
如何使用 Node-Fetch API 在 Node.js 中发起 HTTP 请求?
Specialist in Anti-Bot Strategies
我们目前的网站通常依赖于数十种不同的资源,例如单体化的图像、CSS、字体、JavaScript、JSON 数据等等。然而,世界上第一个网站只用HTML编写。
JavaScript作为一种优秀的客户端脚本语言,在网站的发展中发挥了重要作用。借助XMLHttpRequest或XHR对象,JavaScript可以在不重新加载页面的情况下实现客户端和服务器之间的通信。
然而,这个动态过程受到了Fetch API的挑战。什么是Fetch API?如何在Node.js中使用Fetch API?为什么Fetch API是更好的选择?
现在就开始从本文中获取答案吧!
Node.js中的HTTP请求是什么?
在Node.js中,HTTP请求是构建Web应用程序或与Web服务交互的基础部分。它们允许客户端(例如浏览器或其他应用程序)向服务器发送数据,或从服务器请求数据。这些请求使用超文本传输协议(HTTP),这是Web上数据通信的基础。
- HTTP请求: HTTP请求由客户端发送到服务器,通常用于检索数据(例如网页或API响应)或向服务器发送数据(例如提交表单)。
- HTTP方法: HTTP请求通常包含一个方法,该方法指示客户端希望服务器执行的操作。常见的HTTP方法包括:
- GET: 从服务器请求数据。
- POST: 向服务器发送数据(例如,提交表单)。
- PUT: 更新服务器上的现有数据。
- DELETE: 从服务器删除数据。
- Node.js HTTP模块: Node.js提供了一个内置的http模块来处理HTTP请求。此模块使您可以创建HTTP服务器,侦听请求并响应它们。
为什么Node.js非常适合网络抓取和自动化?
由于其独特的特性、强大的生态系统以及异步、非阻塞架构,Node.js已成为网络抓取和自动化任务的首选技术之一。
为什么Node.js非常适合网络抓取和自动化?让我们一起找出答案!
- 异步和非阻塞I/O
- 速度和效率
- 丰富的库和框架生态系统
- 使用无头浏览器处理动态内容
- 跨平台兼容性
- 实时数据处理
- 简洁的语法,便于快速开发
- 支持代理轮换和反检测
什么是Node-Fetch API?
Node-fetch是一个轻量级模块,它将Fetch API引入Node.js环境。它简化了发出HTTP请求和处理响应的过程。
Fetch API基于Promise构建,非常适合异步操作,例如从网站抓取数据、与RESTful API交互或自动化任务。
如何在Node.JS中使用Fetch API?
Fetch API是一个现代的、基于Promise的接口,与传统的XMLHttpRequest对象相比,它以更有效和灵活的方式处理网络请求。
它在现代浏览器中得到原生支持,这意味着不需要额外的库或插件。在本指南中,我们将探讨如何利用Fetch API执行GET和POST请求,以及如何有效地管理响应和错误。
💬 注意: 如果您的计算机上未安装Node.js,则需要先安装它。您可以此处下载适合您操作系统的Node.js安装包。推荐的Node.js版本为18及以上。
步骤1. 初始化您的Node.js项目
如果您尚未创建项目,可以使用以下命令创建一个新项目:
Bash
mkdir fetch-api-tutorial
cd fetch-api-tutorial
npm init -y打开package.json文件,添加type字段,并将其设置为module:
JSON
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}步骤2. 下载并安装node-fetch库
这是一个在Node.js中使用Fetch API的库。您可以使用以下命令安装node-fetch库:
Bash
npm install node-fetch下载完成后,我们可以开始使用Fetch API发送网络请求。在项目的根目录中创建一个新的文件index.js,并添加以下代码:
JavaScript
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts')
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));执行以下命令运行代码:
Bash
node index.js我们将看到以下输出:
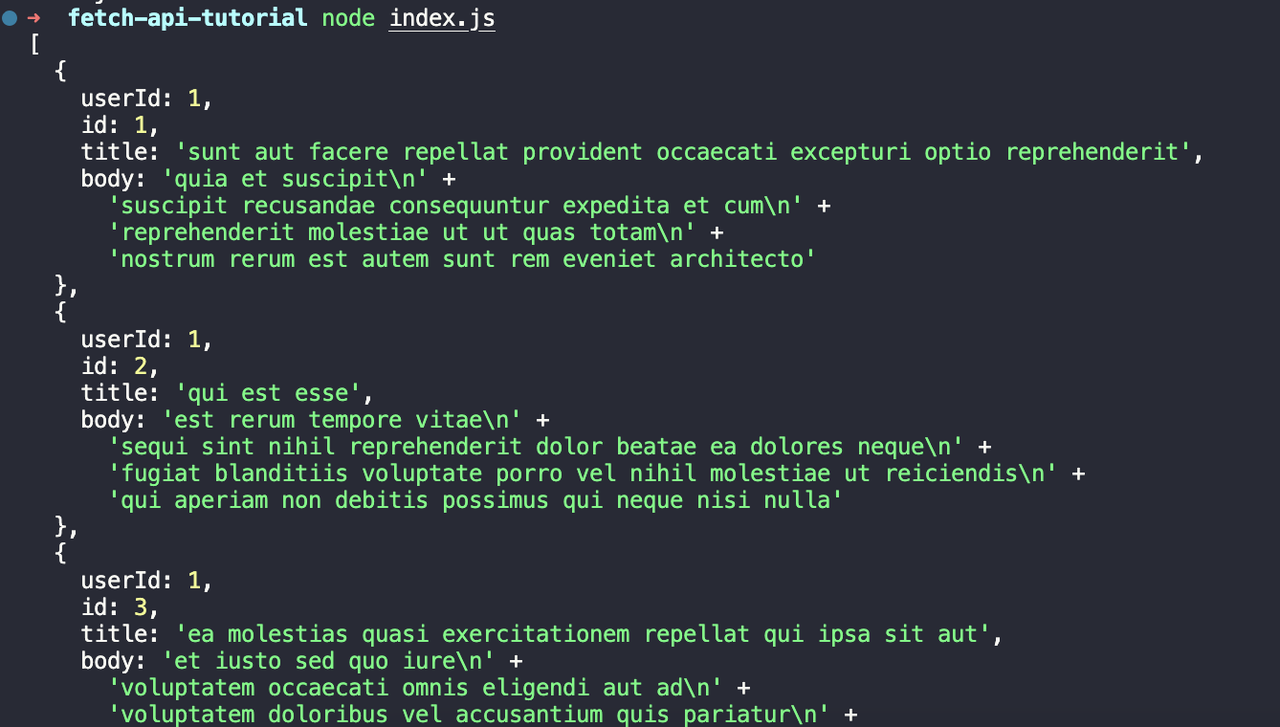
步骤3. 使用Fetch API发送POST请求
如何使用Fetch API发送POST请求?请参考以下方法。在项目的根目录中创建一个新的文件post.js,并添加以下代码:
JavaScript
import fetch from 'node-fetch';
const postData = {
title: 'foo',
body: 'bar',
userId: 1,
};
fetch('https://jsonplaceholder.typicode.com/posts', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(postData),
})
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));让我们分析一下这段代码:
- 我们首先定义一个名为
postData的对象,其中包含我们想要发送的数据。 - 然后我们使用
fetch函数向https://jsonplaceholder.typicode.com/posts发送POST请求,并将配置对象作为第二个参数传递。 - 配置对象包含请求
method、请求headers和请求body。
执行以下命令运行代码:
Bash
node post.js您将看到以下输出:

步骤4. 处理Fetch API响应结果和错误
我们需要在项目的根目录中创建一个新的文件response.js,并添加以下代码:
JavaScript
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts-response')
.then((response) => {
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
return response.json();
})
.then((data) => console.log(data))
.catch((error) => console.error(error));在上面的代码中,我们首先填写一个不正确的URL地址来触发HTTP错误。然后我们在then方法中检查结果响应的状态码,如果状态码不是200,则抛出错误。最后,我们在catch方法中捕获错误并将其打印出来。
执行以下命令运行代码:
Bash
node response.js代码执行后,您将看到以下输出:

网络抓取中的3个常见挑战
1. CAPTCHA
CAPTCHA(区分计算机和人类的完全自动公共图灵测试)旨在防止自动化系统(如网络抓取工具)访问网站。它们通常要求用户通过解决难题、识别图像中的对象或输入扭曲的字符来证明自己是人类。
2. 动态内容
许多现代网站使用JavaScript框架(如React、Angular或Vue.js)来动态加载内容。这意味着您在浏览器中看到的内容通常在页面加载后呈现,这使得使用依赖于静态HTML的传统方法进行抓取变得困难。
3. IP封禁
网站通常会实施措施来检测和阻止抓取活动,其中最常见的方法是IP封锁。当在短时间内从同一个IP地址发送过多请求时,就会发生这种情况,导致网站标记并阻止该IP。
Scrapeless抓取工具包 - 高效的抓取工具
Scrapeless是最好的综合抓取工具之一,因为它能够实时绕过网站阻止,包括IP阻止、CAPTCHA挑战和JavaScript渲染。它支持IP轮换、TLS指纹管理和CAPTCHA解决等高级功能,使其成为大规模网络抓取的理想选择。
Scrapeless如何增强Node.js网络抓取项目?
它易于与Node.js集成,并且具有很高的避免检测成功率,使Scrapeless成为绕过现代反机器人防御的可靠高效的选择,确保抓取操作平滑且不间断。
使用Scrapeless等抓取工具包与手动抓取相比的优势
- 高效处理网站阻止:Scrapeless可以实时绕过常见的反抓取防御措施,例如IP阻止、CAPTCHA和JavaScript渲染,而手动抓取无法高效地处理这些问题。
- 可靠性和成功率:Scrapeless使用IP轮换和TLS指纹管理等高级功能来避免检测,与手动抓取相比,确保更高的成功率和不间断的抓取。
- 易于集成和自动化:与Node.js无缝集成,并自动化整个抓取工作流程,与手动数据收集相比,这节省了时间并减少了人为错误。
只需按照简单的步骤,即可将Scrapeless集成到您的Node.js项目中。
是时候继续滚动浏览了!接下来会更精彩!
将Scrapeless抓取工具包集成到您的Node.js项目中
在开始之前,您需要注册Scrapeless帐户。您还可以参考官方网站了解有关Scrapeless的更多信息。
步骤1. 在Node.js中访问Scrapeless抓取API
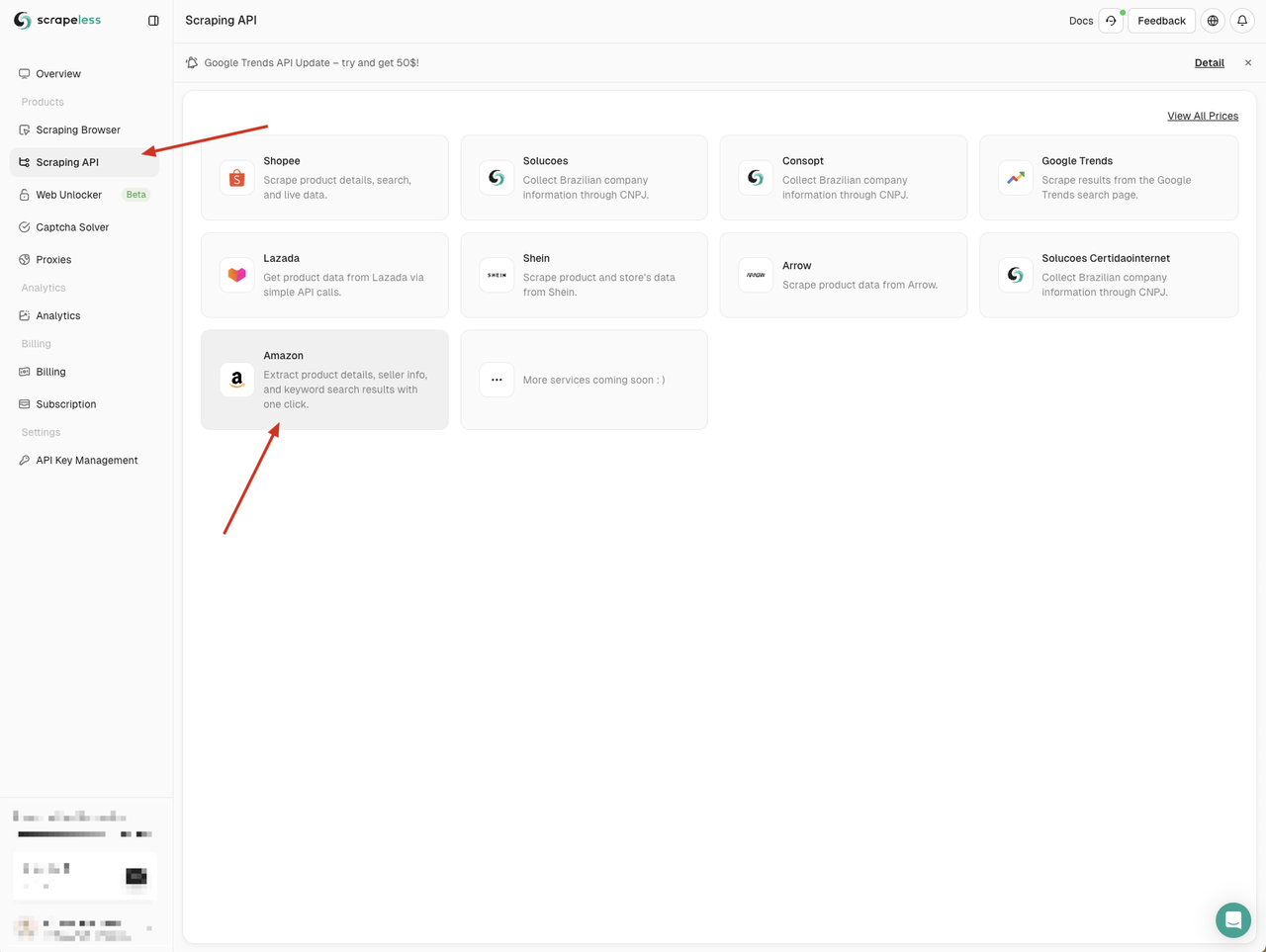
我们需要转到Scrapeless仪表板,单击左侧的“抓取API”菜单,然后选择要使用的服务。
在这里我们可以使用“Amazon”服务
进入Amazon API页面,我们可以看到Scrapeless为我们提供了三种语言的默认参数和代码示例:
- Python
- Go
- Node.js
这里我们选择Node.js并将代码示例复制到我们的项目中:
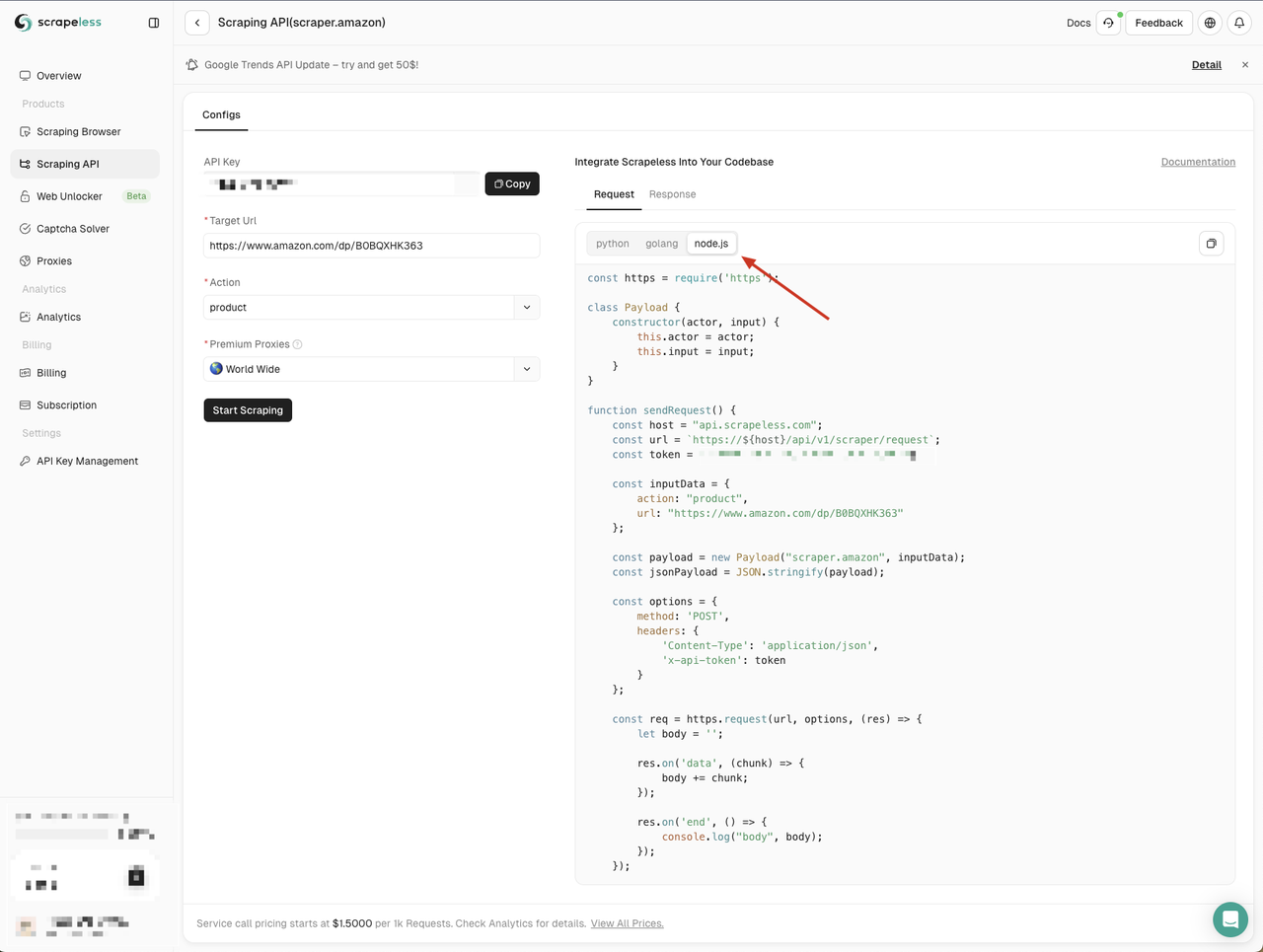
Scrapeless的Node.js代码示例默认使用http模块。我们可以使用node-fetch模块替换http模块,以便我们可以使用Fetch API发送网络请求。
首先,在我们的项目中创建一个scraping-api-amazon.js文件,然后将Scrapeless提供的代码示例替换为以下代码示例:
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input) {
this.actor = actor;
this.input = input;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/scraper/request`;
const token = ''; // Your API token
const inputData = {
action: 'product',
url: 'https://www.amazon.com/dp/B0BQXHK363',
};
const payload = new Payload('scraper.amazon', inputData);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP Error: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();通过执行以下命令运行代码:
Bash
node scraping-api-amazon.js 我们将看到Scrapeless API返回的结果。在这里我们只是简单地打印出来。您可以根据需要处理返回的结果。
步骤2. 利用Web解锁器绕过常见的反抓取措施
Scrapeless提供了一种Web解锁器服务,可以帮助您绕过常见的反抓取措施,例如CAPTCHA绕过、IP阻止等。Web解锁器服务可以帮助您解决一些常见的爬取问题,使您的爬取任务更顺畅。
为了验证Web解锁器服务的有效性,我们可以首先使用curl命令访问需要CAPTCHA的网站,然后使用Scrapeless Web解锁器服务访问同一个网站,看看是否可以成功绕过CAPTCHA。
- 使用curl命令访问需要验证码的网站,例如
https://identity.getpostman.com/login:
Bash
curl https://identity.getpostman.com/login通过查看返回的结果,我们可以看到这个网站连接了Cloudflare验证机制,我们需要输入验证码才能继续访问网站。

- 我们使用Scrapeless Web解锁器服务访问同一个网站:
- 前往Scrapeless仪表板
- 单击左侧的Web解锁器菜单
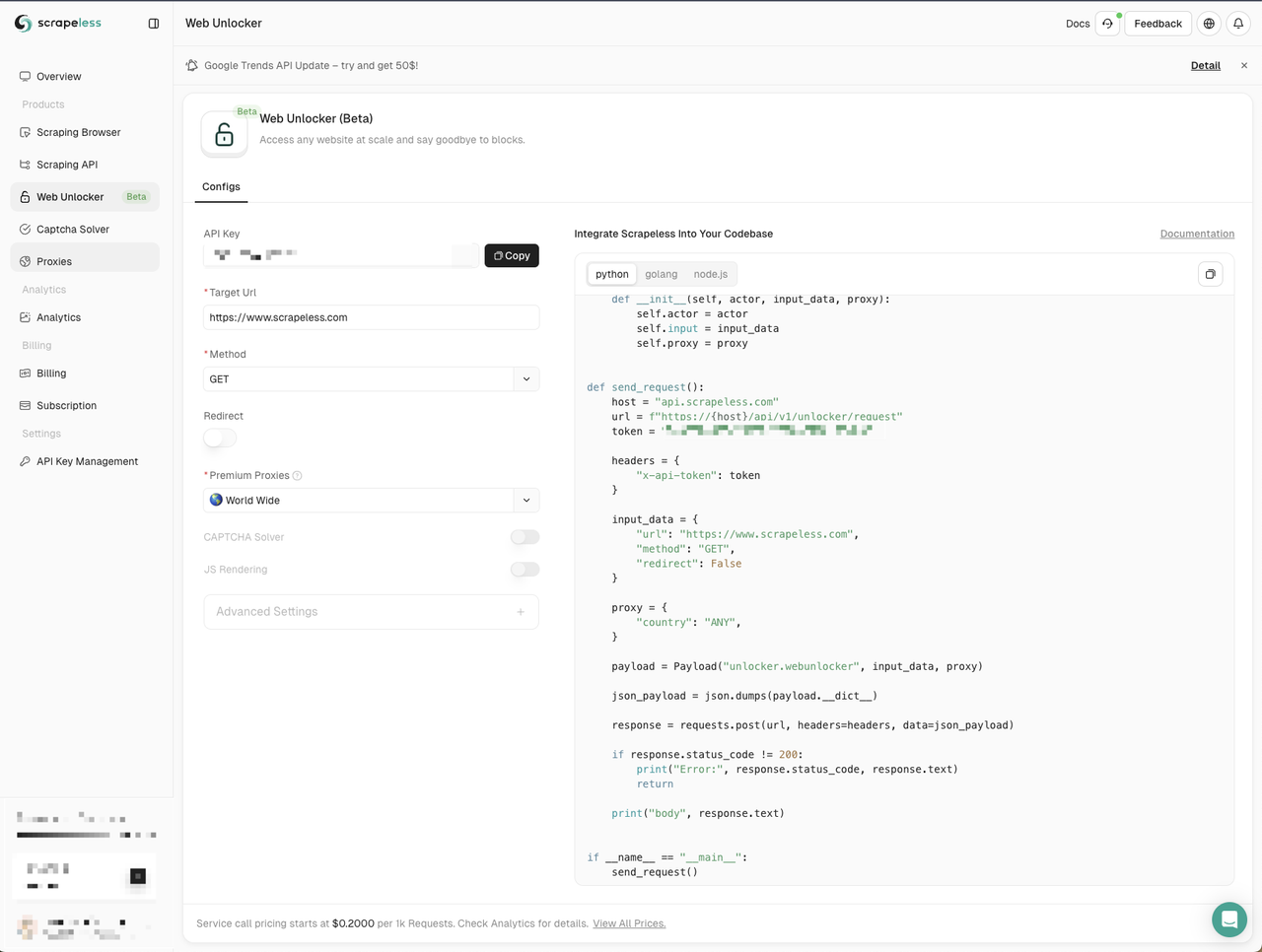
- 将Node.js代码示例复制到我们的项目中
在这里我们创建一个新的web-unlocker.js文件。我们仍然需要使用node-fetch模块发送网络请求,因此我们需要将Scrapeless提供的代码示例中的http模块替换为node-fetch模块:
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input, proxy) {
this.actor = actor;
this.input = input;
this.proxy = proxy;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/unlocker/request`;
const token = ''; // Your API token
const inputData = {
url: 'https://identity.getpostman.com/login',
method: 'GET',
redirect: false,
};
const proxy = {
country: 'ANY',
};
const payload = new Payload('unlocker.webunlocker', inputData, proxy);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();执行以下命令运行脚本:
JavaScript
web-unlocker.js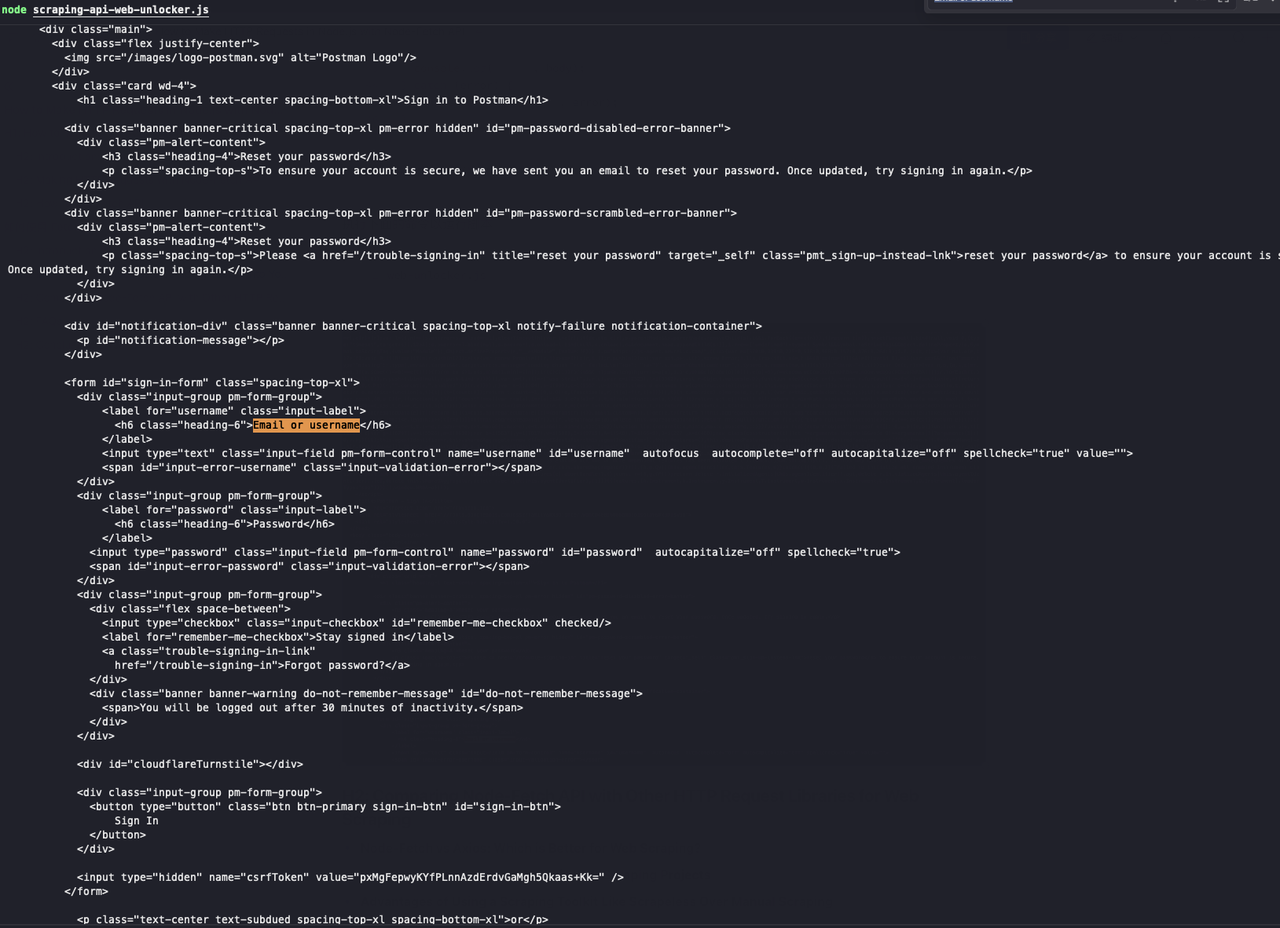
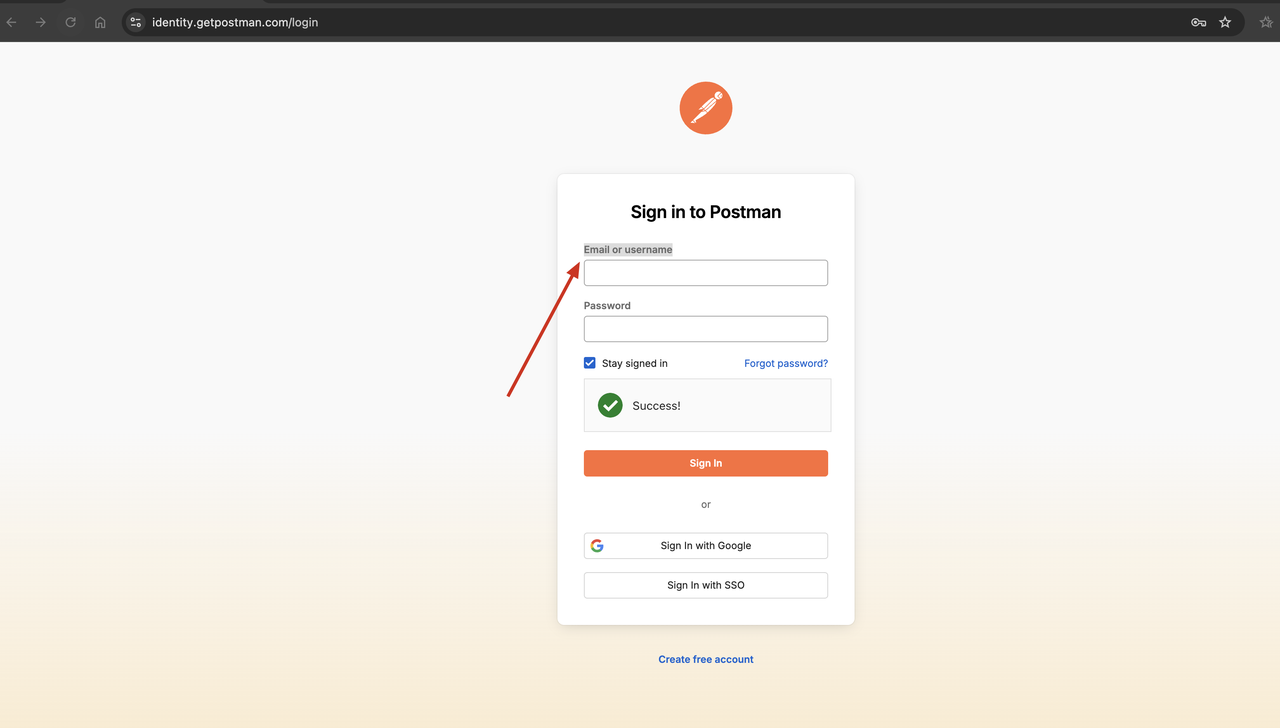
看!Scrapeless Web解锁器成功绕过了验证码,我们可以看到返回的结果包含了我们需要的网页内容。
常见问题
Q1. Node-Fetch vs Axios:哪个更适合网络抓取?
为了让您的选择更容易,Axios和Fetch API有以下区别:
- Fetch API使用请求的body属性,而Axios使用data属性。
- 使用Axios,您可以直接发送JSON数据,而Fetch API需要转换为字符串。
- Axios可以直接处理JSON。Fetch API需要先调用response.json()方法才能获得JSON格式的响应。
- 对于Axios,响应数据变量名必须是data;对于Fetch API,响应数据变量名可以是任何名称。
- Axios允许使用进度事件轻松监控和更新进度。Fetch API中没有直接的方法。
- Fetch API不支持拦截器,而Axios支持。
- Fetch API允许流式响应,而Axios不支持。
Q2. node fetch稳定吗?
Node.js v21最显著的特性是Fetch API的稳定化。
Q3. Fetch API比AJAX更好吗?
对于新项目,建议使用Fetch API,因为它具有现代化的特性和简单性。但是,如果您需要支持非常旧的浏览器或维护遗留代码,则可能仍然需要Ajax。
总结
在Node.js中添加Fetch API是一个期待已久的功能。在Node.js中使用Fetch API可以确保您的抓取工作轻松完成。但是,使用Node Fetch API时不可避免地会遇到严重的网络封锁。
想要完全解决IP封禁和CAPTCHA问题?请务必使用Scrapeless轻松绕过网站监控和IP阻止。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


