
如何用Python抓取Google趋势数据?
Senior Web Scraping Engineer
什么是 Google Trends?
Google Trends 是 Google 提供的一款免费在线工具,用于分析 Google 搜索引擎中特定关键词或搜索词随时间的流行程度。
它以图表的形式呈现数据,帮助用户了解特定主题或关键词的搜索流行度,并识别季节性波动、新兴趋势或兴趣下降等模式。Google Trends 不仅支持全球数据分析,还可以细化到特定地区,并提供相关搜索词和主题的建议。
Google Trends 广泛应用于市场研究、内容规划、SEO 优化和用户行为分析,帮助用户根据数据做出更明智的决策。
如何使用 Python 逐步抓取 Google Trends 数据
例如:在本文中,让我们抓取上个月的“DOGE”的 Google 搜索趋势。
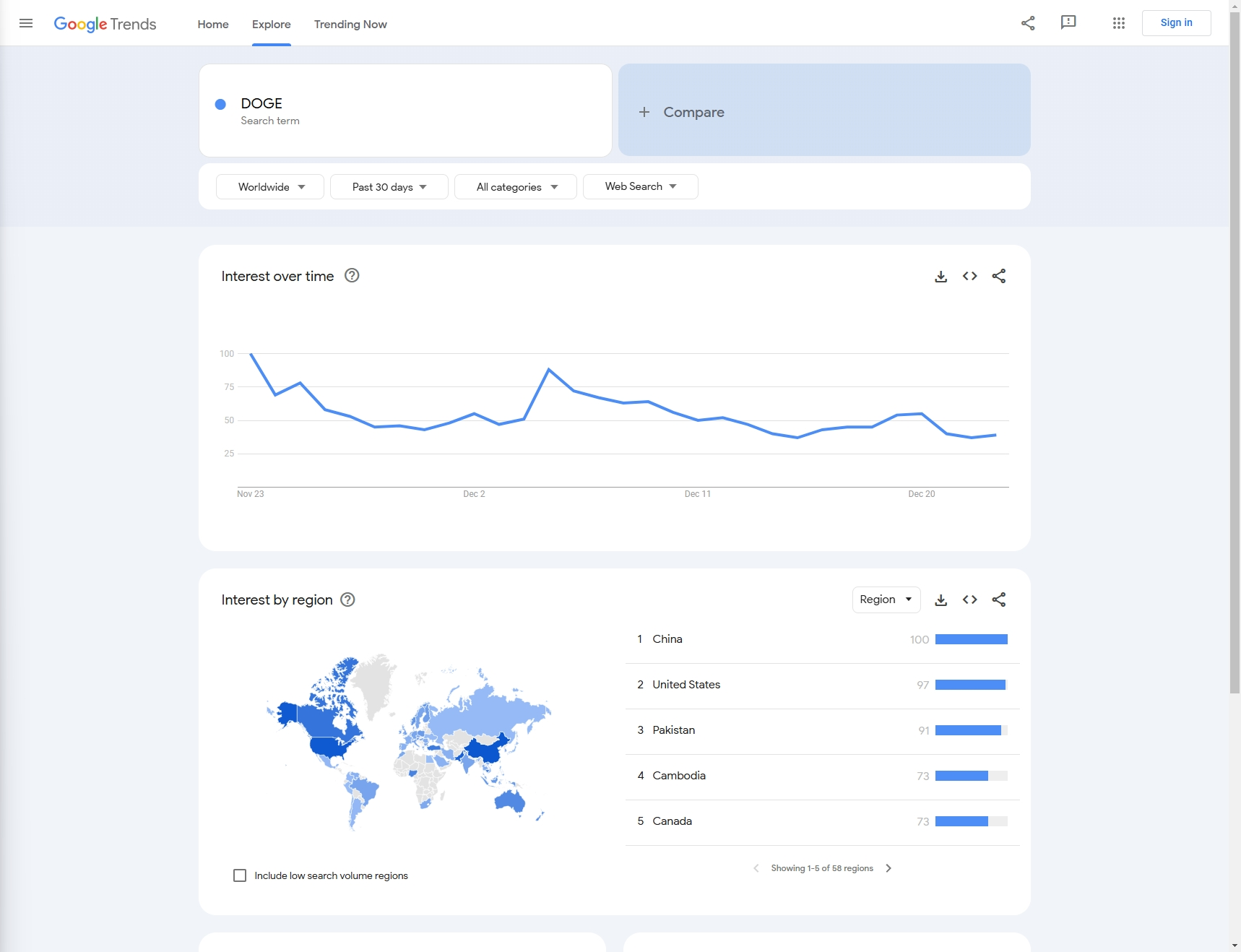
步骤 1:前提条件
安装 Python
在 Windows 上
使用官方 Python 安装程序
-
下载 Python 安装程序:
- 前往官方 Python 网站。
- 网站应该会自动建议 Windows 的最新版本。单击下载 Python按钮下载安装程序。
-
运行安装程序:
- 打开下载的
.exe文件开始安装过程。
- 打开下载的
-
自定义安装(可选):
- 确保在安装窗口的开头选中“将 Python 添加到 PATH”复选框。这使得可以从命令行(
cmd或 PowerShell)访问 Python。 - 您也可以单击“自定义安装”以选择其他功能,例如
pip、IDLE或文档。
- 确保在安装窗口的开头选中“将 Python 添加到 PATH”复选框。这使得可以从命令行(
-
安装 Python:
- 单击立即安装以使用默认设置安装 Python。
- 安装后,您可以通过打开命令提示符(
cmd)并键入以下命令来验证:bashpython --version
-
安装 pip(如果需要):
- Pip 是 Python 包管理器,在现代版本的 Python 中默认安装。您可以通过键入以下命令来检查 pip 是否已安装:
bash
pip --version
- Pip 是 Python 包管理器,在现代版本的 Python 中默认安装。您可以通过键入以下命令来检查 pip 是否已安装:
您也可以直接从 Windows 应用商店(Windows 10/11 上可用)安装 Python。只需在 Microsoft Store 应用中搜索“Python”并选择所需的版本即可。
在 macOS 上
方法 1. 使用 Homebrew(推荐)
-
安装 Homebrew(如果尚未安装):
- 打开终端应用程序。
- 粘贴以下命令以安装 Homebrew(macOS 的包管理器):
bash
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
-
使用 Homebrew 安装 Python:
- 安装 Homebrew 后,您可以使用以下命令安装 Python:
bash
brew install python
- 安装 Homebrew 后,您可以使用以下命令安装 Python:
-
验证安装:
- 安装后,您可以使用以下命令验证 Python 和 pip 版本:
bash
python3 --version pip3 --version
- 安装后,您可以使用以下命令验证 Python 和 pip 版本:
方法 2. 使用官方 Python 安装程序
-
下载 macOS 安装程序:
- 前往Python 下载页面。
- 下载 Python 的最新 macOS 安装程序。
-
运行安装程序:
- 打开
.pkg文件开始安装过程并按照说明操作。
- 打开
-
验证安装:
- 安装后,打开终端并检查 Python 版本:
bash
python3 --version pip3 --version
- 安装后,打开终端并检查 Python 版本:
在 Linux 上
对于基于 Debian/Ubuntu 的发行版
-
更新包列表:
- 打开终端并运行以下命令以更新包列表:
bash
sudo apt update
- 打开终端并运行以下命令以更新包列表:
-
安装 Python:
- 要安装 Python 3(通常是 Python 3.x 的最新版本),请运行:
bash
sudo apt install python3
- 要安装 Python 3(通常是 Python 3.x 的最新版本),请运行:
-
安装 pip(如果未安装):
- 如果 pip 尚未安装,您可以使用以下命令安装它:
bash
sudo apt install python3-pip
- 如果 pip 尚未安装,您可以使用以下命令安装它:
-
验证安装:
- 要检查已安装的 Python 版本:
bash
python3 --version pip3 --version
- 要检查已安装的 Python 版本:
对于基于 Red Hat/Fedora 的发行版
-
安装 Python 3:
- 打开终端并运行:
bash
sudo dnf install python3
- 打开终端并运行:
-
安装 pip(如有必要):
- 如果
pip未默认安装,您可以使用以下命令安装它:bashsudo dnf install python3-pip
- 如果
-
验证安装:
- 要检查已安装的 Python 版本:
bash
python3 --version pip3 --version
- 要检查已安装的 Python 版本:
对于 Arch Linux 和基于 Arch 的发行版
-
安装 Python 3:
- 运行以下命令:
bash
sudo pacman -S python
- 运行以下命令:
-
安装 pip:
- Pip 应该与 Python 一起安装,但如果没有,您可以使用以下命令安装它:
bash
sudo pacman -S python-pip
- Pip 应该与 Python 一起安装,但如果没有,您可以使用以下命令安装它:
-
验证安装:
- 要检查 Python 和 pip 版本:
bash
python --version pip --version
- 要检查 Python 和 pip 版本:
使用 Anaconda 中的 Python(跨平台)
Anaconda 是一个流行的科学计算发行版,它带有 Python、库和conda包管理器。
-
下载 Anaconda:
- 访问Anaconda 下载页面并下载适合您平台的版本。
-
安装 Anaconda:
- 按照基于您的操作系统的安装说明进行操作。Anaconda 为 Windows 和 macOS 提供图形安装程序,也为所有平台提供命令行安装程序。
-
验证安装:
-
安装后,打开终端(或 Windows 上的 Anaconda Prompt)并检查 Python 是否正在运行:
bashpython --version -
您也可以验证
conda(Anaconda 的包管理器):bashconda --version
-
管理 Python 版本(可选)
如果您需要在同一台机器上管理多个 Python 版本,可以使用版本管理器:
-
pyenv: 一个流行的 Python 版本管理器,可在 Linux 和 macOS 上运行。
- 通过 Homebrew 或 GitHub 安装(适用于 Linux 和 macOS)。
- 在 Windows 上,您可以使用pyenv-win。
bashpyenv install 3.9.0 pyenv global 3.9.0
访问 scrapeless API 和 Google 趋势
由于我们尚未开发用于使用的第三方库,您只需要安装 requests 来体验 scrapeless API 服务
Shell
pip install requests步骤 2:配置所需代码字段
接下来,我们需要了解如何通过配置获取所需数据:
- 关键词: 在此示例中,我们的关键词是“DOGE”(我们也支持多个关键词比较数据的收集)
- 数据配置:
- 国家: 查询国家/地区,默认为“全球”
- 时间: 时间段
- 类别: 类型
- 属性: 数据来源
步骤 3:提取数据
现在,让我们使用 Python 代码获取目标数据:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request(data_type, search_term):
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "scrapeless-api-key" # TODO:使用您的 api 密钥
headers = {"x-api-token": token}
input_data = {
"q": search_term,
"date": "today 1-m",
"data_type": data_type,
"hl": "en-sg",
"tz": "-480",
"geo": "",
"cat": "",
"property": "",
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.google.trends", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("错误:", response.status_code, response.text)
return
print("主体", response.text)
if __name__ == "__main__":
send_request(data_type="interest_over_time", search_term="DOGE")- 输出:
JSON
{"interest_over_time":{"averages":[],"timelineData":[{"formattedAxisTime":"24 Nov","formattedTime":"24 Nov 2024","formattedValue":["85"],"hasData":[true],"time":"1732406400","value":[85]},{"formattedAxisTime":"25 Nov","formattedTime":"25 Nov 2024","formattedValue":["89"],"hasData":[true],"time":"1732492800","value":[89]},{"formattedAxisTime":"26 Nov","formattedTime":"26 Nov 2024","formattedValue":["68"],"hasData":[true],"time":"1732579200","value":[68]},{"formattedAxisTime":"27 Nov","formattedTime":"27 Nov 2024","formattedValue":["60"],"hasData":[true],"time":"1732665600","value":[60]},{"formattedAxisTime":"28 Nov","formattedTime":"28 Nov 2024","formattedValue":["49"],"hasData":[true],"time":"1732752000","value":[49]},{"formattedAxisTime":"29 Nov","formattedTime":"29 Nov 2024","formattedValue":["55"],"hasData":[true],"time":"1732838400","value":[55]},{"formattedAxisTime":"30 Nov","formattedTime":"30 Nov 2024","formattedValue":["54"],"hasData":[true],"time":"1732924800","value":[54]},{"formattedAxisTime":"1 Dec","formattedTime":"1 Dec 2024","formattedValue":["55"],"hasData":[true],"time":"1733011200","value":[55]},{"formattedAxisTime":"2 Dec","formattedTime":"2 Dec 2024","formattedValue":["64"],"hasData":[true],"time":"1733097600","value":[64]},{"formattedAxisTime":"3 Dec","formattedTime":"3 Dec 2024","formattedValue":["57"],"hasData":[true],"time":"1733184000","value":[57]},{"formattedAxisTime":"4 Dec","formattedTime":"4 Dec 2024","formattedValue":["61"],"hasData":[true],"time":"1733270400","value":[61]},{"formattedAxisTime":"5 Dec","formattedTime":"5 Dec 2024","formattedValue":["100"],"hasData":[true],"time":"1733356800","value":[100]},{"formattedAxisTime":"6 Dec","formattedTime":"6 Dec 2024","formattedValue":["84"],"hasData":[true],"time":"1733443200","value":[84]},{"formattedAxisTime":"7 Dec","formattedTime":"7 Dec 2024","formattedValue":["79"],"hasData":[true],"time":"1733529600","value":[79]},{"formattedAxisTime":"8 Dec","formattedTime":"8 Dec 2024","formattedValue":["72"],"hasData":[true],"time":"1733616000","value":[72]},{"formattedAxisTime":"9 Dec","formattedTime":"9 Dec 2024","formattedValue":["64"],"hasData":[true],"time":"1733702400","value":[64]},{"formattedAxisTime":"10 Dec","formattedTime":"10 Dec 2024","formattedValue":["64"],"hasData":[true],"time":"1733788800","value":[64]},{"formattedAxisTime":"11 Dec","formattedTime":"11 Dec 2024","formattedValue":["63"],"hasData":[true],"time":"1733875200","value":[63]},{"formattedAxisTime":"12 Dec","formattedTime":"12 Dec 2024","formattedValue":["59"],"hasData":[true],"time":"1733961600","value":[59]},{"formattedAxisTime":"13 Dec","formattedTime":"13 Dec 2024","formattedValue":["54"],"hasData":[true],"time":"1734048000","value":[54]},{"formattedAxisTime":"14 Dec","formattedTime":"14 Dec 2024","formattedValue":["48"],"hasData":[true],"time":"1734134400","value":[48]},{"formattedAxisTime":"15 Dec","formattedTime":"15 Dec 2024","formattedValue":["43"],"hasData":[true],"time":"1734220800","value":[43]},{"formattedAxisTime":"16 Dec","formattedTime":"16 Dec 2024","formattedValue":["48"],"hasData":[true],"time":"1734307200","value":[48]},{"formattedAxisTime":"17 Dec","formattedTime":"17 Dec 2024","formattedValue":["55"],"hasData":[true],"time":"1734393600","value":[55]},{"formattedAxisTime":"18 Dec","formattedTime":"18 Dec 2024","formattedValue":["52"],"hasData":[true],"time":"1734480000","value":[52]},{"formattedAxisTime":"19 Dec","formattedTime":"19 Dec 2024","formattedValue":["63"],"hasData":[true],"time":"1734566400","value":[63]},{"formattedAxisTime":"20 Dec","formattedTime":"20 Dec 2024","formattedValue":["64"],"hasData":[true],"time":"1734652800","value":[64]},{"formattedAxisTime":"21 Dec","formattedTime":"21 Dec 2024","formattedValue":["47"],"hasData":[true],"time":"1734739200","value":[47]},{"formattedAxisTime":"22 Dec","formattedTime":"22 Dec 2024","formattedValue":["44"],"hasData":[true],"time":"1734825600","value":[44]},{"formattedAxisTime":"23 Dec","formattedTime":"23 Dec 2024","formattedValue":["44"],"hasData":[true],"time":"1734912000","value":[44]},{"formattedAxisTime":"24 Dec","formattedTime":"24 Dec 2024","formattedValue":["46"],"hasData":[true],"isPartial":true,"time":"1734998400","value":[46]}]}}步骤 4:优化代码
- 配置多个国家/地区
Python
country_map = {
"全球": "",
"阿富汗":"AF",
"奥兰群岛":"AX",
"阿尔巴尼亚":"AL",
#...
}- 配置多个时间段
Python
time_map = {
"过去一小时":"now 1-H",
"过去四小时":"now 4-H",
"过去七天":"now 7-d",
"过去三十天":"today 1-m",
# ...
}- 配置多个类别
Python
category_map = {
"所有类别": "",
"艺术与娱乐": "3",
"汽车与交通工具": "47",
# ...
}- 配置多个数据来源
Python
property_map = {
"网页搜索":"",
"图片搜索":"images",
"Google 购物":"froogle",
# ...
}- 改进后的代码:
Python
import json
import requests
country_map = {
"全球": "",
"阿富汗": "AF",
"奥兰群岛": "AX",
"阿尔巴尼亚": "AL",
# ...
}
time_map = {
"过去一小时": "now 1-H",
"过去四小时": "now 4-H",
"过去七天": "now 7-d",
"过去三十天": "today 1-m",
# ...
}
category_map = {
"所有类别": "",
"艺术与娱乐": "3",
"汽车与交通工具": "47",
# ...
}
property_map = {
"网页搜索": "",
"图片搜索": "images",
"Google 购物": "froogle",
# ...
}
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request(data_type, search_term, country, time, category, property):
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "scrapeless-api-key" # TODO:使用您的 api 密钥
headers = {"x-api-token": token}
input_data = {
"q": search_term, # 搜索词
"geo": country,
"date": time,
"cat": category,
"property": property,
"hl": "en-sg",
"tz": "-480",
"data_type": data_type
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.google.trends", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload, verify=False)
if response.status_code != 200:
print("错误:", response.status_code, response.text)
return
print("主体", response.text)
if __name__ == "__main__":
# 一个搜索词
send_request(
data_type="interest_over_time",
search_term="DOGE",
country=country_map["全球"],
time=time_map["过去三十天"],
category=category_map["艺术与娱乐"],
property=property_map["网页搜索"],
)
# 两个搜索词
send_request(
data_type="interest_over_time",
search_term="DOGE,python",
country=country_map["全球"],
time=time_map["过去三十天"],
category=category_map["艺术与娱乐"],
property=property_map["网页搜索"],
)抓取过程中的问题
- 我们需要对一些网络错误进行判断,防止错误导致程序中断;
- 添加一定的重试机制可以防止抓取过程中的中断导致重复/无效数据的获取。
使用 Scrapeless 抓取 API 测试 - 最佳 Google Trends 抓取工具
- 步骤 1. 登录Scrapeless
- 步骤 2. 单击“抓取 API”
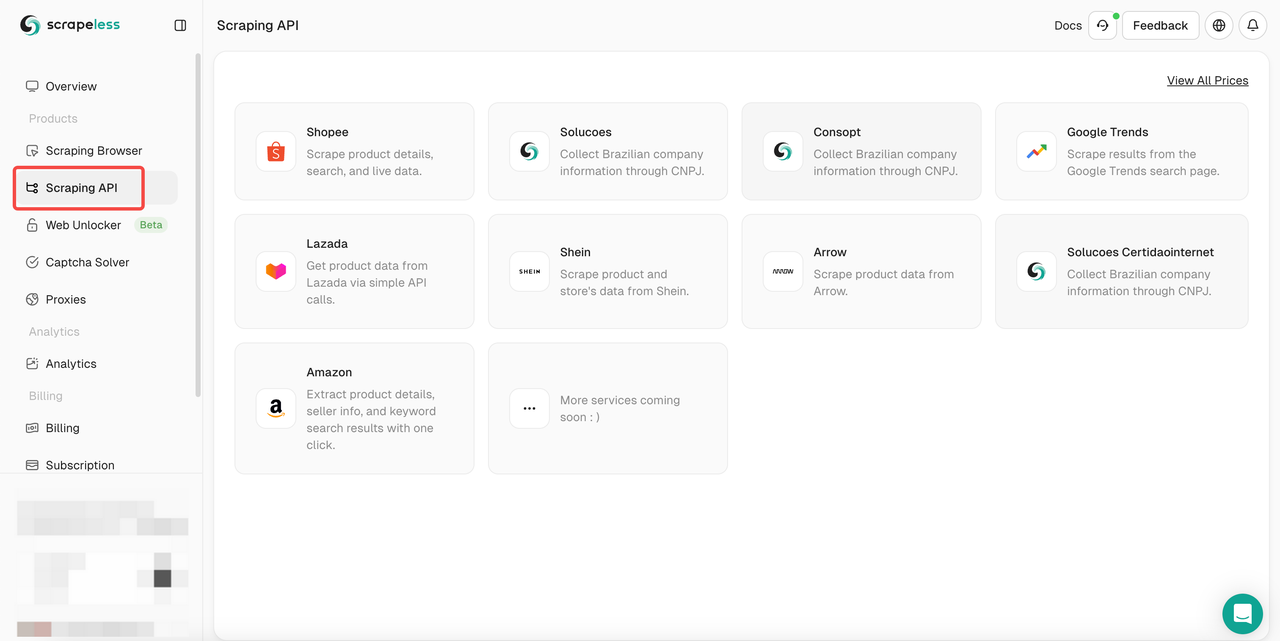
- 步骤 3. 找到我们的“Google Trends”面板并进入:
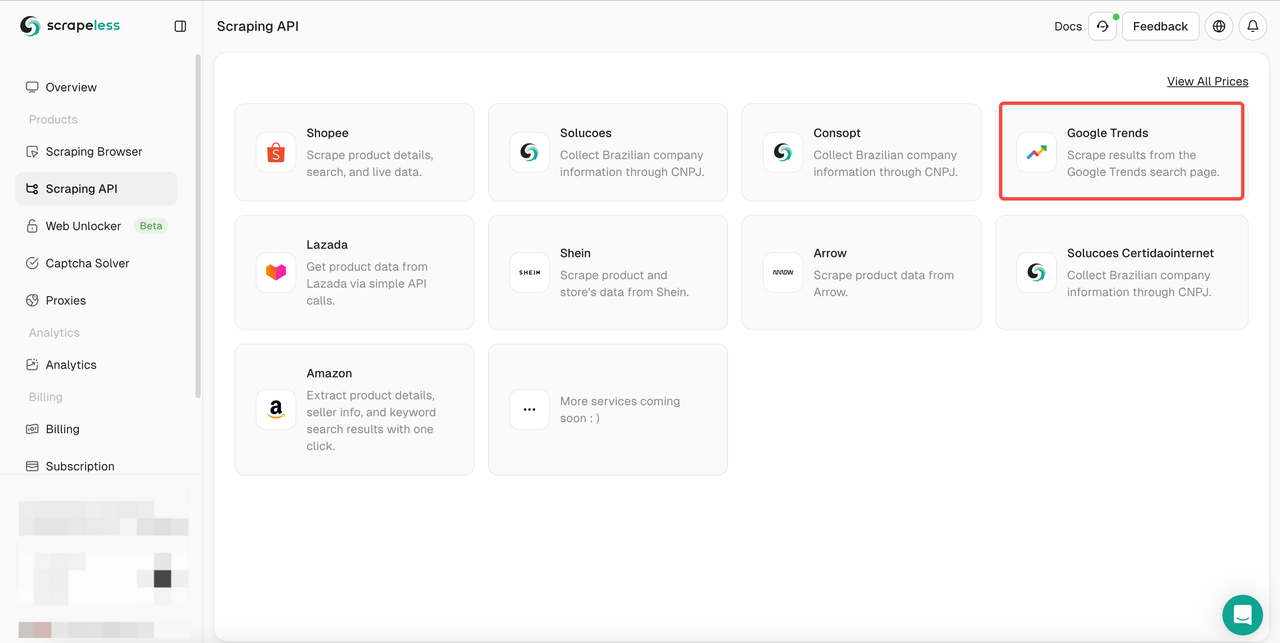
- 步骤 4. 在左侧操作面板中配置您的数据:
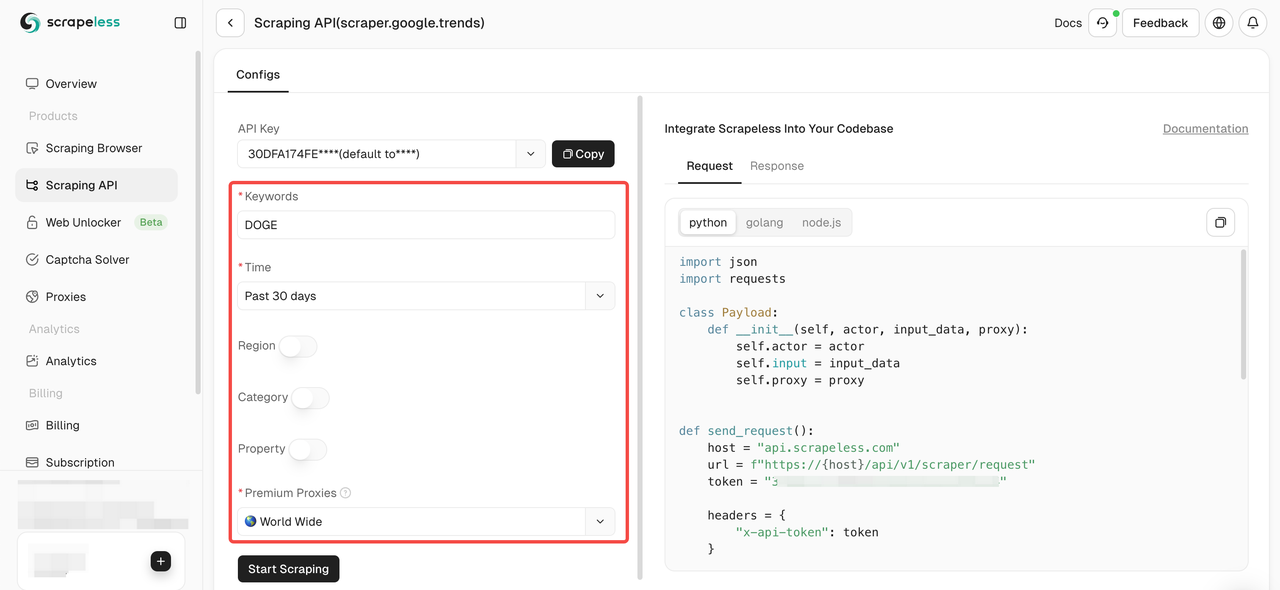
- 步骤 5. 单击“开始抓取”按钮,然后您可以获得结果:
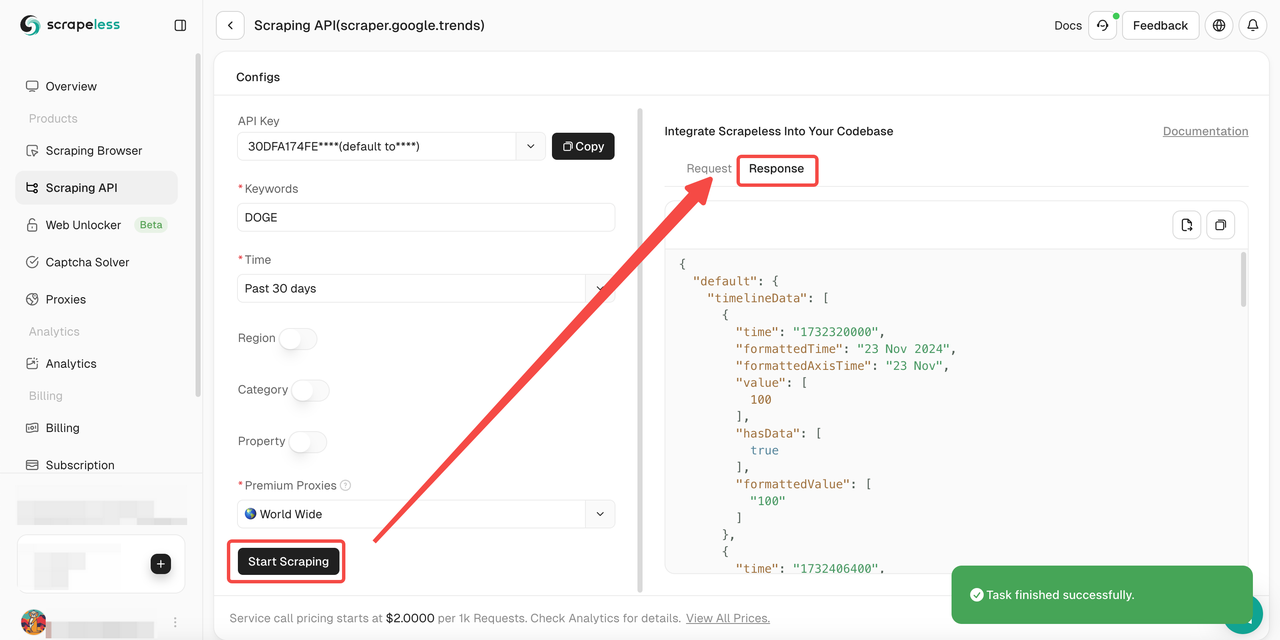
此外,您还可以参考我们的示例代码。
Scrapeless Google Trends API:全面了解
Scrapeless 是一款创新的解决方案,旨在简化从网站提取数据的过程。我们的 API 旨在浏览最复杂的网络环境,有效管理动态内容和 JavaScript 渲染。
为什么 Scrapeless 能够很好地抓取 Google Trends?
如果我们单独使用 Python 代码来抓取 Google Trends,我们将很容易遇到 reCAPTCHA 验证系统。这对我们的抓取过程带来了巨大的挑战。
但是,Scrapeless Google Trends 抓取 API 集成了CAPTCHA 求解器和智能 IP 轮换,因此无需担心被网站监控和识别。Scrapeless 保证 99.9% 的网站抓取成功率,为您提供一个完全稳定和安全的数据抓取环境。
Scrapeless 的 4 个典型优势
- 具有竞争力的价格
Scrapeless 不仅功能强大,而且保证更具竞争力的市场价格。Scrapeless Google Trends 抓取 API 服务调用定价从每 1k 次成功请求 2 美元起。 - 稳定性
丰富的经验和强大的系统确保可靠、不间断的抓取,并具有先进的 CAPTCHA 求解功能。 - 速度
庞大的代理池保证高效、大规模的抓取,不会出现 IP 封锁或延迟。 - 经济高效
专有技术最大限度地降低了成本,使我们能够在不影响质量的情况下提供具有竞争力的价格。 - SLA 保证
服务等级协议确保为企业需求提供一致的性能和可靠性。
常见问题
抓取 Google Trends 是否合法?
是的,抓取全球公开可用的 Google Trends 数据完全合法。但是,请不要通过在短时间内发送过多请求来损害您的网站。
Google Trends 是否具有误导性?
Google Trends 并不能完全反映搜索活动。Google Trends 会过滤掉某些类型的搜索,例如由极少数人执行的搜索。趋势仅显示热门词条的数据,因此搜索量低的词条将显示为“0”。
Google Trends 是否提供 API?
不,Google Trends 尚未提供公共 API。但是,您可以从第三方开发者工具(例如 Scrapeless)中的私有 API 访问 Google Trends 数据。
最后的想法
Google Trends 是一款有价值的数据集成工具,它通过分析搜索引擎上的搜索查询来提供关键词分析和热门搜索主题。在本文中,我们深入介绍了如何使用 Python 抓取 Google Trends。
但是,使用 Python 代码抓取 Google Trends 总是会遇到 CAPTCHA 障碍。这使得您的数据提取特别困难。尽管 Google Trends API 尚未提供,但 Scrapeless Google Trends API 将是您的理想工具!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


