
8个免费的免代码网页抓取工具 | 2025最佳选择
Senior Web Scraping Engineer
无代码爬虫是什么?
无代码网页抓取工具,也称为托管式抓取,是一种网页抓取方法,它帮助您从网站提取数据,而无需构建或维护代码基础设施。这些工具通常使用可视化界面或简化的工作流程构建,使用户可以轻松设置和执行网页抓取任务。
无代码抓取的核心优势之一是它大大减少了从网络收集数据所需的时间和精力。您可以上传目标URL,使用针对热门网站或常见用例的预构建抓取模板,并几乎立即获取数据。
这些工具无需手动编码和基础设施管理,使您可以更专注于分析和从提取的数据中获得有价值的见解。
可扩展性是无代码抓取工具带来的另一个好处。例如,使用Scrapeless的API服务,您可以使用cron作业或自定义间隔来安排抓取任务,以实现更大的自动化和可扩展性。
如果您想持续监控您的竞争对手,这一点尤其有用。是的,他们每天都可能更改价格和列表关键字,因此您应该跟上这些发展以保持竞争力。
为什么我们应该选择无代码爬虫?
- 可视化界面: 无代码网页抓取工具通常提供拖放界面或点击式功能,用户可以在其中选择要抓取的网站元素,而无需了解如何编写代码。
- 预配置模板: 许多无代码网页抓取器都带有针对常见网页抓取任务的预构建模板,使入门更加容易。
- 自动化: 这些工具通常会自动化重复性的抓取任务,因此用户可以安排或触发抓取作业,而无需每次都手动干预。
- 兼容性: 无代码网页抓取器可以通过利用内置浏览器或云环境来呈现页面,来处理静态和动态网站的数据,包括使用JavaScript的那些网站。
- 数据导出: 它们允许用户以各种格式导出抓取的数据,例如CSV、Excel甚至API集成,使数据易于访问以进行分析或用于其他系统。
- 无需编程知识: 主要好处是用户可以构建复杂的抓取工作流程,而无需学习Python、JavaScript或其他编程语言。
无代码爬虫的核心评估标准
- 易用性: 操作是否直观和简单?对我来说,选择易于上手的工具是重中之重。如果工具过于复杂或操作繁琐,无论其功能多么强大,我都会感到不知所措。好的无代码网页抓取工具至少应该具有简洁的用户界面和清晰的操作步骤。
- 数据抓取能力: 它能否抓取复杂的动态网页?无代码网页抓取器的最重要的功能是其准确快速地抓取网络数据的能力。特别是,它能否处理动态网站和JavaScript渲染的页面?毕竟,现在许多网站都通过JavaScript加载内容,普通的工具往往无法处理。
- 反检测能力: 它能否绕过网站的反抓取机制?当我使用无代码网页抓取器进行抓取时,许多网站都采取了反抓取措施(例如IP限制、验证码等)。这经常导致在使用某些工具时被阻止或面临验证码挑战。
- API和自动化: 它是否支持集成和自动化任务?作为一个经常需要重复抓取数据的人,我希望我的工具支持API,这样我就可以自动化抓取任务,甚至将它们集成到我现有的业务流程中。
- 定价和成本效益: 该工具的成本是否合理?我通常选择那些物有所值的工具。虽然免费工具很好,但它们的功能和限制往往不能满足我的需求。如果付费版本功能丰富且价格合理,那将是一项非常值得的投资。
排名:8款最佳无代码爬虫工具分析
以下是我们为您精心挑选的8款最佳无代码网页抓取工具。它们具有不同的功能,您需要选择适合您实际需求的产品。
概述比较
| 主要功能 | 付费计划 | 免费试用 | 易用性 | |
|---|---|---|---|---|
| Scrapeless | 综合性、稳定性高、成功率高 | 从$49起 | 所有服务均可享受一个月免费试用 | ⭐⭐⭐⭐⭐ |
| ParseHub | 适用于非技术用户 | 从$189起 | 价值$99 | ⭐⭐⭐⭐⭐ |
| Diffbot | AI网页结构解析 | 从$299起 | 长期试用,功能有限 | ⭐⭐⭐⭐ |
| Outscraper | 用于谷歌搜索类别数据 | 根据您的需求 | 前500次操作免费 | ⭐⭐⭐⭐ |
| WebHarvy | 非常适合小型数据收集任务 | 从$129起 | 不支持 | ⭐⭐⭐⭐ |
| DataMiner | 抓取结构化数据,如表格和列表 | 从$19.99起 | 免费计划每月提供500页 | ⭐⭐⭐ |
| Simplescraper | 适用于小型项目 | 从$39起 | 100个免费入门积分 | ⭐⭐⭐ |
| Browse AI | 非常适合竞争分析和价格跟踪 | 从$19起 | 50个积分 | ⭐⭐⭐ |
#1 Scrapeless – 一个全面且稳定的无代码网页抓取器
Scrapeless是一个基于云的网页抓取工具,由Browserless技术提供支持,旨在为用户提供稳定的抓取环境。它支持通过智能代理绕过IP限制,使其特别适用于电子商务、新闻和SEO数据提取。
对于没有编程技能或不想花费太多时间进行编码的用户,Scrapeless提供了一个简单的API接口,可以快速集成到内部业务系统中以自动化数据抓取任务。Scrapeless的API通过其强大的开发能力完全支持JavaScript渲染。只需点击几下并进行简单的配置,用户就可以完成通常需要复杂抓取器设置才能完成的工作。
Scrapeless还将推出AI Agent服务。总的来说,它非常适合需要长期、大规模数据抓取的用户,特别是由于其与传统无代码抓取器相比具有更好的反检测能力。
如何部署Scrapeless?以下是清晰的步骤:
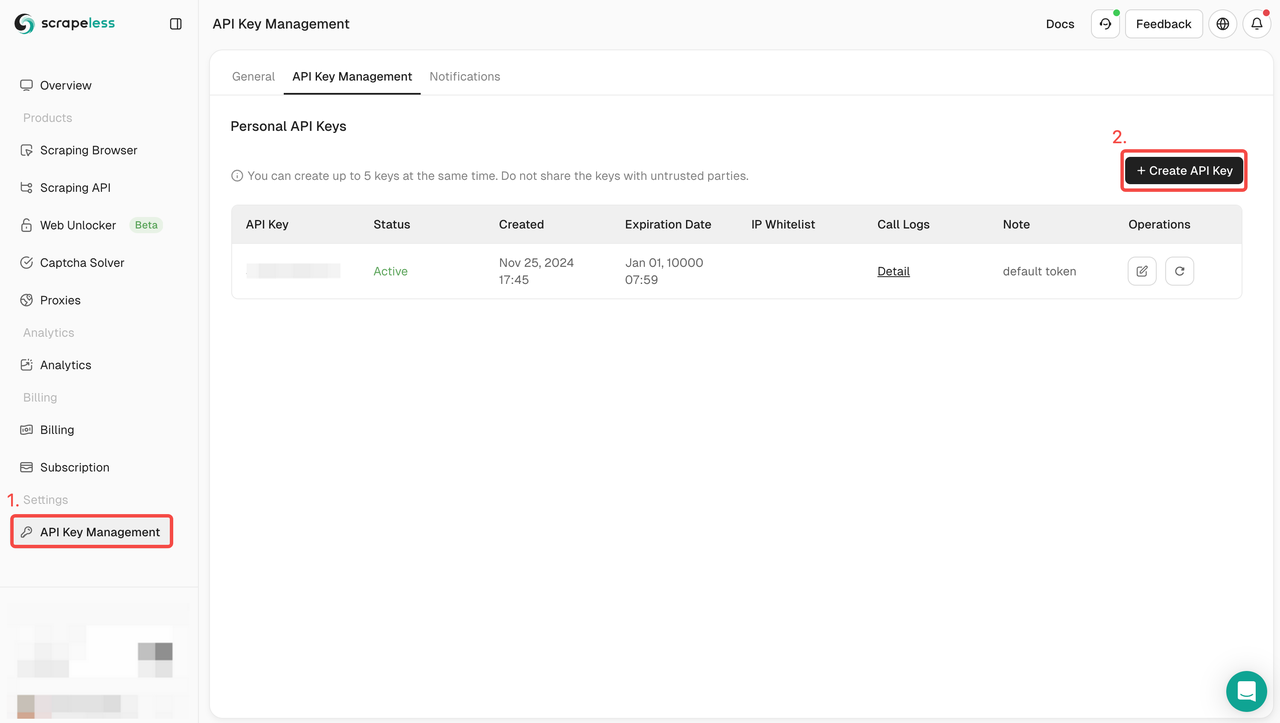
步骤1. 获取您的API密钥
要开始使用,您需要从Scrapeless仪表盘获取您的API密钥:
- 登录到Scrapeless仪表盘。
- 导航到API密钥管理。
- 点击创建以生成您的唯一API密钥。
- 创建后,只需点击API密钥即可复制它。
步骤2:在代码中使用您的API密钥
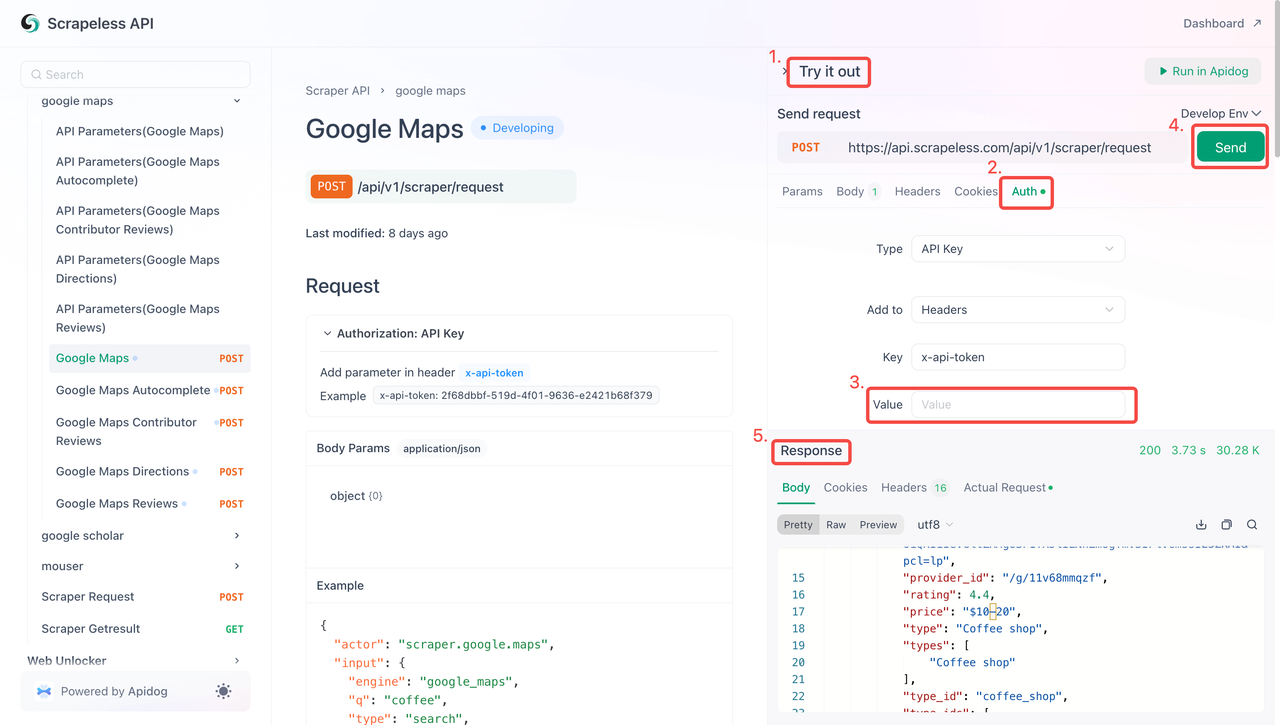
您现在可以使用您的API密钥将Scrapeless集成到您的项目中。请按照以下步骤测试和实现API:
- 访问API文档。
- 点击所需端点的“试用”。
- 在“Auth”字段中输入您的API密钥。
- 点击“发送”以获取抓取响应。
以下是一个您可以直接集成到您的Google Maps抓取器的示例代码片段:
Python
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.maps",
"input": {
"engine": "google_maps",
"q": "coffee",
"type": "search",
"ll": "@40.7455096,-74.0083012,14z",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))JavaScript
JavaScript
var myHeaders = new Headers();
myHeaders.append("Content-Type", "application/json");
var raw = JSON.stringify({
"actor": "scraper.google.maps",
"input": {
"engine": "google_maps",
"q": "coffee",
"type": "search",
"ll": "@40.7455096,-74.0083012,14z",
"hl": "en",
"gl": "us"
}
});
var requestOptions = {
method: 'POST',
headers: myHeaders,
body: raw,
redirect: 'follow'
};
fetch("https://api.scrapeless.com/api/v1/scraper/request", requestOptions)
.then(response => response.text())
.then(result => console.log(result))
.catch(error => console.log('error', error));#2 ParseHub – 用于复杂网站的可视化抓取工具
- 主要功能:
✅ 可视化界面,适用于非技术用户
✅ 网页抓取调度
ParseHub提供强大的可视化数据收集功能,使其成为没有编程经验的用户的一个绝佳选择。它还支持处理JavaScript渲染的网站。但是,免费版本的功能有限,使其对想要尝试网页抓取而无需完全投入的网络数据爱好者特别有吸引力。
#3 Diffbot – AI网页结构解析,非常适合新闻和文章抓取
- 主要功能:
✅ AI内容识别,无需手动设置规则
✅ 适用于非结构化数据,例如文章、评论等
Diffbot是一款使用AI技术解析网页结构的工具,使其特别适用于从非结构化内容(如新闻网站和博客)中提取数据。借助其强大的AI模型,用户可以轻松提取所需信息,而无需手动设置抓取规则。
#4 Outscraper – 非常适合谷歌搜索和地图数据抓取
- 主要功能:
✅ 专门为谷歌数据设计,抓取性能出色
✅ 提供API支持,用于自动化数据收集
✅ 可以从谷歌地图和搜索结果中提取数据
Outscraper专注于抓取与谷歌相关的的数据,例如谷歌地图和谷歌搜索结果,使其非常适合本地商业数据分析。通过其API,用户可以快速集成和自动化他们的数据收集任务。
#5 WebHarvy – Windows桌面网页抓取工具
- 主要功能:
✅ 用户友好的界面,非常适合小型数据抓取任务
✅ 购买后终身使用
WebHarvy是一个基于Windows桌面的可视化抓取器,非常适合小型数据收集任务。其用户友好的界面专为非技术用户设计,允许他们通过图形界面轻松设置抓取规则。
#6 DataMiner – 用于小型爬虫的轻量级Chrome扩展程序
- 主要功能:
✅ 安装后即可使用,门槛低
✅ 适用于抓取结构化数据,如表格和列表
DataMiner是一个轻量级的Chrome扩展程序,适用于小型数据抓取任务。它易于安装和使用,非常适合提取结构化数据,如表格和列表。
#7 Simplescraper – 支持API的轻量级抓取工具
- 主要功能:
✅ 快速访问API,支持自动化抓取
✅ 易于使用,适用于非技术用户
✅ 非常适合具有稳定API性能的小型项目
Simplescraper提供了一个用户友好的API,非常适合中小型项目的用户,能够快速进行网页数据抓取和自动化处理。它非常适合希望将抓取工作流程集成到现有系统中的开发人员。
#8 Browse AI – 专为监控网站变化而设计
- 主要功能:
✅ 自动跟踪网络数据变化
✅ 非常适合竞争分析和价格跟踪
✅ 具有可视化设置界面
Browse AI专门监控网站数据的变化,使其适合价格跟踪和市场监控等定期任务。它可以自动监控指定网页上的更新,满足竞争分析和SEO数据监控的需求。
结论
无代码网页抓取器弥合了数据收集和非技术团队之间的差距,但也使技术团队能够受益,因为它们允许他们快速收集数据,而无需从头开始开发复杂的基础设施。
处理公共网络数据收集可能是一项棘手的任务。但是,借助上述8款优秀的无代码网页抓取工具,非程序员现在可以轻松利用网页抓取。剩下的就是选择满足您项目需求的工具。
想要了解有关网站抓取和自动化工具的更多信息?阅读更多有效的解决方案!
常见问题
1. 使用无代码抓取器合法吗?
通常情况下,抓取公开可用的数据是合法的。但是,抓取个人数据、知识产权或登录后的数据可能会引发法律问题。
2. 无代码抓取器是如何工作的?
无代码抓取器提供用户友好的界面,允许用户在不编写代码的情况下从网站提取数据。用户可以选择网页上的元素来定义要提取的数据。然后,该工具会自动执行导航网站、提取指定数据并将其导出为CSV或JSON等结构化格式的过程。
3. 我可以使用无代码抓取器从任何网站抓取数据吗?
虽然无代码抓取器可以用于许多网站,但务必确保您的抓取活动符合网站的服务条款和适用的法律。
4. 无代码抓取器获得的数据可靠吗?
是的。以Scrapeless为例,Scrapeless保证99%的成功率和可靠性。谷歌趋势抓取的稳定性和准确性已达到近100%!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


