
如何使用 Puppeteer绕过 Cloudflare
Advanced Data Extraction Specialist
在数据采集和网页爬取领域,开发者经常面临一个棘手的问题:如何有效绕过Cloudflare的防护机制。作为全球广泛使用的网站安全和性能优化服务,Cloudflare的反爬虫和防火墙功能给数据爬取带来了相当大的挑战。当使用Puppeteer进行网页爬取时,这个问题尤其突出。本文将深入探讨如何使用Scrapeless Scraping Browser结合Puppeteer,轻松突破Cloudflare的限制,开启高效稳定的数据采集之旅。
Cloudflare如何检测机器人
Cloudflare使用多种技术组合来检测机器人,包括:
- 行为分析 – 监控鼠标移动、按键、滚动行为和交互模式,以区分人类用户和机器人。
- IP信誉 – 使用全球威胁情报数据库,根据以往活动识别可疑IP地址。
- 挑战-响应测试 – 部署CAPTCHA或JavaScript挑战,以验证访问者是否是人类。
- 指纹识别 – 分析浏览器特性、HTTP头部和设备属性以检测自动化。
- 速率限制 – 标记异常的请求模式,例如高频或非人类的浏览行为。
- 机器学习 – 使用在海量流量数据上训练的AI模型来识别类似机器人的行为。
- TLS指纹识别 – 检查TLS连接的建立方式,以区分真实的浏览器和自动化脚本。
- JavaScript执行监控 – 检查JavaScript是否正确执行,以检测无头浏览器和禁用脚本的机器人。
为什么仅Puppeteer无法绕过Cloudflare
以下是包含核心关键词“绕过Cloudflare”的翻译:
1. Cloudflare复杂的检测机制
Cloudflare使用多种方法来检测和区分人类用户和Puppeteer之类的自动化工具,包括行为分析、IP信誉检查和HTTP指纹识别。这些机制使得Puppeteer单独绕过Cloudflare变得困难。
2. Puppeteer的默认行为很容易被识别
默认情况下,Puppeteer表现出的行为与人类用户不同,例如:
- 固定不变的用户代理字符串与典型浏览器不匹配。
- 缺乏类似人类的交互,例如不自然的鼠标移动或点击模式。
- 独特的请求头会将其暴露为自动化工具。
3. Cloudflare的挑战机制
当Cloudflare检测到可疑流量时,它会触发诸如CAPTCHA或验证步骤之类的挑战。Puppeteer本身无法解决这些挑战,因此无法在没有其他工具的情况下绕过Cloudflare。
4. 需要额外的配置和工具
为了绕过Cloudflare,Puppeteer需要额外的设置,例如:
- 使用随机延迟和真实的交互来模拟人类行为。
- 使用代理IP来避免IP封禁。
- 修改请求头以模拟真实浏览器。
- 集成CAPTCHA解决服务,例如2Captcha。
5. 持续更新的检测规则
Cloudflare定期更新其检测算法,使旧的绕过方法随着时间的推移变得无效。
总之,Puppeteer单独难以绕过Cloudflare的检测。它需要与其他技术和工具结合使用,才能有效地模拟人类行为并处理Cloudflare的挑战。
方法一:使用puppeteer-extra-plugin-stealth绕过Cloudflare
puppeteer-extra-plugin-stealth是一个补丁,通过掩盖Puppeteer的自动化浏览器属性来帮助绕过Cloudflare,使其看起来像一个真实的浏览器。
例如,Stealth插件会覆盖WebDriver属性,并将HeadlessChrome标志替换为Chrome以掩盖自动化信号。它还会模拟其他合法浏览器属性,例如chrome.runtime,即使在无头模式下也能使其看起来像有头模式。
Puppeteer Stealth插件使用与基础Puppeteer类似的API,因此对于已经使用Puppeteer的开发者来说,没有学习曲线。
让我们绕过CoinTracker(一个具有简单Cloudflare保护的网站)来了解Puppeteer Stealth的工作原理。
首先,安装插件:
npm install puppeteer-extra puppeteer-extra-plugin-stealth现在,导入所需的库并添加Stealth插件。然后,请求受保护的网站并截取其主页的屏幕截图:
// npm install puppeteer-extra puppeteer-extra-plugin-stealth
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
// add the stealth plugin
puppeteer.use(StealthPlugin());
(async () => {
// set up browser environment
const browser = await puppeteer.launch();
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://sailboatdata.com/sailboat/11-meter/', {
waitUntil: 'load',
});
// take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();Puppeteer Stealth插件绕过了Cloudflare并截取了网站主页的屏幕截图,如图所示:
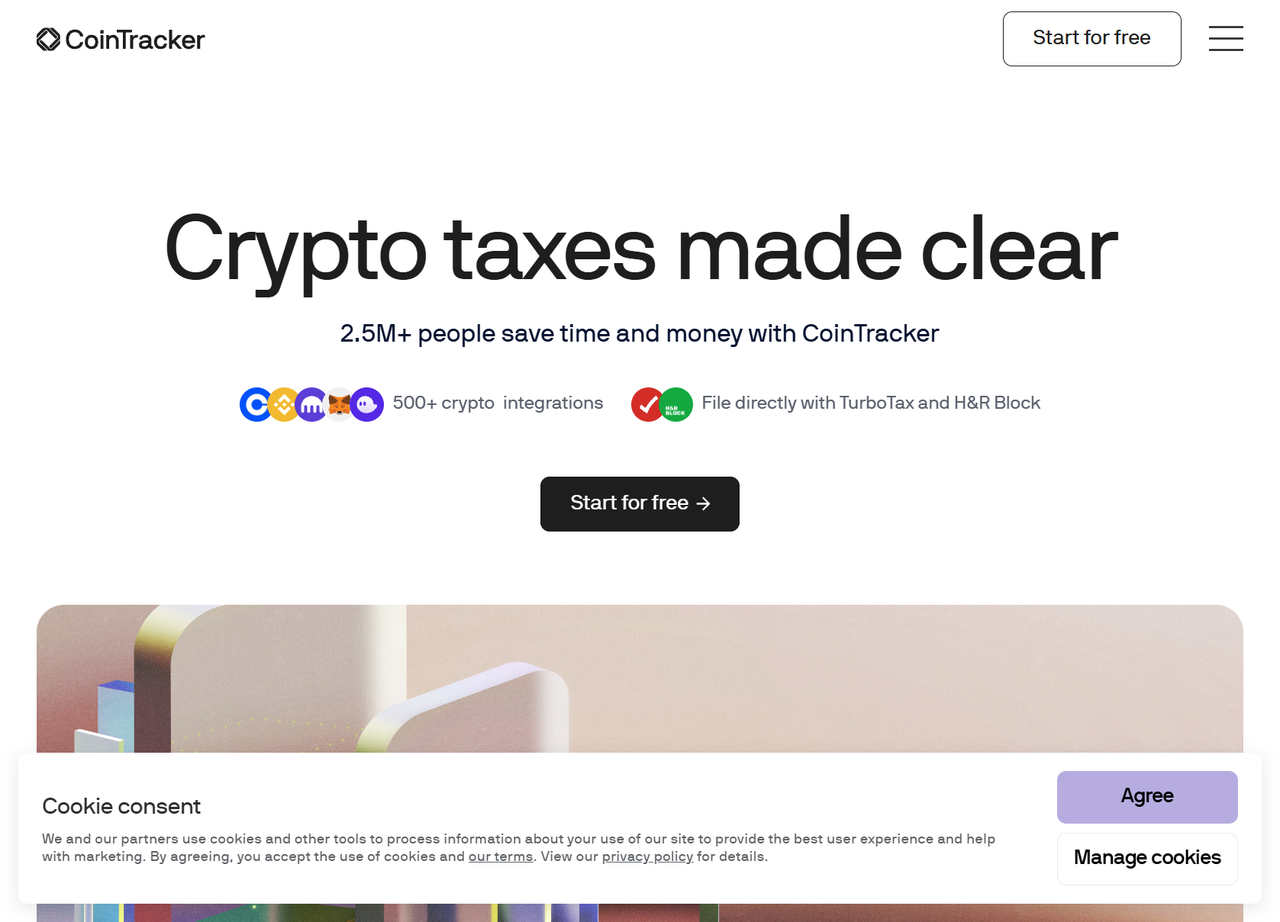
你已经成功躲避了Cloudflare的检测。
当然,当前目标网站易于访问,因为它没有强制执行任何复杂的检测技术。
Puppeteer Stealth插件能否处理更高级的安全措施?答案是……
Stealth插件被阻止了,如图所示。
Puppeteer Stealth插件的局限性
某些网站使用比其他网站更高级的Cloudflare安全检查。在这种情况下,使用Puppeteer-extra-plugin-stealth Cloudflare规避技术来掩盖Puppeteer的自动化属性不足以通过。
例如,在尝试访问Cloudflare挑战页面时,Puppeteer Stealth被阻止了。
尝试将之前的目标URL替换为挑战页面URL来自己尝试:
// npm install puppeteer-extra puppeteer-extra-plugin-stealth
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
// add the stealth plugin
puppeteer.use(StealthPlugin());
(async () => {
// set up browser environment
const browser = await puppeteer.launch();
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {
waitUntil: 'networkidle0',
});
// wait for the challenge to resolve
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
// take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();Stealth插件被阻止了,如图所示:
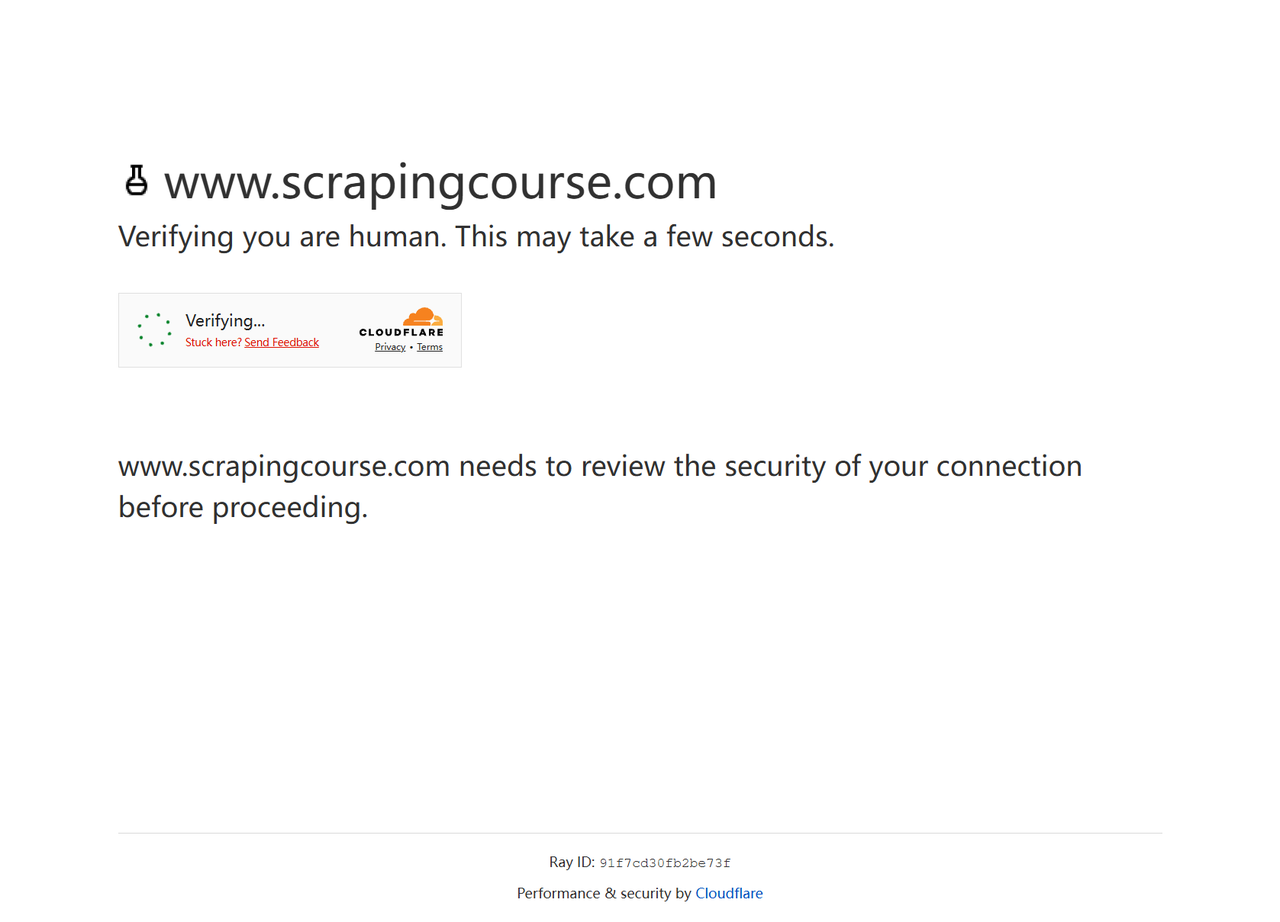
结果表明,更高级的Cloudflare反机器人系统将Stealth插件检测为机器人。Stealth插件仍然具有一些可检测的特征,例如WebGL或Canvas渲染不一致,从而将其暴露为机器人。
如何解决这些限制并从复杂的网站中提取数据?答案是Scrapeless。
方法二:使用Scrapeless和Puppeteer绕过Cloudflare
避免Puppeteer及其Stealth插件限制的最简单方法是将库与Scrapeless Scraping Browser集成。使用Scrapeless Scraping Browser,你的Puppeteer爬虫将获得高级规避功能,使其看起来像人类并绕过反机器人检测。
你只需在现有的Puppeteer脚本中添加一行代码,Scraping Browser将帮助你处理核心浏览器指纹识别、添加缺失的插件和扩展、管理住宅代理轮换等等。
Scraping Browser还在云端运行,避免了运行本地浏览器实例的内存开销。此功能使其具有高度可扩展性。
Scrapeless Scraping Browser的关键特性
Scrapeless Scraping Browser是一个专为高效和大型网页数据提取而设计的工具:
- 模拟真实的人类交互行为,以绕过高级反爬虫机制,例如浏览器指纹识别和TLS指纹识别检测。
- 支持自动解决多种类型的验证码,包括cf_challenge,以确保爬取过程不中断。
- 与Puppeteer和Playwright等流行工具无缝集成,简化开发流程,并支持使用一行代码启动自动化任务。
如何将Scraping Browser与Puppeteer集成
Scrapeless需要puppeteer-core,这是一个不下载Chrome二进制文件的Puppeteer版本。因此,请确保安装它:
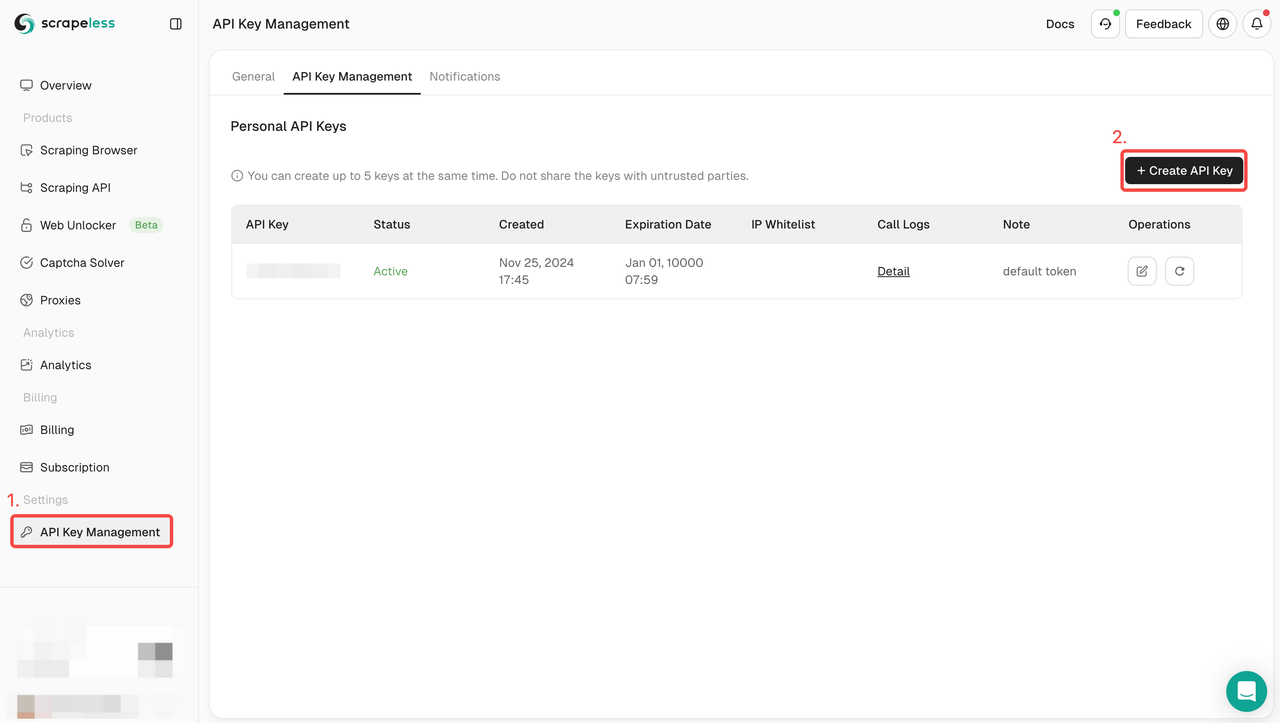
npm install puppeteer-core步骤1. 注册Scrapeless,点击API Key Management > Create API Key创建你的Scrapeless API Key。
注册Scrapeless并获得免费试用。如有任何疑问,也可以通过Discord联系Liam
步骤2. 然后,转到Scraping Browser并复制你的浏览器URL。
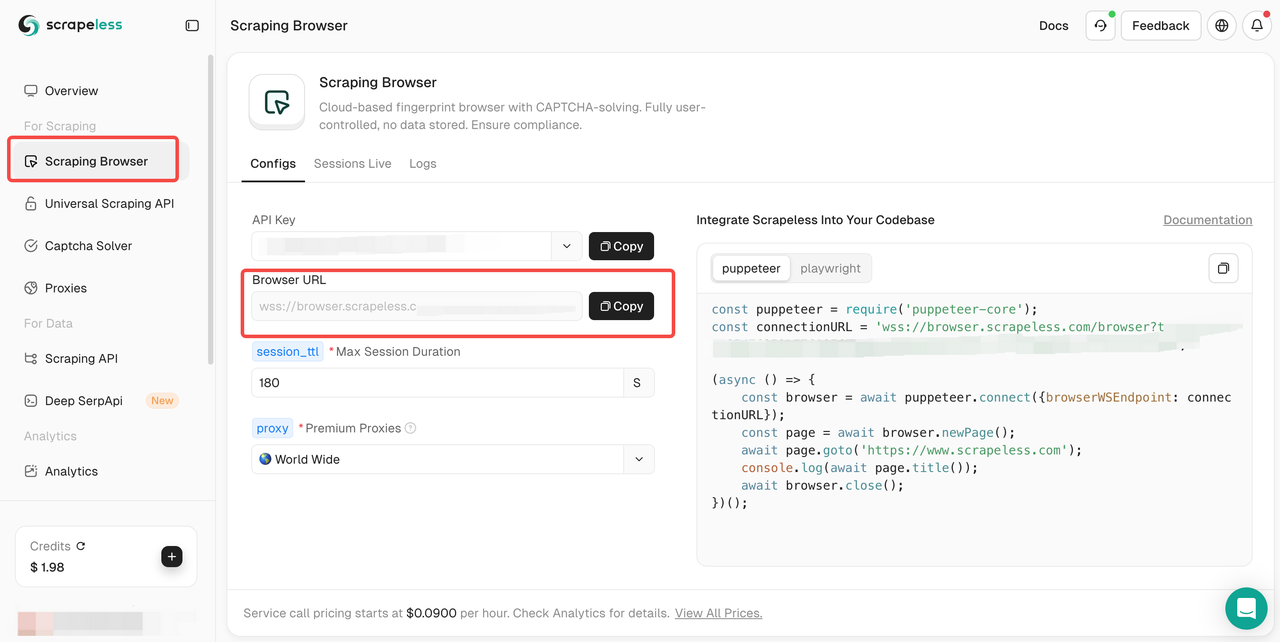
将复制的浏览器URL集成到你的Puppeteer脚本中,如下所示:
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_Scrapeless_API_KEY>&session_ttl=180&proxy_country=ANY';
(async () => {
// set up browser environment
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
});
// create a new page
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {
waitUntil: 'networkidle0',
});
// wait for the challenge to resolve
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
//take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();你需要将
https://www.scrapingcourse.com/cloudflare-challenge替换为任何具有cloudflare-challenge的网站;还要将你的Scrapeless API Key替换到token部分。
以上代码访问并截取了受保护页面的屏幕截图。请参见下面的结果:
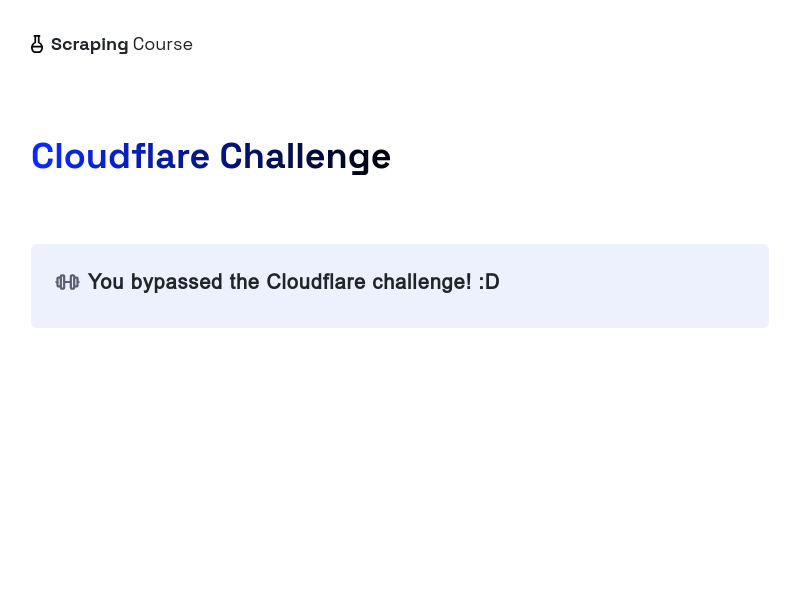
恭喜🎉!你已成功使用Puppeteer和Scrapeless绕过Cloudflare。
将Scrapeless Scraping Browser集成到Puppeteer以绕过Cloudflare的好处
将Scrapeless Scraping Browser集成到Puppeteer以绕过Cloudflare具有以下好处:
- 增强反检测能力
Puppeteer本身具有明显的自动化特征(例如,navigator.webdriver属性、HeadlessChrome用户代理标志),使得Cloudflare很容易将其识别为机器人。Scrapeless Scraping Browser可以模拟真实浏览器的指纹(类型、用户代理、屏幕分辨率等),有效隐藏Puppeteer的自动化特征,降低Cloudflare检测的风险,提高爬取成功率。
- 简化配置和集成
Scrapeless Scraping Browser提供易于使用的API和集成方法。开发者可以在现有的Puppeteer脚本中添加少量代码来利用其强大的反检测功能,无需了解Puppeteer的内部机制或Cloudflare的反爬虫机制。这降低了开发障碍和工作量。
- 增强代码可维护性
使用Scrapeless Scraping Browser减少了对Puppeteer底层配置和自定义脚本的依赖。这使得代码更简洁清晰,方便未来的维护和升级。
额外资源
结论
总而言之,使用Puppeteer绕过Cloudflare需要有效的工具和方法。Scrapeless Scraping Browser通过增强反检测能力、简化集成和提高可维护性,提供了一个简单而强大的解决方案。在爬取时,请务必确保遵守法律法规。
提升您的业务效率,选择Scrapeless Scraping Browser的企业级定制化解决方案。我们提供专业高效的数据采集服务。
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


