
MCP集成指南:Chrome DevTools MCP、Playwright MCP和Scrapeless Browser MCP
Expert Network Defense Engineer
本指南介绍了三个模型上下文协议(MCP)服务器——Chrome DevTools MCP、Playwright MCP 和 Scrapeless Browser MCP。
概述:选择合适的 MCP
| MCP 类型 | 技术栈 | 优势 | 主要生态系统 | 最适合的用途 |
|---|---|---|---|---|
| Chrome DevTools MCP | Node.js / Puppeteer | 官方标准,强大的性能分析工具。 | 广泛(Gemini、Copilot、Cursor) | CI/CD 自动化、跨 IDE 工作流和深入的性能审计。 |
| Playwright MCP | Node.js / Playwright | 使用可访问性树而不是像素;确定性和 LLM 友好,无需视觉。 | 广泛(VS Code、Copilot) | 可靠、结构化的自动化,减少因细微 UI 更改而造成的故障。 |
| Scrapeless Browser MCP | 云服务 | 零本地设置,可扩展的云浏览器,处理复杂网站和反机器人措施。 | API 驱动(任何客户端) | 大规模并行自动化任务,以及与检测强的网页进行交互。 |
一个云浏览器,无限集成
所有三个 MCP——Chrome DevTools MCP、Playwright MCP 和 Scrapeless Browser MCP——共享一个基础:它们都连接到 Scrapeless Cloud Browser。
与传统的本地浏览器自动化不同,Scrapeless Browser 完全在云中运行,为开发人员和 AI 代理提供无与伦比的灵活性和可扩展性。
以下是其真正强大的原因:
- 无缝集成:与 Puppeteer、Playwright 和 CDP 完全兼容,可以通过一行代码轻松迁移现有项目。
- 全球 IP 覆盖:在195个国家和地区访问住宅、ISP 和无限 IP 池,透明的成本效益($0.6–1.8/GB)。非常适合大规模网络数据自动化。
- 隔离配置文件:每个任务在专用的持久环境中运行,确保会话隔离、多账户管理和长期稳定性。
- 无限制并发扩展:瞬间启动 50-1000+ 浏览器实例,具有自动扩展基础设施——无需服务器设置,无性能瓶颈。
- 全球边缘节点:在多个全球节点上部署,提供超低延迟,比其他云浏览器启动快 2-3 倍。
- 反检测:内置对 reCAPTCHA、Cloudflare Turnstile 和 AWS WAF 的解决方案,确保即使在严格保护层下也能不间断自动化。
- 可视化调试:通过实时视图实现人机互动调试和实时代理流量监控。通过会话录制逐页重放会话,快速识别问题并优化操作。
Chrome DevTools MCP
Chrome DevTools MCP 是一个模型上下文协议(MCP)服务器,允许 AI 编码助手——如 Gemini、Claude、Cursor 或 Copilot——控制和检查实时 Chrome 浏览器,以实现可靠的自动化、先进的调试和性能分析。
关键功能
- 获取性能洞察: 使用 Chrome DevTools 记录跟踪并提取可操作的性能洞察。
- 高级浏览器调试: 分析网络请求、截屏并检查浏览器控制台。
- 可靠的自动化: 使用 Puppeteer 自动化 Chrome 中的操作,并自动等待操作结果。
要求
- Node.js v20.19 或最新的维护 LTS 版本。
- npm。
快速入门
登录 Scrapeless 并获取 API 密钥。
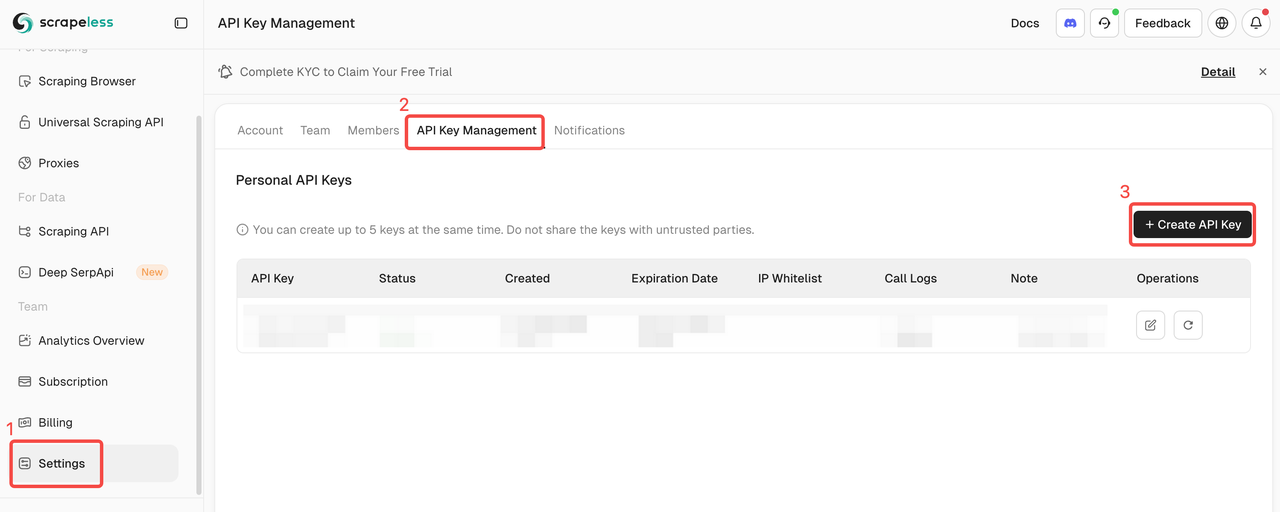
快速启动
此 JSON 配置由 MCP 客户端用于连接到 Chrome DevTools MCP 服务器并控制远程 Scrapeless 云浏览器实例。
{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"chrome-devtools-mcp@latest",
"--wsEndpoin=wss://browser.scrapeless.com/api/v2/browser?token=scrapeless api key&proxyCountry=US&sessionRecording=true&sessionTTL=900&sessionName=CDPDemo"
]
}
}
}示范
用例
- 网页性能分析:记录CDP的跟踪信息,提取关于页面加载、网络请求和JavaScript执行的可操作洞察,使AI助手能够建议性能优化。
- 自动调试:捕获控制台日志,检查网络流量,拍摄屏幕截图,自动重现错误以加快故障排查。
- 端到端测试:使用Puppeteer自动化复杂工作流,验证页面交互,并检查Chrome中的动态内容渲染。
- AI辅助自动化:像Gemini或Copilot这类的大语言模型可可靠且精确地填写表单、点击按钮或从Chrome页面抓取结构化数据。
Playwright MCP
Playwright MCP是一个基于Playwright的模型-上下文-协议(MCP)服务器,提供浏览器自动化功能。它允许大型语言模型(LLMs)或AI编码助手与网页进行交互。
主要特性
- 快速且轻量。使用Playwright的可访问性树,而不是基于像素的输入。
- 适合LLM。无需视觉模型,完全基于结构化数据运行。
- 确定性工具应用。避免了通常与基于截图的方法相关的模糊性。
要求
- Node.js 18或更新版本
- VS Code,Cursor,Windsurf,Claude Desktop,Goose或任何其他MCP客户端
开始使用
登录Scrapeless并获取您的API密钥。
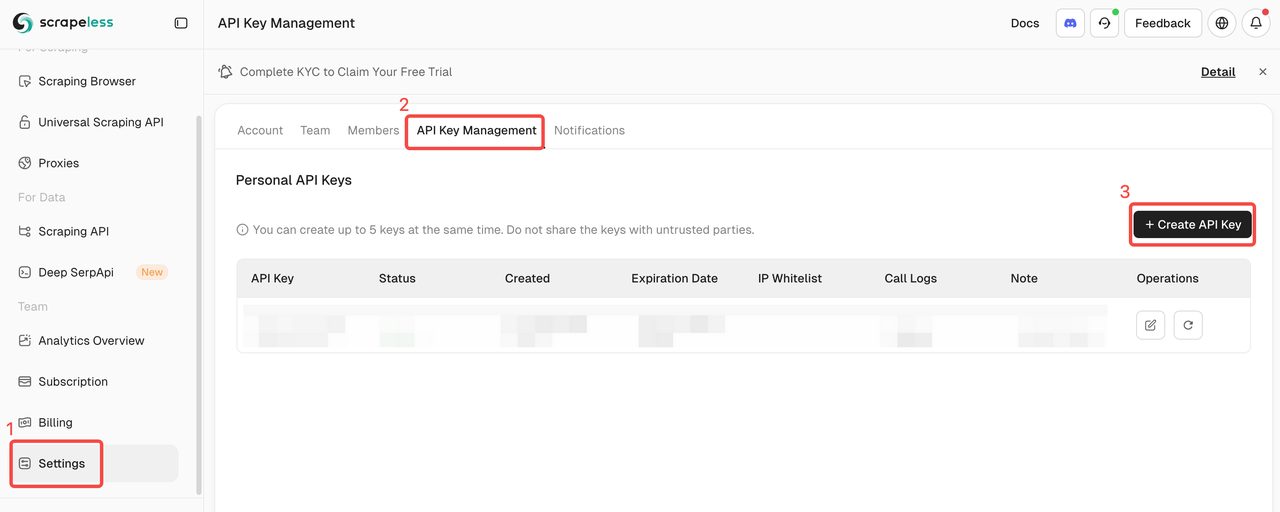
快速入门
此JSON配置由MCP客户端用于连接到Playwright MCP服务器,并控制远程Scrapeless云浏览器实例。
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest",
"--headless",
"--cdp-endpoint=wss://browser.scrapeless.com/api/v2/browser?token=Your_Token&proxyCountry=ANY&sessionRecording=true&sessionTTL=900&sessionName=playwrightDemo"
]
}
}
}展示
用例
-
网络爬虫和数据提取:由Playwright MCP支持的LLMs可以在真实浏览器环境中浏览网站,提取结构化数据,并自动化复杂的爬虫任务。这支持市场研究、内容聚合和竞争情报的大规模信息收集。
-
自动化工作流执行:Playwright MCP允许AI代理执行基于Web的重复工作流,例如数据输入、报告生成和仪表板更新。它在业务流程自动化、人力资源入职等高频操作中尤为有效。
-
个性化客户服务和支持:AI代理可以使用Playwright MCP直接与Web门户交互,检索用户特定数据并执行故障排查操作。这使得个性化和上下文感知的支持体验成为可能,例如自动获取订单详情或解决登录问题。
浏览器MCP
Scrapeless浏览器MCP服务器无缝连接像ChatGPT、Claude这样的模型和像Cursor、Windsurf这样的工具,提供一系列外部能力,包括:
- 用于页面级导航和交互的浏览器自动化
- 抓取动态、JavaScript密集的网站—导出为HTML、Markdown或截图
支持的MCP工具
| 名称 | 描述 |
|---|---|
| browser_create | 使用Scrapeless创建或重用云浏览器会话。 |
| browser_close | 通过断开云浏览器连接来关闭当前会话。 |
| browser_goto | 导航浏览器到指定的URL。 |
| browser_go_back | 在浏览器历史中向后退一步。 |
| browser_go_forward | 在浏览器历史中向前迈进一步。 |
| browser_click | 点击页面上的特定元素。 |
| browser_type | 在指定输入字段中键入文本。 |
| browser_press_key | 模拟按键。 |
| browser_wait_for | 等待特定页面元素出现。 |
| browser_wait | 暂停执行一段固定时间。 |
| browser_screenshot | 捕获当前页面的截图。 |
| browser_get_html | 获取当前页面的完整HTML。 |
| browser_get_text | 获取当前页面的所有可见文本。 |
| browser_scroll | 滚动到页面底部。 |
| browser_scroll_to | 将特定元素滚动到视图中。 |
| scrape_html | 抓取一个URL并返回其完整的HTML内容。 |
| scrape_markdown | 抓取一个URL并将其内容作为Markdown返回。 |
| scrape_screenshot | 捕获任何网页的高质量截图。 |
开始使用
登录到Scrapeless并获取您的API令牌。
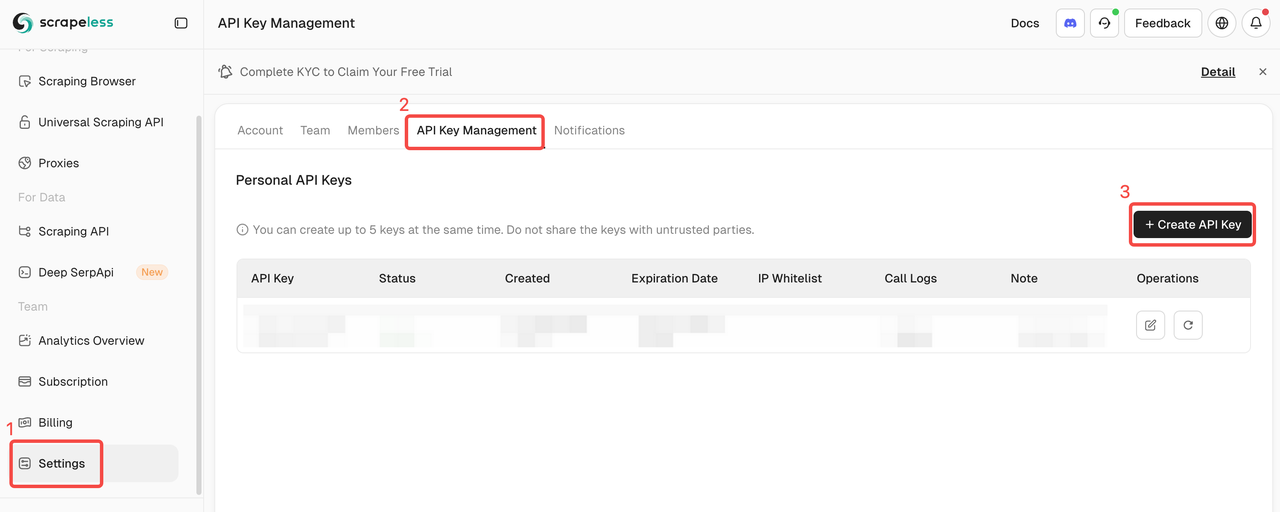
配置您的MCP客户端
Scrapeless MCP服务器支持Stdio和可流式HTTP传输模式。
🖥️ Stdio(本地执行)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "您的_SCRAPELESS_KEY"
}
}
}
}🌐 可流式HTTP(托管API模式)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "您的_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}高级选项
通过可选参数自定义浏览器会话行为。这些可以通过环境变量(对于Stdio)或HTTP头(对于可流式HTTP)进行设置:
| Stdio(环境变量) | 可流式HTTP(HTTP头) | 描述 |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | 指定用于会话持续性的可重用浏览器配置文件ID。 |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | 启用对cookie、本地存储等的持久存储。 |
| BROWSER_SESSION_TTL | x-browser-session-ttl | 定义最大会话超时时间(以秒为单位)。会话将在此不活动持续时间后自动过期。 |
用例
网络抓取与数据收集
- 电子商务监控:自动访问产品页面以收集价格、库存状态和描述。
- 市场研究:批量抓取新闻、评论或公司页面进行分析和比较。
- 内容聚合:提取页面内容、帖子和评论进行集中收集。
- 潜在客户生成:从公司网站或目录中收集联系信息和公司详情。
测试与质量保证
- 功能验证:使用点击、输入和元素等待确保页面按预期行为。
- 用户旅程测试:模拟真实用户交互(输入、点击、滚动)以验证工作流程。
- 回归测试支持:捕获关键页面的屏幕截图并进行比较以检测UI或内容变化。
任务与工作流自动化
- 表单填写:自动完成并提交网页表单(例如,注册、调查)。
- 数据捕获与报告生成:定期提取页面数据,并以HTML或屏幕截图的形式保存以供分析。
- 简单的行政任务:使用模拟点击和输入自动化重复的后端或基于Web的操作。
展示
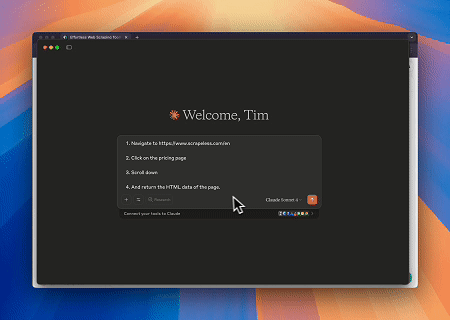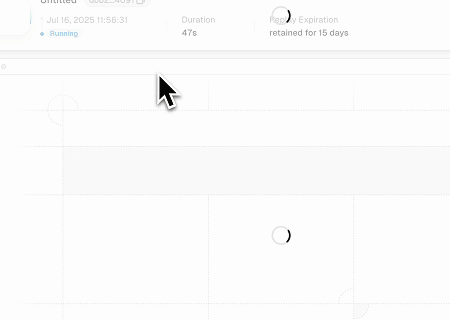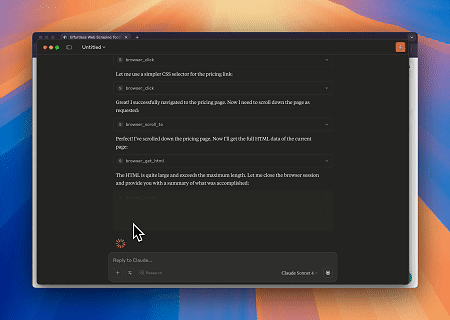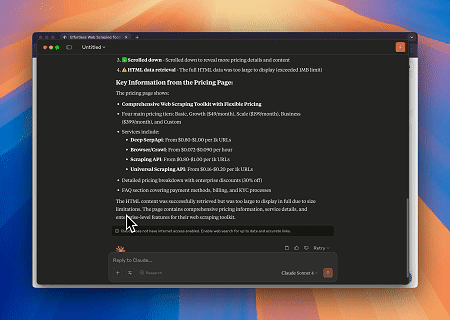
案例 1:使用Claude进行网页交互和数据提取自动化
使用浏览器MCP服务器,Claude可以通过对话命令执行复杂的网页操作,例如导航、点击、滚动和数据抓取,并实时预览执行。
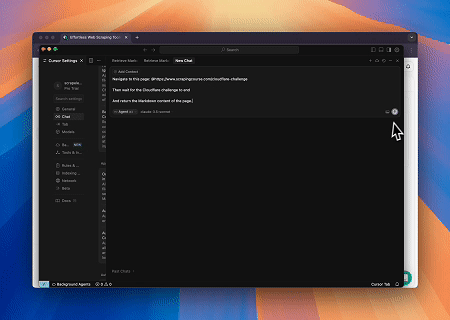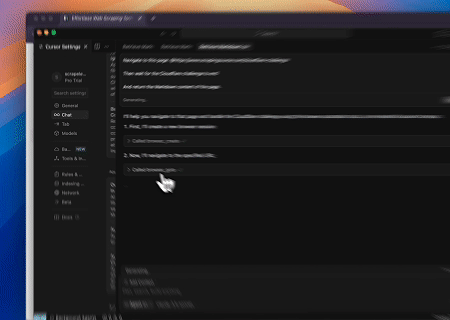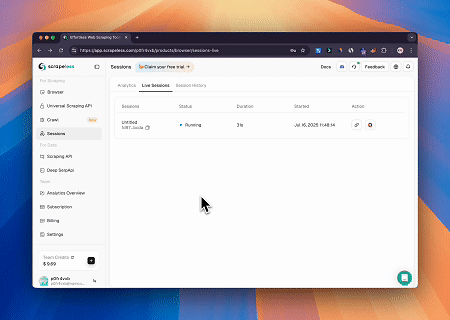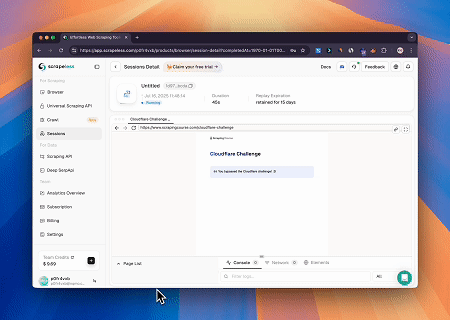
案例 2:绕过Cloudflare以获取目标页面内容
使用浏览器MCP服务器,自动访问Cloudflare保护的页面,并在完成后提取页面内容并以Markdown格式返回。
集成
Claude桌面
- 打开Claude桌面
- 导航到:设置 → 工具 → MCP服务器
- 点击**“添加MCP服务器”**
- 粘贴上述Stdio或可流式HTTP配置
- 保存并启用服务器
- Claude现在将能够发出Web查询、提取内容,并使用Scrapeless与页面交互
Cursor IDE
- 打开Cursor
- 按下 Cmd + Shift + P 并搜索: 配置 MCP 服务器
- 使用上述格式添加 Scrapeless MCP 配置
- 保存文件并重启 Cursor(如果需要)
- 现在你可以问 Cursor 诸如:
- “在 StackOverflow 上搜索这个错误的解决方案”
- “抓取这个页面的 HTML”
- 它将在后台使用 Scrapeless。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


