返回博客

使用 Scrapeless 和 n8n 工作流自动化房地产挂牌数据抓取
Emily Chen
Advanced Data Extraction Specialist
11-Jul-2025
在房地产行业,自动化抓取最新房产 listings 并将其以结构化格式存储以便分析是提高效率的关键。本文将提供关于如何使用低代码自动化平台 n8n,以及网页抓取服务 Scrapeless,定期从 LoopNet 房地产网站抓取租赁 listings 并自动将结构化的房产数据写入 Google Sheets,以便轻松分析和共享的逐步指南。
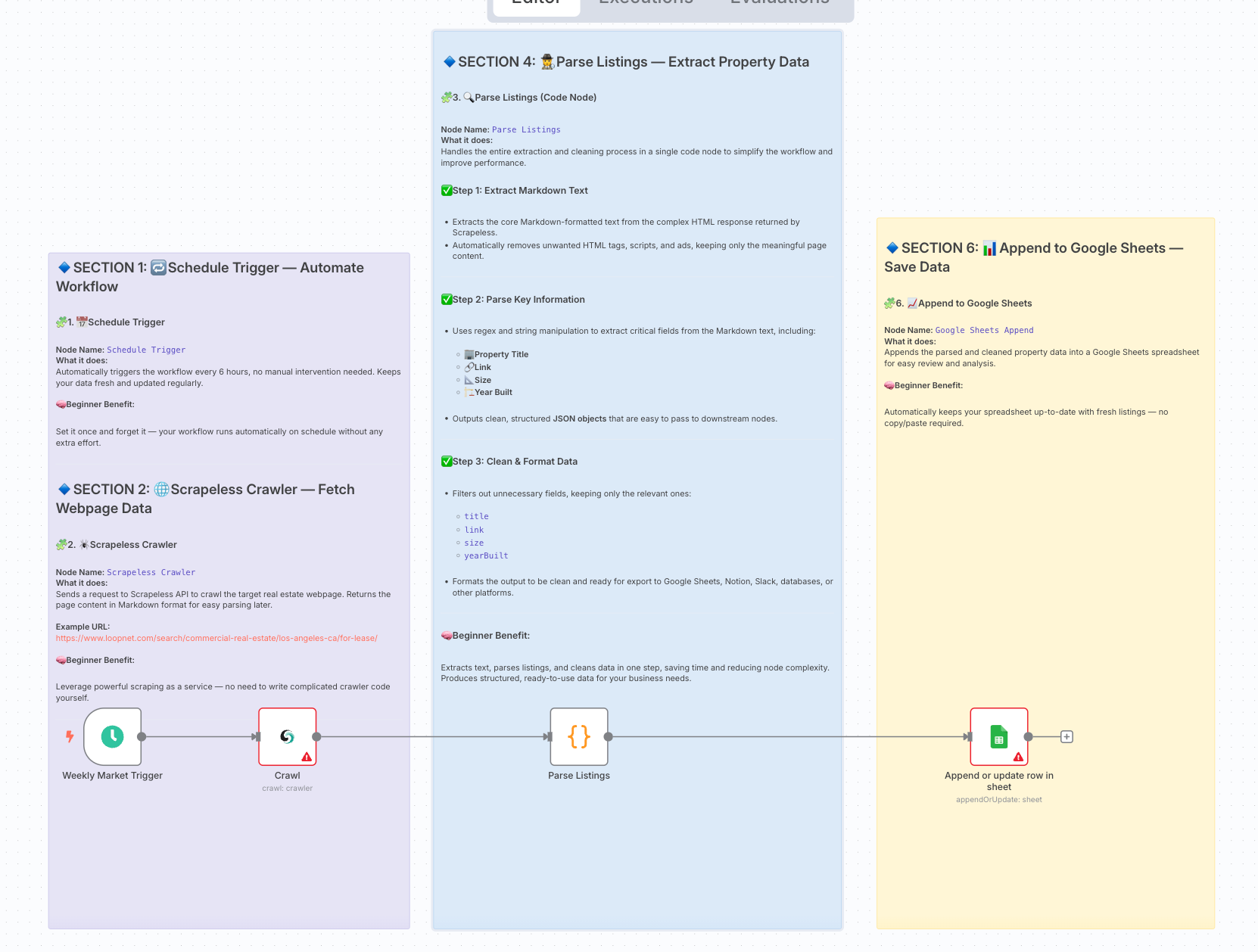
1. 工作流程目标和架构
目标:在每周计划中自动获取来自商业房地产平台(例如,Crexi / LoopNet)的最新待售/待出租 listings。
绕过反抓取机制,并将数据以结构化格式存储在 Google Sheets 中,以便于报告和 BI 可视化。
最终工作流程架构:
2. 准备
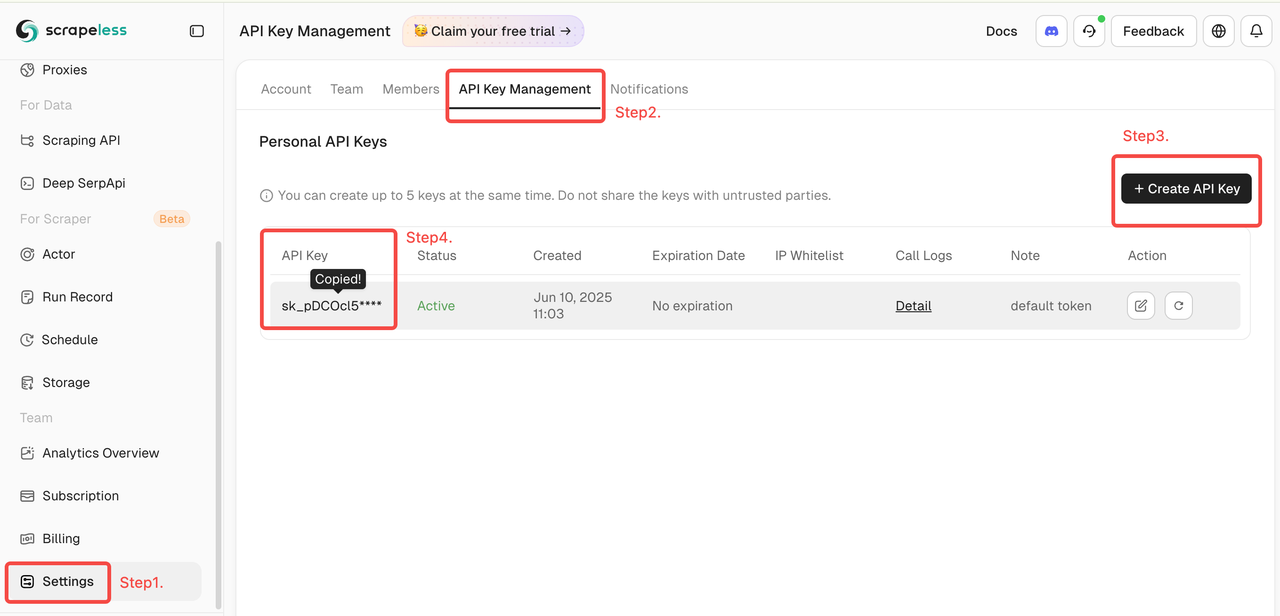
- 在 Scrapeless 官方网站注册账号并获取 API 密钥(每月 2000 次免费请求)。
- 登录到 Scrapeless 控制面板
- 然后在左侧点击“设置” -> 选择“API 密钥管理” -> 点击“创建 API 密钥”。最后,单击您创建的 API 密钥以复制它。
- 确保您已在 n8n 中安装了 Scrapeless 节点的社区版本
- 一个具有可写权限的 Google Sheets 文档和相应的 API 凭证。
3. 工作流程步骤概述
| 步骤 | 节点类型 | 目的 |
|---|---|---|
| 1 | 计划触发器 | 每 6 小时自动触发工作流程。 |
| 2 | Scrapeless 爬虫 | 抓取 LoopNet 页面并以 markdown 格式返回抓取的内容。 |
| 4 | 代码节点(解析 Listings) | 从 Scrapeless 输出中提取 markdown 字段;使用正则表达式解析 markdown 并提取结构化的房产 listing 数据。 |
| 6 | Google Sheets 附加 | 将结构化的房产数据写入 Google Sheets 文档。 |
4. 详细配置和代码说明
1. 计划触发器
- 节点类型: 计划触发器
- 配置: 将间隔设置为每周(或根据需要调整)。
- 目的: 按计划自动触发抓取工作流程,无需人工操作。
2. Scrapeless 爬虫节点
- 节点类型: Scrapeless API 节点(
crawler - crawl) - 配置:
- URL: 目标 LoopNet 页面,例如
https://www.loopnet.com/search/commercial-real-estate/los-angeles-ca/for-lease/ - API 密钥: 输入您的 Scrapeless API 密钥。
- 限制页面: 2(根据需要调整)。
- URL: 目标 LoopNet 页面,例如
- 目的: 自动抓取页面内容并以 markdown 格式输出网页。

3. 解析 Listings
- 目的: 从 Scrapeless 抓取的 markdown 格式网页内容中提取关键商业房地产数据,并生成结构化数据列表。
- 代码:
const markdownData = [];
$input.all().forEach((item) => {
item.json.forEach((c) => {
markdownData.push(c.markdown);
});
});
const results = [];
function dataExtact(md) {
const re = /\[更多详情为 ([^\]]+)\]\((https:\/\/www\.loopnet\.com\/Listing\/[^\)]+)\)/g;
let match;
while ((match = re.exec(md))) {
const title = match[1].trim();
const link = match[2].trim()?.split(' ')[0];
// 提取匹配位置周围的上下文片段
const context = md.slice(match.index, match.index + 500);
// 提取大小范围,例如 “10,000 - 20,000 SF”
const sizeMatch = context.match(/([\d,]+)\s*-\s*([\d,]+)\s*SF/);
const sizeRange = sizeMatch ? `${sizeMatch[1]} - ${sizeMatch[2]} SF` : null;
// 提取建造年份,例如 “建于 1988”
const yearMatch = context.match(/建于\s*(\d{4})/i);
const yearBuilt = yearMatch ? yearMatch[1] : null;
// 提取图像 URL
javascript
const imageMatch = context.match(/!\[[^\]]*\]\((https:\/\/images1\.loopnet\.com[^\)]+)\)/);
const image = imageMatch ? imageMatch[1] : null;
results.push({
json: {
title,
link,
size: sizeRange,
yearBuilt,
image,
},
});
// 如果没有找到匹配项,则返回原始的markdown(用于调试)
if (results.length === 0) {
return [
{
json: {
error: '没有匹配的列表',
raw: md,
},
},
];
}
}
markdownData.forEach((item) => {
dataExtact(item);
});
return results;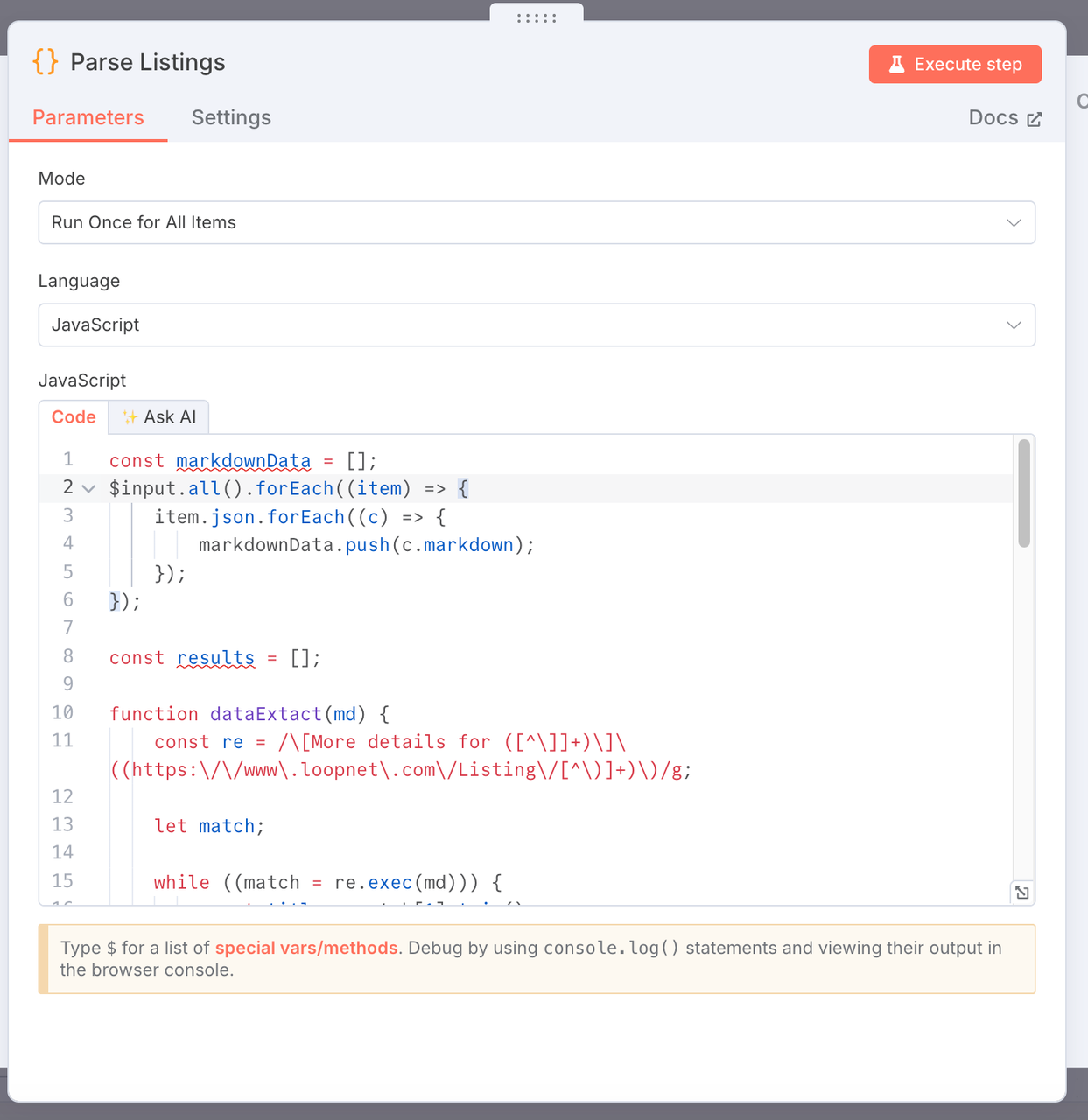
4. Google 表格追加(Google 表格节点)
- 操作: 追加
- 配置:
- 选择目标 Google 表格文件。
- 工作表名称: 例如,
房地产市场报告。 - 列映射配置: 将结构化的房产数据字段映射到工作表中的对应列。
| Google 表格列 | 映射的 JSON 字段 |
|---|---|
| 标题 | {{ $json.title }} |
| 链接 | {{ $json.link }} |
| 面积 | {{ $json.size }} |
| 建造年份 | {{ $json.yearBuilt }} |
| 图片 | {{ $json.image }} |
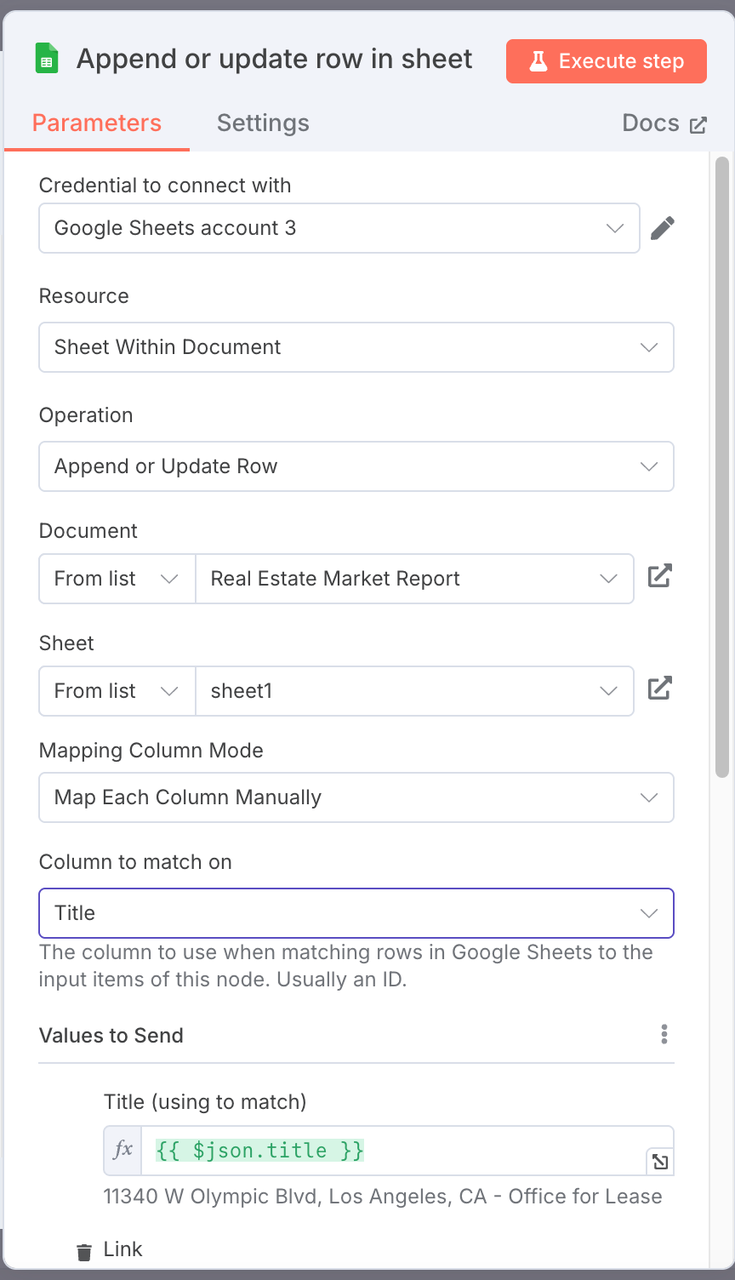
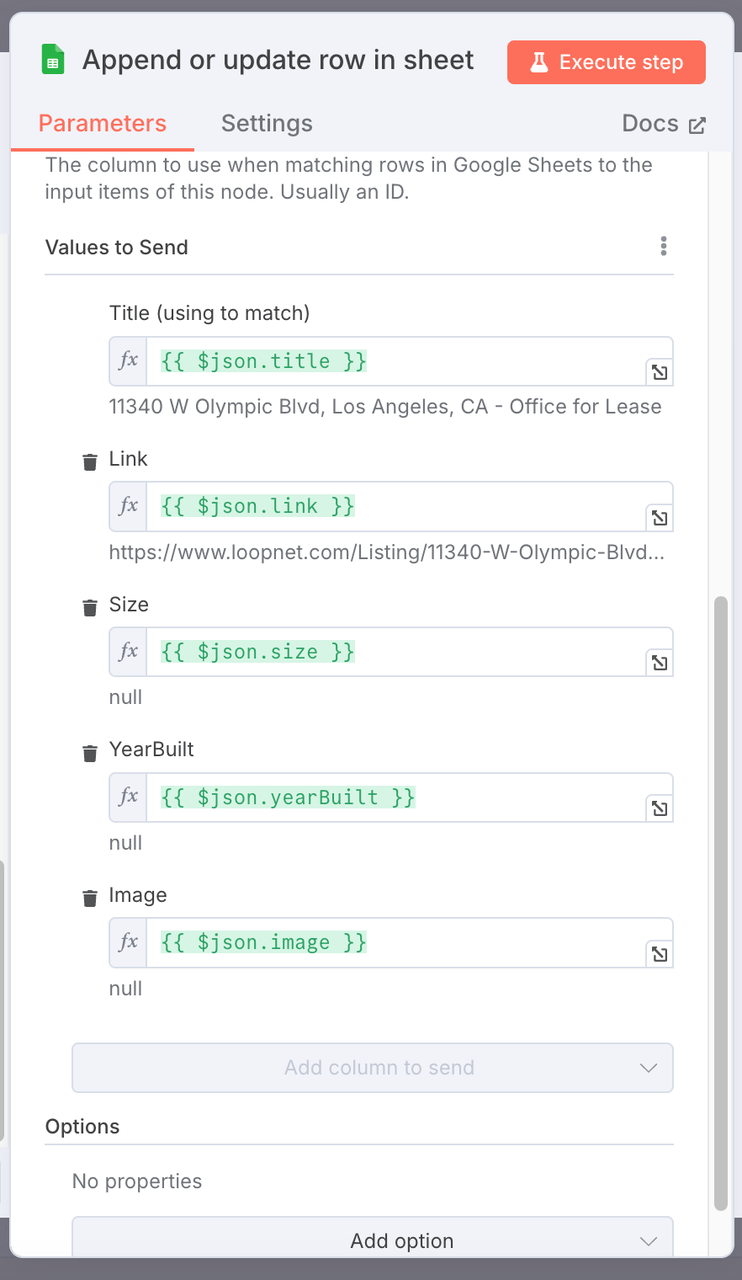
注意:
建议您的工作表名称应与我们的名称保持一致。如果需要修改特定名称,则需要注意映射关系。
5. 结果输出
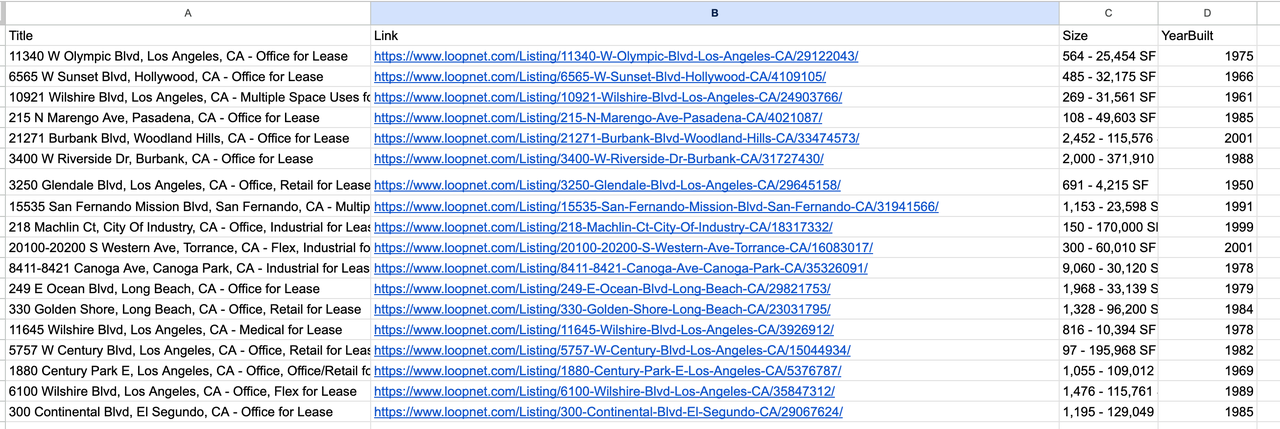
5. 工作流程流程图

6. 调试建议
- 在运行每个 代码 节点时,打开节点输出以检查提取的数据格式。
- 如果 解析列表 节点没有返回数据,请检查 Scrapeless 输出是否包含有效的 markdown 内容。
- 格式输出 节点主要用于清理和规范输出,以确保正确的字段映射。
- 连接 Google 表格追加 节点时,请确保您的 OAuth 授权已正确配置。
7. 未来优化
- 去重: 避免写入重复的房产列表。
- 按价格或面积过滤: 添加过滤器以定位特定的列表。
- 新列表通知: 通过电子邮件、Slack 等发送警报。
- 多城市和多页面自动化: 针对不同城市和页面自动化抓取。
- 数据可视化和报告: 构建仪表板并生成结构化数据的报告。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。
最受欢迎的文章



目录