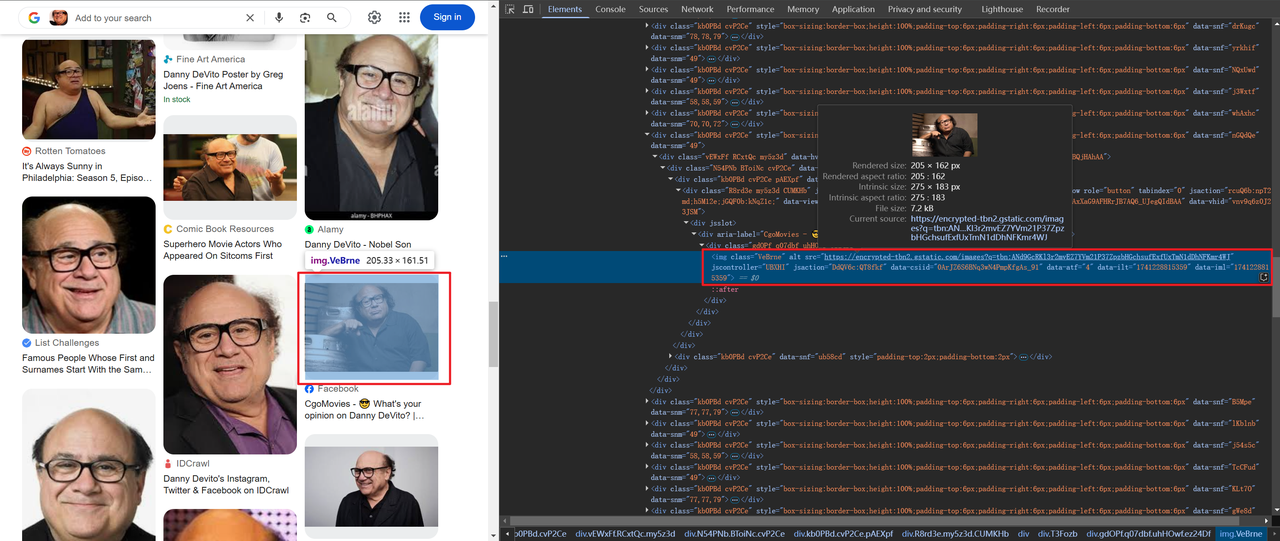
获取标题和图像信息的代码如下:
# 将 lens 信息存储在字典中
img_info = {
'title': item.find("span").text,
'thumbnail': item.find("img").attrs['src'],
}由于我们需要抓取页面上的所有数据,而不仅仅是一个,因此我们需要循环遍历并抓取上述数据。完整的代码如下:
import json
from bs4 import BeautifulSoup
from playwright.sync_api import sync_playwright
def scrape(url: str) -> str:
with sync_playwright() as p:
# 启动浏览器并禁用一些可能导致检测的功能
browser = p.chromium.launch(
headless=True,
args=[
"--disable-blink-features=AutomationControlled",
"--disable-dev-shm-usage",
"--disable-gpu",
"--disable-extensions",
],
)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
bypass_csp=True,
)
page = context.new_page()
page.goto(url)
page.wait_for_selector("body", state="attached")
# 等待 2 秒以确保页面完全加载或渲染
page.wait_for_timeout(2000)
html_content = page.content()
browser.close()
return html_content
def main():
url = "https://lens.google.com/uploadbyurl?url=https%3A%2F%2Fi.imgur.com%2FHBrB8p0.png"
html_content = scrape(url)
soup = BeautifulSoup(html_content, 'html.parser')
# 获取页面的主要数据
items = soup.find('div', {'jscontroller': 'M3v8m'}).find("div")
# 循环组装
assembly = lens_info(items)
# 将结果保存到 JSON 文件
with open('google_lens_data.json', 'w') as json_file:
json.dump(assembly, json_file, indent=4)
def lens_info(items):
lens_data = []
for item in items:
# 将 lens 信息存储在字典中
img_info = {
'title': item.find("span").text,
'thumbnail': item.find("img").attrs['src'],
}
lens_data.append(img_info)
return lens_data
if __name__ == "__main__":
main()第 4 步:输出结果
在您的 PyCharm 目录中将生成一个名为 google_lens_data.json 的文件。输出如下(部分示例):
[
{
"title": "Danny DeVito - Wikipedia",
"thumbnail": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBxAQEhAQEBAQEB
},
{
"title": "Devito Danny Royalty-Free Images, Stock Photos & Pictures | Shutterstock",
"thumbnail": "https://encrypted-tbn1.gstatic.com/images?q=tbn:ANd9GcSO6Pkv_UmXiianiCh52nD5s89d7KrlgQQox-f-K9FtXVILvHh_"
},
{
"title": "DATA | Celebrity Stats | Page 62",
"thumbnail": "https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcQ9juRVpW6sjE3OANTKIJzGEkiwUpjCI20Z1ydvJBCEDf3-NcQE"
},
{
"title": "Danny DeVito, Grand opening of Buca di Beppo italian restaurant on Universal City Walk Universal City, California - 28.01.09 Stock Photo - Alamy",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQq_07f-Unr7Y5BXjSJ224RlAidV9pzccqjucD4VF7VkJEJJqBk"
}
]更高效的工具:如何使用 Scrapeless 抓取 Google Lens 结果
Scrapeless 提供了一个强大的工具,可以帮助开发人员轻松抓取 Google Lens 搜索结果,无需编写复杂的代码。以下是将 Scrapeless API 集成到您的 Python 爬虫工具中的详细步骤:
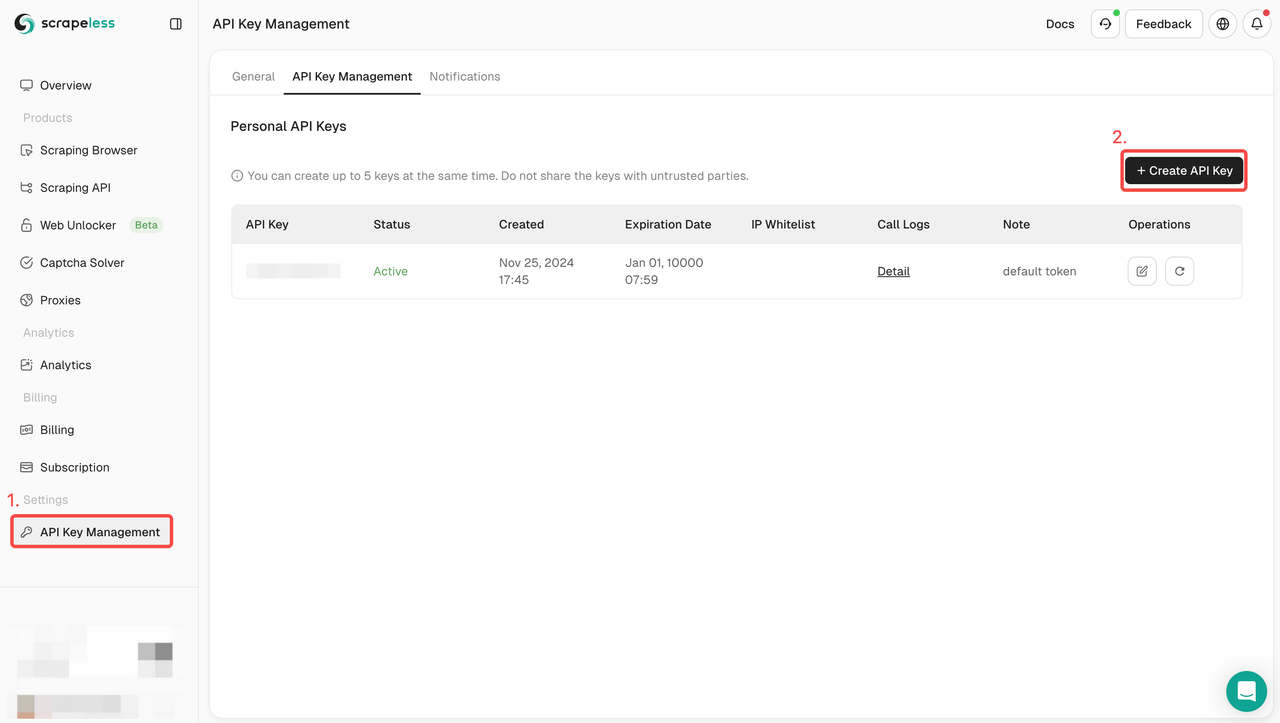
第 1 步:注册 Scrapeless 并获取 API 密钥
- 如果你还没有 Scrapeless 帐户,请访问 Scrapeless 网站并注册。
- 注册后,登录您的 仪表板。
- 在仪表板中,导航到 API 密钥管理 并点击 创建 API 密钥。复制生成的 API 密钥,这将是您调用 Scrapeless API 时的身份验证凭据。
第 2 步:编写 Python 脚本来集成 Scrapeless API
以下是使用 Scrapeless API 抓取 Google Lens 结果的示例代码:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
engine: "google_lens",
hl: "en",
country: "jp",
url: "https://s3.zoommer.ge/zoommer-images/thumbs/0170510_apple-macbook-pro-13-inch-2022-mneh3lla-m2-chip-8gb256gb-ssd-space-grey-apple-m25nm-apple-8-core-gpu_550.jpeg",
}
payload = Payload("scraper.google.lens", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()注意
API 密钥安全性:请确保不要在公共代码存储库中公开您的 API 密钥。
查询优化:根据您的需求调整查询参数以获得更精确的结果。有关 API 参数的更多信息,您可以查看 Scrapeless 的 官方 API 文档
为什么选择 Scrapeless 抓取 Google Lens
Scrapeless 是一款 强大的 AI 驱动的网络抓取工具,旨在实现高效且稳定的网络抓取。
1. 实时数据和高质量结果
Scrapeless 提供实时 Google Lens 搜索结果,可以在 1-2 秒内返回 Google Lens 搜索结果。确保用户获取的数据始终是最新的。
2. 价格实惠
Scrapeless 的价格非常有竞争力,价格低至每 1,000 次查询仅需 0.1 美元。
3. 强大的功能支持
Scrapeless 支持多种搜索类型,包括 20 多种 Google 搜索结果场景。它可以以 JSON 格式返回结构化数据,方便用户快速解析和使用。
Scrapeless Deep SerpAPI:强大的实时搜索数据解决方案
Scrapeless Deep SerpApi 是一个为 AI 应用程序和检索增强生成 (RAG) 模型设计的实时搜索数据平台。它提供实时、准确和结构化的 Google 搜索结果数据,支持 20 多种 Google SERP 类型,包括 Google 搜索、Google 趋势、Google 购物、Google 航班、Google 酒店、Google 地图等。

核心功能
- 实时数据更新:基于过去 24 小时内的数据更新,确保信息的及时性和准确性。
- 多语言和地理位置支持:支持多语言和地理位置,可以根据用户的地理位置、设备类型和语言定制搜索结果。
- 快速响应:平均响应时间仅为 1-2 秒,适合高频次和大规模数据检索。
- 无缝集成:兼容 Python、Node.js、Golang 等主流编程语言,易于集成到现有项目中。
- 成本效益高:价格低至每 1,000 次查询 0.1 美元,是市场上最具成本效益的 SERP 解决方案。
特别优惠
- 免费试用:提供免费试用,用户可以体验所有功能。
- 开发者支持计划:前 100 位用户可以获得价值 50 美元(500,000 次查询)的免费 API 调用配额,适合测试和扩展项目。
如果您有任何疑问或定制要求,可以通过点击 Discord 链接 联系 Liam。
结论
在本文中,我们详细介绍了如何使用 Scrapeless 抓取 Google Lens 搜索结果。借助 Scrapeless 提供的强大 API,开发人员和研究人员可以轻松获取实时、高质量的视觉数据,无需编写复杂的代码或担心反爬虫机制。Scrapeless 的效率和灵活性使其成为处理 Google Lens 数据的理想工具。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。



{kind=link}