
Scrapeless完全整合了谷歌人工智能概述、人工智能模式和Gemini:GEO时代的终极数据优化框架
Specialist in Anti-Bot Strategies
来自谷歌人工智能概述到Gemini 3,从AI模式的推理链到结构化数据提取——Scrapeless提供了一个完全集成的抓取和分析系统,揭示了2026年AI搜索的真实工作原理,并向您展示了真正的机会所在。
引言:搜索流量分配的重大转变
自2025年初以来,谷歌大幅加速了搜索与人工智能的融合。
随着AI模式的推出,AI概述的覆盖范围扩大,以及Gemini 2.5 Pro在搜索管道中的深度集成,谷歌建立了GEO 2.0的技术基础。
到2025年11月,Gemini 3的发布标志着一个重大转折点——一个根本重塑搜索流量分配方式的转折点。
这并不仅仅是一个简单的产品升级。
这是对搜索可见性和流量分配方式的范式转变。
旧世界(SEO):排名第一 = 最多流量
谷歌搜索曾经是一个静态排行榜。
每个人都看到相同的蓝色链接,排名决定了一切。
但那个时代已经过去。
GEO时代不同
**GEO(生成引擎优化)**完全改变了规则:
流量不再由排名决定。
它取决于AI模型如何解读、选择和引用您的内容。
AI摘要、深度搜索模式和生成的LLM现在选择哪些页面进行引用、组合和展示。
您的流量现在依赖于:
- AI是否能看到您的内容
- AI是否能理解您的内容
- AI是否决定引用您的内容
- 您的内容是否符合模型的偏好结构和推理链
例如,搜索*“最佳xxxx工具”* 现在可能会呈现出三个平行的AI驱动渠道:
1. 谷歌AI概述
一个综合的SERP顶部AI回答,引用3-5个外部网站。
2. 谷歌AI模式
一个完整的生成回答,包含:
- 步骤推理链
- 参考来源
- 扩展子问题
3. Gemini应用搜索
使用Gemini的多模态推理提供更个性化、结构化的响应。
这三条渠道共存——但每个渠道使用不同的内容选择规则:
| 渠道 | 决定您被引用的因素 |
|---|---|
| AI概述 | 清晰度、结构、事实密度、可提取性 |
| AI模式 | 扩展子问题的覆盖范围;深度与证据 |
| Gemini搜索 | 权威性、推理一致性、结构化数据 |
这就是GEO时代的残酷现实。
而一切都在季度变化中演变。
Gemini 3在发布后的几天内,已在核心基准上超越了GPT-5 Pro。
凭借每月6.5亿的Gemini用户和世界上最大的搜索索引,每一次谷歌更新都在重塑整个AI搜索生态系统。
❓那么,您如何理解和优化这三条渠道呢?
答案——也是本文的目的——是明确的:
使用Scrapeless浏览器解锁谷歌的整个AI搜索管道。
第一部分:GEO的核心逻辑
从“排名第一”→“具备结构、易于理解并可被AI引用”
传统SEO是单维度的:
更高的排名 → 更多流量。
GEO是多维度的。
随着Gemini 3、AI模式和AI概述的同时运行,您在三个不断发展的维度上竞争:
维度1:Gemini 3的深度推理能力
Gemini 3在人类的最后考试基准上得分为37.4——超过了GPT-5 Pro。
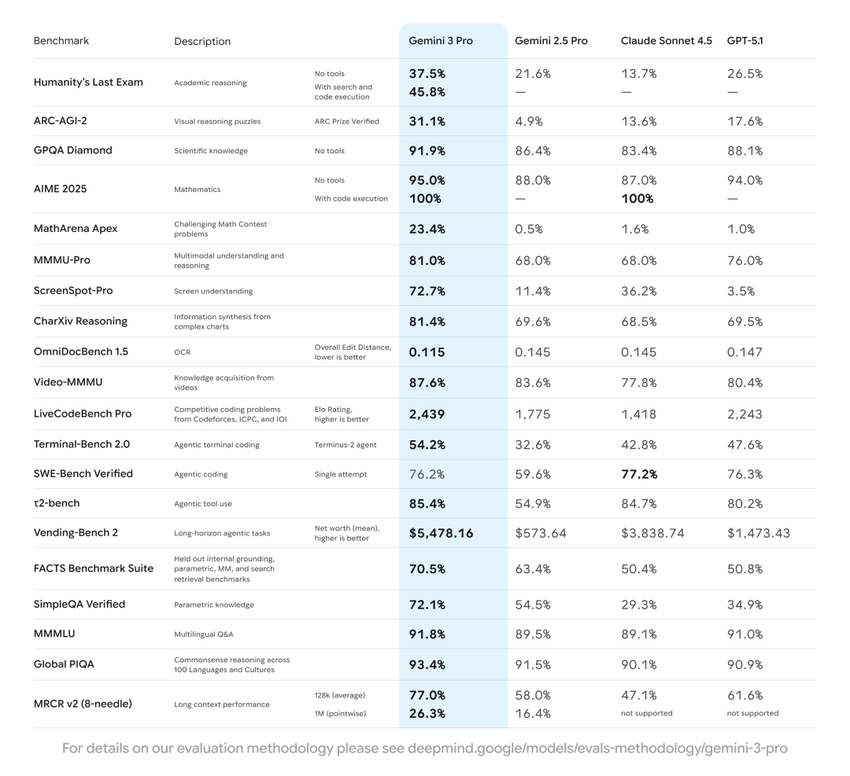
它引入了:
- 明确的思维推理链
- 自我批评
- 证据加权的答案评分
这意味着Gemini不断提出问题:
“这个答案有足够的证据支持吗?”
为了被选中,您的内容必须:
- 回答表面和隐含子问题
- 提供数据和事实基础
- 包含示例和验证
- 保持内部逻辑一致
更重要的是:
Gemini偏爱记忆中的高权威内容。
它仅在必要时进行实时互联网搜索。
长期GEO战略很明确:
使您的内容具有足够的权威,能够进入下一代模型的训练数据。
维度2:AI模式的自动查询扩展
当用户提出一个问题时,AI模式会自动生成:
➡️ 8-12个子问题
➡️ 独立搜索每个问题
➡️ 为每个答案选择不同的网站
排名第一并不保证被引用,因为您的竞争对手——排名第五的人——可能正好符合一个子问题。
这导致了一个大胆的结论:
不要写一篇 5,000 字的“终极指南”。
写 十篇 500 字的深入回答,每篇针对一个原子问题。
维度 3:AI 概述的可提取性规则
AI 概述旨在生成快速、准确的摘要。
要被引用,您的内容必须提供:
✔️ 清晰的结构
标题、副标题和独立段落。
✔️ 基于事实的陈述
表格、数字、逐步逻辑。
✔️ 可提取的句子
简短、准确、逻辑完整的陈述。
✔️ 全面覆盖
以便 AI 可以从您的页面提取多个片段。
被引用并不总是意味着点击——但它确实带来了:
- 品牌可见性
- 模型级别的权威提升
- 更高的长期引用概率
- 当用户查看引用来源时的推荐流量
简而言之:
AI 概述不是排名竞争——而是可提取性竞争。
第二部分:Scrapeless 浏览器对 GEO 数据收集的重要性
根本问题:传统抓取工具的三大失败
许多人问:
“为什么不直接使用 Puppeteer 或 Selenium 连接浏览器进行抓取?”
答案在于传统抓取工具在 GEO 时代无法再处理的三个结构性问题。
挑战 1:IP 检测和快速封锁
在 2025 年 9 月中旬,谷歌悄然删除了一个存在近 20 年的参数:num=100。
这不仅仅是参数的移除——它标志着谷歌反机器人架构的重大升级。
当您通过传统抓取工具发送大量搜索请求时,谷歌会立即:
- 识别您的 IP
- 触发 reCAPTCHA v3
- 如果您继续,将在 24–72 小时内封锁您的 IP
这在实践中意味着什么?
如果您需要在谷歌 AI 概述中跟踪 100 个关键词,传统抓取工具可能需要 20–30 个旋转代理 IP,仍有很高的被检测风险。
谷歌的检测系统已经远远超出了 IP 检查。它现在评估:
- 请求时间模式(过于规律=机器人)
- 浏览器指纹(这是真实浏览器吗?)
- 交互模式(鼠标移动、点击延迟、停留时间)
- 跨域连续性(这看起来像人类的搜索会话吗?)
传统抓取工具根本无法可靠地模拟这些行为。
挑战 2:JavaScript 渲染不完整
谷歌 AI 概述、AI 模式和 Gemini 都是 动态生成 回答的。
这些内容在初始 HTML 中并不存在。它是通过多层 JavaScript 渲染构建的。
如果您简单地运行:
js
await page.goto(url);并立即进行抓取,您通常会看到:
- AI 答案容器存在,但 内容为空
- 引用列表 尚未加载
- AI 模式中的推理步骤 缺失
为什么?
因为谷歌使用了多步骤异步渲染管道:
- 加载结构框架
- 触发推理
- 渲染答案
- 渲染引用
- 渲染交互元素
除非您的浏览器能够正确等待每个阶段,否则您的输出将是 不完整的。
挑战 3:获得稳定和可重复的数据
在 AI 模式和 Gemini 中,个性化上下文显著影响结果。
谷歌根据以下条件个性化答案:
- 搜索历史
- 地理位置
- 设备属性
- Gmail / YouTube 活动
- 先前的交互模式
示例:
用户 A(健身爱好者)搜索 “快速健康早餐”
→ AI 模式建议高蛋白饮食计划
用户 B(烘焙爱好者)搜索相同的术语
→ AI 模式建议面包食谱
如果您使用真实用户账户进行抓取,您的结果将深深与该用户的历史关联。
这破坏了 可重复性,而可重复性对 GEO 分析至关重要。
Scrapeless 浏览器通过以下方式解决此问题:
- 虚拟用户模拟(没有历史,没有偏好,没有登录数据)
- 每个会话的干净、独立环境
- 所有运行中的一致、可重复输出
这消除了个性化噪声,确保数据可靠用于分析。
Scrapeless 浏览器:专为 GEO 数据收集而构建的解决方案
Scrapeless 浏览器专门设计用于克服上述三大挑战。
解决方案 1:云浏览器 + 智能代理轮换
Scrapeless 不仅提供 IP,还提供 完整的云浏览器实例。
每个实例包括:
- 一个独立的浏览器进程
- 专用的浏览器配置文件
- 全球 IP 池(195 个国家及地区)
- 真实的网络延迟和类人交互模式
- 指纹定制(随机化或完全控制)
从谷歌的角度来看,每个请求看起来都像是 不同的真实人类,具有:
- 不同的位置
- 不同的设备
- 不同的浏览器
- 自然浏览行为
示例:
js
// 请求 1:东京的 Chrome 用户
wss://browser.scrapeless.com/api/v2/browser?proxyCountry=JP&sessionName=User_Tokyo_001
// 请求 2:新加坡的 Safari 用户
wss://browser.scrapeless.com/api/v2/browser?proxyCountry=SG&sessionName=User_Singapore_001
// 请求 3:伦敦的 Edge 用户
wss://browser.scrapeless.com/api/v2/browser?proxyCountry=GB&sessionName=User_London_001这对于传统爬虫来说简直不可能。
解决方案 2:一个完整的、真实的 JavaScript 执行环境
Scrapeless 不 获取静态 HTML。
它作为一个 真实浏览器 加载页面,执行所有生成所需的 JavaScript,以完全生成:
- AI 答复
- 引用
- 推理链
- 动态 UI 块
- 页面加载后构建的任何 DOM 组件
示例:
js
const geminiInput = await page.waitForSelector('div[role="textbox"]');
await geminiInput.type('最佳 shopee 爬虫工具');
await geminiInput.press('Enter');
// 等待 AI 答复生成完毕
await new Promise(resolve => setTimeout(resolve, 10000));核心优势
- 捕获所有动态 AI 内容——不仅仅是初始 DOM
- 完美镜像人类可见结果
- 保证完整的答案提取
解决方案 3:会话管理与可重现性
Scrapeless 浏览器最大的优势是其会话架构。
Scrapeless 提供:
-
持久会话 (sessionTTL):
保持 cookies、本地存储和环境状态一致。 -
幽灵用户环境:
没有搜索历史,没有登录上下文,没有个性化。
这确保了:
- 稳定结果
- 可重现数据
- 无个性化偏见
- 适合 GEO 基准测试的清洁环境
第 3 部分:完整代码集成——使用 Scrapeless 从所有三个 Google 平台提取数据
平台 1:监控 Google AI 概述
Google AI 概述在搜索结果页面的顶部显示,为 AI 生成的总结。
监控这一点可以让你了解:
- Google 引用哪些网站
- 这些网站是如何构建其内容的
- AI 认为什么类型的信息是“高质量”的
完整代码示例
js
const puppeteer = require('puppeteer-core');
async function scrapeWithGoogle() {
const query = new URLSearchParams({
sessionTTL: 900,
sessionRecording: "true",
sessionName: "AskGemini",
proxyCountry: 'US',
token: "SCRAPELESS API KEY",
});
const browserWSEndpoint = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`;
console.log('browserWSEndpoint: ', browserWSEndpoint);
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto("https://google.com");
// 接受 cookies
const dialogButtons = await page.$$('[role="dialog"] div > button > div[role="none"]');
const agentButton = dialogButtons?.length ? dialogButtons[dialogButtons.length - 1] : null;
if (agentButton) {
await agentButton.click();
await new Promise((resolve) => setTimeout(resolve, 1500));
}
await page.waitForSelector("textarea");
await page.type("textarea", "最佳 shopee 爬虫工具");
await page.keyboard.press("Enter");
// 等待 AI 概述加载
await new Promise((resolve) => setTimeout(resolve, 5000));
// 将输出保存为截图
await page.screenshot({ path: 'result.png', fullPage: true });
} catch (err) {
console.error(err);
}
}
scrapeWithGoogle().then();平台 2:跟踪 Google AI 模式中的推理链
Google AI 模式是 Google 最新的深度搜索模式。它生成详细的推理、结构化的答案和可见的引用来源。
监控 AI 模式有助于你:
- 理解 AI 的复合答案
- 查看模型引用了哪些页面
- 追踪 AI 的推理步骤和信息层次
完整代码示例
js
const puppeteer = require('puppeteer-core');
async function scrapeGemini() {
const query = new URLSearchParams({
sessionTTL: 900,
sessionRecording: "true",
sessionName: "GoogleAI",
proxyCountry: 'US',
token: "SCRAPELESS API KEY",
});
const browserWSEndpoint = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`;
console.log('browserWSEndpoint: ', browserWSEndpoint);
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto('https://google.com/ai', { waitUntil: "domcontentloaded" });
// 输入查询
const textArea = await page.waitForSelector('textarea[placeholder="Ask anything"]');
```javascript
await textArea.type('最佳 Shopee 抓取工具');
await textArea.press('Enter');
// 等待推理 + 回答
await new Promise((resolve) => setTimeout(resolve, 10000));
await page.screenshot({ path: 'result.png', fullPage: true });
await browser.disconnect();
} catch (err) {
console.error(err);
}
}
scrapeGemini().then();平台 3:监控 Gemini(谷歌的最强大 LLM)
Gemini 是谷歌的顶级 LLM,具有先进的推理和严格的引用选择。
监控 Gemini 帮助您:
- 查看您的查询在高推理模型下的表现
- 观察模型如何生成答案
- 确定 Gemini 信任和引用的来源
完整代码示例
javascript
const puppeteer = require('puppeteer-core');
async function scrapeGemini() {
const query = new URLSearchParams({
sessionTTL: 900,
sessionRecording: "true",
sessionName: "AskGemini",
proxyCountry: 'US',
token: "SCRAPELESS API KEY", // XiaoLu
});
const browserWSEndpoint = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`;
console.log('browserWSEndpoint: ', browserWSEndpoint);
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto('https://gemini.google.com/app', { timeout: 60000 });
// 在 Gemini 中输入查询
const geminiInput = await page.waitForSelector('div[role="textbox"]');
await geminiInput.type('最佳 Shopee 抓取工具');
await geminiInput.press('Enter');
// 等待 Gemini 生成答案
await new Promise((resolve) => setTimeout(resolve, 10000));
await page.screenshot({ path: 'result.png', fullPage: true });
await browser.disconnect();
} catch (err) {
console.error(err);
}
}
scrapeGemini().then();第 4 部分:从数据到行动 — 如何利用这些洞察来提高您的排名
现在您从三个平台获得了详细数据。
关键问题是:您如何使用这些数据来实际提高您的产品或内容排名?
用例 1:识别缺失的“子问题覆盖”
数据来源:
谷歌 AI 模式的 引用网站 和 生成的子问题
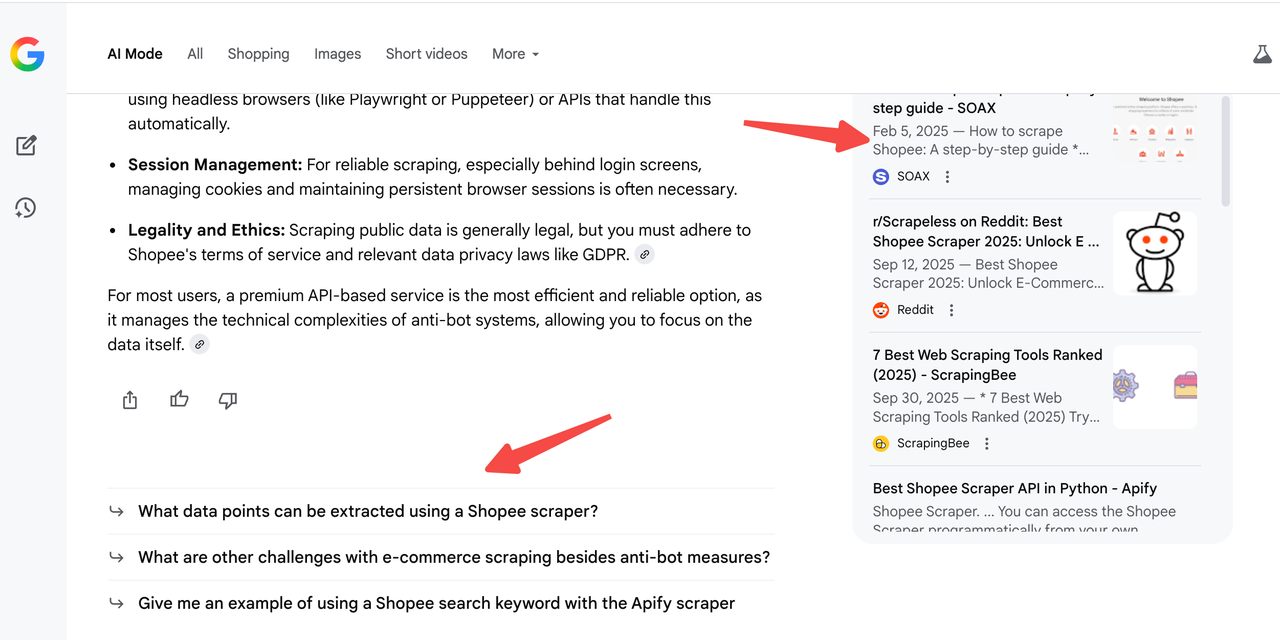
当您运行 AI 模式抓取器时,您将收到完整的子问题列表。
例如,如果您查询 “最佳 Shopee 抓取工具”,AI 模式可能会在右侧面板生成 10 个子问题——而您的网站可能只涵盖其中的 3 个。
行动计划
- 为每个缺失的子问题创建一篇 500–800 字的专门文章。
- 直接使用 子问题本身作为文章标题——不要改写或简化。
- 在文章开头用 H1 标签立即回答子问题,然后提供额外细节。
用例 2:向被引用最多的竞争对手学习
数据来源:
从三个平台提取的引用网站
如果您注意到一个竞争对手在 10 个子问题中被引用 7 次,而您只被引用 2 次,这意味着他们的内容结构与 AI 期望更一致。
行动计划
-
访问被引用的确切竞争对手页面。
-
分析这些页面之间的共同结构:
- 他们是否使用清晰的副标题?
- 他们是否包含比较表?
- 他们是否提供真实的示例或数据?
- 典型段落长度是多少?
-
根据这些结构模式重写或更新您的内容。
用例 3:跟踪 Gemini 模型中的知识更新
数据来源:
Gemini 的回答和引用模式
Gemini 每月更新。一些主题从 “需要实时搜索” 转变为 “模型已经知道答案”。
这揭示了哪些信息可能已经进入模型的训练集。
行动计划
-
进行每月监控会话,记录 Gemini 对您的核心主题的回答如何变化。
-
当一个问题变成模型“已经很好地回答”的内容时,不要放弃该主题。相反,提升您的内容:
- 添加 2025 年级别的更新信息(例如,“在 2024 年底发布的工具”)。
- 添加 真实用户案例——模型无法抓取这些。
- 比较模型可能还不知道的 新竞争对手。
用例 4:检测用户兴趣的变化
数据来源:
来自谷歌 AI 模式 + Gemini 的关键词和问题分解
AI生成的答案反映了用户行为的聚合——子问题和答案段落揭示了用户最关心的痛点。
### **行动计划**
1. 随时间比较AI答案,跟踪最频繁的关键词和子问题。
2. 更新你的内容,并将高关注度的话题推到页面顶部。
3. 使用FAQ模块、H2/H3标题以及模式标记,以增加与搜索和AI引用模式的对齐。
---
# **结论**
在生成搜索时代,"排名第一"的旧SEO思维正在被取代。
真正的竞争不再是关于谁在传统搜索结果页面上排名更高——
而是关于**谁的内容被AI选择、信任并引用**在答案中。
Scrapeless使公司能够完全了解AI的决策过程,并将这些洞察转化为可操作的GEO策略。
---
# **为什么Scrapeless是GEO的核心引擎**
Scrapeless浏览器提供无与伦比的优势:
* **全球代理网络**:涵盖195个以上国家,以捕捉市场特定的AI结果
* **仿人类模拟**:自动处理反机器人系统、浏览器指纹、验证码
* **完整数据提取**:AI答案、引用、HTML结构等
* **零维护云环境**:无需本地浏览器或服务器——将运营成本降低95%
* **完整GEO工具套件**:AI引用监测、结构化内容分析、全球数据捕捉
生成引擎优化不再是可选项——它是企业内容竞争力的基础。
如果你想在AI搜索时代赢得战略可见性,Scrapeless提供了最完整的GEO数据解决方案。
Scrapeless不仅提供基于浏览器的GEO自动化,还有更先进的工具和数据策略,帮助你全面理解和影响AI引用机制。
**我们还推出了[完整的LLM API访问](https://www.scrapeless.com/zh/blog/scrapeless-llm-chat-scraper)**(ChatGPT、Perplexity、Gemini 等)。
如果你感兴趣, [联系我](https://t.me/liam_scrapeless)以获取**免费试用访问**。在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


