
如何用Python爬取Google学术?
Expert Network Defense Engineer
Google Scholar是一个用于访问学术数据的搜索引擎。使用Google Scholar,您可以检索科学文章、研究论文和论文。然而,学术研究通常需要从Google Scholar搜索结果中收集和分析大量数据。
手动浏览无数的结果是一项艰巨的任务。这就是为什么可靠的Google Scholar爬虫可以帮助使这个过程不那么痛苦。通过自动化,您可以爬取Google Scholar,以秒速从Google Scholar页面上的每个结果中提取诸如标题、作者和引用等数据。
在本教程中,您将学习如何通过使用Scrapeless Google Scholar API和Python发出HTTP请求来构建有效的Google Scholar爬虫。
继续滚动以了解更多信息!
🎓 什么是Google Scholar爬虫?
Google Scholar爬虫是一种旨在从Google Scholar提取公开的学术数据(例如研究论文、引用、作者和出版物详细信息)的工具。它使研究人员、学者和组织能够收集有价值的见解,用于分析、趋势跟踪和学术研究。但是,由于其强大的反爬虫机制,使用网络爬虫爬取Google Scholar会面临重大挑战。
为什么Google Scholar上的数据如此有价值?
- 审查和研究: 查找与学术研究或项目相关的论文、文章、论文和书籍。比较不同的方法和理论框架。
- 学术分析: 识别学术出版物中的新兴趋势和主题,并计算学术指标(例如H指数和引用次数)。
- 潜在合作: 识别特定领域的专家,以进行潜在的合作、会议或同行评审。
- 产品开发: 研发专业人员可以爬取Google Scholar以进行深入研究、取得突破,并跟踪相关科学或技术领域中竞争对手的出版物。
Google Scholar爬取挑战与解决方案
Google Scholar是一个强大的学术搜索引擎,提供了大量的学术论文、专利、书籍和会议文章。但是,爬取Google Scholar数据面临许多技术和法律挑战。以下是您在网络爬取Google Scholar时可能遇到的主要问题及其解决方案:
| 挑战 | 描述 | 解决方案 |
|---|---|---|
| IP封锁 | 频繁请求会导致IP封锁。 | 使用代理。轮换多个IP地址以防止主IP被封锁。 |
| CAPTCHA | Google可能会要求用户输入CAPTCHA以确认他们是人类。 | 选择可以自动为您解决CAPTCHA的服务。 |
| 请求速率限制 | 过高的请求速率会被检测并阻止。 | 更改用户代理并在请求之间等待几秒钟以模拟人类行为。 |
| 动态内容加载 | Google Scholar使用JavaScript动态加载内容。 | 使用无头浏览器(如Puppeteer或Selenium)来渲染JavaScript并提取内容。 |
此外,Google Scholar的爬取还存在API限制。由于Google Scholar没有官方API,网络爬取Google Scholar需要直接解析网页,这增加了复杂性和不稳定性。
幸运的是,您可以尝试使用强大的第三方API服务。它们保证方便、快速和准确的数据提取。此外,在许多API服务提供商中,Scrapeless还内置了CAPTCHA解码服务、轮换代理和网页解锁器。
分步:构建您的Python Google Scholar爬虫
接下来,我们将开始使用Python Google Scholar爬虫爬取Google Scholar。您将看到如何获取文章标题、出版信息和文章标题等数据。
步骤1. 配置环境
Python: 软件https://www.python.org/downloads/是运行Python的核心。您可以从官方网站下载所需版本,如下所示。但是,不建议下载最新版本。您可以下载比最新版本早1.2个版本的版本。
Python IDE: 任何支持Python的IDE都可以使用,但我们推荐PyCharm。它是一个专门为Python设计的开发工具。对于PyCharm版本,我们推荐免费的PyCharm社区版。
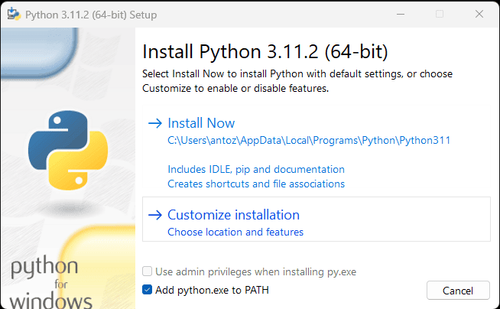
注意: 如果您是Windows用户,请不要忘记在安装向导期间选中“将python.exe添加到PATH”选项。这将允许Windows在终端中使用Python和命令。由于Python 3.4或更高版本默认包含它,因此您无需手动安装它。
现在,您可以通过打开终端或命令提示符并输入以下命令来检查是否安装了Python:
Bash
python --version步骤2. 安装依赖项
建议创建一个虚拟环境来管理项目依赖项并避免与其他Python项目冲突。在终端中导航到项目目录,并执行以下命令以创建名为google_scholar_env的虚拟环境:
Bash
python -m venv google_scholar_env根据您的系统激活虚拟环境:
- Windows:
Bash
google_scholar_env\Scripts\activate- MacOS/Linux:
Bash
source google_scholar_env/bin/activate激活虚拟环境后,安装网络爬取所需Python库。用于在Python中发送requests的库是requests,用于爬取数据的主要库是BeautifulSoup4。使用以下命令安装它们:
Bash
pip install requests
pip install beautifulsoup4步骤3. 爬取数据
在浏览器中打开Google Scholar并搜索“biology”。以下是搜索结果:
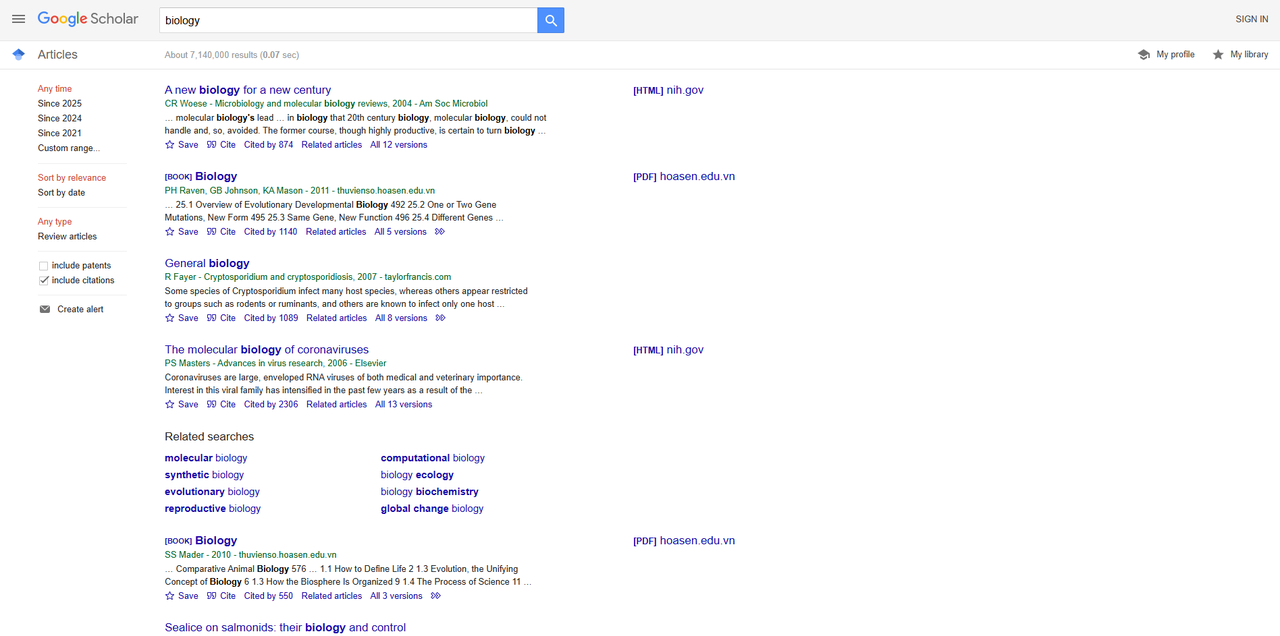
- 爬取标题:
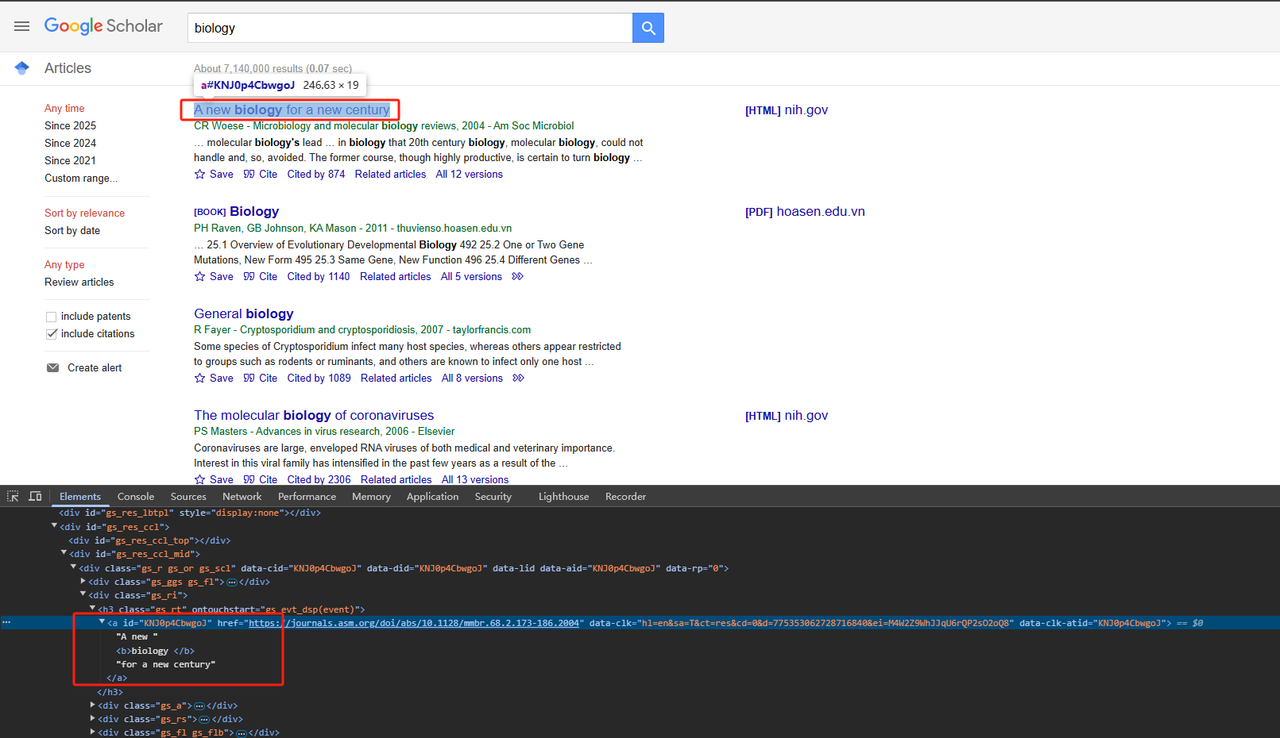
解析相关的HTML页面元素。详细的Python代码如下:
Python
def scrape_scholar_title(listing):
title_element = listing.select_one('h3.gs_rt a')
return title_element .text.strip()- 爬取出版信息:
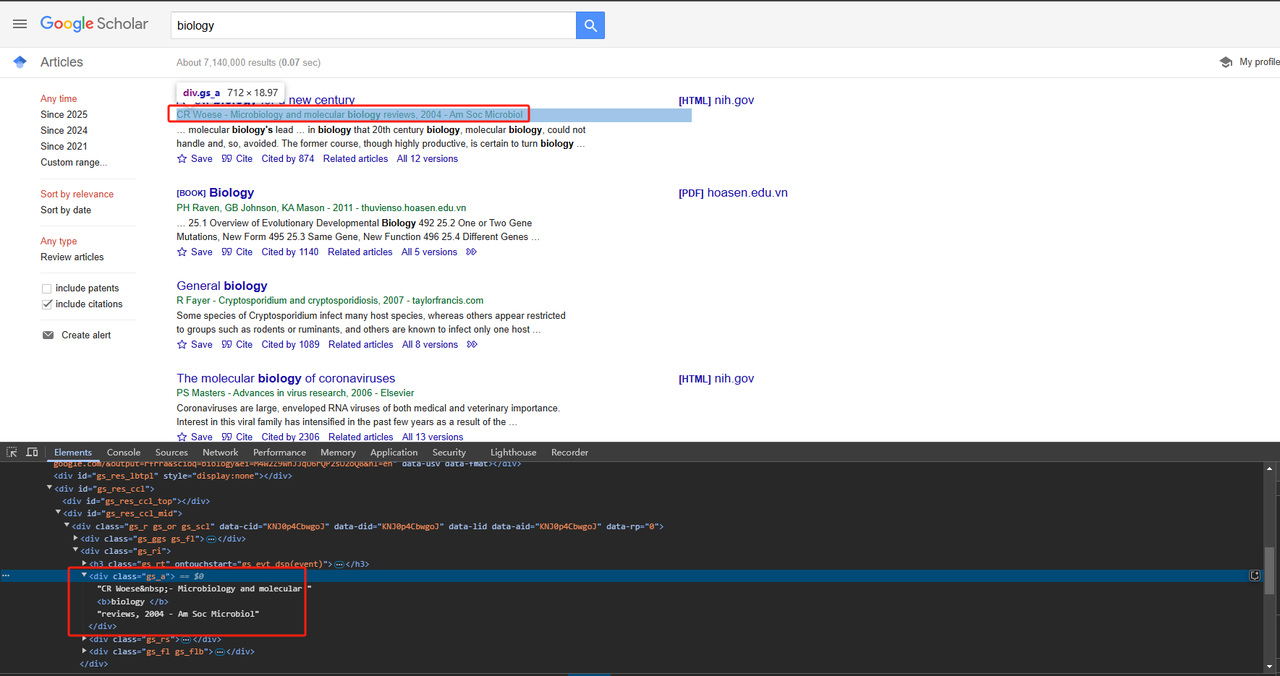
可以使用div类属性直接爬取出版信息。详细的Python代码如下:
Python
def scrape_scholar_publication_info(listing):
publication_info_element = listing.select_one('div.gs_a')
return publication_info_element .text.strip()- 爬取文章摘要:
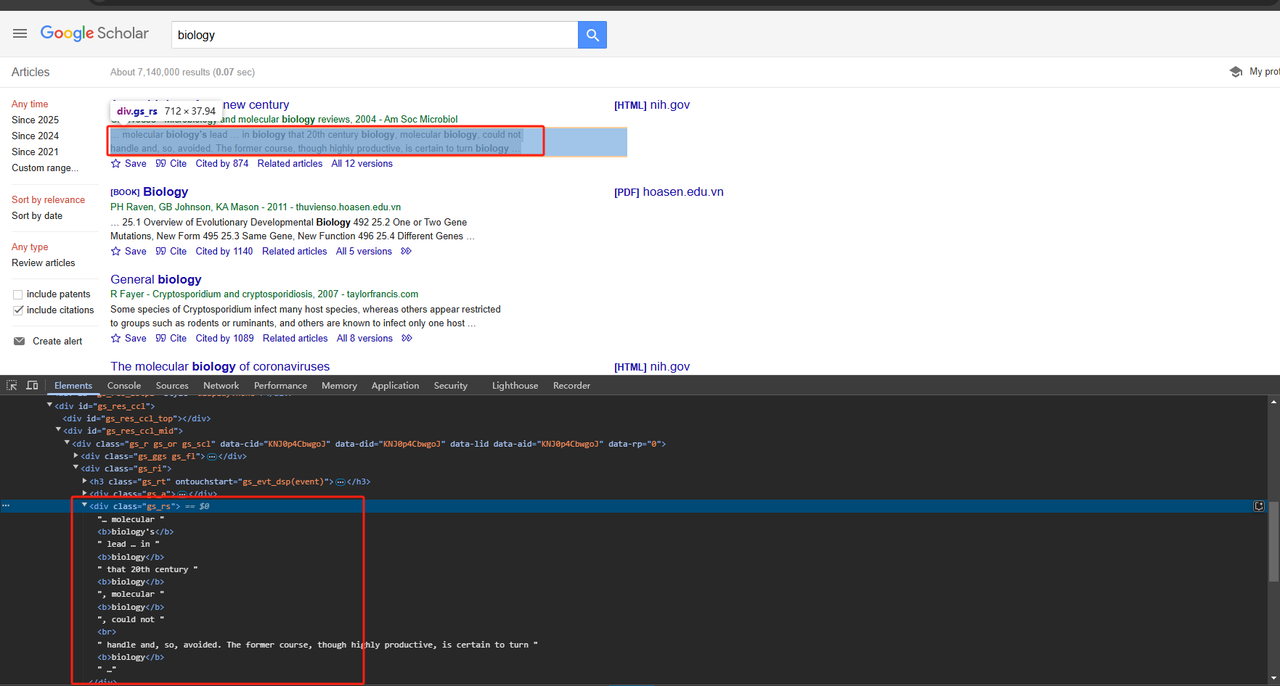
也可以使用div类属性直接爬取文章摘要。详细的Python代码如下:
Python
def scrape_scholar_snippet(listing):
snippet_element = listing.select_one('div.gs_rs')
return snippet_element .text.strip()由于我们需要爬取页面上的所有数据,而不仅仅是一个,因此我们需要循环遍历并爬取上述数据。完整的代码如下:
Python
# Import necessary libraries
import time
import requests
from bs4 import BeautifulSoup
import json
# Function to scrape listing elements from google_scholar
def scrape_listings(soup):
return soup.select('div.gs_r.gs_or.gs_scl')
# Function to scrape title from google_scholar
def scrape_scholar_title(listing):
title_element = listing.select_one('h3.gs_rt > a')
print(title_element.text)
return title_element.text.strip()
# Function to scrape publication_info from google_scholar
def scrape_scholar_publication_info(listing):
publication_info_element = listing.select_one('div.gs_a')
print(publication_info_element.text)
return publication_info_element.text.strip()
# Function to scrape snippet from google_scholar
def scrape_scholar_snippet(listing):
snippet_element = listing.select_one('div.gs_rs')
print(snippet_element.text)
return snippet_element.text.strip()
# Main function
def main():
# Make a request to google_scholar URL and parse HTML
url = 'https://scholar.google.com/scholar?hl=en&q=biology'
response = requests.get(url, verify=False)
time.sleep(2)
soup = BeautifulSoup(response.text, 'html.parser')
# Scrape scholar listings
listings = scrape_listings(soup)
print(listings)
# Iterate through each listing and extract scholar information
scholar_data = []
for listing in listings:
title = scrape_scholar_title(listing)
publication_info = scrape_scholar_publication_info(listing)
snippet = scrape_scholar_snippet(listing)
# Store scholar information in a dictionary
scholar_info = {
'title': title,
'publication_info': publication_info,
'snippet': snippet
}
scholar_data.append(scholar_info)
# Save results to a JSON file
with open('google_scholar_data.json', 'w') as json_file:
json.dump(scholar_data, json_file, indent=4)
if __name__ == "__main__":
main()步骤4. 输出结果
您将在PyCharm目录中生成一个名为google_scholar_data.json的文件。输出如下:
JSON
[
{
"title": "A new biology for a new century",
"publication_info": "CR Woese\u00a0- Microbiology and molecular biology reviews, 2004 - Am Soc Microbiol",
"snippet": "\u2026 molecular biology's lead \u2026 in biology that 20th century biology, molecular biology, could not \nhandle and, so, avoided. The former course, though highly productive, is certain to turn biology \u2026"
},
{
"title": "Biology",
"publication_info": "PH Raven, GB Johnson, KA Mason - 2011 - thuvienso.hoasen.edu.vn",
"snippet": "\u2026 25.1 Overview of Evolutionary Developmental Biology 492 25.2 One or Two Gene \nMutations, New Form 495 25.3 Same Gene, New Function 496 25.4 Different Genes\u00a0\u2026"
},
{
"title": "General biology",
"publication_info": "R Fayer\u00a0- Cryptosporidium and cryptosporidiosis, 2007 - taylorfrancis.com",
"snippet": "Some species of Cryptosporidium infect many host species, whereas others appear restricted \nto groups such as rodents or ruminants, and others are known to infect only one host \u2026"
},
{
"title": "The molecular biology of coronaviruses",
"publication_info": "PS Masters\u00a0- Advances in virus research, 2006 - Elsevier",
"snippet": "Coronaviruses are large, enveloped RNA viruses of both medical and veterinary importance. \nInterest in this viral family has intensified in the past few years as a result of the \u2026"
},
{
"title": "Biology",
"publication_info": "SS Mader - 2010 - thuvienso.hoasen.edu.vn",
"snippet": "\u2026 Comparative Animal Biology 576 \u2026 1.1 How to Define Life 2 1.3 Evolution, the Unifying \nConcept of Biology 6 1.3 How the Biosphere Is Organized 9 1.4 The Process of Science 11\u00a0\u2026"
},
{
"title": "Sealice on salmonids: their biology and control",
"publication_info": "AW Pike, SL Wadsworth\u00a0- Advances in parasitology, 1999 - Elsevier",
"snippet": "\u2026 This review examines the voluminous literature on the biology and control of sealice and \nbrings together ideas for developing our knowledge of these organisms. Research on the \u2026"
},
{
"title": "Biology data book",
"publication_info": "PL Altman, DS Dittmer - 1972 - bionumbers.hms.harvard.edu",
"snippet": "Embryos were raised at constant temperature in circulating nalis\" u 10% smaller. For \nadditional information on salmowater, from three hours after fertilization. Age= time from nids, \u2026"
},
{
"title": "The biology of Pseudocalanus",
"publication_info": "CJ Corkett, IA McLaren\u00a0- Advances in marine biology, 1979 - Elsevier",
"snippet": "Publisher Summary Pseudocalanus is typical of most crustaceans in that after hatching at \nan early stage of development it adds successively new segments and appendages. \u2026"
},
{
"title": "Introduction to a submolecular biology",
"publication_info": "A Szent-Gyorgyi - 2012 - books.google.com",
"snippet": "\u2026 Biology is the science of the improbable and I think it is on principle that the body works \nonly with reactions which are statistically improbable. If metabolism were built of a series of \u2026"
},
{
"title": "The biology of mycorrhiza.",
"publication_info": "JL Harley - 1959 - cabidigitallibrary.org",
"snippet": "Since Dr. Rayner published her book on mycorrhiza in 1927 there has not been a comprehensive \naccount of this subject, although the need for a critical re-appraisal of the extensive \u2026"
}
]简易部署Scrapeless Google Scholar API
为什么Scrapeless Scholar API 至关重要?
当然!您只需要一个价格合理、稳定且安全的API服务。但是,找到满足所有这些条件的服务非常具有挑战性!幸运的是,Scrapeless Google Scholar API在众多API产品中脱颖而出:
- 🔴 节省成本: Google Scholar API 只需**$0.80**,订阅$49即可获得10%的折扣!
- 🔴 准确的数据: 我们的开发人员不断分析Google的爬取算法和限制,以确保API得到更新和优化。
- 🔴 稳定且成功率高: Scrapeless 保证99% 的成功率和可靠性。Google Trends 爬取的稳定性和准确性已达到近100%!目前,平均响应时间约为3秒**,比大多数API提供商都快得多。此外,数据以标准化的JSON格式返回,可以直接使用。
Scrapeless 已经赢得了超过2,000家企业用户的信任!立即加入Discord 即可领取免费试用! 限时仅有1,000个名额——快来行动!
进一步阅读:
使用步骤:
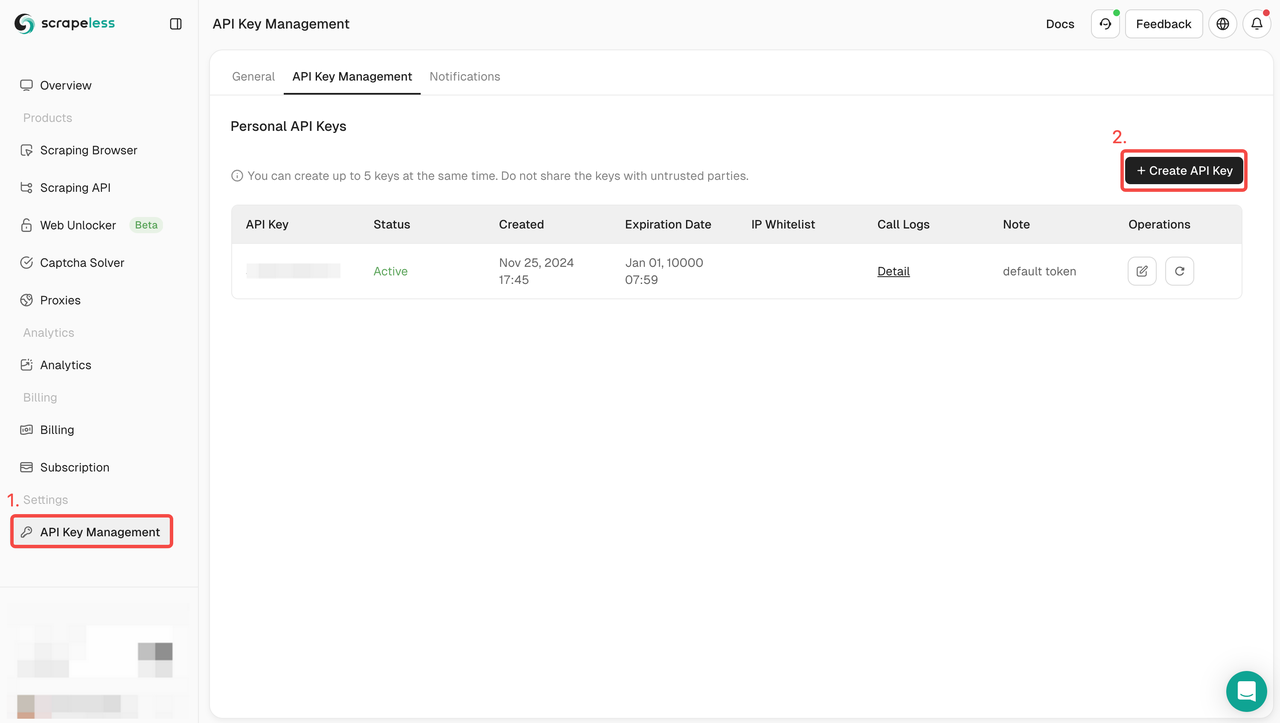
步骤1. 获取API令牌
- 登录到仪表板。
- 导航到API密钥管理。
- 点击创建以生成您的唯一API密钥。
- 只需点击API密钥即可复制它。
步骤2:在代码中使用您的API密钥
现在您只需要配置API文档中的参数即可爬取所需Google Scholar数据。
- 访问API文档。
- 点击所需端点的“试用”。
- 在代码正文中配置所需的parameters。
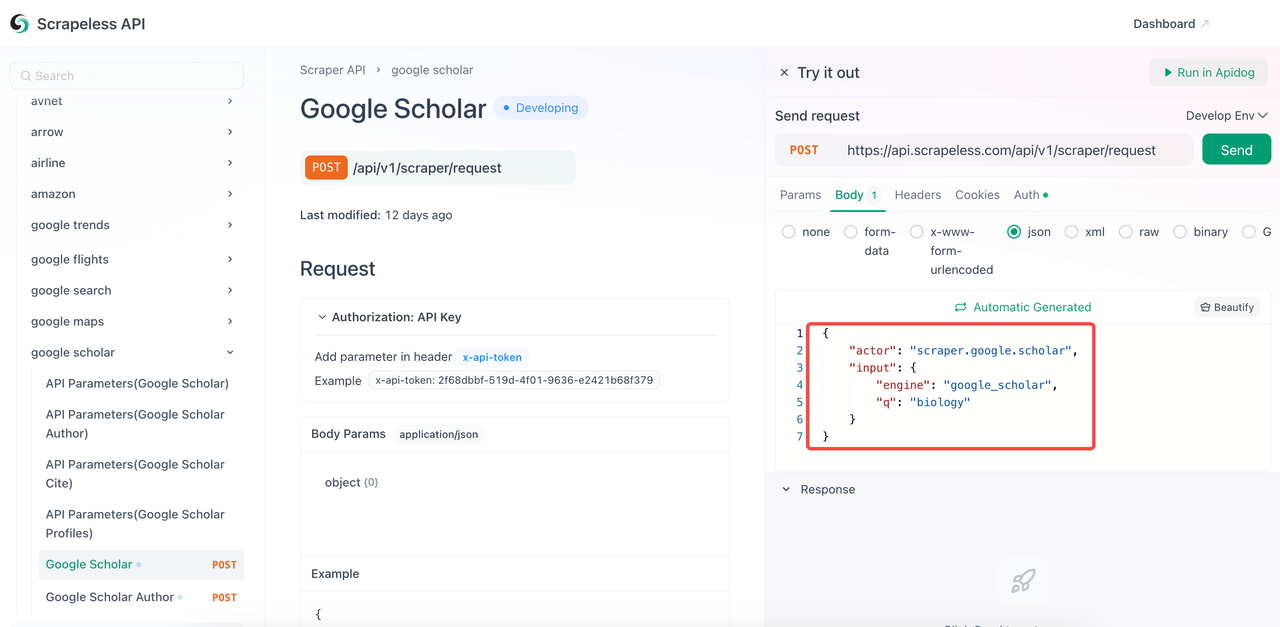
- 将关键字
q替换为您要查询的关键字。 engine参数是必须的,其值必须为google_scholar。但是,您可以添加更具体的参数,例如google_scholar_author。- 常用参数:
| 参数 | 必需 | 描述 |
|---|---|---|
engine |
TRUE | 设置为google_scholar以使用此API。 |
q |
TRUE | 搜索查询(例如,“机器学习”)。 |
cites |
FALSE | 查找引用文章的唯一ID。 |
as_ylo |
FALSE | 过滤特定年份的结果。 |
as_yhi |
FALSE | 过滤截至特定年份的结果。 |
hl |
FALSE | 语言设置(默认:en)。 |
num |
FALSE | 结果数量(1-20,默认:10)。 |
- 在“Auth”字段中输入您的API密钥。
- 点击“发送”以获取爬取响应。
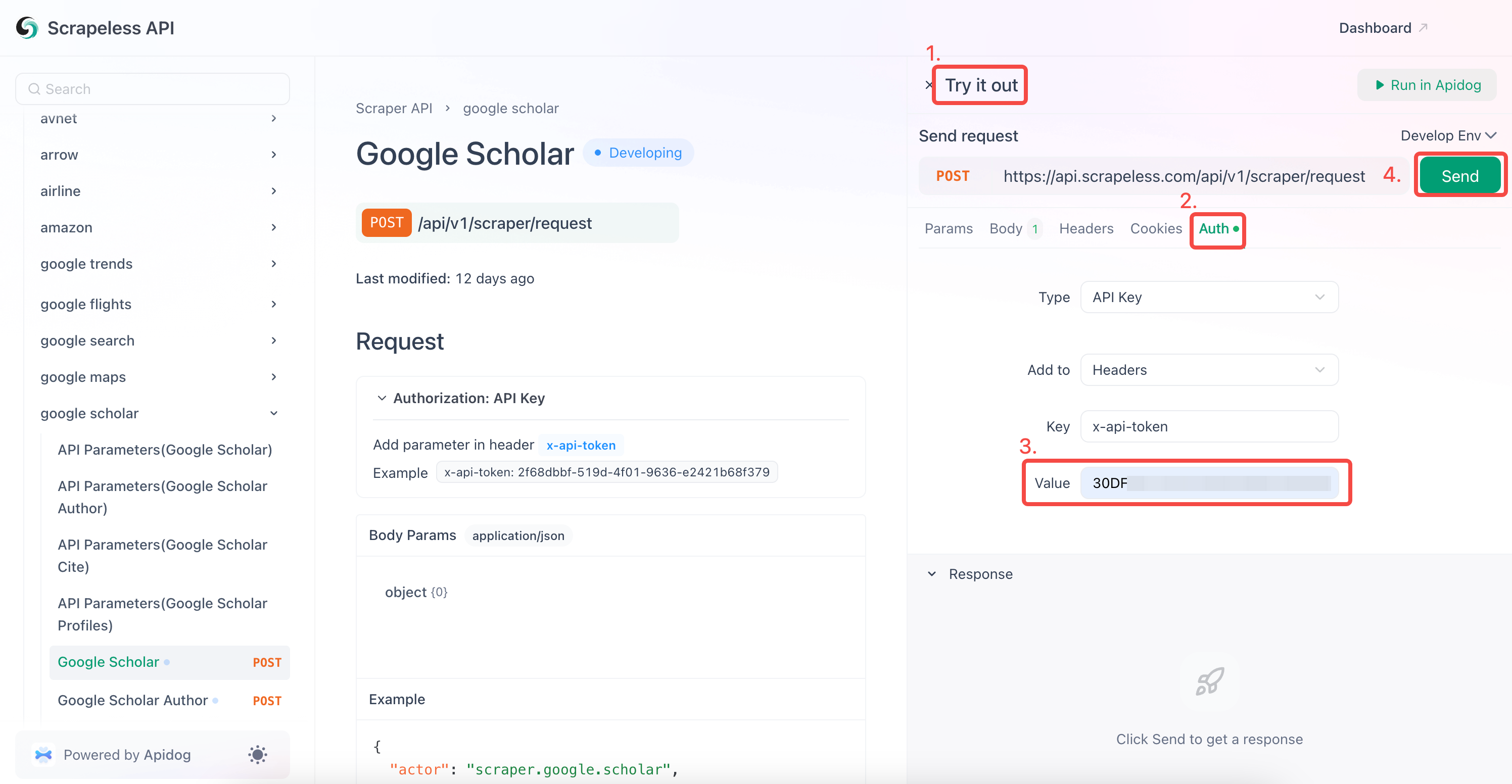
Scrapeless Google Scholar还支持爬取:
- Google Scholar 作者
- Google Scholar 引用
- Google Scholar 个人资料
您也可以直接将我们的参考代码集成到您的程序中。只需将your_token替换为您申请的令牌:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = your_token ## replace with your API Token
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_scholar",
"q": "biology",
}
payload = Payload("scraper.google.scholar", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()立即构建您的Google Scholar爬虫!
爬取Google Scholar是提取学术信息的好方法。无论您是在寻找代码还是无代码方法来爬取Google Scholar或其他搜索引擎,我们都为您提供了一个简单快速的解决方案。
Scrapeless 提供为期一个月的免费试用,您可以在其中享受所有服务以收集数据。如何从Google Scholar中查找详细数据?您可以使用Scrapeless在很短的时间内收集大量数据。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


