网页爬取时绕过 CAPTCHA 的 7 种方法
Web Data Collection Specialist
您是否曾在抓取网站数据的时候被 CAPTCHA 所阻拦?事实上任何网络数据抓取工作都可能受到 CAPTCHA 的阻碍,而它们也变得越来越难以解决。
值得庆幸的是,有一些技巧可以在抓取网页时绕过 CAPTCHA,我们将在本文中介绍 7 种行之有效的方法。
CAPTCHA:它是什么?
CAPTCHA 全称是“完全自动化的公共图灵测试,用于区分计算机和人类”。为了保护网站免受可能的损害和类似机器人的行为(如网页抓取),CAPTCHA 会阻止自动化程序对网站的访问。因此在进入受保护的网站之前,用户通常要完成 CAPTCHA 所提供的测试。
Web 抓取工具很难绕过 CAPTCHA,因为机器人很难理解它们,但人类却很容易克服。例如,当需要通过勾选下图中的框来验证其人类身份时,机器人往往无法直观地执行此命令。
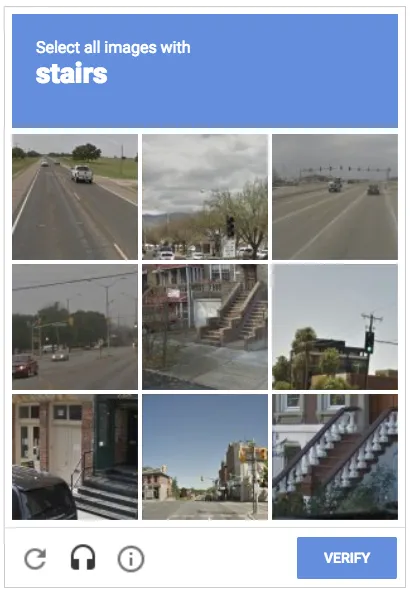
Web 抓取如何被 CAPTCHA 阻止?
网站开发者的不同应对策略决定了 CAPTCHA 的不同形式。有些 CAPTCHA 在您访问网站时始终存在于页面,但大多数情况下只针对 Web 抓取等自动化操作弹出 CAPTCHA。
网页抓取过程中出现 CAPTCHA 的原因一般有这些:
- 在短时间内从同一 IP 发送多个查询
- 重复的自动操作,例如单击同一链接或访问同一页面
- 可疑的自动交互,包括快速浏览大量页面而不进行交互、快速点击或快速填写表格
- 使用禁止的网站并忽略 robots.txt 文件。
是否可以绕过 CAPTCHA?
虽然这不是一个简单的操作,但我们也可以使用技巧绕过 CAPTCHA。如果 CAPTCHA 被阻止,建议尝试重新提交请求并避免它首先出现。
您也可以选择直接解答 CAPTCHA 提供的题目,但这样做成本很高,成功率也会低得多。很多 CAPTCHA 解决服务都使用人工解决程序来处理查询,然后提供答案。这种方法会大大降低抓取工具的效率并减慢其速度。
绕过 CAPTCHA 更可靠,因为它采取了所有必要的预防措施来阻止导致 CAPTCHA 的自动行为。我们将在下面介绍在网页抓取时绕过 CAPTCHA 的最佳方法,以便您可以检索所需的信息。
如何在网页抓取时绕过 CAPTCHA
本节将介绍在 Python 中进行网页抓取时绕过烦人的 CAPTCHA 的七种方法。
方法 1. 轮换 IP
在开发用于 URL 和数据提取的爬虫时,防御系统阻止访问的最简单技术是禁用 IP。如果服务器在短时间内从同一 IP 地址收到大量请求,他们会标记该地址。
为了避免这种情况,使用多个 IP 地址是最简单的解决方案。但是,当涉及到服务器时,很难(甚至不可能)对其进行修改。因此,您必须使用代理服务器来处理您的请求以循环 IP。有了它们,您的初始请求将不会被更改,但目标服务器将看到他们的 IP 地址而不是您的 IP 地址。
方法 2. 轮换用户代理
用户的 Web 浏览器发送到服务器的字符串称为用户代理 (UA)。它位于 HTTP 标头中,提供有关操作系统以及浏览器类型和版本的信息。使用客户端的导航器和 JavaScript 访问。远程 Web 服务器使用 userAgent 属性以符合用户规范的方式识别和呈现内容。
尽管它们包含各种结构和数据,但大多数 Web 浏览器通常遵循相同的格式:
(<system-information>) Mozilla/5.0 <extensions> <platform> (<platform-details>)
例如,对于 Chrome (Chromium),用户代理字符串可以是 Mozilla/5.0 (Windows NT 10.0; Win64; x64)。 AppleWebKit/537.36(类似于 KHTML 中的 Gecko)109.0.0.0 Safari/537.36;Chrome。具体来说,它说明了浏览器的名称(Chrome)、运行的版本(109.0.0.0)以及运行的操作系统(Windows NT 10.0,64 位 CPU)。
使用 UA 字符串进行抓取可以帮助将您的蜘蛛伪装成 Web 浏览器,因为它们可以帮助 Web 服务器识别来自浏览器(和机器人)的请求类型。
请注意:如果您使用不正确的用户代理,您的数据提取脚本将被停止。
方法 3. 使用 CAPTCHA 解码器
被称为 CAPTCHA 解码器的服务可以帮助您通过自动解决 CAPTCHA 来连续抓取网页,Scrapeless 便是众多解码器中的代表之一.
厌倦了不断被CAPTCHA阻碍你的网页抓取工作?
向您强烈推荐 Scrapeless - 性能强大的一体化网页抓取解决方案。
Scrapeless:目前最好的一体化在线抓取解决方案!
借助我们强大的工具套件,可以轻松发挥数据抓取的全部潜力:
最佳 CAPTCHA 解码器
自动解决复杂的 CAPTCHA 问题,确保持续而丝滑地抓取网页数据。
免费试用开启中!
方法 4. 避免隐藏的陷阱
您不知道的是,网站使用狡猾的陷阱来识别机器人。例如,蜜罐陷阱会欺骗机器与隐藏的功能(例如链接或不可见的表单字段)进行交互。
人类用户看不到这些陷阱;只有机器人才能看到它们。当用户与这些陷阱交互时,网站可以识别异常活动并警告机器人的 IP 地址。
但是,您可以学习如何识别和操作这些陷阱。一种方法是在网站的 HTML 中查找隐藏元素,并避开名称或值奇怪的元素。
方法 5. 模拟人类行为
准确复制人类行为对于在网页抓取时绕过 CAPTCHA 是必要的。例如,在几毫秒内提交多个请求可能会导致 IP 限制和速率限制。
在请求之间增加时间以降低查询频率是模仿人类行为的一种方法。为了使其更合乎逻辑,您可以改变时间安排。使用指数退避是延长每次请求失败后等待时间的另一种策略。
方法 6. 保存 Cookie
您在网页抓取时选择的隐藏武器可能是 Cookie。这些小文件包含有关您如何与网站交互的信息,例如您的偏好和登录状态。
如果您在登录后抓取,Cookie 会很有用,因为它们省去了您反复登录的麻烦,并降低了被发现的可能性。此外,cookie 允许您稍后暂停或继续网络抓取会话。
利用无头浏览器(如 Selenium)和 HTTP 客户端(如 Requests),您可以以编程方式保存和加载 cookie 并检索数据,而不会被注意到。
方法 7. 隐藏自动化标头
即使使用无头浏览器,您也应该小心谨慎,因为网站可以通过扫描自动化的迹象(如浏览器指纹)来检测自动流量。
另一方面,诸如 Selenium Stealth 之类的插件可用于自动执行类似于人的动作的鼠标和键盘动作,而不会引起您的注意。
总结
虽然防止 CAPTCHA 阻碍网络抓取是一项艰巨的任务,但您现在拥有解决此问题所需的工具。然而,大规模计划可能需要更多时间和工作才能完全执行上述策略。
使用 Scrapeless,您可以获得有效绕过 CAPTCHA 和其他反机器人所需的所有工具。
免费使用 Scrapeless 获得最棒的数据抓取体验吧!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


