
如何使用Python抓取Expedia数据?
Expert Network Defense Engineer
Expedia是旅行者的首选网站!用户可以轻松找到上面全面准确的旅行信息:从机票价格到度假租赁和汽车租赁。除了信息检索,Expedia还允许用户直接在其网站上预订航班、住宿和租赁,使其成为宝贵的旅行相关数据资源。
然而,Expedia不提供抓取API,这使得直接抓取大量航班信息变得困难。由于页面数量庞大,手动收集这些数据并不实际。
让我们在本文中学习更多关于如何轻松抓取Expedia上准确航班信息的方法。
现在就开始阅读吧!
为什么Expedia的数据如此重要?
通过爬取Expedia的数据,您可以获得丰富的市场信息,帮助公司在旅游行业做出更明智的决策。无论是优化运营策略,还是为客户提供更具成本效益的选择,这些数据都能发挥重要作用。
- 市场分析: 分析市场趋势和竞争价格,帮助旅行社制定更有竞争力的策略。
- 价格比较: 实时比较不同平台的价格,确保为客户提供最佳选择。
- 库存监控: 追踪航班、酒店和汽车租赁库存,及时调整供应以满足需求。
- 趋势预测: 基于历史数据预测旅行趋势,提前规划资源。
为什么从Expedia抓取数据如此困难?
与大多数现代网站一样,Expedia是一个动态网站,它使用大量的JavaScript来渲染内容和处理用户交互。因此,使用传统的基于HTML的网页抓取工具,如Beautiful Soup和Cheerio很难抓取数据,因为它们无法执行JavaScript。
使用Python抓取Expedia数据的两种方法
方法1. Scrapeless抓取API(最佳选择)
Scrapeless是一个功能强大且高效的一体化工具包,用于从Expedia和其他与旅行相关的网站提取数据。它提供了一种无缝的方式来收集有价值的信息,而无需构建您自己的抓取工具的技术挑战。
Scrapeless提供价格合理、稳定且安全的Expedia抓取API服务。它帮助您在3秒内获取航班和酒店详细信息。您只需要简单地配置参数并输入您的API令牌。
- 全面的数据提取: Scrapeless可以抓取包括航班、酒店价格、汽车租赁等旅行数据,确保您获得所需的所有信息。
- 可定制的解决方案: 提供量身定制的抓取解决方案,以满足您的特定业务需求,无论是市场分析、竞争定价还是库存监控。
- 处理动态内容: 用于管理JavaScript密集型网站的先进技术,确保完整准确的数据提取。
- 可扩展且可靠: 能够处理大规模数据抓取,可靠高效地交付项目,为您提供及时且一致的数据。
- 数据传输: 您可以将Scrapeless代码直接传输到您的数据库中,确保与现有系统的无缝集成。Scrapeless支持JSON格式的返回和导出。
- 合规性和伦理: Scrapeless确保遵守法律和伦理准则,尊重网站服务条款和数据隐私法规。
方法2. 构建您自己的Expedia Python抓取程序
缺点:
- 构建您自己的Google地图抓取工具非常耗时。
- 您可能会面临诸如IP封锁、CAPTCHA验证、设置多个代理以及管理请求限制等挑战。
使用Scrapeless和Python抓取Expedia数据
接下来,我们将详细解释如何结合Python和Scrapeless API来爬取Expedia航班数据。
在没有Scrapeless API的情况下开发时,爬取Expedia网站可能需要考虑请求速度、代理、风险控制、数据提交等问题,但现在使用Scrapeless API,您只需要配置和编辑所需数据的配置,然后运行程序,即可获得所需的数据。
注意:相关的代码和配置稍后将显示
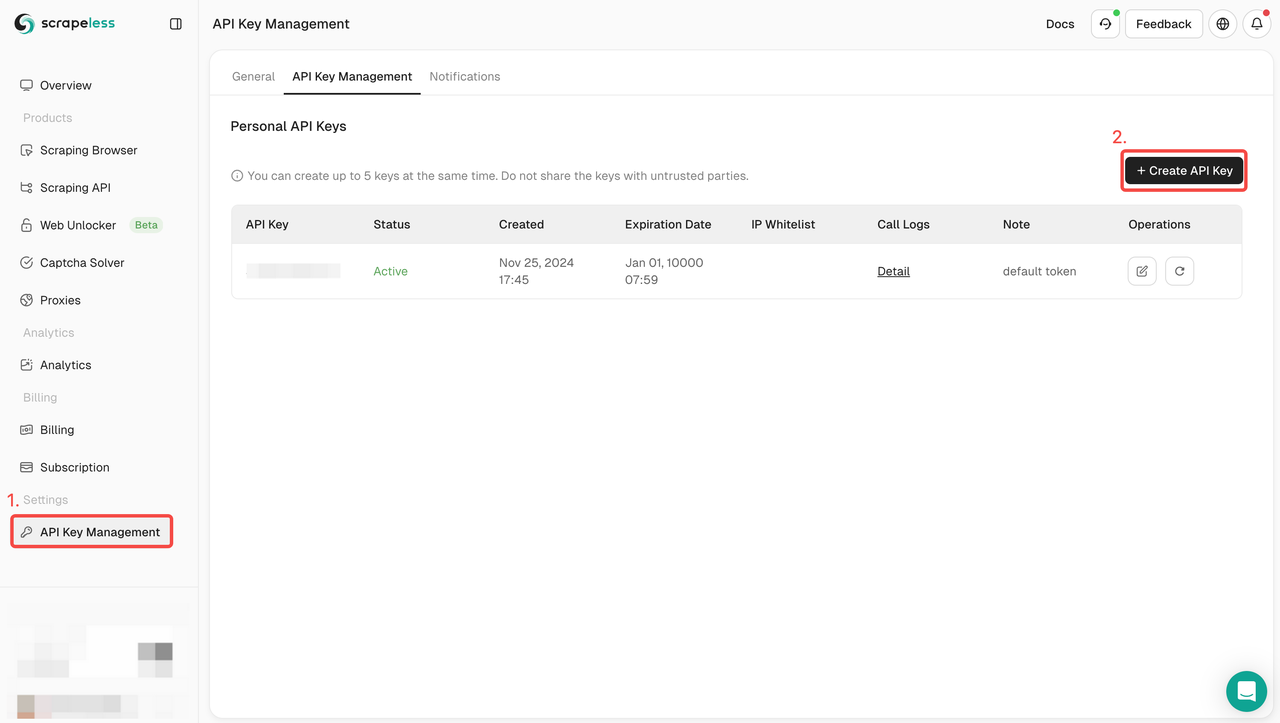
步骤1. 获取您的API密钥
首先,您需要从Scrapeless仪表板获取您的API密钥:
- 登录到Scrapeless仪表板。
- 导航到API密钥管理。
- 点击创建以生成您的唯一API密钥。
- 创建完成后,只需点击API密钥即可复制它。
完成Scrapeless注册后,您将获得2美元的免费搜索余额。
步骤2. 编写Scrapeless API请求代码
以下是我的参考请求代码。您可以根据需要调整具体的值:
Python
payload = {
"actor": "scraper.expedia", # 要调用的服务
"input": {
"origin": "Tokyo (and vicinity), Tokyo Prefecture, Japan", # 出发地址
"destination": "New York, NY, United States of America (NYC-All Airports)", # 目的地
"date": {"year": 2025, "month": 3, "day": 5}, # 出发日期
"cabin_class": "PREMIUM_ECONOMY", # 客舱等级
"travelers": {
"adult": 1, # 成人数量
"children": [], # 2-17岁儿童年龄
"infants_on_lap": [], # 0-1岁婴儿年龄(怀抱)
"infants_in_seat": [], # 0-1岁婴儿年龄(单独座位)
},
"size": 20, # 每次查询返回的数据数量,最多20
"page": 0, # 查询的页数
},
}步骤3. 集成到Scrapeless API
还记得我们刚刚创建的API密钥吗?在编写请求后,我们需要正式访问Scrapeless API服务。请在下面的代码中填写您的API令牌:
Python
url = "https://api.scrapeless.com/api/v1/scraper/request"
headers = {"x-api-token": api-key} # 输入您的API密钥
res = requests.post(url, json=payload, headers=headers)完整代码:
Python
import time
import requests
api_key = "..."
headers = {"x-api-token": api_key}
payload = {
"actor": "scraper.expedia",
"input": {
"page": 0,
"origin": "Tokyo (and vicinity), Tokyo Prefecture, Japan",
"destination": "New York, NY, United States of America (NYC-All Airports)",
"date": {"year": 2025, "month": 4, "day": 22},
"cabin_class": "PREMIUM_ECONOMY",
"travelers": {
"adult": 1,
"children": [],
"infants_on_lap": [],
"infants_in_seat": [],
},
"size": 20,
"page": 0,
},
}
url = "https://api.scrapeless.com/api/v1/scraper/request"
res = requests.post(url, json=payload, headers=headers)
print(data.text)
data = res.json()
# 如果发生超时,我们返回任务ID
if "taskId" in data:
for i in range(10):
time.sleep(1)
url = "https://api.scrapeless.com/api/v1/getTaskResult/" + data["taskId"]
resp = requests.get(url, headers=headers)
if resp.status_code != 200:
print("failed:", resp.text)
break
if "data" in resp.json():
print("succeed:", resp.text)
break
print(resp.text)抓取结果参考

进一步阅读:
通过APIDocs抓取Expedia数据
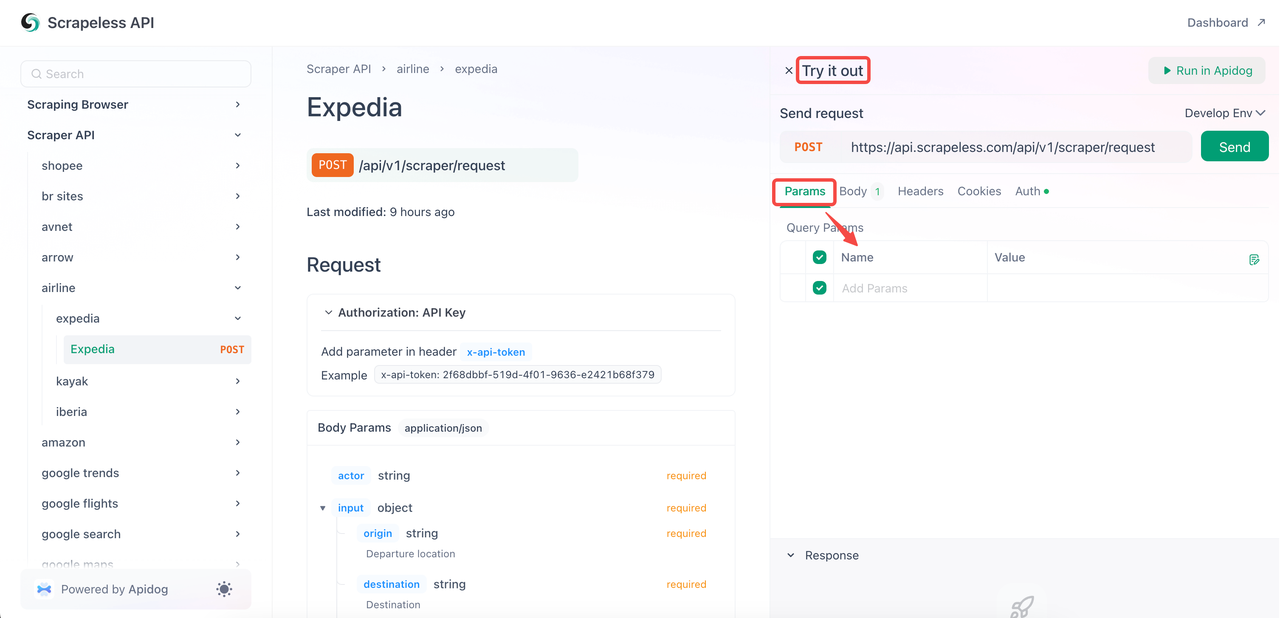
您也可以直接在Scrapeless API文档中抓取Expedia航班数据。请参考以下步骤。
- 步骤1. 创建您的API令牌(前面已提到)。
- 步骤2. 转到Expedia页面并点击“试一下”。
- 步骤3. 在“参数”部分配置您需要的参数。您可以在“主体”中查看整体代码内容。
以下是参考请求代码:
Python
{
"actor": "scraper.expedia",
"input": {
"origin": "Tokyo (and vicinity), Tokyo Prefecture, Japan",
"destination": "New York, NY, United States of America (NYC-All Airports)",
"date": {
"year": 2025,
"month": 3,
"day": 5
},
"cabin_class": "PREMIUM_ECONOMY",
"travelers": {
"adult": 1,
"children": [],
"infants_on_lap": [],
"infants_in_seat": []
},
"size": 20,
"page": 0
}
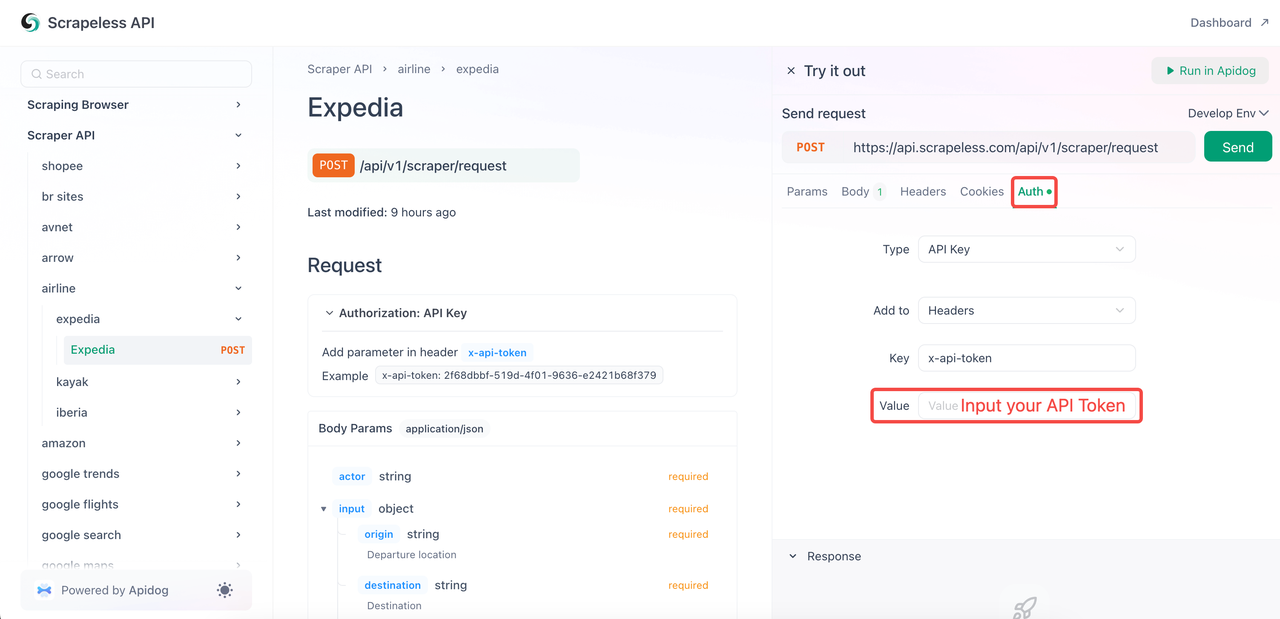
}- 步骤4. 最重要的是点击“身份验证”并粘贴您的API令牌。最后,点击“发送”来抓取数据!
- 爬取结果参考:
JSON
{
"data": {
"flightsSearch": {
"flightsSheets": null,
"clientMetadata": {
"pageName": "TYO to NYC flights",
"pageNameAnalytics": {
"__typename": "FlightsAnalytics",
"linkName": "Flight Search Page One Way",
"referrerId": "page.Flight-Search-Oneway"
},
"responseTags": [
"RESPONSE_SUMMARY_HYBRID",
"UNRECOGNIZED",
"UNRECOGNIZED",
"UNRECOGNIZED",
"RESPONSE_SUMMARY_REFINEMENTS_CACHE_LIVE"
],
"responseMetrics": [
{
"name": "LISTINGS_SUPPLY_RESPONSE_TIME",
"value": "1450"
}
],
"evaluatedExperiments": [
{
"bucket": 0,
"id": "FARES_ON_FSR_VARIANT"
},
{
"bucket": 1,
"id": "RECOMMENDED_SORT_V2_ENABLED"
},
{
"bucket": 0,
"id": "CACHE_HYDRATOR_FEATURE"
},
{
"bucket": 0,
"id": "TEST_SEARCH_STACK"
},
{
"bucket": 0,
"id": "NONSTOP_ENABLED"
},
{
"bucket": 1,
"id": "VERTICAL_SLICING_ENABLED"
},
{
"bucket": 0,
"id": "SHARED_UI_LISTINGS_ENABLED"
}
]
},Scrapeless Deep SerpApi已准备就绪!
Deep SerpAPi是一个专为大型语言模型(LLM)和AI代理设计的专用搜索引擎。它提供实时、准确和无偏见的信息,使AI应用程序能够有效地检索和处理数据:
✅ 它内置了20多个Google Search API场景接口,并连接到主流搜索引擎的数据。
✅ 它涵盖了20多种数据类型,例如搜索结果、新闻、视频和图像。
✅ 它支持过去24小时内的历史数据更新。
Deep SerpApi将充分考虑AI开发者的需求!我们将简化将动态网页信息集成到AI驱动解决方案的过程,最终实现一个一键搜索和提取网页数据的一体化API。此外,我们将长期保持该领域最低的价格:0.1-0.3美元/1K查询。
不要错过我们的开发者赞助计划!
加入我们的社区,立即获得50万免费积分。
结语
手动构建Python爬虫可以爬取Expedia数据,但很容易遇到各种网站封锁障碍。如果您想更安全、直接、快速、准确地爬取Expedia航班数据,您可以尝试Scrapeless抓取API。只需要简单的参数配置和数据填充,即可无缝完成结果爬取。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


