
使用Scrapeless轻松抓取Google职位信息创建职位列表
Advanced Data Extraction Specialist
快速找到合适的职位数据可能是一项挑战,但有了合适的工具,它就变得轻而易举。从 Google 职位抓取职位列表可以帮助企业、招聘网站和开发者收集准确、最新的职位信息。通过自动化流程,您可以轻松编译全面的职位列表,按位置或职位类型进行筛选,并将这些数据集成到您的平台中。在本文中,我们将向您展示如何高效地抓取 Google 职位并创建既相关又准确的职位列表。
什么是 Google 职位?
Google 职位是由 Google 提供的专业职位搜索引擎,它汇总来自各种来源的职位列表,包括招聘网站、公司网站和招聘机构。Google 职位于 2017 年推出,旨在通过为用户提供一个一站式平台来发现不同行业和地区的职位机会,从而简化求职流程。
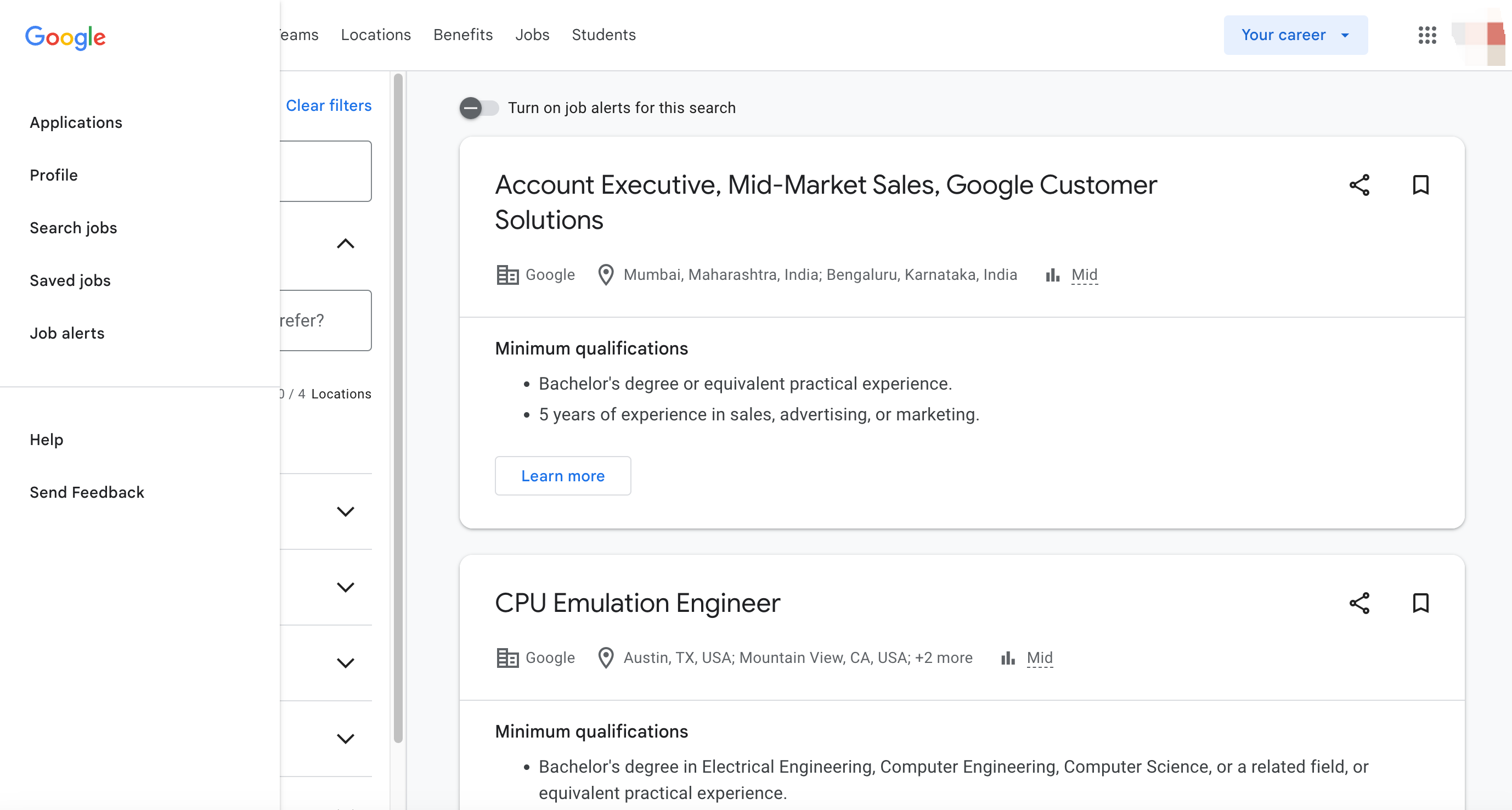
为什么抓取 Google 职位?
抓取 Google 职位为企业、求职者和招聘网站提供了诸多优势。以下是一些您应该考虑抓取 Google 职位数据的主要原因:
1. 全面的职位列表
Google 职位汇总来自多个值得信赖来源的职位列表,使其成为职位数据的一站式商店。
2. 可自定义的搜索
您可以根据特定条件(例如位置、职位名称和薪资范围)筛选职位结果,从而为您的受众提供量身定制的结果。
3. 节省时间的自动化
通过自动化 Google 职位的抓取,您可以确保您的网站或应用程序始终拥有最新的职位列表,无需手动更新。
4. 竞争优势
如果您运营招聘网站或招聘网站,访问 Google 职位数据可以提供竞争优势,因为它可以提供吸引求职者的全面的职位列表。
使用 Python 抓取 Google 职位以轻松创建职位列表
寻找合适的职位可能是一项艰巨的任务,但使用 Scrapeless,您可以快速有效地从 Google 职位收集职位发布信息,并将其集成到您自己的工具中。在本文中,我们将引导您逐步了解如何使用 Scrapeless API 抓取职位数据并创建您自己的职位列表。
Scrapeless 是一款功能强大且易于使用的网络抓取工具,它允许您从各种来源(包括 Google 职位)收集结构化数据,而无需自行处理抓取的复杂性。

Scrapeless 的优势
-
**准确和全面的数据:**提供准确的职位信息,涵盖职位名称、公司名称、工作地点、薪资范围、职位描述等关键内容。
-
**支持多参数自定义:**允许开发者使用超过 10 个自定义参数,例如职位类型(全职、兼职等)、经验要求、行业领域等,以准确过滤目标职位数据。
-
**多区域覆盖:**可以捕获不同国家和地区的 Google 职位搜索结果,以满足全球业务扩展的需求。
-
**格式规范:**以标准化的 JSON 格式输出数据,方便开发者在不同的系统和程序中集成和处理。
-
**易于集成:**提供简单的 API 接口,方便开发者使用常见的编程语言(如 Python、Java 等)进行调用和集成。
-
**实时更新:**确保获取的职位数据是实时的,并及时反映最新的招聘信息。
立即注册 并获得 2 美元的免费积分,试用我们所有强大的功能。不要错过
步骤 1:构建 Google 职位数据爬取环境
首先,我们需要构建一个数据爬取环境并准备以下工具:
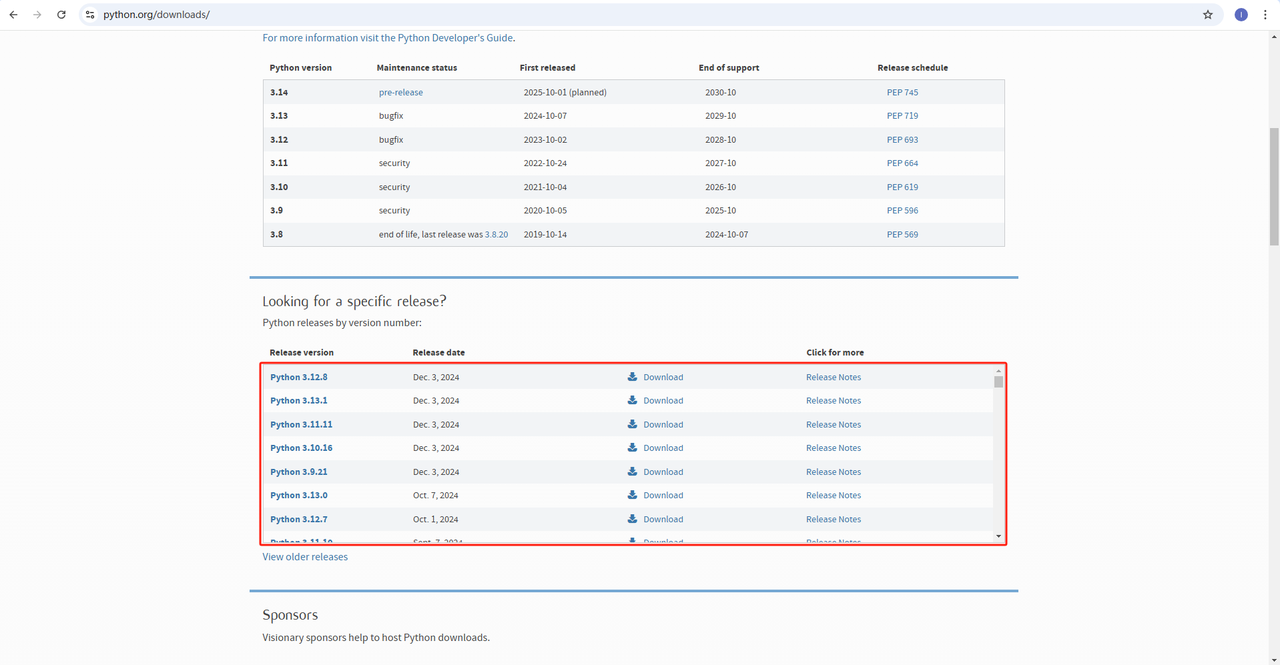
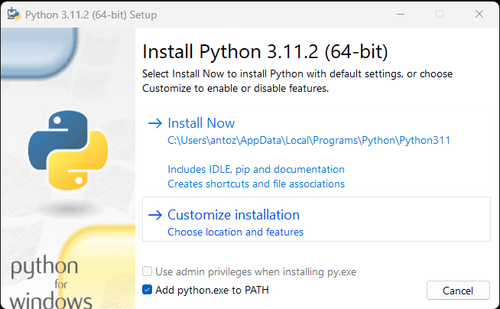
1. Python:此 是运行 Python 的核心软件。您可以从官方网站链接下载我们需要的版本,如下图所示,但建议不要下载最新版本。您可以下载最新版本之前的 1-2 个版本。
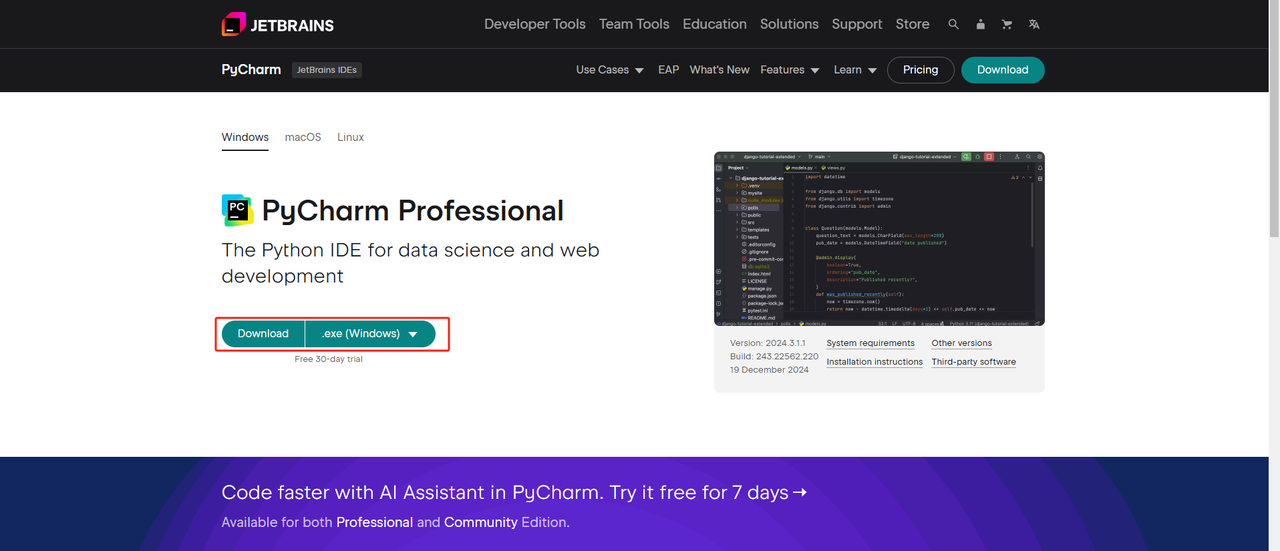
**2. Python IDE:**任何支持 Python 的 IDE 都可以,但我们推荐 PyCharm,它是一款专门为 Python 设计的 IDE 开发工具软件。关于 PyCharm 版本,我们推荐免费的 PyCharm 社区版。
**3. Pip:**您可以使用 Python 包索引通过单个命令安装运行程序所需的库。
**注意:**如果您是 Windows 用户,请不要忘记在安装向导中选中“将 python.exe 添加到 PATH”选项。这将允许 Windows 在终端中使用 Python 和命令。由于 Python 3.4 或更高版本默认包含它,因此您无需手动安装它。
通过以上步骤,Google 职位数据爬取的环境就搭建好了。接下来,您可以使用下载的 PyCharm 结合 Scraperless 来爬取 Google 职位数据。
步骤 2:使用 PyCharm 和 Scrapeless 抓取 Google 职位数据
- 启动 PyCharm 并从菜单栏中选择文件>新建项目… 。
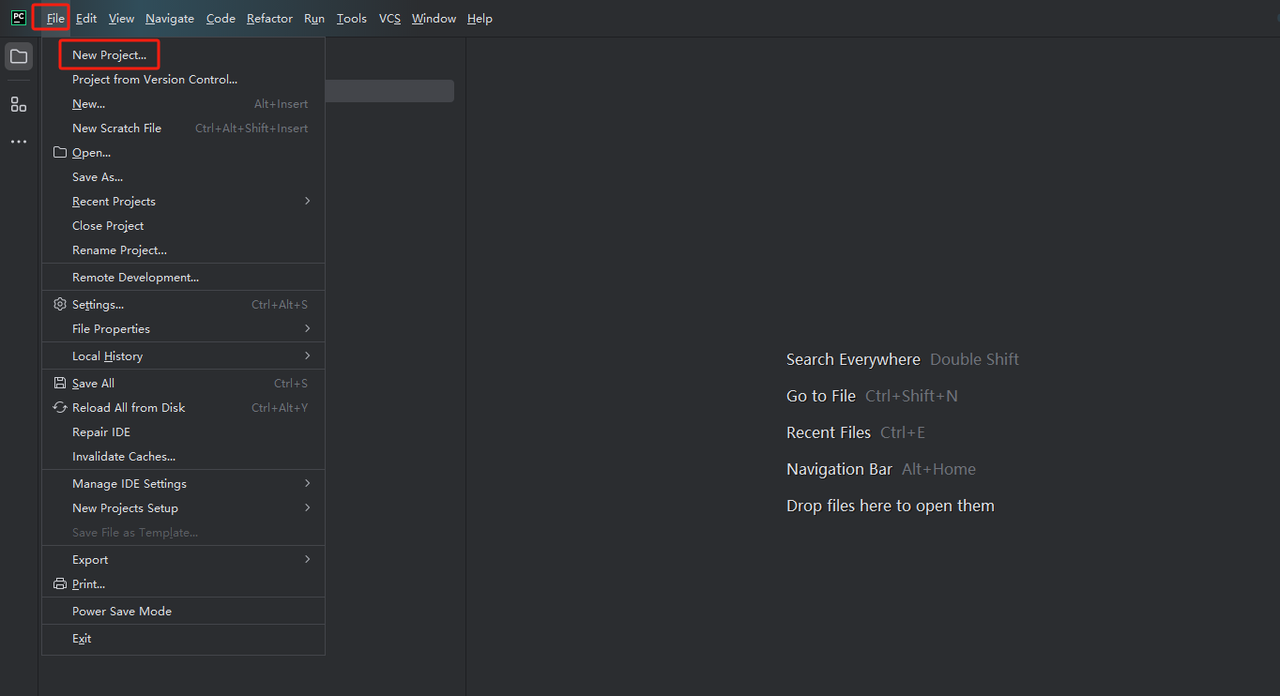
- 然后,在弹出的窗口中,从左侧菜单中选择纯 Python,并如下设置您的项目:
**注意:**在下面的红色方框中,选择在环境配置的第一步中下载的 Python 安装路径
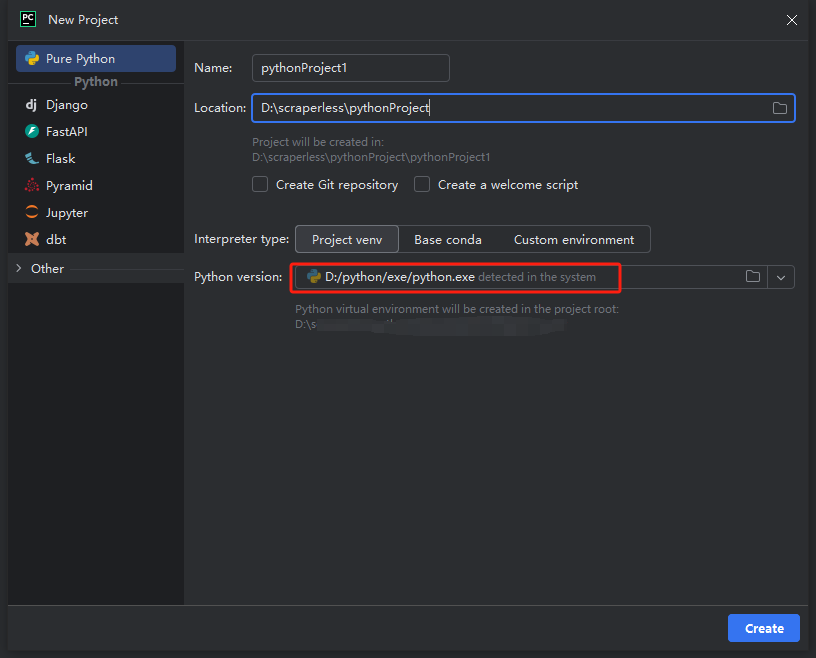
- 您可以创建一个名为 python-scraper 的项目,选中“在文件夹中创建 main.py 欢迎脚本选项”,然后单击“创建”按钮。PyCharm 设置项目一段时间后,您应该会看到以下内容:
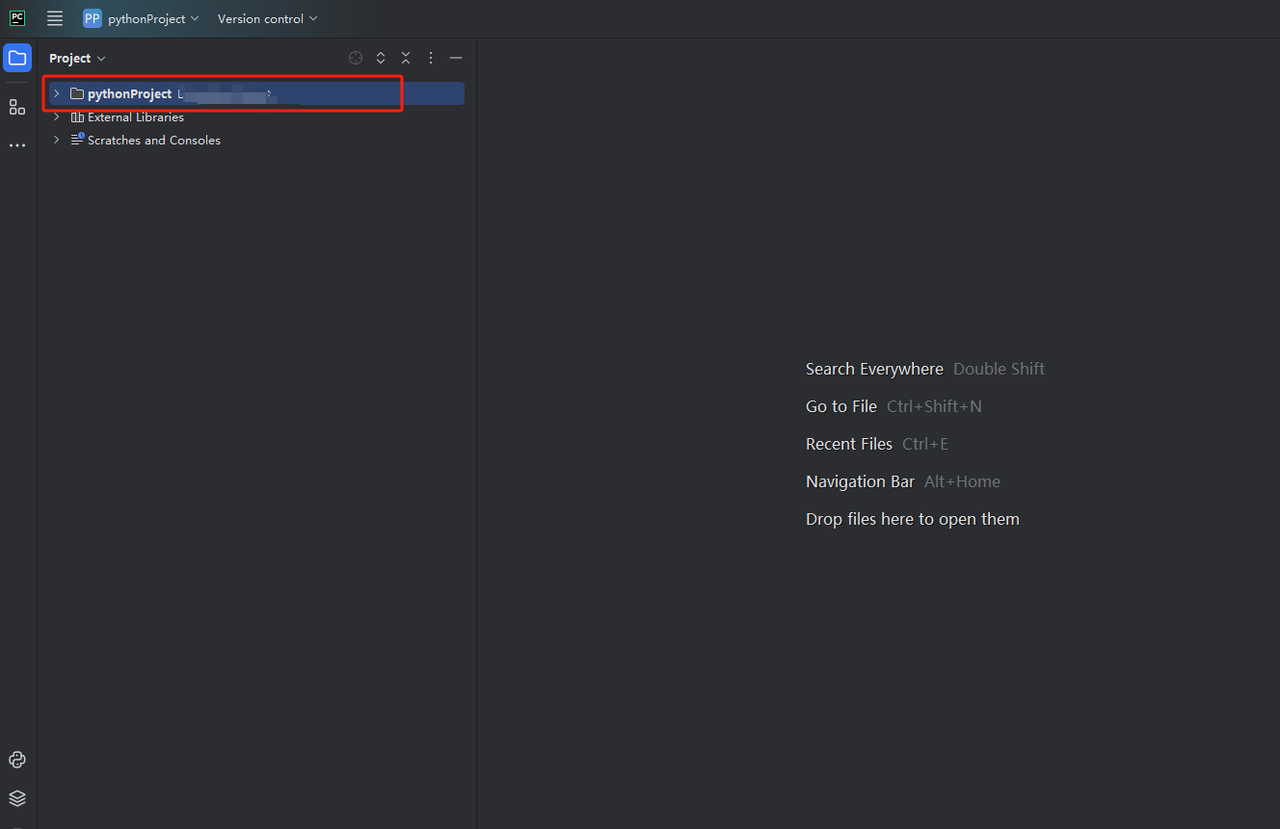
- 然后,右键单击以创建一个新的 Python 文件。
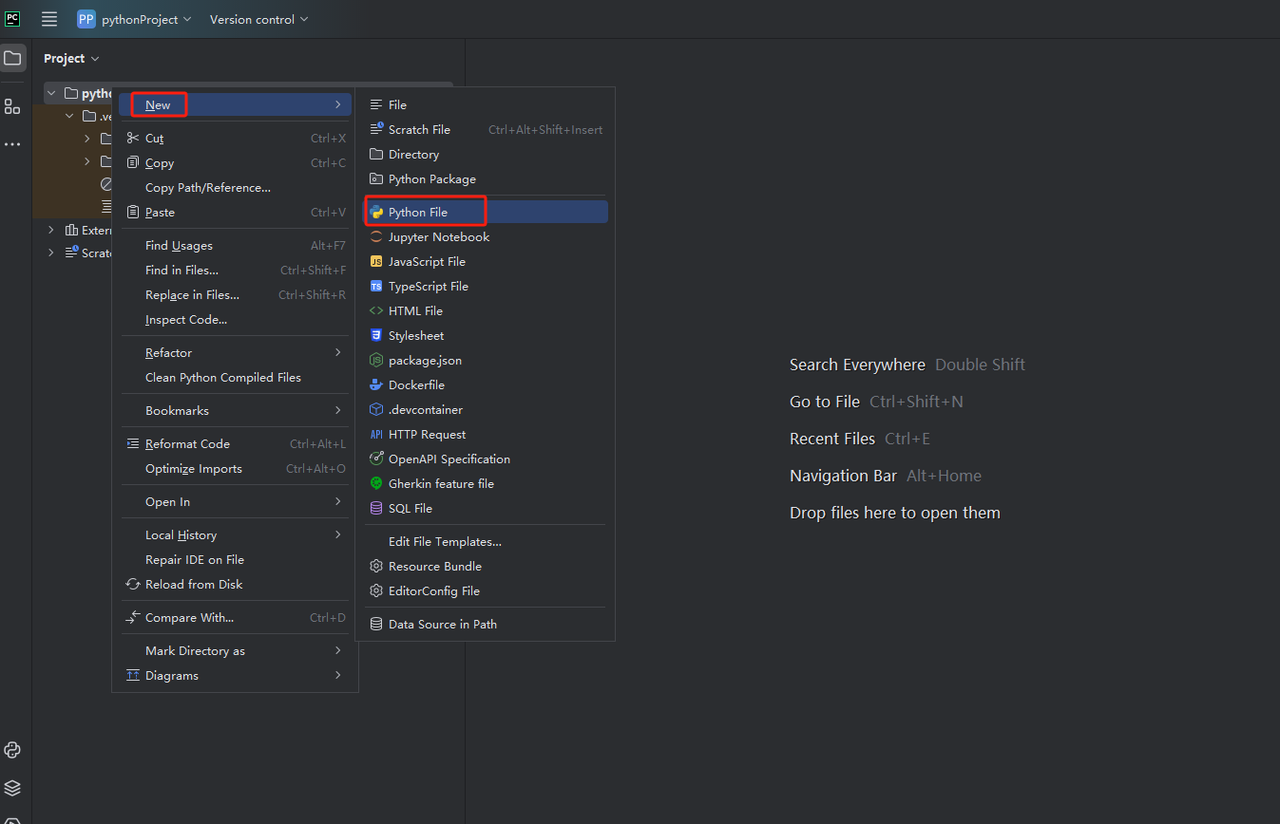
- 要验证一切是否正常运行,请打开屏幕底部的终端选项卡并键入:python main.py。启动此命令后,您应该会得到:Hi, PyCharm。
步骤 3:获取 Scrapeless API 密钥
现在您可以直接将 Scrapeless 代码复制到 PyCharm 中并运行它,这样您就可以获得 Google Job 的 JSON 格式数据。但是,您需要首先获取 Scrapeless API 密钥。步骤如下:
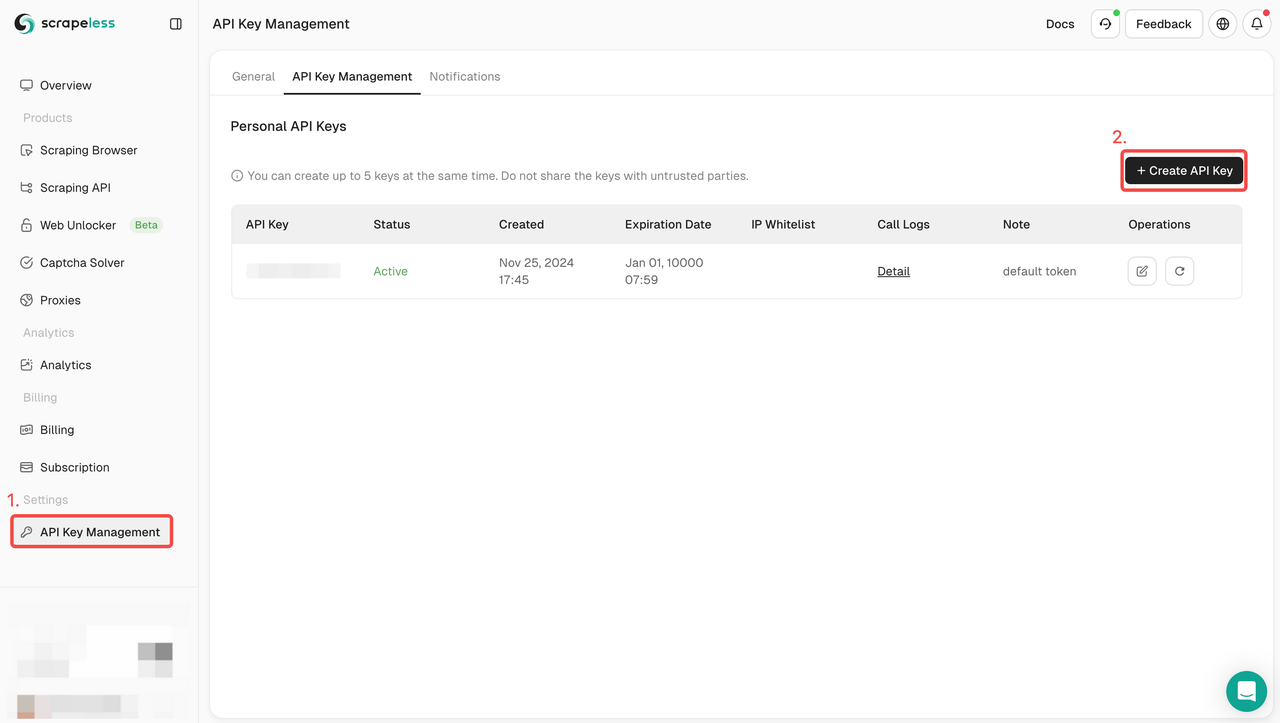
- 如果你还没有账户,请注册 Scrapeless。注册后,登录您的仪表板。
- 在您的 Scrapeless 仪表板中,导航到API 密钥管理并单击创建 API 密钥。您将获得您的 API 密钥。只需将鼠标放在上面并单击它即可复制它。调用Scrapeless API时,此密钥将用于验证您的请求。
步骤 4:了解 Scrapeless API 参数
Scrapeless API 提供各种参数,您可以使用这些参数来过滤和细化要检索的数据。以下是用于抓取 Google 职位信息的 主要 API 参数:
| 参数 | 必填 | 说明 |
|---|---|---|
| engine | TRUE | 将参数设置为 google_jobs 以使用 Google 职位 API 引擎。 |
| q | TRUE | 参数定义您要搜索的查询。 |
| uule | FALSE | 参数是您要用于搜索的 Google 编码位置。uule 和 location 参数不能同时使用。 |
| google_domain | FALSE | 参数定义要使用的 Google 域名。默认为 google.com。访问 Google 域名页面以获取完整的受支持 Google 域名列表。 |
| gl | FALSE | 参数定义要用于 Google 搜索的国家/地区。它是两位字母的国家/地区代码(例如,us 代表美国,uk 代表英国,fr 代表法国)。访问 Google 国家/地区页面以获取完整的受支持 Google 国家/地区列表。 |
| hl | FALSE | 参数定义要用于 Google 职位搜索的语言。它是两位字母的语言代码(例如,en 代表英语,es 代表西班牙语,fr 代表法语)。访问 Google 语言页面以获取完整的受支持 Google 语言列表。 |
| next_page_token | FALSE | 参数定义下一页标记。它用于检索下一页结果。每页最多返回 10 个结果。下一页标记可以在 SerpApi JSON 响应中找到:pagination -> next_page_token。 |
| lrad | TRUE | 定义搜索半径(公里)。不会严格限制半径。 |
| ltype | TRUE | 参数将按在家工作进行过滤结果。 |
| uds | TRUE | 参数可以启用过滤搜索。它是 Google 提供的作为过滤器的字符串。uds 值在以下部分提供:filters with uds,为每个过滤器提供的 q 和 link 值。 |
步骤 5:如何将 Scrapeless API 集成到您的抓取工具中
获得API 密钥后,您可以开始将Scrapeless API集成到您自己的抓取工具中。以下是关于如何使用 Python 和 requests 调用 Scrapeless API 并检索数据的示例。
使用 Scrapeless API 抓取 Google 职位信息的示例代码:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_jobs",
"q": "barista new york",
}
payload = Payload("scraper.google.jobs", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()步骤 6:分析结果数据
Scrapeless API 的结果数据将包含JSON 格式的详细信息。以下是结果数据的局部示例。可以在API 文档中查看具体信息。
{
"filters": [
{
"name": "Salary",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=Barista+new+york+salary&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQIDRAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J",
"q": "Barista new york salary"
}
},
{
"name": "Remote",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista%2Bnew%2Byork+remote&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQICxAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU",
"q": "barista+new+york remote"
}
},
{
"name": "Date posted",
"options": [
{
"name": "Yesterday",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york since yesterday&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAC",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw",
"q": "barista new york since yesterday"
}
},
{
"name": "Last 3 days",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last 3 days&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAD",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg",
"q": "barista new york in the last 3 days"
}
},
{
"name": "Last week",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last 结果中的关键字段:
- title:职位名称。
- company:提供工作的公司
- link:职位发布链接
- location:职位地点
- date_posted:发布职位的日期
您现在可以使用这些数据来构建招聘网站、发送通知或将职位数据集成到您现有的网站或应用程序中。
正在寻找轻松收集职位列表的方法?
立即开始使用 Scrapeless 的 Google 职位 API!轻松获得准确的实时职位数据,并简化您的求职流程。立即试用 并查看区别!
探索招聘和就业市场分析的其他热门数据来源
除了 Google 职位外,许多其他平台也提供有价值的招聘数据和行业趋势,这些数据适用于更广泛的招聘数据分析。例如,Crunchbase、Indeed 和 LinkedIn 都是招聘和人才市场分析的重要数据来源。
- Crunchbase 提供有关初创企业、企业融资、行业趋势等的详细信息,这对于研究公司招聘需求和市场趋势非常有帮助。
- Indeed 是全球最大的招聘平台之一,拥有丰富的职位信息、薪资数据和行业趋势,适用于职位分析、薪资预测和人才市场调研。
- LinkedIn 提供全球专业社交网络和招聘数据,可以帮助分析人才流动、技能需求和职位发展趋势。
如果您的业务不局限于 Google 职位抓取,您还可以考虑使用 Scrapeless 等工具从这些平台获取招聘数据,以进一步丰富您的招聘分析和市场调研。
如果您有类似的抓取需求,或者想了解如何使用Scrapeless 工具从 Crunchbase、Indeed、LinkedIn 等平台抓取数据,请联系我们。我们将提供定制的解决方案,帮助您高效完成数据抓取和分析。
Scrapeless Deep SerpApi:您强大的 Google SERP API 工具
Deep SerpApi 是一款专门为大型语言模型 (LLM) 和 AI 代理设计的专业搜索引擎 API。它提供实时、准确和无偏见的信息,使 AI 应用程序能够高效地从 Google 及其他来源检索和处理数据。
✅ 综合数据覆盖接口:涵盖 20 多种 Google SERP 场景和主流搜索引擎。
✅ 经济实惠:Deep SerpApi 的定价从每千次查询 0.10 美元起,响应时间为 1-2 秒,使开发者和企业能够高效且低成本地获取数据。
✅ 高级数据集成能力:可以集成来自所有可用在线渠道和搜索引擎的信息。
✅ 获取实时更新,数据在过去 24 小时内刷新。
作为我们未来路线图的一部分,我们完全致力于满足 AI 开发者的需求,简化动态网络信息到 AI 驱动解决方案的集成。目标是提供一个一体化 API,允许通过单个调用无缝搜索和数据提取。
🎺🎺令人兴奋的公告!
**开发者支持计划:将 Scrapeless Deep SerpApi 集成到您的 AI 工具、应用程序或项目中。[我们已经支持 Dify,并将很快支持 Langchain、Langflow、FlowiseAI 和其他框架]。然后在 GitHub 或社交媒体上分享您的成果,您将获得 1-12 个月的免费开发者支持,每月最多可达500 美元。
常见问题
Q1:如何获取 Scrapeless 的 API 密钥?
在 scrapeless.com 注册,登录您的仪表板,并在 API 密钥管理部分生成 API 密钥。
Q2:我可以从其他网站抓取职位吗?
是的,Scrapeless 支持抓取各种职位发布网站和许多其他类型的数据。Google 职位 API 只是一个示例。
Q3:我可以免费抓取 Google 职位吗?
Scrapeless 提供有限的免费试用。要继续使用,您需要付费计划,这将使您可以访问更高的限制和更高级的功能。
Q4:Scrapeless 还提供什么?
除了 Google 职位外,Scrapeless 还可以抓取许多类型的数据,包括 Google 地图、Google Flights、Google Trends 等。
结论
使用 Scrapeless API 抓取 Google 职位是一种强大且简便的方法,可以为您的项目收集职位发布信息。只需几行代码,您就可以将 Scrapeless 集成到您的抓取工具中并自动化职位数据提取过程。
通过利用 Scrapeless 的功能,您可以快速从 Google 的职位搜索引擎创建职位列表,从而节省时间并专注于构建您的招聘网站或应用程序。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


