
什么是网页抓取?如何从网站抓取数据?
Senior Web Scraping Engineer
网络抓取是一种自动化过程,用于从网站提取数据,并将非结构化或半结构化的网络数据转换为结构化格式,例如CSV或JSON。
由于各行各业(包括电子商务、金融、营销和研究)越来越依赖数据进行决策,这项技术受到了广泛关注。
利用可靠的网络抓取服务可以进一步提高数据提取过程的效率。这对于进行市场研究、提高销售和营销团队的潜在客户开发效率以及为竞争激烈的零售和旅游企业提供价格监控尤其重要。
什么是网络抓取以及如何无缝抓取网站?
本文将提供详细指南!
什么是网络抓取?
网络抓取涉及使用软件或脚本从网站收集和处理信息。与手动收集数据不同,网络抓取可以自动化提取过程,使其更高效且更具可扩展性。其主要目标是收集可操作的见解或大型数据集,用于分析、研究或集成到应用程序中。
网络抓取在为机器学习模型提供数据方面发挥着关键作用,进一步推动了人工智能技术的发展。通过自动化数据收集过程并扩展数据以从各种来源收集信息,网络抓取有助于创建强大、准确且训练有素的人工智能模型。
如果您想要获取数据的公共网站没有API,或者仅提供有限的网络数据访问权限,则网络抓取特别有用!
在这种情况下,传统方法无法满足需求,利用Scrapeless等外部网络抓取服务可能是一种策略性方法。这些服务提供了更高效和更具可扩展性的解决方案。此外,对于那些寻求高级功能的用户,Scrapeless的API和Scraping Browser等工具提供了全面的解决方案,提供了处理阻止、自动浏览器操作、会话和Cookie管理以及高效数据提取等功能。
与其他类似产品相比,Scrapeless还提供更低廉的价格,同时确保高稳定性。它减轻了预算有限但需求强烈的公司的成本负担。
网络抓取是如何工作的?
网络抓取是自动化收集非结构化和结构化数据的过程。它也被广泛称为网络数据提取或网络数据抓取。
网络抓取的一些主要用例包括价格监控、价格情报、新闻监控、潜在客户开发和市场研究等。
一般来说,它被希望利用公开可用的网络数据来生成有价值的见解并做出更明智决策的个人和企业使用。
手动网络抓取
如果您曾经从网站复制粘贴信息,那么您执行的功能与任何网络抓取工具相同,只是您手动执行了数据抓取过程:
- 确定目标网站
- 收集目标页面的URL
- 向这些URL发出请求以获取页面的HTML
- 使用定位器在HTML中查找信息
- 将数据保存为JSON或CSV文件或其他结构化格式
这似乎足以满足日常网络抓取的需求。不幸的是,如果您需要大规模提取数据,则需要处理相当多的挑战。
例如,如果网站布局发生更改,维护数据提取工具和网络爬虫,管理代理,执行javascript,或绕过反机器人。这些都是消耗内部资源的技术问题。
此时,我们需要使用更强大的自动化工具——网络抓取器
网络抓取器
与自己费力地提取数据不同,网络抓取使用机器学习和智能自动化从互联网检索数百万甚至数十亿个提取的数据点。
- 网络抓取通过向网站发送HTTP请求并获取其HTML内容来工作。
- 然后,脚本使用标签、属性或模式解析HTML结构以定位和提取特定数据点。
- 高级方法可以通过使用Puppeteer或Selenium等工具模拟浏览器行为来处理通过JavaScript呈现的动态内容。
无论您自己编写网络抓取器还是使用强大的网络数据提取工具,您都需要了解有关网络抓取或网络数据提取基础知识的更多信息!
网络抓取和网络爬取的区别
| 特性 | 网络抓取 | 网络爬取 |
|---|---|---|
| 目标 | 提取特定数据 | 爬取网页链接并构建内容索引 |
| 范围 | 关注少量网页和特定内容 | 爬取大量网页 |
| 技术复杂性 | 中等,主要用于数据分析 | 高,需要管理链接跟踪和重复数据删除 |
| 常用工具 | BeautifulSoup, Puppeteer, Scrapy | Scrapy, Apache Nutch, Selenium |
| 主要应用 | 数据分析,电子商务价格监控 | 搜索引擎索引,SEO分析 |
网络抓取
网络抓取是一个集中的过程,用于从网页提取特定数据并将其转换为结构化格式,例如CSV或JSON。目标是检索精确的信息,例如价格、评论或产品详细信息,以便进行分析或进一步使用。抓取器使用XPath、CSS选择器或正则表达式来高效地定位和提取所需数据。
网络爬取
网络爬取,通常称为“蜘蛛”,是一个自动浏览互联网的过程,通过跟踪链接来索引和收集网页。爬虫通常用于构建大型数据集或索引,例如搜索引擎的索引。在某些项目中,网络爬取是收集URL的初步步骤,然后由网络抓取器处理以提取特定数据。
抓取网站的2种常用网络抓取方法
为了让您更清楚地了解如何抓取网站,我们现在将使用2种流行且强大的爬取工具:Scraping API和Scraping Browser来抓取Google Trends。
Scraping API
使用高级Scraping API,您可以轻松访问和抓取Google Trends数据,无需编写或维护复杂的抓取脚本。只需调用我们提供的API即可快速获得所需的所有信息。
您可以轻松抓取Google Trends数据的类别,例如:
- 一段时间内的兴趣
- 按区域细分的比较
- 按子区域划分的兴趣
- 相关查询
- 相关主题
让我们看看详细步骤:
- 步骤1. 登录Scrapeless
- 步骤2. 点击“Scraping API”
- 步骤3. 找到我们的“Google Trends”面板并进入:
- 步骤4. 在左侧操作面板中配置您的数据:
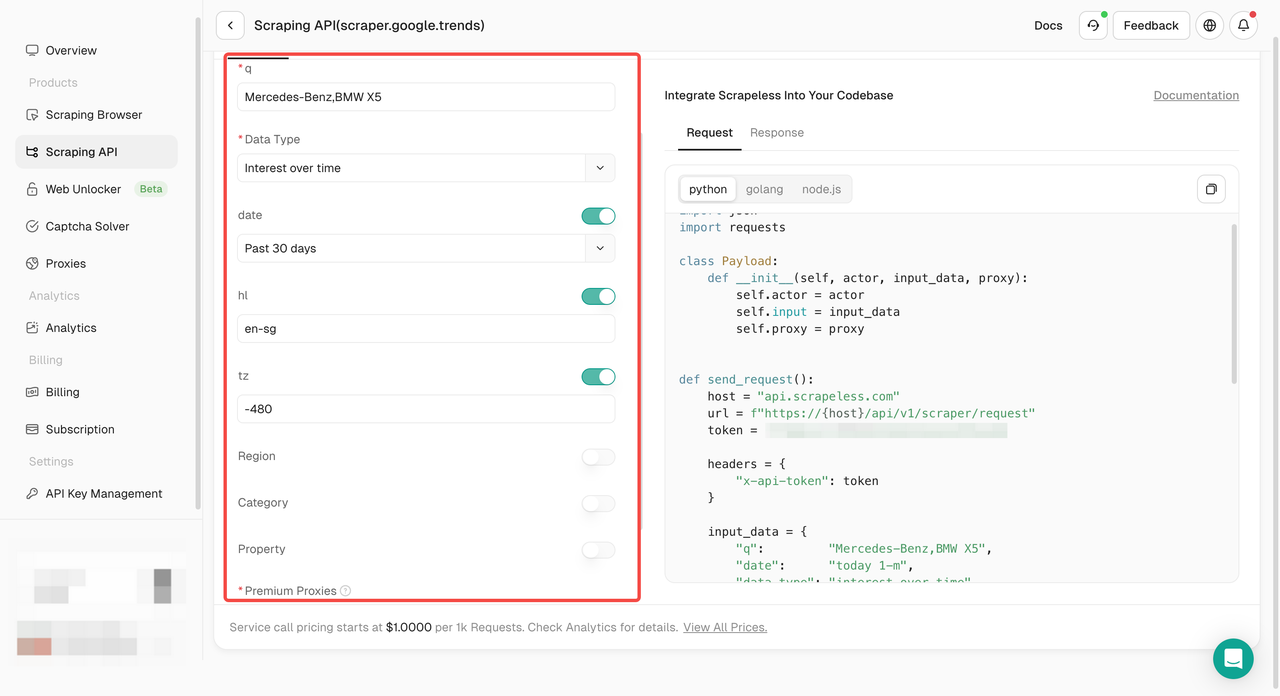
- 步骤5. 点击“开始抓取”按钮,然后您就可以获得结果:
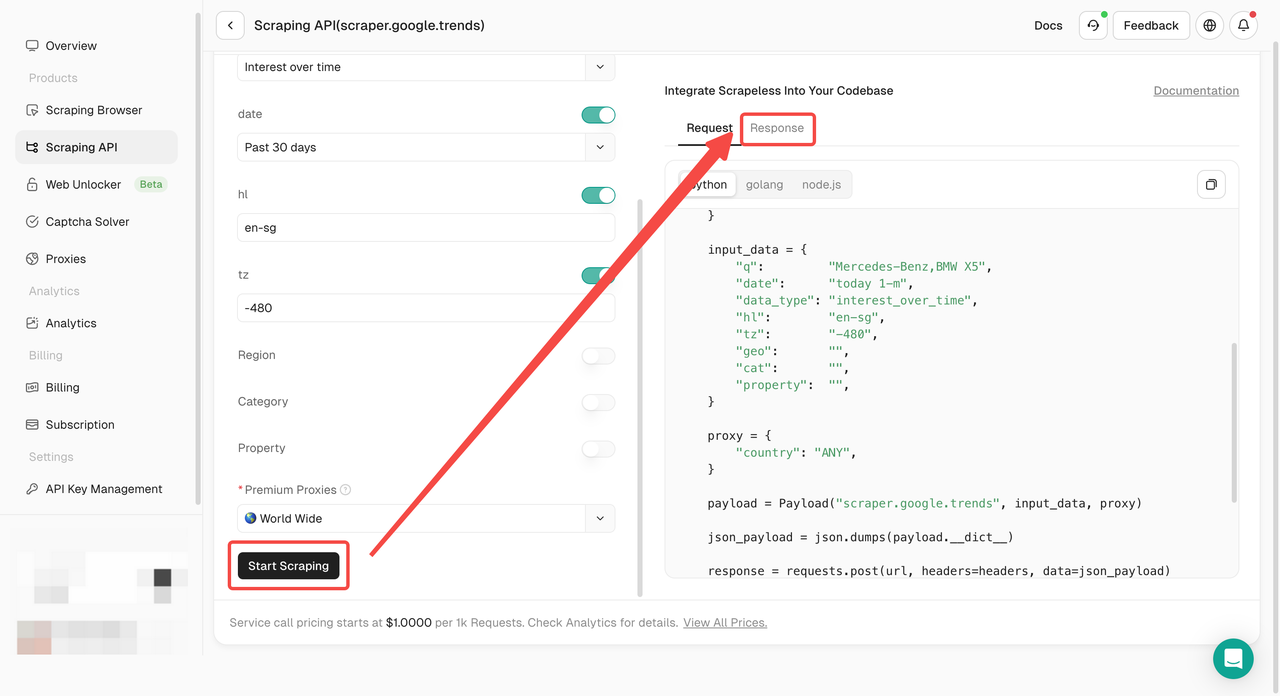
或者您可以将我们的API部署到您自己的项目中,例如:
- Python
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.trends",
"input": {
"keywords": "Mercedes-Benz,BMW X5",
"geo": "",
"time": "today 1-m",
"category": "0",
"property": ""
},
"proxy": {
"country": "US"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.trends",
"input": {
"data_type": "autocomplete",
"q": "Mercedes-Benz"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}Scraping Browser
需求:
- Node.js: 确保安装了14版或更高版本。
- npm: 用于处理依赖项的Node包管理器。
- Scrapeless Browserless Service: 使用Scrapeless提供的浏览器服务。
然后,请访问Scraping Browser仪表板,导航到“设置”选项卡,并检索您的API密钥。
然后,请按照我们的步骤操作:
- 使用以下命令安装必要的依赖项:
Bash
npm install- 设置环境变量
在项目根目录中创建一个.env文件,并添加您的API密钥,如下所示:
Bash
API_KEY=your_scrapeless_api_key- 自定义脚本参数
该脚本预先配置为在过去7天内获取美国“youtube”和“twitter”的趋势。您可以调整以下设置:
- 关键词: 修改
QUERY_PARAMS变量中的q参数以更改搜索词。 - 地理位置: 更新
geo参数以设置所需的位置。 - 日期范围: 根据您要分析的时间段调整
date参数。
- 设置Cookie
为了稳定与随时间变化的兴趣相关的数据,请在访问网站之前使用Puppeteer配置cookie:
JavaScript
const cookies = JSON.parse(fs.readFileSync('./data/cookies.json', 'utf-8'));
await browser.setCookie(...cookies);要生成cookies.json文件,请通过您的浏览器登录Google Trends并以JSON格式导出cookie。如果您不确定如何操作,请考虑使用专为cookie导出设计的浏览器扩展程序。
- 使用Node.js执行脚本:
Bash
node index.js网络抓取可以用于什么?
价格情报
是的,价格情报是网络抓取最大的用例。
从电子商务网站提取产品和价格信息,然后将其转化为情报,是现代电子商务公司的一个重要组成部分,这些公司希望根据数据做出更好的定价/营销决策。
网络价格数据和价格情报的好处:
- 动态定价
- 收入优化
- 竞争对手监控
- 产品趋势监控
- 品牌和MAP合规性
市场研究
市场研究至关重要,应该以最准确的信息为驱动。通过数据抓取,您可以访问各种形状和大小的高质量、高容量、高洞察力的网络抓取数据,这些数据正在推动全球市场分析和商业情报。
- 市场趋势分析
- 市场定价
- 优化切入点
- 研究与开发
- 竞争对手监控
金融替代数据
利用为投资者量身定制的网络数据,从头开始发现alpha并创造价值。
决策从未如此明智,数据也从未如此富有洞察力——鉴于其令人难以置信的战略价值,网络抓取数据越来越多地被世界领先的公司使用。
- 从SEC文件提取见解
- 评估公司基本面
- 公众情绪整合
- 新闻监控
房地产
过去二十年来房地产的数字化转型有可能扰乱传统业务,并催生行业中强大的新参与者。
通过将从网络抓取的房地产数据纳入日常运营,代理商和经纪公司可以抵御自上而下的在线竞争,并在市场中做出明智的决策。
- 评估房产价值
- 监控空置率
- 预计租金收益
- 了解市场方向
新闻和内容监控
现代媒体可以在一个新闻周期内为您的业务创造巨大的价值或带来生存威胁。
如果您的公司依赖及时的新闻分析,或者是一家经常出现在新闻中的公司,那么网络抓取新闻数据是监控、聚合和解析您所在行业最重要新闻的最终解决方案。
- 投资决策
- 在线公众舆论分析
- 竞争对手监控
- 政治活动
- 情绪分析
潜在客户开发
潜在客户开发是所有企业的关键营销/销售活动。
在2024年Hubspot的一份报告中,65%的入站营销人员表示,生成流量和潜在客户是他们最大的挑战。幸运的是,可以使用网络数据提取从网络获取结构化的潜在客户列表。
品牌监控
在当今竞争激烈的市场中,保护您的在线声誉是重中之重。
无论您是在线销售产品并需要执行严格的定价策略,还是只想了解人们如何看待您的产品,使用网络抓取进行品牌监控都可以为您提供这些信息。
业务自动化
在某些情况下,访问数据可能会很麻烦。也许您需要以结构化的方式从您自己或合作伙伴的网站提取数据。
但是没有简单的方法在内部做到这一点,因此创建一个抓取工具并直接抓取数据是一个明智之举。而不是尝试用复杂的内部系统来解决它。
MAP监控
最低广告价格 (MAP) 监控是一种标准做法,用于确保品牌的在线价格与其定价策略一致。
由于经销商和分销商数量众多,手动监控价格是不可能的。
这就是为什么网络抓取如此方便,因为您可以轻松监控产品价格。
如何免费抓取网站?
有各种可用的免费网络抓取解决方案,可用于自动抓取内容并从网络提取数据。这些解决方案的范围从面向非专业人士的简单点击式抓取解决方案到具有广泛配置和管理选项的更强大的面向开发人员的应用程序。
Scraping API和Scraping Browser将成为最强大的工具,与互联网社会的发展相一致。它们内置了网络解锁器、代理和CAPTCHA等功能,使您的网络抓取更加便捷和快速。
只需简单的配置操作即可立即获得最准确的数据。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


