
如何用Python抓取谷歌搜索结果 - 最好的谷歌搜索抓取工具?
Specialist in Anti-Bot Strategies
什么是Google SERP?
每当讨论网络抓取Google搜索结果时,你很可能会遇到缩写“SERP”。SERP代表搜索引擎结果页面(Search Engine Results Page)。这是你在搜索栏输入查询后得到的页面。
过去,Google会为你的查询返回一系列链接。今天,它看起来完全不同——SERP包含各种功能和元素,使你的搜索体验快速便捷。
通常,页面包含:
- 自然搜索结果
- 付费搜索结果
- 特色摘要
- 知识图谱
- 其他元素: 例如根据查询显示的地图、图片或新闻报道。
抓取Google搜索结果是否合法?
在抓取Google搜索结果之前,务必了解法律含义。Google的服务条款禁止抓取其搜索结果,正如其政策中所述:
“你不得为了任何目的而抓取、爬取或使用任何自动化手段访问服务。”
违反这些条款可能会导致IP封禁,甚至Google的法律诉讼。但是,抓取的合法性取决于司法管辖区、你正在抓取的数据以及你如何使用它。
抓取Google的替代方案:
- Google自定义搜索API: Google提供了一个官方API来检索搜索结果,这是一种合法且结构化的访问数据方式,不会违反其政策。
- 其他搜索API: 如果你不一定要使用Google,还有其他搜索引擎和服务提供用于访问搜索结果的API,例如Bing和Scrapeless。
抓取Google SERP的四个主要难点
抓取Google SERP存在许多挑战,这就是为什么它被认为很困难的原因。这些包括:
- 机器人检测: Google采用多种技术来检测和阻止机器人,包括:
- CAPTCHA
- IP封锁
- 速率限制
- 动态内容: Google搜索结果通常使用JavaScript动态生成,这可能会使抓取变得复杂。内容可能在页面初始加载后加载,需要像Selenium这样的工具才能完全呈现页面。
- HTML结构变化: Google经常更改其搜索结果的布局和结构,这意味着抓取工具需要快速适应以避免代码中断。
- 复杂数据: SERP包含各种复杂的元素,如广告、图片、视频和丰富的摘要,这使得持续提取有意义的数据具有挑战性。
尽管存在这些挑战,但使用正确的技术和工具仍然可以抓取Google搜索结果。
让我们将流程分解为以下步骤,以使用Python抓取Google搜索结果:
如何使用Python抓取Google搜索结果?
步骤1:向Google发送请求
在开始抓取之前,你需要向Google的搜索页面发送请求。由于Google阻止大多数来自机器人的请求,因此通过设置正确的User-Agent标头来模拟真实用户至关重要。
Python
import requests
from fake_useragent import UserAgent
# 生成一个随机的用户代理
ua = UserAgent()
headers = {'User-Agent': ua.random}
# Google搜索查询
query = "How to scrape Google search results with Python"
url = f"https://www.google.com/search?q={query}"
# 发送GET请求
response = requests.get(url, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
print(response.text)
else:
print("Failed to retrieve the page")步骤2:解析HTML内容
一旦你获得了Google SERP的HTML内容,就可以使用BeautifulSoup提取所需的数据。
Python
from bs4 import BeautifulSoup
# 解析页面内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有搜索结果容器
search_results = soup.find_all('div', class_='BVG0Nb')
for result in search_results:
title = result.text
link = result.find('a')['href']
print(f"Title: {title}")
print(f"Link: {link}\n")步骤3:处理JavaScript(使用Selenium)
Selenium是一个处理依赖JavaScript呈现内容的页面的好工具。它自动化浏览器并模拟用户交互,使其成为抓取动态生成内容的理想选择。
Python
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 设置Selenium WebDriver
driver = webdriver.Chrome(ChromeDriverManager().install())
# 打开Google并执行搜索
driver.get("https://www.google.com/")
search_box = driver.find_element(By.NAME, 'q')
search_box.send_keys("How to scrape Google search results with Python")
search_box.submit()
# 等待结果加载并提取链接
driver.implicitly_wait(5)
# 获取搜索结果
search_results = driver.find_elements(By.CLASS_NAME, 'BVG0Nb')
for result in search_results:
title = result.text
link = result.find_element(By.TAG_NAME, 'a').get_attribute('href')
print(f"Title: {title}")
print(f"Link: {link}\n")
driver.quit()步骤4:避免检测
为了最大限度地减少被Google检测和阻止的可能性,你应该:
- 轮换用户代理: 使用不同的用户代理来模拟来自各种浏览器的请求。
- 添加延迟: 在请求之间引入随机延迟以模仿类似人类的浏览行为。
- 使用代理: 轮换IP地址以分发你的请求并避免检测。
- 尊重robots.txt: 始终检查Google的robots.txt文件并遵循道德抓取实践。
最佳Google搜索抓取API - Scrapeless
虽然直接抓取Google是可能的,但这可能会很繁琐且容易出错,而且常常会导致被阻止。这就是Scrapeless的用武之地。凭借强大的CAPTCHA求解器、IP轮换、智能代理和网页解锁器,Scrapeless是一个功能强大的API,专门设计用于帮助用户在不被阻止的情况下抓取搜索结果。
为什么选择Scrapeless?
- 合法性: Scrapeless提供了一种合法合规的访问搜索结果的方式。
- 可靠性: 该API使用复杂的技术来避免检测,确保不间断的数据收集。
- 易于使用: Scrapeless提供了一个简单的API,可以轻松地与Python集成,非常适合需要快速访问搜索结果数据的开发人员。
- 可定制: 你可以根据自己的需要定制结果,例如指定内容类型(例如,自然列表、广告等)。
Scrapeless Google搜索抓取API - 使用步骤:
为了使数据更有针对性和具体性,我们在本文中抓取了Google趋势作为演示。
对网络封锁和Google搜索抓取感到沮丧?
加入我们的社区,并获得具有免费试用版的有效解决方案!
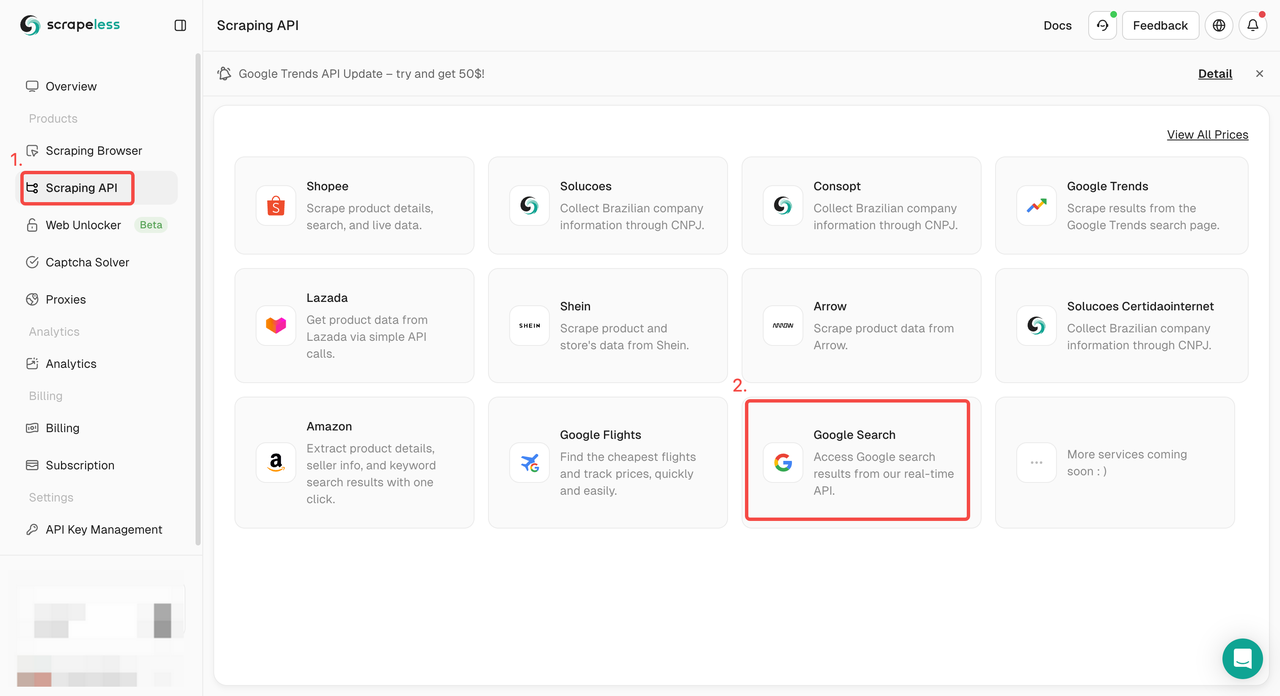
步骤1. 登录Scrapeless仪表板 并转到“Google搜索API”。
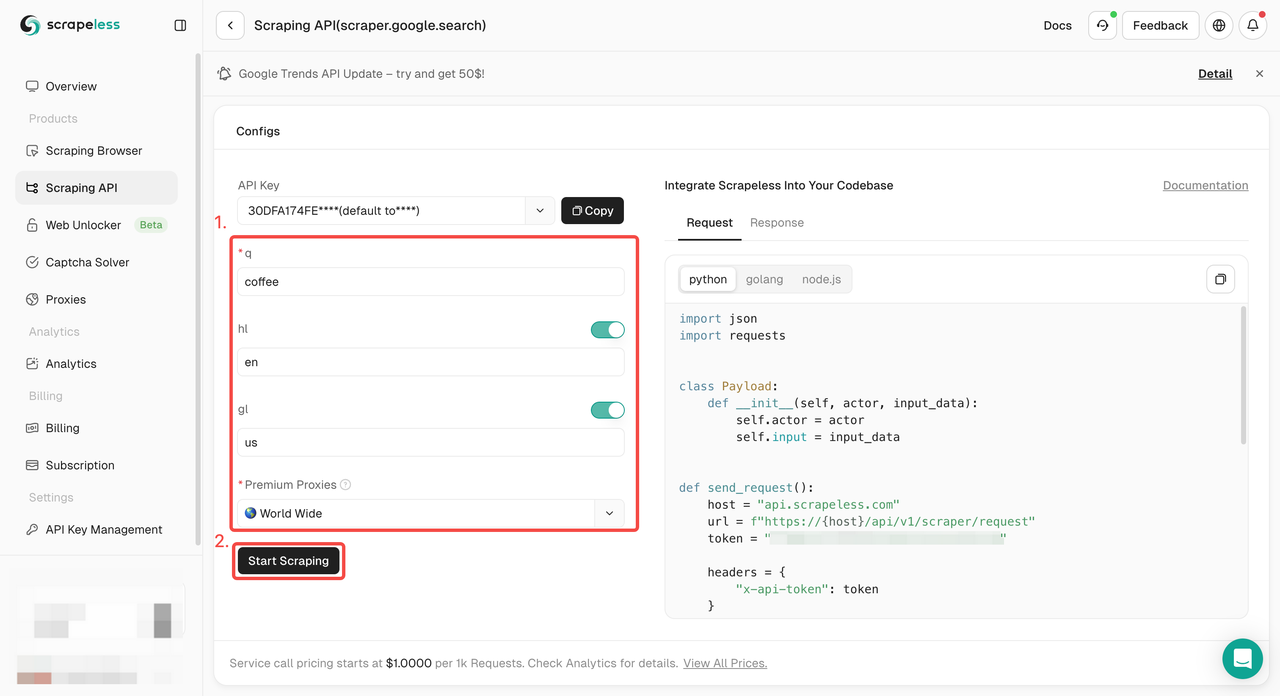
步骤2. 在左侧配置所需的关键字、区域、语言、代理和其他信息。确保一切正常后,点击“开始抓取”。
q: 参数定义你要搜索的查询。gl: 参数定义要用于Google搜索的国家/地区。hl: 参数定义要用于Google搜索的语言。
步骤3. 获取抓取结果并导出它们。
只需要将示例代码集成到你的项目中?我们已经为你准备好了!或者你可以访问我们的API文档以获取你需要的任何语言。
- Python:
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}结束语
抓取Google搜索结果可能很棘手,但是使用正确的工具和技术,它绝对是可以实现的!记住:这不仅仅是编写代码——它还关乎如何避免检测、尊重法律界限以及在必要时寻找替代方案。
Scrapeless抓取API可能是你在抓取Google搜索结果世界中的最佳朋友!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


